はじめに
本記事では、Dockerコンテナ化したSpring Bootアプリケーションで、
PrometheusとGrafanaを使用してメトリクスの可視化をした事例を紹介します。
背景
私が携わっているプロジェクトでは、Spring Bootで作成したアプリケーションをDockerイメージとしてお客様(事業者)に提供し、お客様のシステム環境で運用します。
このアプリケーションは推奨スペック(CPU数、メモリ容量など)を提示しているものの、実態としては事業者の利用要件によっては過剰スペックになることがあり、無駄に運用コストがかかってしまう問題がありました。
実際どの程度のスペックを割り当てればよいのかは、事業者側で実際に想定するシステム負荷で性能テストを行い、通信のレイテンシやCPU使用率、メモリ使用率など様々なメトリクスを採取して分析する必要があります。
そこで本記事では、Dockerコンテナ化したSpring Bootアプリケーションで、メトリクスを収集・可視化する方法を検証しました。
メトリクスについて
メトリクスという言葉は使用される文脈によって様々なものを指します。
本記事で対象とするアプリケーションはJava製ですので、CPU使用率やヒープの使用状況、GC発生状況に焦点を当てることにします。
手法の選定
Javaアプリケーションのメトリクスを収集、可視化する手段には様々な選択肢が存在します。
例えばJMXやJava Flight Recorderを使う方法も考えられますが、
JMXやJFR用のポートを開けたくないし、JFRをファイルで吐き出す方法もありますが取りに行くのが面倒です。
また、各種クラウドベンダーが用意しているメトリクス採取手段もありますが、Javaアプリケーションのメトリクス採取にはエージェントを導入する必要があります。
これは私のプロジェクト事情ですが、Dockerイメージをどのクラウドベンダーの環境で実行するかは事業者の自由にしています。想定しうるベンダー毎にエージェントを仕込んだDockerイメージを作ってしまうと我々の保守コストが上がってしまいますし、全部入りのイメージで一つにまとめるなんてもってのほかです。
というわけで、今回は実行するクラウドベンダーに依存せず簡単に構築できることを目指して、以下のOSSを採用します。
- Spring Boot Actuator
- Prometheus
- Grafana
Spring Boot Actuatorとは
https://docs.spring.io/spring-boot/reference/actuator/index.html
Spring Boot Actuatorとは、アプリケーションを本番環境で運用するときに役立つ、監視や管理の機能群を備えたライブラリです。
本来の用途では本番環境の運用監視等に利用しますが、今回は性能テストを対象にしていますので、性能のメトリクスの採取だけ設定します。
Prometheusとは
https://prometheus.io/docs/introduction/overview/
Prometheusとは、Pull型のシステム監視およびアラートツールキットです。
Prometheusの機能を使うと、メトリクスを時系列データとして収集・保存ができます。
Grafanaとは
https://grafana.com/docs/grafana/latest/introduction/
Grafanaとは、収集したメトリクスやログ、トレースなどを横断的に紐づけて可視化、アラート等ができるツールキットです。
Prometheusと似ているように感じますが、Prometheusはメトリクスの収集やアラート機能に優れているのに対して、Grafanaは可視化の機能に優れています。
今回の検証構成では、Prometheusをメトリクスの収集のみに利用し、可視化はGrafanaに任せています。
検証
構成図
検証のため以下のような環境を用意しました。
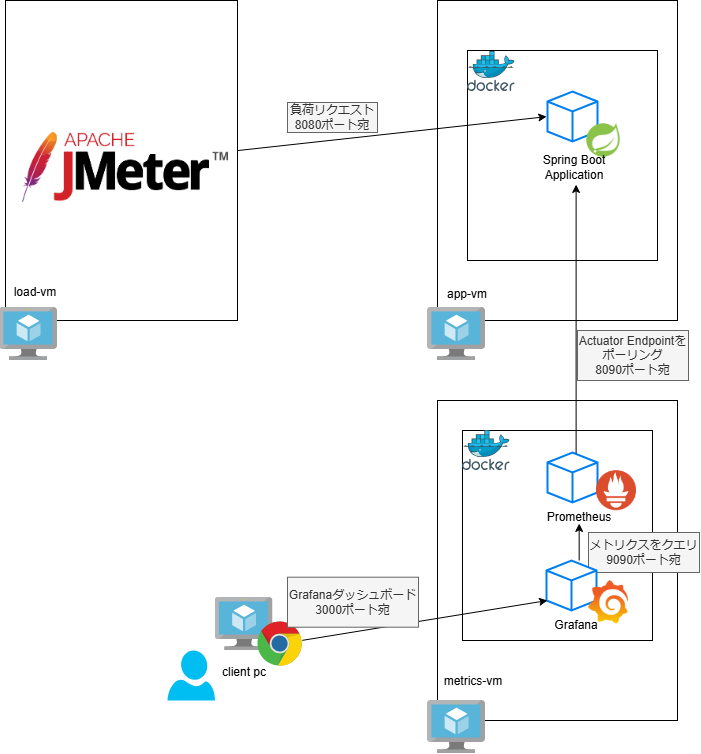
負荷をかけるのにはJMeterを使用します。
PrometheusとGrafanaは既存の環境を間借りするので、環境を汚さないようにDockerで起動します。
計測対象のSpring Bootアプリケーションは余計な影響を受けないようにJMeterやPrometheus+Grafanaを起動するマシンとはVMごと分離しています。
このような構成で性能テストを実施し、Grafanaのダッシュボードからメトリクスを観察して適切なCPU、メモリ割り当てなどを調整しています。
Spring Boot Actuatorの設定
Actuatorのメトリクス公開機能でPrometheus用のメトリクスを扱えるようにするため、依存関係にruntimeOnly io.micrometer:micrometer-registry-prometheusを追加します。
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'org.springframework.boot:spring-boot-starter-webflux'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'io.micrometer:micrometer-registry-prometheus' // ★追加
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'io.projectreactor:reactor-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
次にapplication.propertiesの設定です。
ActuatorのHTTPエンドポイント公開機能で、Prometheus用のエンドポイントを公開する設定を追加します。
management.endpoints.web.exposure.include=prometheus
次にポートの設定です。
Spring BootでWebMVCまたはWebFluxを使用する場合、デフォルトではアプリケーション用の公開ポートが8080になります。
Prometheusのようなメトリクス採取やヘルスチェック等の管理エンドポイントも、デフォルトでは同じポートで公開されます。
アプリケーション用の公開ポートは負荷をかけすぎると応答しなくなることがあり、管理エンドポイントと同じポートを共用しているとメトリクスが採取できなくなってしまうことがあります。
このような問題を避けるため、アプリケーション用の公開ポートと管理エンドポイント用の公開ポートは異なるポート番号を使用するように変更します。
management.server.port=8090
Prometheusの設定
PrometheusとGrafanaは同じVM上に構築するため、docker-composeで構築します。
GithubのAwesome Composeにちょうどよいものが公開されているので、こちらを使います。
https://github.com/docker/awesome-compose/tree/master/prometheus-grafana
PrometheusからSpring Boot Applicationのprometheusエンドポイントを叩くため、prometheus.ymlのscrape_configsセクションに以下の内容を加えます。
scrape_configs:
- job_name: spring-app
scrape_interval: 5s
metrics_path: '/actuator/prometheus'
scheme: http
static_configs:
- targets: ["<replace_your_hostname>:8090"]
Grafanaの設定
Grafanaの管理コンソールにログインし、ダッシュボードを追加します。
ダッシュボードを一から作るのは大変なので、先人の知恵を借ります。
Grafanaではダッシュボードを公開するコミュニティサイトがあるので、Spring Boot向けのダッシュボード(https://grafana.com/grafana/dashboards/14430-spring-boot-statistics-endpoint-metrics/) を使用します。
設定するとこんな感じのダッシュボードになります。
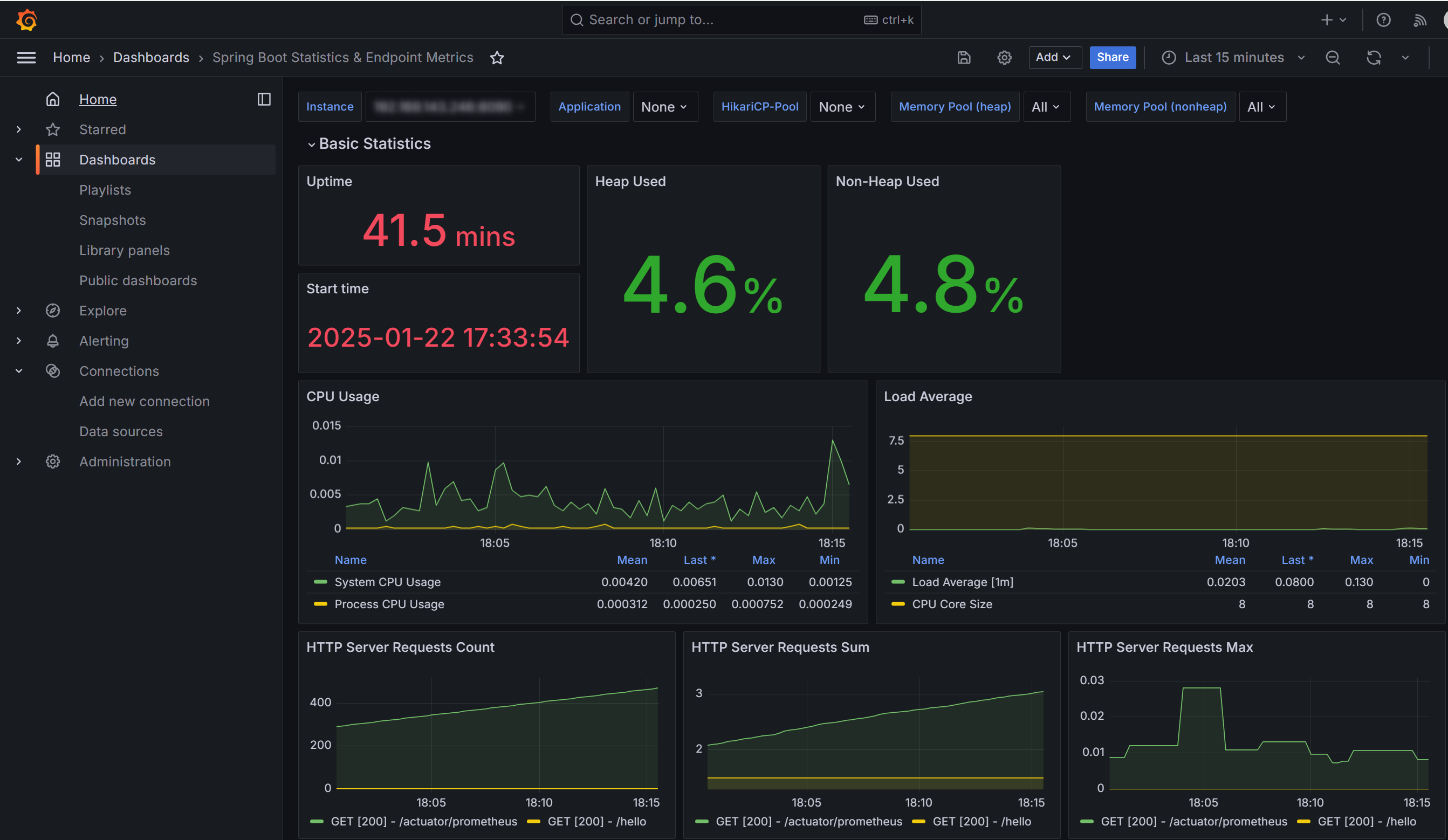
これで負荷をかけてメトリクスを観察する準備が整いました。
メトリクスの確認ポイント
サンプル用に用意した簡単なアプリケーションでは面白くないので、私が開発しているアプリケーションに負荷をかけてメトリクスを採取します。
元々はヒープサイズが3GB固定、GCアルゴリズムがG1GCなのですが、今回はわかりやすくするためにヒープサイズを512MBに変更します。
JMeterのレポートは都合上見せられないのですが、レスポンスタイムがかなり悪化している状況です。
採取したメトリクスをGrafanaで見てみます。
CPUの使用状況はこちら。
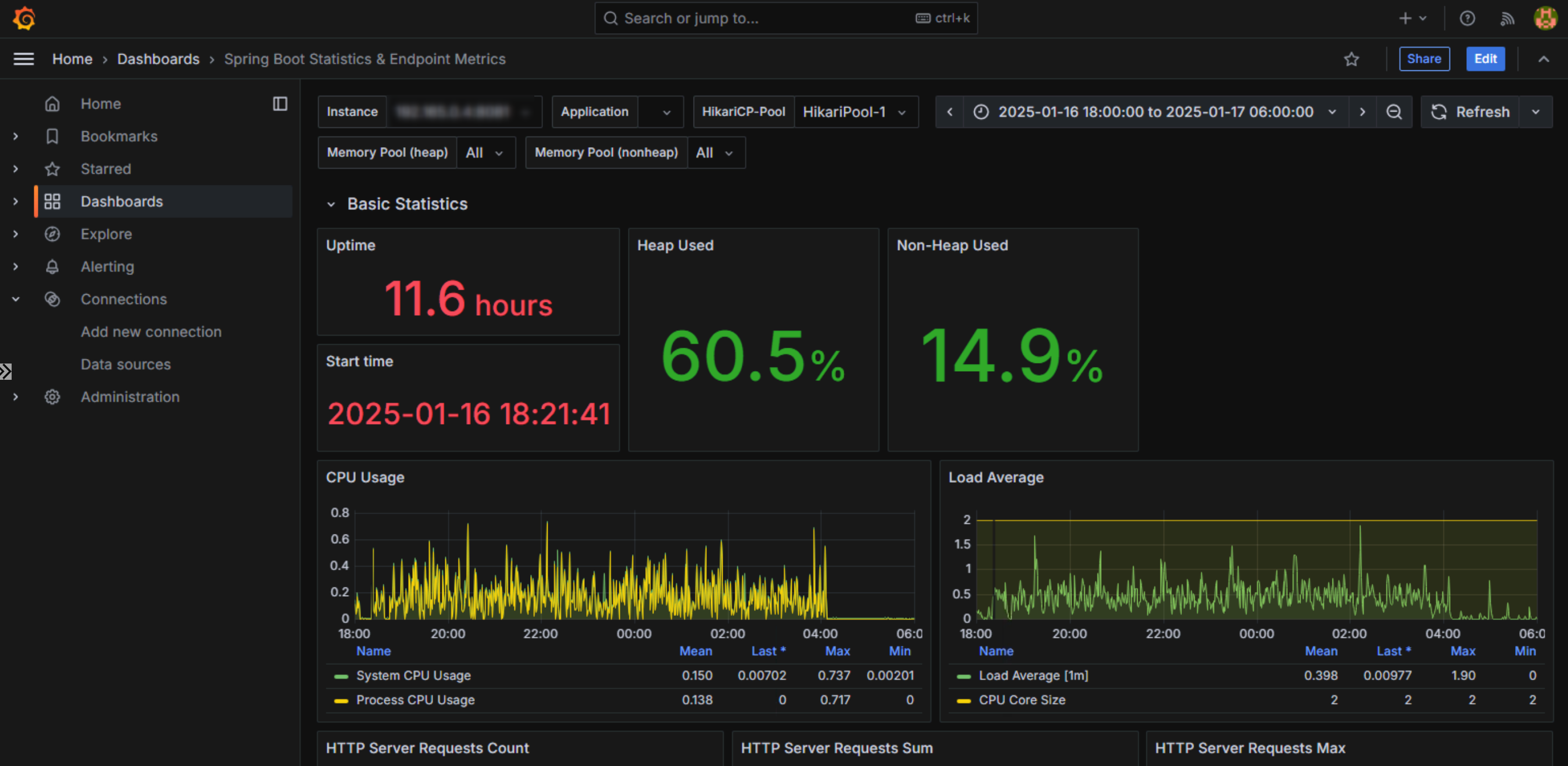
2Coreのマシンで動かしています。CPUUsageおよびLoad Averageを見ても特段逼迫しているようには見えないので、割当Core数は十分なように見えます。
次にヒープの使用状況を見てみます。
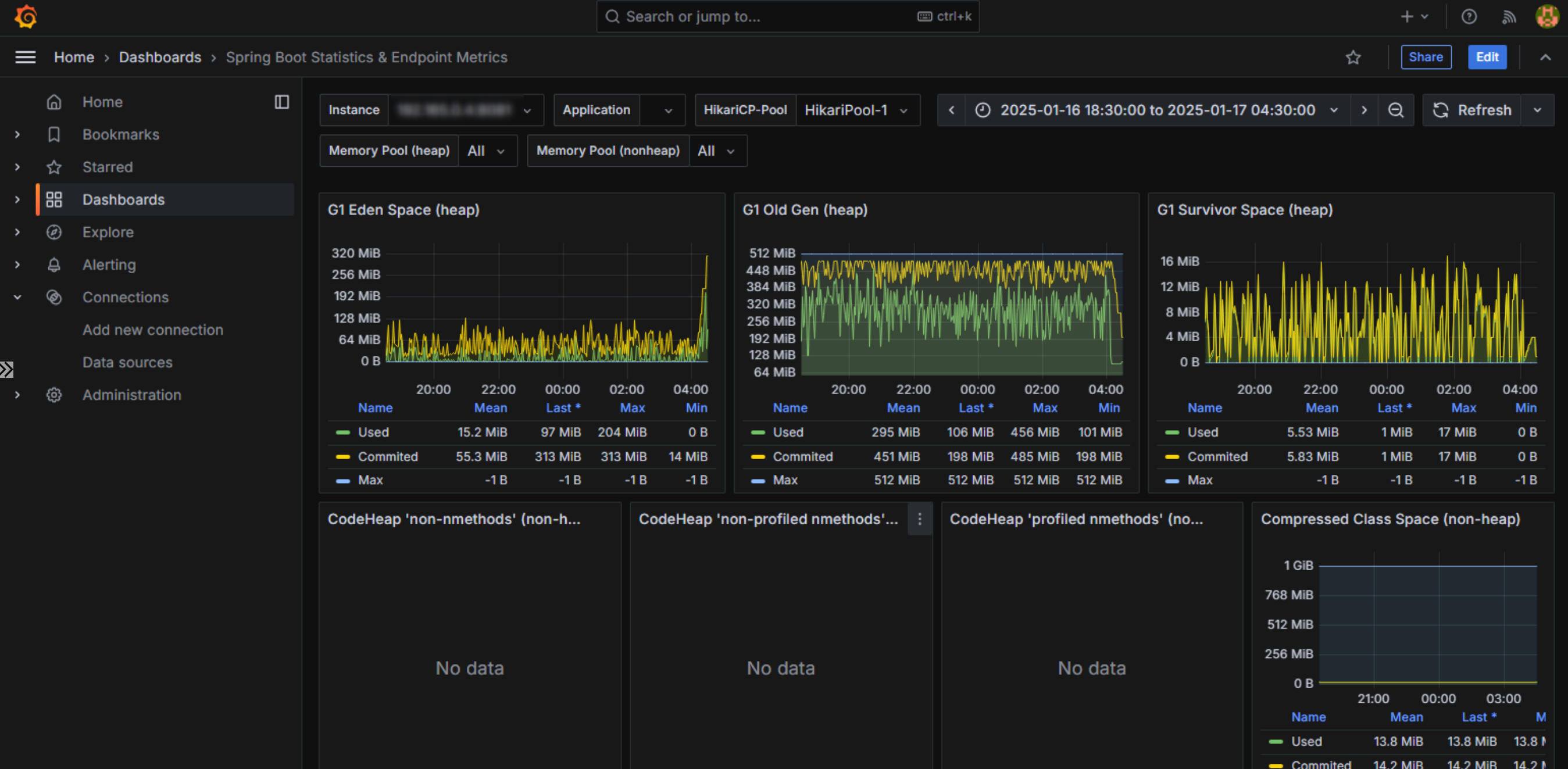
G1 Old Gen (heap) をかなり容量を取られていることが見て取れます。
最後にGCの状況を見てみます。
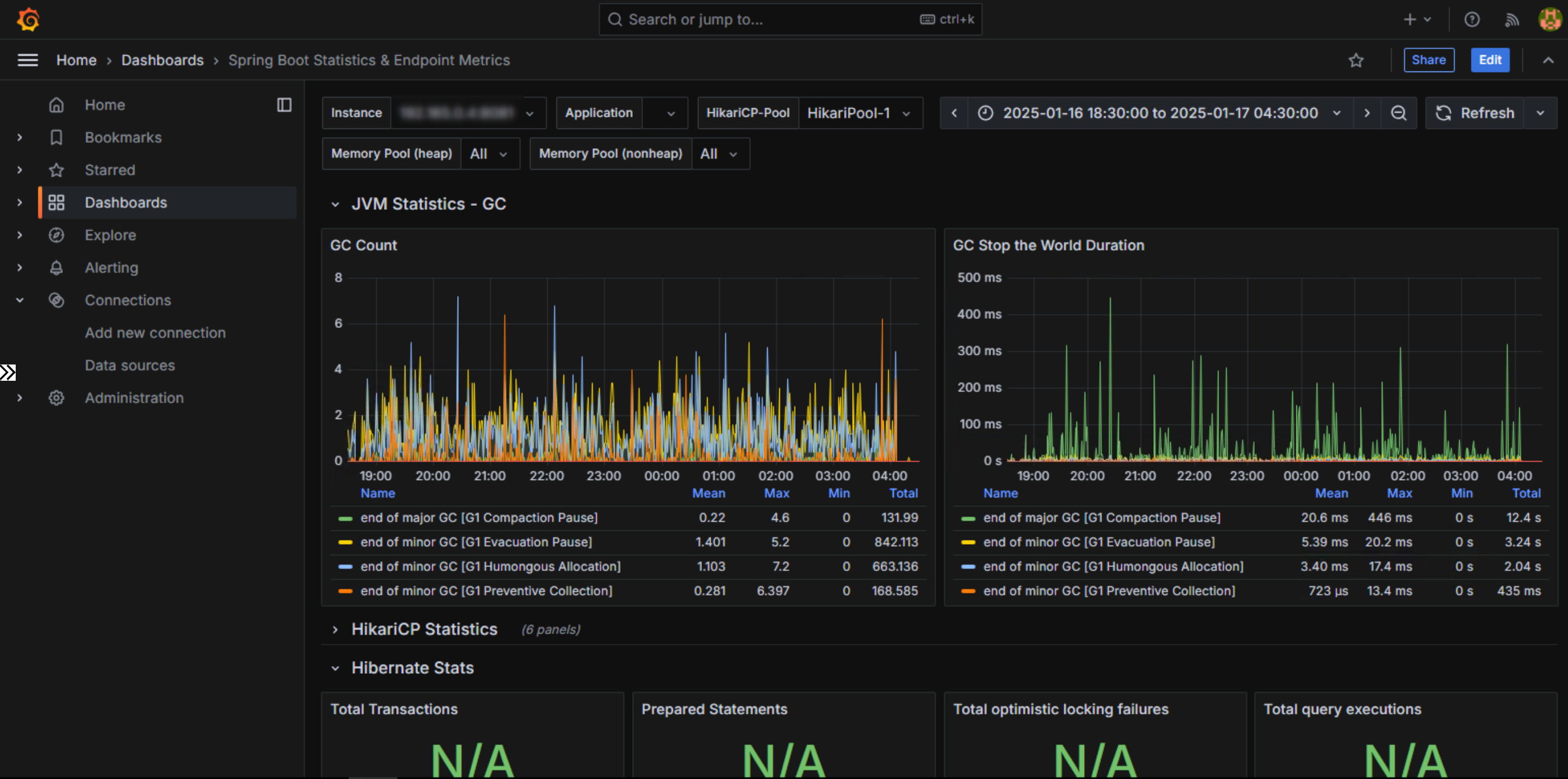
GC Stop the World Durationのグラフを見てみると、G1 Compaction Pauseが多数発生しており、多くのStop The Worldを発生させています。これによりアプリケーションの停止時間がレスポンスに悪影響を与えていると見受けられるため、GCのチューニングを行う必要があります。
※ここではチューニングに関しては深堀りしませんが、気になる方はOracleのチューニングガイドを参照してみてください。
https://docs.oracle.com/javase/jp/17/gctuning/index.html
チューニング後の改善確認
アプリケーションのヒープサイズを3GBに戻して、再度性能をテストしました。
CPUは特に変わりないので、ヒープから見ていきます。
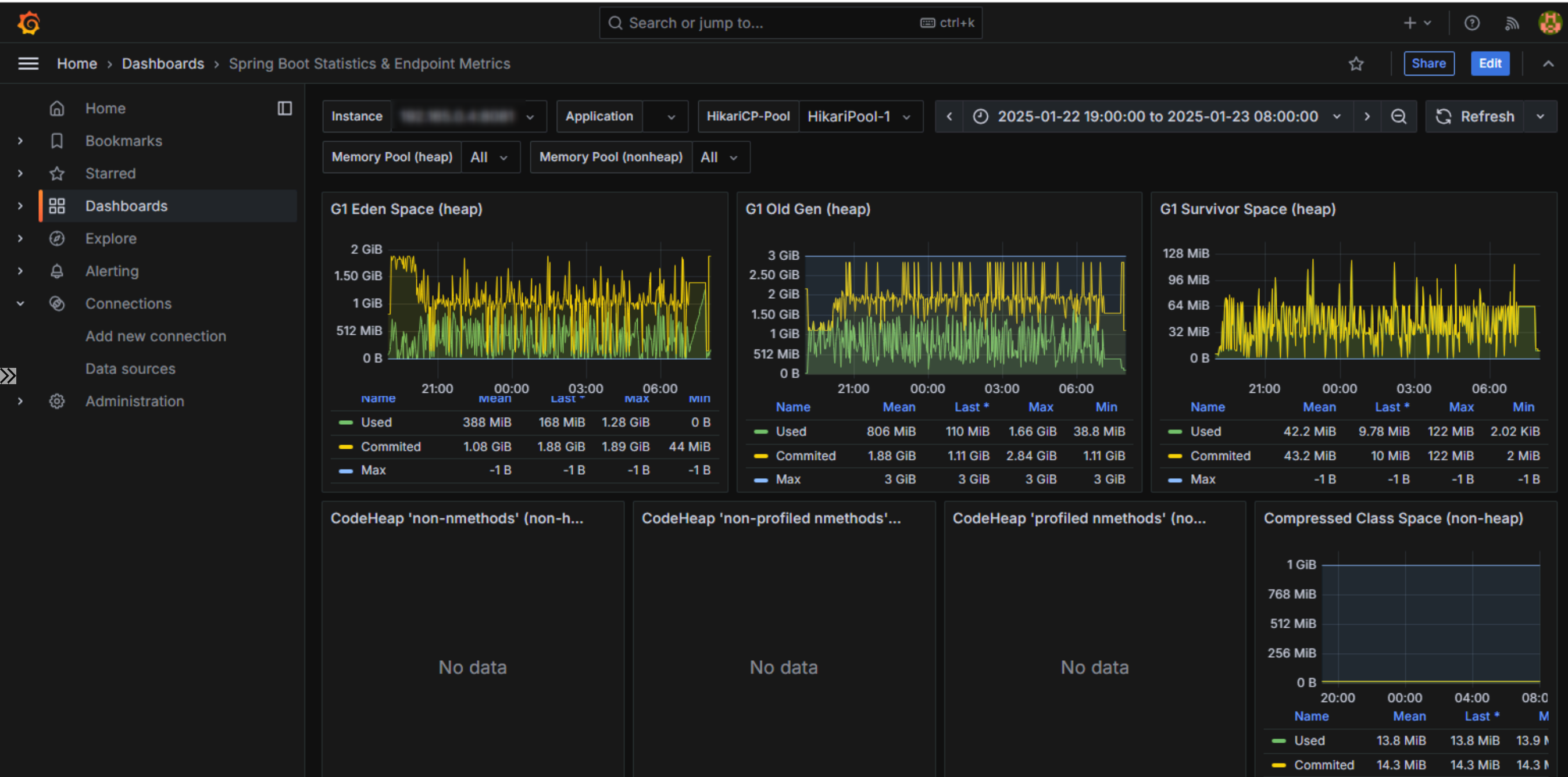
先程はヒープ領域のサイズがG1 Old Genに食い尽くされていましたが、今回は程よくEden Speceにも使用されています。
次にGCの状況です。
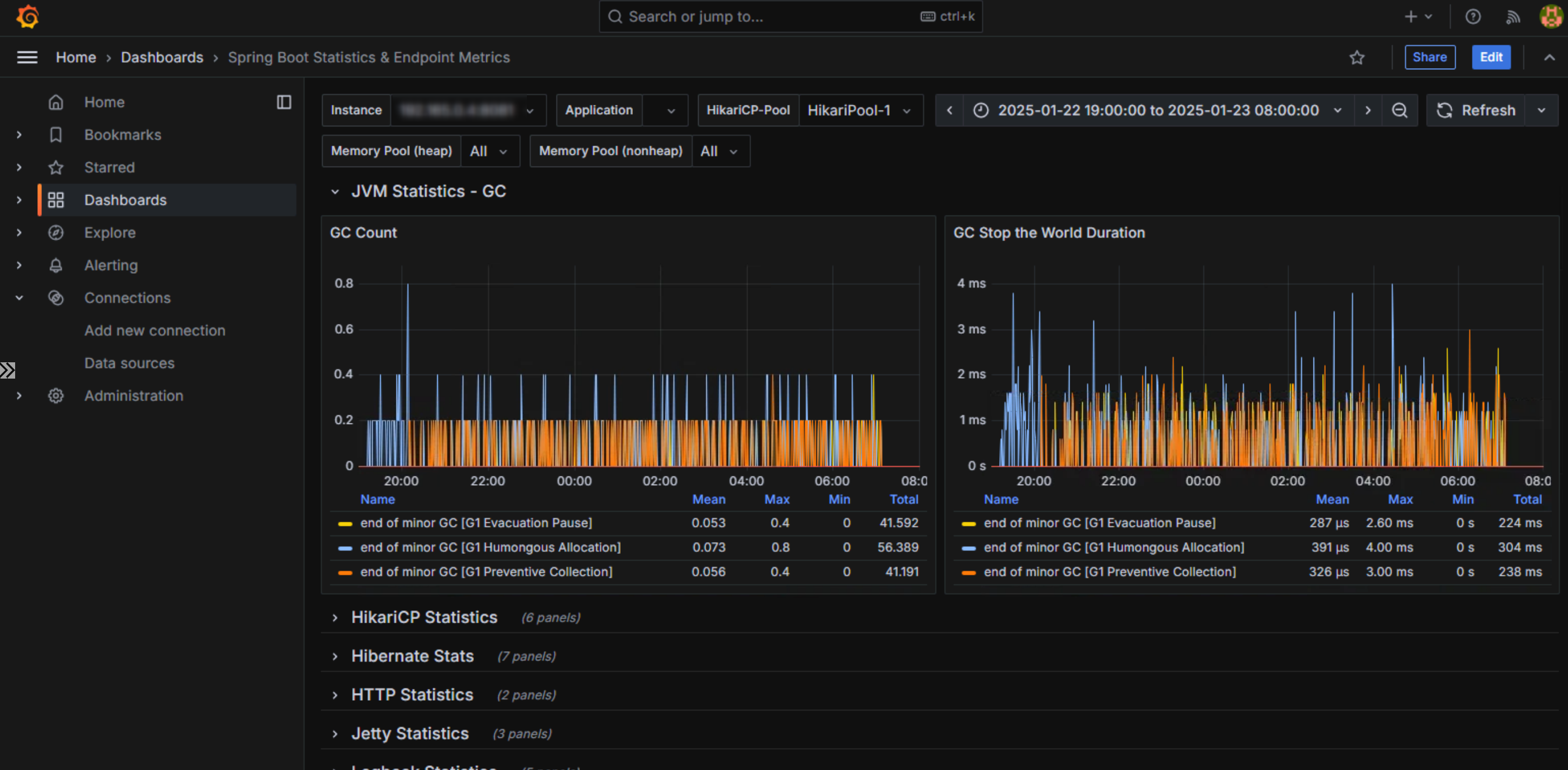
問題となっていたStop The WorldのCompaction Pauseが発生しなくなり、問題なく稼働していることが見て取れます。
おわりに
簡単にメトリクスを採取・可視化するというテーマで検証しました。
性能テストのためにちょっと立ち上げる、という用途ではこれで十分だと思います。
本番運用で性能監視がしたい場合は、PrometheusやGrafana自体の可用性を考慮する必要があります。
その場合は別の方法を検討したほうが良いでしょう。
今回はDockerイメージをクラウドベンダーに依存せずお客様の環境で利用するため、汎用的に使える方法を模索しました。
自分たちでDockerイメージをコントロールできる場合は、当然実行環境ごとに用意されている監視ソリューションを使うのが最も安定感のある方法だと思います。
We Are Hiring!