おはようございます。
今までは、GraalVMの機能を中心に記事を書いていたのですが、「具体的な実装方法」に関しても、今後は書いていきたいと思います。
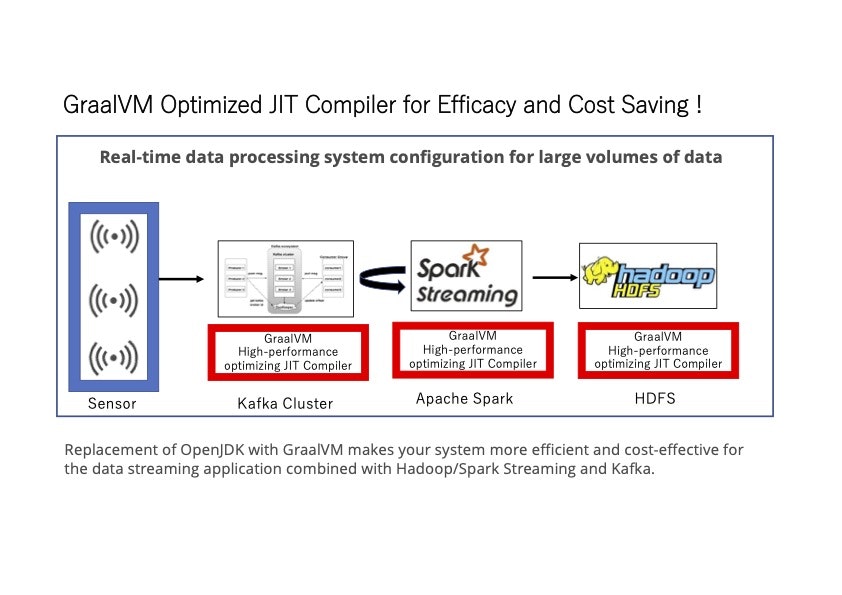
今回は、GraalVMの「最適化されたJITコンパイラー機能」(主要3機能の内の1つ)を活用して、大規模データ分析基盤を、コスト削減しながら、より高速に動かす実装方法に関して、議論します。
================
リアルタイムデータ処理システムにおいても、Graal VMの「最適化されたJITコンパイラ機能」が威力を発揮致します。
■ GraalVMカタログ(P7)
https://www.oracle.com/a/ocom/docs/graalvm-enterprise-white-paper.pdf
While there are many sophisticated performance tuning options and techniques available in Apache Spark, one of the easiest ways to improve overall performance is to run it on GraalVM Enterprise.
■ Facebook社様が、GraalVMを使用して、Apache Sparkを高速化させた事例
https://medium.com/graalvm/graalvm-at-facebook-af09338ac519
>The Facebook team used GraalVM Community as a replacement of OpenJDK. In this scenario, migration to GraalVM is very easy — it’s just a matter of switching runtime, with no changes required for the application code.
>GraalVM can significantly speed up Spark workloads. The Renaissance benchmark suite’s Apache Spark benchmarks show an average speedup 1.1x for Community and of 1.42x for Enterprise, with some benchmarks running up to 4.84x faster.
■ Apache SparkをGraalVM上で動くと、メモリー消費を抑えつつ高速化する実証データ
https://blogs.oracle.com/java/post/apache-sparklightning-fast-on-graalvm-enterprise
As you can see, for a range of benchmarks Apache Spark consumes less memory and runs faster on GraalVM Enterprise than on OpenJDK. If you’re running Apache Spark in production and would like to use fewer compute resources while improving throughput it’s as easy as switching to GraalVM Enterprise. To try it out for yourself simply install GraalVM Enterprise, set your JAVA_HOME, and go! Download GraalVM Enterprise today.