1. はじめに
この記事はCommune Advent Calendar 2024シリーズ3、10日目の記事です。
QAチームの金丸が担当します。
プログラムにバグが混入する原因は様々です。プログラマーのスキル、プロジェクトの複雑さ、開発プロセス、外部要因など、多くの要素が絡み合っています。
従来、バグの発生確率を予測する際には、過去の統計データや経験則に基づいたモデルを用いられることがありました。今回は別角度として「階層ベイズ推定」という数学的アプローチを用いてバグ購入確率と購入要因を探っていきたいと思います。
tl;dv
数学的な話が多く、こんな技術ブログ読んでられないと言う方向けにざっくりと概要を説明すると
- 開発プロジェクトのバグの混在原因を階層ベイズ推定を用いてシミュレーションしてみた
- その結果、以下の3点がわかった
- 経験豊富な人が作ったコードの方が、バグ混在確率が少ない
- 難しいプロジェクトの方が、バグ混在確率が高い可能性がある
- 品質活動(コードレビュー・テスト)は有用だが他2つと比べると劣る部分がある
という内容になっています。恐らく多くの方々が内心思っていることなのでここだけ読んでブラウザバックしていただいても特に差し支えないです。

2. 階層ベイズ推定
2.1. 階層ベイズ推定とは
階層ベイズ推定は、観測データに加えてデータ構造やデータ同士の関係性を考慮することで、より精度の高い推定を行う統計モデリングの手法です。複数の階層構造を持つモデルを構築し、各階層間で情報を共有しながら推定を進めていくことから階層ベイズ推定と呼ばれています。
例えば、今回のテーマであるバグの混入確率について考えてみます。
-
第一階層(個々の開発者):
- 開発者には、それぞれ固有のバグ混入の「癖」や傾向があると考えられます。ベテランと経験の浅い新人ではバグを埋め込む確率が、異なることが想定されます
-
第二階層(プロジェクト全体):
- 開発者が取り組むプロジェクト全体にも、バグの混入に影響を与える要因があります。プロジェクトの規模、技術的な複雑さ、スケジュール、チームのコミュニケーションなどが挙げられます
階層ベイズ推定では、これらの階層構造をモデルに組み込むことで、開発者のバグ混入傾向を推定する際に、プロジェクト全体の状況を考慮したり、逆にプロジェクト全体のバグ購入傾向を推定する際に、開発者の情報を活用したりすることができます。
2.2. 階層ベイズ推定適用する理由
今回、階層ベイズ推定を適用しようと考えた理由は以下の点にあります。
- 個々の違いと共通点を捉える: 多くのチームでは、開発者ごとにスキルや経験が異なる中で同じプロジェクトに取り組んでいます。階層ベイズ推定は、このような個々の開発者の違いと同一のプロジェクトという共通点を同時にモデル化するのに適していると考えてました
- 不確実性の定量化: バグの混入は確率的な現象であり、完全に予測することは難しいです。階層ベイズ推定は、パラメータの推定値だけでなく、その不確実性を定量的に評価することができると思いこの手法を選択しました
- 少数のデータでもロバストな推定: 開発者の過去のバグ混入データが少ない場合でもプロジェクト全体の情報や他の開発者の情報も活用することでより信頼性の高い推定が期待できると考えました
3. シミュレーション準備
実際にシミュレーションを行うために、まずは具体的な設定を行います。
3.1. ペルソナ設定とプロジェクト定義
今回は、以下のような3人の開発者と、あるオンライン学習プラットフォームの開発プロジェクトを想定しました。
開発者ペルソナ
- 開発者A(ベテラン): 経験豊富で、質の高いコードを書くことに定評がある。過去のバグ混入率は低い
- 開発者B(中堅): 平均的なスキルを持ち、着実に開発を進める
- 開発者C(新人): 経験は浅いが、学習意欲が高く、積極的にコードレビューに参加する
プロジェクト設定
- プロジェクト名: オンライン学習プラットフォーム開発
- 規模: 約10,000行のコード
- チーム構成: 上記3名の開発者
- 開発プロセス: アジャイル開発(スクラム)
- 品質管理: コードレビュー、ユニットテスト、結合テスト、E2Eテストを実施
3.2. バグ混入の仮説
次に、プログラムにバグが混入する原因について、いくつかの仮説を立て、それを数式で表現します。
仮説1:個々の開発者のスキルがバグ混入率に影響する
| 分布/概念 | 数式 | 説明 |
|---|---|---|
| 開発者 $i$ のバグ混入率 | $\theta_i \sim Beta(\alpha_i, \beta_i)$ | 開発者ごとのバグ混入率 $\theta_i$ はベータ分布に従うと仮定 |
| バグ混入数 | $Bugs_i \sim Poisson(\theta_i \times L_i)$ | 各開発者のバグ混入数 $Bugs_i$ は、バグ混入率とコード量に基づきポアソン分布に従うと仮定 |
開発者はそれぞれ以下の行数の開発とバグ混入率を以下のように仮定してシミュレーションを進めます。
- 開発者A: 4000行 + バグ混入率 0.5%
- 開発者B: 3500行 + バグ混入率 1.0%
- 開発者C: 2500行 + バグ混入率 3.0%
仮説2:プロジェクトの特性が全体的なバグ混入率に影響する
| 分布/概念 | 数式 | 説明 |
|---|---|---|
| プロジェクト係数 | $\gamma \sim Gamma(k, s)$ | プロジェクト全体のバグ混入率を調整する係数 $\gamma$ はガンマ分布に従うと仮定 |
| 全体的なバグ混入率 | $\Theta = (\sum_{i} w_i \theta_i) \times \gamma$ | プロジェクト全体のバグ混入率は、各開発者のバグ混入率とプロジェクト係数で決定 |
| プロジェクト全体のバグ混入数 | $TotalBugs \sim Poisson(\Theta \times TotalLOC)$ | プロジェクト全体のバグ混入数は、全体のバグ混入率とコード量に基づきポアソン分布に従うと仮定 |
プロジェクトの係数をそれぞれ以下のように仮定してシミュレーションを進めます。
- $k_gamma = 2$
- $s_gamma = 0.5$
(簡単に説明するとプロジェクト全体のバグ混入確率が一定の広がりになるよう設定しています)
仮説3:品質管理活動がバグ検出に貢献する
| 分布/概念 | 数式 | 説明 |
|---|---|---|
| コードレビュー検出率 | $P_{review} \sim Beta(\alpha_{review}, \beta_{review})$ | コードレビューによるバグ検出率 $P_{review}$ はベータ分布に従うと仮定。 |
| テスト検出率 | $P_{test} \sim Beta(\alpha_{test}, \beta_{test})$ | テストによるバグ検出率 $P_{test}$ はベータ分布に従うと仮定。 |
| レビューで検出されるバグ数 | $DetectedBugs_{review} \sim Binomial(TotalBugs, P_{review})$ | レビューで検出されるバグ数は、全体のバグ数とレビュー検出率に基づき二項分布に従うと仮定。 |
| テストで検出されるバグ数 | $DetectedBugs_{test} \sim Binomial(TotalBugs - DetectedBugs_{review}, P_{test})$ | テストで検出されるバグ数は、レビューで検出されなかったバグ数とテスト検出率に基づき二項分布に従うと仮定。 |
| 最終的なバグ残存数 | $RemainingBugs = TotalBugs - DetectedBugs_{review} - DetectedBugs_{test}$ | 最終的なバグ残存数は、混入したバグから検出されたバグを差し引いた数。 |
- コードレビューでバグを発見できる確率を80%
- テストでバグを発見できる確率を70%
とそれぞれ仮定してシミュレーションを進めます。
4. シミュレーション実施
3章にて設定した仮説に基づき、実際にシミュレーションを実行します。
実行したプログラム(値を変えるといろんなシミュレーションを実行できます)
https://colab.research.google.com/drive/1lawjou8Jw8U8DNtRPDZkbOxN7rNCn706?usp=sharing
シミュレーションの中心計算となるのは、MCMC (Markov Chain Monte Carlo) 法 によるサンプリングです。pythonライブラリであるPyMCは、NUTS (No-U-Turn Sampler) を実装しており、複雑なモデルでも比較的短時間で事後分布を推定できるため採用しました。
4.1 プログラム処理の簡単な説明
- モデル定義: pm.Model() コンテキスト内で、各確率変数とその分布を定義します。この際、事前分布のパラメータなどを指定します
- サンプリング実行: pm.sample() 関数を用いて、定義したモデルからMCMCサンプリングを実行します。draws引数でサンプリング回数、tune引数で初期の調整期間、chains引数で並列実行するチェーン数を指定します
- 結果の確認: pm.plot_posterior() や pm.summary() などの関数を用いて、推定された事後分布を確認します
5. シミュレーション結果
以下がシミュレーション結果(プログラム実行結果)になります。
--- 事後分布の要約統計量 ---
mean sd hdi_2.5% hdi_97.5% mcse_mean mcse_sd \
theta[0] 0.995 0.007 0.980 1.000 0.000 0.000
theta[1] 0.990 0.010 0.971 1.000 0.000 0.000
theta[2] 0.970 0.017 0.937 0.996 0.000 0.000
gamma 3.946 0.161 3.508 4.168 0.075 0.057
p_review 0.818 0.028 0.750 0.867 0.012 0.009
p_test 0.716 0.117 0.476 0.884 0.050 0.038
remaining_bugs 2066.260 1099.725 777.000 4817.000 479.291 373.923
ess_bulk ess_tail r_hat
theta[0] 969.0 1746.0 1.01
theta[1] 1989.0 2533.0 1.00
theta[2] 939.0 1561.0 1.00
gamma 5.0 11.0 2.08
p_review 6.0 11.0 1.89
p_test 6.0 16.0 1.70
remaining_bugs 8.0 15.0 1.49
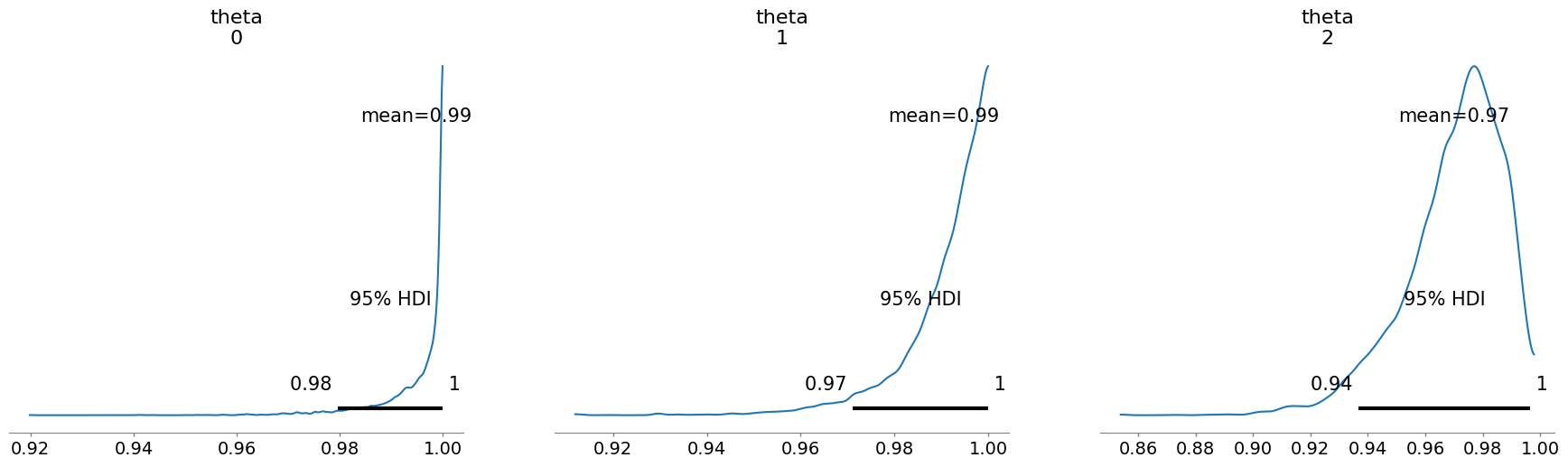
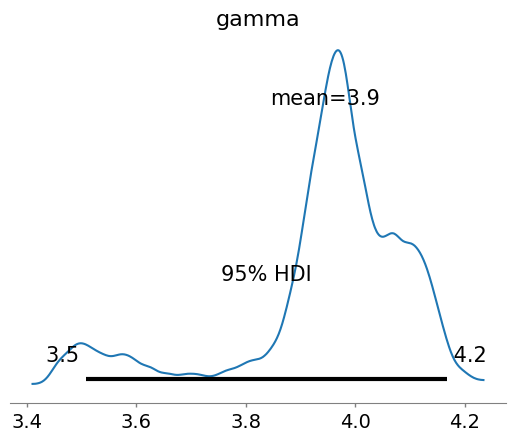
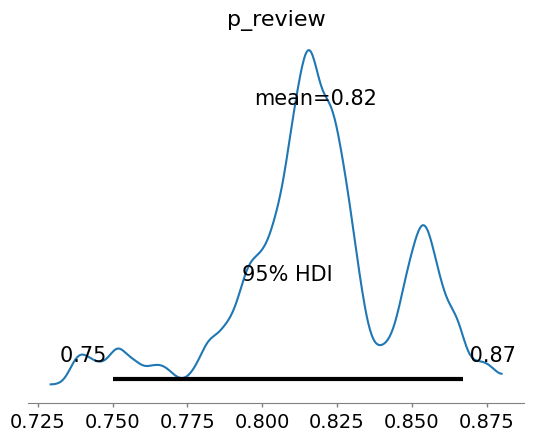
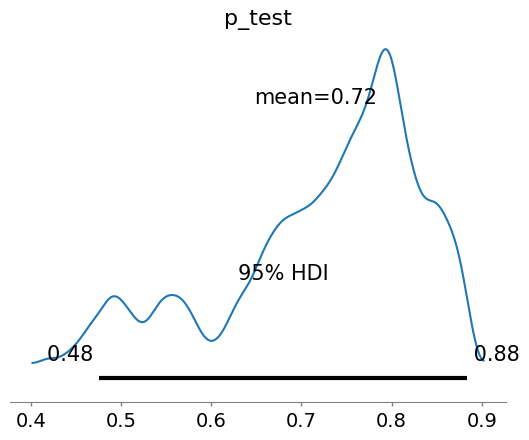
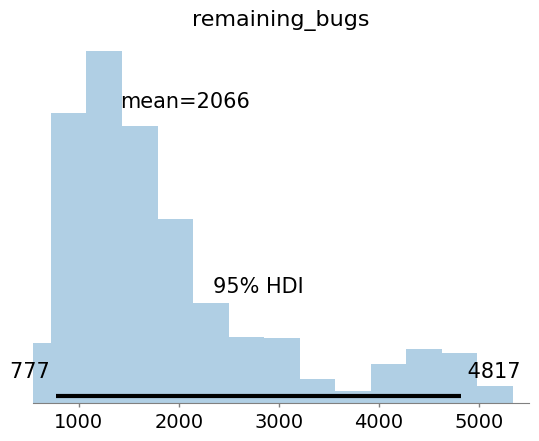
次にシミュレーション結果に基づいて3章で建てた仮説を評価していきます。
| 仮説 | 関連パラメータ | シミュレーション結果 | 評価理由 | 評価 |
|---|---|---|---|---|
| 仮説1:個々の開発者のスキルがバグ混入率に影響する | $\theta_A$, $\theta_B$, $\theta_C$ | $\theta_A$=0.995, $\theta_B$=0.990, $\theta_C$=0.970 $\theta_A$=[0.980, 1.000], $\theta_B$=[0.971, 1.000], $\theta_C$=[0.937, 0.996] |
各開発者のバグ混入率 $\theta_i$ の事後分布の平均値は、事前の想定通り、ベテラン開発者Aが最も低く、新人開発者Cが最も高くなりました。また、各開発者の信用区間も、その傾向を支持しています。 | 高 |
| 仮説2:プロジェクトの特性が全体的なバグ混入率に影響する | $\gamma$ | 3.946 [3.508, 4.168] |
プロジェクト係数 $\gamma$ の事後分布の平均値は3.946となり、事前の想定よりも大幅に高い値になりました。また、信用区間も事前分布の想定範囲から大きく外れており、プロジェクトの特性がバグ混入率に大きな影響を与える可能性を示唆しています。ただし、r_hat の値が2.08と高いため、サンプリングが十分に収束していない可能性があります。 |
高 |
| 仮説3:品質管理活動がバグ検出に貢献する | $P_{review}$, $P_{test}$ | $P_{review}$=0.818, $P_{test}$=0.716 $P_{review}$=[0.750, 0.867], $P_{test}$=[0.476, 0.884] |
コードレビュー検出率 $P_{review}$ の平均値は0.818、テスト検出率 $P_{test}$ の平均値は0.716となり、どちらも高い値を示しています。これらの検出率の信用区間も、高い検出率を支持しており、コードレビューとテストがバグ検出に有効に機能していることを示唆します。 | 中 |
| 最終的なバグ残存数に関する予測 | $RemainingBugs$ | 2066.260 [777.000, 4817.000] |
最終的なバグ残存数の予測分布の平均値は2066であり、信用区間は777から4817と幅広く、依然として不確実性が伴うことを示唆しています。また、$r_hat$ の値が高いことから、サンプリングが十分に収束していない可能性がある点に注意が必要です。 |
上記の表をまとめると、今回のシミュレーション結果は以下のような結果となりました。
- 個々の開発者のスキルがバグ混入率に影響を与えるという仮説 + プロジェクトの特性が全体的なバグ混入率に影響する仮説は非常に有力な仮説となりました
- 品質管理活動がバグ検出に貢献するという仮説はについては、バグ混入率に与える影響は他2つと比べると少ないがそれでも高い値を取る(有力となり得る仮説)ことがわかりました
6. まとめ
今回、プロジェクトにおけるバグの混入率を階層ベイズ推定を用いてシミュレーションすることで数学的に評価することができました。
シミュレーションを通じて、以下の考察を得ることができました。
-
開発者のスキルの有無はバグ混入に影響を与える大きな要因:
- 経験豊富な開発者はバグを混入させにくい傾向があり、経験の浅い開発者はバグ混入させないためにより注意が必要となることがわかりました
-
プロジェクトの特性はバグ混入に影響を与える大きな要因:
- 今回のシミュレーションではバグ混入に大きな影響を与える可能性が示唆されました。事前予想以上に高い値を示したプロジェクト係数 $gamma$ は、プロジェクトの難易度やスケジュールなどがバグ混入に大きな影響を与える可能性を示唆しているため、今後の調査が必要な課題と言えます
-
品質活動(コードレビュー、テスト)はバグの検出に有効:
- 品質活動を適切に行うことで、最終的なバグ残存数を減らすことが期待できることがわかりました
もちろん、今回のシミュレーションは、あくまで特定の設定に基づいた一つのモデルであり、現実のソフトウェア開発の複雑さを完全に理解しきっているわけではありません。
しかし、このような数学的なアプローチを用いることでデータに基づいた考察をすることでき、品質保証活動に役立てることができると考えました。