はじめに
昨日学問バーで「機械学習で読み解く生命現象」という題でバーテンダーをやりましたが流行に迎合してLLMの話しかしなかったので忘れないうちにちょっとまとめておきます。
LLMとは?
これを読もうという人でいまさらLLMって何って人はいないとは思うのですが、この記事ではLLMとはBERT登場以降の「大規模な文字列の学習を穴埋め問題や2文連続問題みたいな人間がラベル付けを行わないデータを学習した基盤モデル」を指すとします。なのでLSTMみたいのは含まないし、また、表現学習を使って特定の機能予測(例えばm6Aが起きるのはどこの配列か、みたいな予測をあらかじめm6Aサイトを集めておいて負例も作って表現学習で予測器を作る)するみたいのは含まないとします。
ざっくり言ってつい最近出たこのプレプリに取り上げられているようなものをLLMとし、そのゲノム科学への応用を扱うことにします。具体的にはこのプレプリの以下の図にふくまれているようなもの、ということになります。
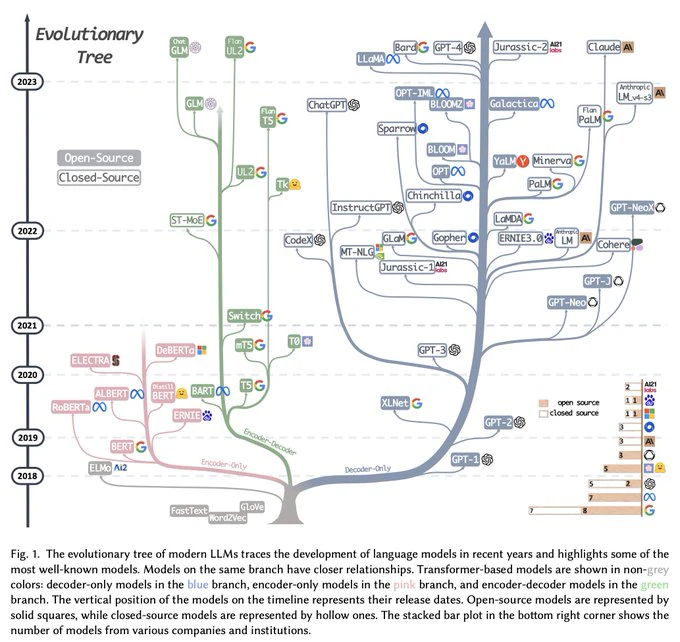
解説文書(英語)
現状、包括的なレビューはないんじゃないかなと思います(あったらすみません)。
- AI & Genomics: How transformers and large language models relate to biological data
- Take the DNA Delorean: The Promise of Large Language Models in Genomics
ちょっと気づいた感じだとこのあたりのふわっとしたエッセイしかない感じですね。
あといくつか日本語の説明と原著論文の組み合わせで
蛇足ですが前者はGPT型、後者はBERT型となります。プレプリの分類
| 特徴 | LLMs | |
|---|---|---|
| BERT型(エンコーダーのみ、または、エンコーダー+デコーダー) | (学習:穴埋め) (目的:判別) (タスク:穴埋め単語予測) | ELMo, BERT, RoBERTa, DistilERT, BioBERT, XLM, Xlnet, ALBERT, ELRCTRA, T5, GLM, XLM-E, ST-MoEe, AlexaTM |
| GPT型 デコーダーのみ | (学習:次単語作成) (目的:生成) (タスク:次単語予測) | GPT-3, OPT, PaLM, BLOOM, MT-NLG, GLaM, Gophermchnchilla, LaMDA, GPT-J, LLaMA, GPT-4, BlooombergGPT |
にもあるようにGPT型は生成に向いていてBERT型は判別に向いているのでそのような使わけになっているようです。
おわりに
別に包括的なレビューとかをかけるほどちゃんと調べたわけじゃないんですけどガチなLLMを塩基配列に使った話ってまだまだ少ない感じの印象だったので。重要な点としてはLLMってなんでうまくいくかよくわからないわけでだけどいろんなパフォーマンスがすごいわけですよね。つまり意味が解らなくても解析できる。人類はゲノム配列も意味わかってないので、「意味が解らない文章をなぜか解析できる」というLLMの性能は実はゲノム配列データに使うのにとても向いているのではと思いました。
深層学習は機能サイトの予測とか、創薬の予測なんかに盛んに使われてきたわけですが、LLMは特に目的を決めず全部文章を読んでしまってそれからファインチューニングで機能性を持たせるという使い方(←ここ大事)なわけですが、それが意味の分からない配列が膨大にあるゲノム配列の解析にちょっと向いているかもしれないな、と思った次第です。まちがっていたらすみません。