2022/10/29 追記・注意事項
執筆から1ヶ月半ほどですが、この記事の内容は既にだいぶ古いです。お絵描きAI進歩速すぎる。
Waifu Diffusionは1.3からpromptソートが無意味になり、アンダーバーも不要になり、
ていうかそもそもモデル何でもいいならNovel AIの流出モデルを使った方が比べ物にならないほど質がいいです。
アプリもNMKDは最新トレンドについてこれてないのでAutomatic web ui一択になってます。
もういちいち更新する気も起きないのでこの記事は当時の状況を記す歴史資料として残します。
最新情報は他の記事を当たってください。
前置き
この記事ではWaifu Diffusionを扱います。
意外と知らずに使っている方もいるようなのでここで念押ししておきますが、Waifu DiffusionはDanbooruという真っ黒もいいとこな無断転載天国サイトを学習データとして使っていると明言しており、使用者の立場によっては不適切とみなされ炎上したりこういうサイトを容認してるという意思表示とみなされるリスクがあります。微妙な立場の人はとりんさまモデルでも使ってた方が身のためですよ。
知ったこっちゃないという人はどうぞ。
目的
Stable Diffusionやその派生で欲しい絵を描くワークフローは既に色々出回ってますが、これらは元々絵を描ける人が補助ツールとして使う方法という側面が強いです。
棒人間すらまともにかけないヨドコロちゃんのようなカス画力の持ち主はPromptをいじり倒して呪文ガチャ1に祈るしかないのが黎明期のAI画でした。
しかし今やimg2imgが各種GUIアプリでも標準搭載されるに至り、我々の手の届くところにあります。
txt2imgとimg2imgを組み合わせれば、特定のキャラデザに似せて描くことだってできます。
この記事では画力一切不要でそれっぽい絵を作るためのノウハウを書いていきます。
用意するもの
- VRAMいっぱいのPC
- NMKD Stable Diffusion GUI https://nmkd.itch.io/t2i-gui
- Waifu Diffusionモデル https://huggingface.co/hakurei/waifu-diffusion
インストールについてはそのへんに解説があると思うので省略します。ていうか一目瞭然だから別に調べなくても普通に分かる。
よくあるエラーとして、NMKDがFileNotFoundExceptionで止まったらモデルのDL失敗だから手動で適当に代わりを用意して置いてから再実行すればいいです。
あと生成画像が緑一色になるやつはVRAMが足りないからLow memory modeにするべし。それでもだめならグラボを買え。
手順
以下の流れで作っていきます。
- 描きたい相手とシチュを決める
- 適合するタグをDanbooruで集める
- 集めたタグでpromptを作る
- 「惜しい絵」が出るまで呪文ガチャを回す
- 「惜しい絵」に加筆して各要素を正しくする
- 加筆した絵を元にimg2imgで再度呪文ガチャを回す
- (必要なら)要素をコラする
- 完成
描きたい相手とシチュを決める
相手というのは説明不要ですね。
シチュというのは表情、場所、時間帯みたいなフワッとしたレベルの話です。
細かいポージングとかは鬼門なので最初は諦めるべし。慣れてきたらPromptに入れてみて絶望しよう。
適合するタグをDanbooruで集める
シチュが決まったらDanbooruを開いて、それらの要素がDanbooruでどうタグ付けされているか調べてリストアップします。
タグはアンダースコア区切りの英単語です。オタクの言葉なので日本語のローマ字表記がそのまま使われている場合もあります。tsurimeとか。
親切なことにタグの定義までサイト内で見れるので悩むより入れてみた方が早いです。
たとえば「hair」と入れるとこんな感じで候補が出まくります。
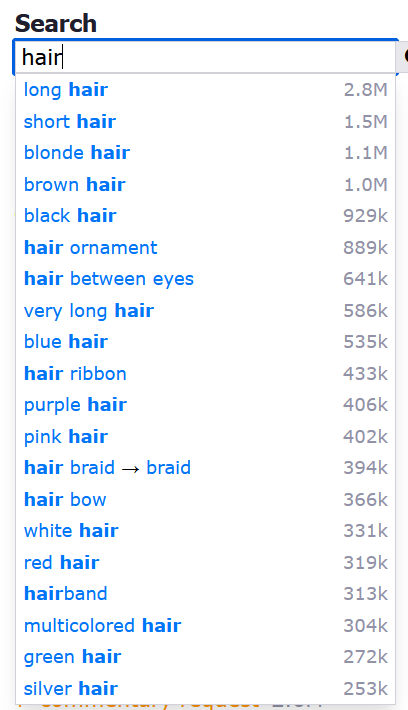
髪色、長さ、アクセサリーなど。一目瞭然ですね。右の数字はヒット件数で、この数字が大きいほど影響力があります。1000件未満のタグは入れてもほとんど効果が無いことが多いです。
どーしてもわからない場合はその要素を持ってる版権キャラで調べて、その絵についてるタグを見るとよいです。
こうして髪色、髪型、年齢、瞳の色、衣装、表情、感情、天候、場所、光の向きなど思い付く限りの情報をタグにして集めます。
集めたタグでpromptを作る
さて、材料は揃ったので呪文を作るわけですが、Waifuに関しては他のモデルとは全く異なる独自の指針があります。
以下のwikiに詳解があります(英語)
大事なとこだけ訳すと、このような順にソートせよということです。
[originalまたは作品タイトル][キャラ名(既存キャラを出す場合)][Danbooruのタグ][作者・作風]
かつ、各カテゴリ内ではアルファベット順にソートせよとあります。他のモデルでは「重要な情報ほど先頭に置け」が鉄則なので、性質が全く異なります。
この法則に基づいて、タグを並べ替えます。例えばこんな感じです。
original 1girl bangs bare_shoulders blush bowtie doyagao flat_chest fox_ears fox_tail full_body half-closed_eyes headdress loli looking_at_viewer long_hair neck_ribbon pink_bowtie pink_eyes pink_hair pink_sailor_collar sailor_collar sailor_shirt serafuku sleeveless smug squinting standing tsurime twintails white_jacket
originalは先頭に置きます。版権キャラでは作品名のタグが入ります。あとはアルファベット順にソートされたタグの羅列です。
絵柄や作風についても指示したい場合はこれらのタグの後ろに追記します。ミュシャとかのやつ。そっちはソートしなくてOKです。
実は並べ替えなくてもそれなりに期待通りの画は出ますが、顔面や手足の整合性は体感で分かるくらい悪くなります。打率は重要なのでサボらず並べ替えましょう。スプレッドシートに羅列しておいて自動でソートさせると楽。
「惜しい絵」が出るまで呪文ガチャを回す
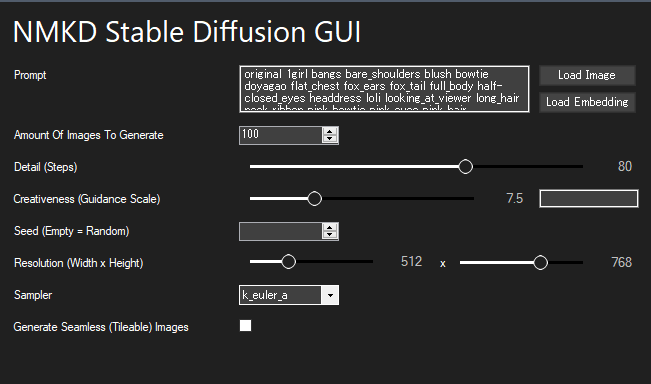
呪文ができたので、適当に100枚くらい回してみます。
20枚くらいで様子を見て、傾向に修正が必要そうなら直してまた回します。ここは基本と変わらないです。
ただし、このヨドコロちゃん式ワークフローの重要ポイントとして、この段階では整合性や色、細かい指定については反映されていなくてもいいものとします。
何故なら、このあと加筆して再度img2imgでAIに修正させるからです。
手の形が崩れてるとか、目が怖いとか、そういうのはスルーして、構図と大まかな「要望一致度」だけに注目します。
なので、「加筆で直せる修正」はスルーして、それ以外の項目だけに着目します。
「加筆で直せる修正」とは例えば以下の要素です。
- 髪や瞳の色がなんか違う
- 髪が長い、短い、ツインテが無い
- 服のパーツがおかしい
- 3本目の腕が生えてる、片腕しかない
こういうのはあとからどうにでもなるのでどーでもいいです。雰囲気を大事にしましょう。
最初はわからないと思いますが、このあとのimg2imgのプロセスを1度やってみれば次からは勘が働くようになるはずです。
何でも一発でうまくできることなんてないのでそこは練習です。数回やれば身に付くんだから絵の練習よりよっぽど楽ですよ。
ちなみにパラメタは適当ですが、うちはこんな感じにしてます。
「惜しい絵」に加筆して各要素を正しくする
で、「これだ!」という絵を見つけたら、加筆します。
例としてこんな絵が出たとします。

いい感じのメスガキですね。しかしこれが欲しかった絵かというと色々違います。描きたかった相手はこの人です。
っは~~~~~~~~~~~~~!!!!!!!!! かわよ

全身はこんな感じです。
比べてみると全然違います。

こういう気に入らない箇所が全部正しくなるまでガチャを回していると一生かかっても出ません。
しかし一生ガチャを回さなくてもいいように、img2imgが登場しました。
img2imgは、promptに加えて下絵となる画像もAIに読ませることでそれらしい絵を出させる機能です。
「下絵をどれくらい尊重するか」みたいなパラメタがあり、これを下げてAIの想像に任せ気味にすると適当な単色塗分けからいい感じの風景画を出すみたいなことができたりします。
逆に下絵をよく尊重するような設定で描かせると立ち絵の差分みたいな微妙な違いの類似画像を描かせまくることができます。今回はこれを利用します。
画力不要とか言っといて結局描くのかよ! と言いたい気持ちはわかりますが、要求されるレベルは棒人間を描く以下なので安心してください。
とりあえず加筆したものをお見せします。こうするのじゃ。

えー、挫折した方の絵下手マンでなく、そもそもフォトショもクリスタも触ったこと無い方の素人絵下手マンの場合、この画像を見て「めちゃくちゃ描いとるやん! 絵うまやん!!」と思うかもしれませんが、気のせいです。誰でもできます。
ここでペイントツールの使い方をだらだら書いてるとテンポが悪いので記事を分けました。
以下の記事を参考に雑に加筆してしまいましょう。
これで、めちゃくちゃ縮小してみた時になんとなくいい感じになっていればOKです。
拡大するとダメなのですが、遠目にはなんかちゃんと描けてるように見えます。これでOKです。
加筆した箇所の要点はこんな感じです。

見たまんまですね。1つだけ、画像サイズについて補足します。
AIに自由に描かせると、95%の確率で頭が見切れます。
これはもうAIの特性上どうしようもないです。呪文ではどうにもなりません。
なのでもう加筆する前提で最初から縦に少し小さい画像を作らせ、加筆する段階で足りない部分を描き足すとよいです。
うちのGPUでは512×768が限界なので、まず512×640で生成し、加筆する段階で512×768に拡張しています。
加筆した絵を元にimg2imgで再度呪文ガチャを回す
Load Imageボタンを押すと画像を選択できるので、加筆した絵を指定します。
するとimg2imgモードに切り替わります。
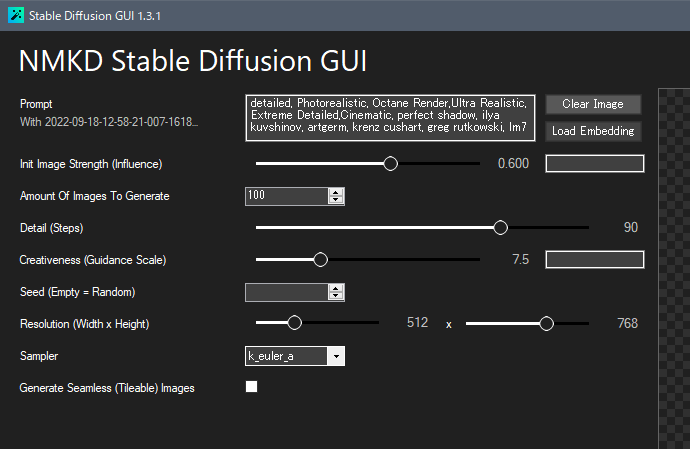
Influenceという項目が増えました。これが「元画像をどれだけ尊重するか度」です。0にすると完全に無視し、1にすると元画像がそのまま出るみたいな感じになります。
加筆修正の場合は0.600から始めて、結果を見ながら微調整するのがよいと思います。
加筆で塗りつぶして単色になった部分が多いほど、Influenceを下げてAIの方で補完してもらう必要があります。
promptはtxt2imgの時と同じままでよいです。また50枚ほど生成してもらって結果を見ましょう。

遠目にはあまり違いがわからない類似画像が大量に出てきました。しかし拡大すると全然違います。

たとえば左の子は襟の部分がリボンみたいになっちゃってますね。首周りの背景もおかしいしこれはNGですね。
右の子は表情がちょっと病みすぎです。空もなんかグラデが変になってるし。猫口も潰れちゃっててNGですね。
こんな感じでかなり惜しい画像が出まくります。しかしみんな似てるので50~100枚も出せば1枚くらいは当たりがあります。
同じ箇所が何度も「惜しい」になる場合は、加筆画像に戻って該当箇所をちょっと直すと改善します。

うーん……これでヨシということにしよう!
(必要なら)要素をコラする
二次創作の場合、キャラ固有のアクセやマーク入り衣装があるとそれこそガチャでは一生出ないですよね。
img2imgでもそれは同じなのでそこだけは手動でコラしてやる必要があります。

髪にロゴを入れてあげました。う~ん、これはもうめかにゃんこ様に違いない。
完成
以上です。
既にお気づきかと思いますが、この方法では「完璧」にはならないです。
この画像だって襟の線が微妙だし、鎖骨のところの布が無いし、スカートも本当はエプロンドレスなのにプリーツになってるし、そもそも髪型もなんか違う……。
うるせ~~~~!!!! しょーがねーだろ画力ゼロなんだから!!!!
余談ですがAIが絵描きの仕事を奪うとかいう話がいかにたわごとかよくわかりますね。真にAIを使いこなすには画力が必要なのは明白です。ただ全体のレベルが底上げされたに過ぎないってわけ。
そういうわけで我々素人は衣装再現とかはほどほどにしておいて、水着とかメイド服とか好き放題着せたりして道具の持ち味を生かすことを考えたほうが建設的だと思います。
さて、せっかくのファンアートなので描いてもらった絵を見てもらいましょう、相手によっては喜んでくれます。
好反応だった時、ありがとうなんて言われたときにはもうね……絵下手マンが一生届かないと思っていた種類の喜びが沸き上がってきて泣きそうになります。
喜んでくれなそうな相手には見せないでください。前置きの通り微妙なところがあるので。
一線は守るんじゃよ。
その他細かいノウハウ
背景は合成でもいい
背景や場面について指定しないと、のぺっとした立ち絵だけが出力されがち。
なので基本的に背景は何かしら指定したほうがいいのですが、衣装や髪型などでニッチな要素をpromptに入れるとなかなか反映されなくて、他のタグを削っていくとようやく少しずつ特徴が現れだす、みたいなことはままあります。
そういう場合、キャラ以外のタグをガッツリ削って立ち絵だけでまず作ってしまうというのも1つの方法です。
単色背景を透過してコラするのは簡単なので、綺麗な風景を描くのが得意な素のStable Diffusionに好きな背景を適当に生成してもらい、最後に立ち絵と重ねればよいです。
ライティングの整合性とかまで考えるともちろん良くはないのですが、終わらないガチャを回すよりはよっぽどマシです。

ヨドコロちゃん自身の肖像画。この背景はキャラとは別のprompt、別のモデルで生成したコラです。
そんなに気にならないよね?
呪文に悩んだらStepsを減らそう
Stepsは生成にかける処理の回数みたいなパラメタで、数値が小さいとノイズに近付き、大きいと細部まで精細になっていきます。
そして大きいほど生成にかける時間はどんどん長くなります。
思い通りの要素が出ずにpromptを試行錯誤している段階では、Stepsが大きいまま試行するのは時間の無駄です。
50くらいまで減らしてもpromptが持つ特徴は見えてくるので、まずはそれでpromptを決定するところまで進めましょう。
それからStepsを100とかにしていい絵が出るのを待つのです。
素人が無料ツールでうまいこと加筆する方法
記事の途中でもリンクしましたが、長くなるので記事を分けました。
これです。
みんなでお絵かきしてハッピーになろう。
おわり。
-
欲しい絵や構図が出るかどうかはpromptだけでなく運にも由来する。promptを変えながら欲しい絵が出るまで生成し続けるさまはまさしくガチャである。 ↩