開発環境
Windows10
Anaconda3 ( jupyter notebook )
説明と目的
ある大学生の卒論備忘録
テーマは、ニュースツイートにおいて、拡散されるものと拡散されないものの判別器を作るというものです。
今回は、その中でのTweet前処理(RT除外とURL削除)と私なりの拡散の定義を行っています。
前提条件
・MeCab ( NEologdの辞書適用 )環境設定済み
参考URL
・MeCabとNeologdの環境設定
https://www.pytry3g.com/entry/mecab-ipadic_neologd
・URL除去
https://labo.utsubo.tokyo/2017/07/11/post-1205/
・pandasのindex変換
https://stackoverflow.com/questions/51564266/pandas-convert-index-type-from-rangeindex-to-int64index
・前回の記事
https://qiita.com/YoJI/items/d2e4db094ae147b1bae4
1. 必要なライブラリをインポート
import pandas as pd
import MeCab
import re
import numpy as np
from matplotlib import pyplot as plt
2.Tweet_アカウント名.csvから読み込みと必要な列を作る
今回は、MeCab結果を入れるためのOwakati列を挿入しています。
読み込むデータは前回取得したlivedoornewsのデータです。
acount = "@livedoornews"
file_name = "../data/tweet_{}.csv".format(acount)
df = pd.read_csv(file_name,dtype={"tweet_no": "int64",
"time": str,
"text": str,
"favorite_count": "int64",
"RT_count": "int64"})
df.index = list(df.index)
df["Owakati"] = 0
df
Out[ ] 著作権等の関係があるため、ヘッダーのみの表示
| index | tweet_no | time | text | favorite_count | RT_count | Owakati |
|---|---|---|---|---|---|---|
| 0 | 00000000 | yyyy-mm-dd 時間:分:秒 | XXXXXX | xx | xx | 0 |
| ・read_csvのdtype | ||||||
| read_csvにおいて、各列のデータ型をdtypeで定義しているのは、無しで行うとpythonの自動判別のため、たまにint型をfloat型にしてしまったり、str型をint型にしてしまったりするためです。 | ||||||
| 自動でもdf.info()で上述と同じ型であれば、 | ||||||
| df = pd.read_csv(file_name) で大丈夫です。 | ||||||
| ・Owakatiの初期値には0を代入 | ||||||
| ・indexの再定義 | ||||||
| これは、IndexをRangeIndexからInt64Indexへ変更しています。次回以降の処理において、うまくいったデータセットがこれになっていたため、変更しています。これも自動でInt64Indexになっていれば必要ありません。 |
3. 前処理と分かち書き保存
# MeCab準備
# tagger = MeCab.Tagger('-Owakati') # 通常のMeCabはこちら
tagger = MeCab.Tagger(r'-Owakati -d C:NEologd辞書までのパス')
# URL削除 & 分かち書き保存 ※この他の前処理もここで行う
df = df[~df['text'].str.startswith('RT')] # RTを最初に含む行削除
df = df.reset_index(drop=True) # indexの修正
for index in df.index: # 一行ずつURLの削除
ret = re.sub(r"(https?|ftp)(:\/\/[-_\.!~*\'()a-zA-Z0-9;\/?:\@&=\+\$,%#]+)", "" ,df.iloc[index,2])
df.iloc[index,5] = tagger.parse(ret).strip()
df
Out[ ]: 著作権等保護のため、ヘッダーのみ表示
| index | tweet_no | time | text | favorite_count | RT_count | Owakati |
|---|---|---|---|---|---|---|
| 0 | 00000000 | yyyy-mm-dd 時間:分:秒 | XXXXXX | xx | xx | xx x x xx |
4. 拡散ツイートの定義
まず、普段どのくらいのRT数を稼いでいるのか、平均値・最小値・最大値とヒストグラムを表示して確認します。
# RTの最大値と最小値を表示
print("RT数")
print("最大値 : {:>6,}".format(df["RT_count"].max()))
print("最小値 : {:>6,}".format(df["RT_count"].min()))
print("平均値 : {:>6,.0f}".format(df["RT_count"].mean()))
Out[ ]:
RT数
最大値 : 62,239
最小値 : 24
平均値 : 2,124
"{}"の中身の:>6"は6マス右寄せを表しており、","はカンマ区切りで表示。"0f"は整数表示にしています。
※整数表示の丸め込みや四捨五入については以下のサイトを参考にしてください。
https://note.nkmk.me/python-round-decimal-quantize/
では、これをもとにヒストグラムをmatplotを用いて作ります
# ヒストグラム表示
x = np.array(df["RT_count"])
plt.hist(x,bins=100) # 100等分する
plt.title('Histgram')
plt.xlabel('RT_count')
plt.ylabel('Tweet')
plt.xlim(0, 45000)
plt.ylim(0,300)
Out[ ]:
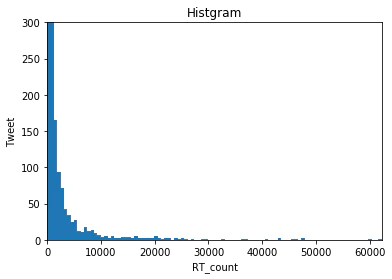
すると、5000RT~7000RTで凹みがあります。
では、0RT~5000RTを非拡散ツイートとし、7000RT~を拡散ツイートとしましょう。
※これらは暫定的であり、以後変更することもあります。
5. 拡散と判定されたデータの拡散判定を1とする
Buzz判定列を挿入し、そこに、7000RT以上稼いだものには1をたてます。
# df["Buzz"]を作成
df["Buzz"] = 0
# 拡散ニュースと通常ニュースの個数カウント & df["Buzz"]に1をいれる
count_usual = 0
count_buzz = 0
for index, RT in zip(df.index,df["RT_count"]):
if RT > 7000:
count_buzz += 1
df.iloc[index,6] = 1
else:
count_usual += 1
print("拡散ニュース数 : {}".format(count_buzz))
print("通常ニュース数 : {}".format(count_usual))
拡散ニュース数 : 144
通常ニュース数 : 1887
6. preprocessing_アカウント名.csvに保存
# save_file
save_file = "../data/finish_preprocessing_{}.csv".format(acount)
# 新規保存用
df.to_csv(save_file, index=False)
以上で、データセット作成と保存を終了です!
まとめと次回内容
今回の前処理は、RTの除去とURLの削除だけですので、必要に応じて前処理を随時追加していく予定です。
次回は、取得したツイートのTF-IDFを実装していきたいと思います。ついでにcosine類似度word2vecでロジスティック回帰を用いて簡単な判別を行う予定です。
※TF-IDFは取得した文書によって左右されすぎてしまい、安定した結果が得られないため、word2vecに変更しました。