とある地域のワンルームマンションの適切な家賃を決定するために、
他の変数から精度の高い家賃予測ができるモデルをPythonで構築してみる。
使用するデータ
とある地域のワンルームマンションに関する41件のデータセット(souba.csv)
データセットの内容
id:物件id
rent:家賃(円)
area:面積( m2m2 )
age:築年数(年)
minutes:駅徒歩(分)
全体の流れ
1)データの下準備
2)データを色々な軸から把握する
3)特徴量の選択・モデル比較
4)モデルを学習・評価
実践
1)データの下準備
まずは、データを取り込み確認。
import numpy as np
import pandas as pd
import seaborn as sns
df = pd.read_csv("souba.csv")
df.head()
id rent area age minutes
0 1 4.3 13.00 26 6
1 2 4.2 14.35 35 5
2 3 5.0 15.60 33 9
3 4 4.5 13.09 32 5
4 5 4.6 12.92 38 7
分析に関係のない意味のない変数idは削除。
data = df.drop(["id"], axis = 1)
data.head()
rent area age minutes
0 4.3 13.00 26 6
1 4.2 14.35 35 5
2 5.0 15.60 33 9
3 4.5 13.09 32 5
4 4.6 12.92 38 7
訓練データとテストデータに7:3に分割する。
# 訓練データとテストデータに分割
X = data[["area", "age", "minutes"]].values
y = data["rent"].values
from sklearn.model_selection import train_test_split, cross_validate, KFold
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
X_train.shape, X_test.shape
((28, 3), (13, 3))
訓練データとテストデータそれぞれでDataframeを作成。
# Dataframeを作成
data_train = pd.DataFrame(X_train,columns = ["area", "age", "minutes"])
data_train["rent"] = y_train
data_test = pd.DataFrame(X_test,columns = ["area", "age", "minutes"])
data_test["rent"] = y_test
2)データを色々な軸から把握する
まずは、訓練データを可視化してみる。
可視化の目的は、
①全体のデータの関係性をざっと把握すること
②外れ値を見つけること
sns.pairplot(data_train)
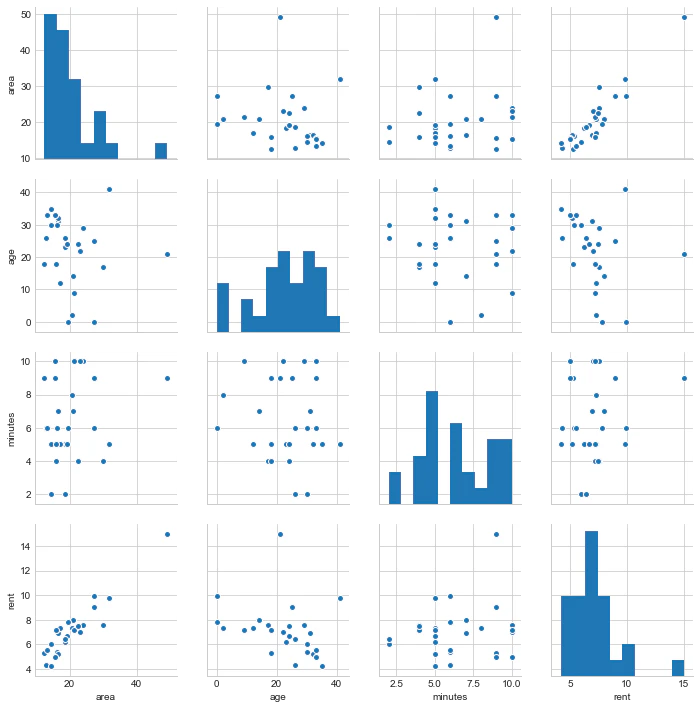
rent(家賃)とその他の変数の関係をみてみると、
・area(面積)は相関がありそう
・minutes(駅徒歩)はareaほどではないが弱い相関がありそう
・age(築年数)は逆相関に近そう
ということが読み取れる。
areaでひとつだけ外れ値があるので、除外しておく。
# 外れ値の対応
data_train = data_train.query("area < 40")
sns.pairplot(data_train)
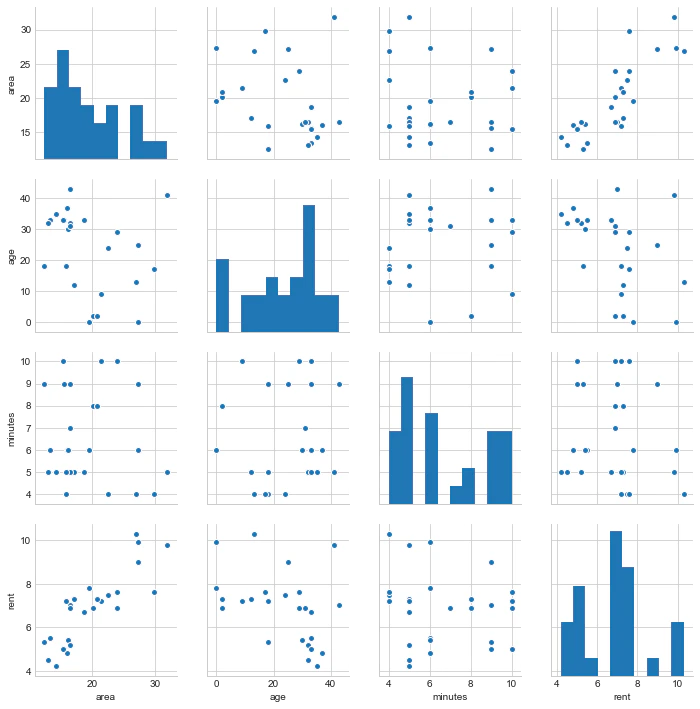
続いて相関係数を計算してみる。
data_train.corr()
area age minutes rent
area 1.000000 -0.148793 0.207465 0.925012
age -0.148793 1.000000 -0.088959 -0.315480
minutes 0.207465 -0.088959 1.000000 0.154623
rent 0.925012 -0.315480 0.154623 1.000000
rentと各変数の相関をみると、
areaは非常に相関が高いがageは弱い逆相関、minutesはほぼ相関はなし。
以上より。area>age>minutesの順に特徴量としてとるのがよさそう。
3)特徴量の選択・モデル比較
【ポイント】
・モデル選択は必ず訓練データのみで実施すること
まず、説明変数が全変数の場合の線形回帰モデルをつくってみる。
ここでは、3-fold cross validationを使います。
X_train = data_train[["area", "age","minutes"]].values
y_train = data_train["rent"].values
LR = LinearRegression()
res_1 = cross_validate(LR, X = X_train, y = y_train, scoring = "r2", cv = KFold(n_splits = 3, shuffle = True), return_train_score = True)
res_1
# スコア
{'fit_time': array([0. , 0.00254989, 0.00099754]),
'score_time': array([0.00401378, 0. , 0. ]),
'test_score': array([-0.11587073, 0.67717773, 0.65301948]),
'train_score': array([0.96132849, 0.66332986, 0.90608152])}
次に、説明変数から駅徒歩を除いた線形回帰モデルをつくってみる。
X_train = data_train[["area", "age"]].values
y_train = data_train["rent"].values
LR = LinearRegression()
res_2 = cross_validate(LR, X = X_train, y = y_train, scoring = "r2", cv = KFold(n_splits = 3, shuffle = True), return_train_score = True)
res_2
# スコア
{'fit_time': array([0.00318336, 0.0009973 , 0.0010891 ]),
'score_time': array([0. , 0.00185704, 0. ]),
'test_score': array([0.32138226, 0.87606109, 0.83912145]),
'train_score': array([0.94496232, 0.88506422, 0.80168397])}
それぞれのtest_scoreを比較すると、
説明変数から駅徒歩を除いた後者のモデルの方が決定係数が高いため、これをモデルとして採用することにする。
4)モデルを学習・評価
特徴量をarea,ageとして、モデルを学習する。
X_train = data_train[["area", "age"]].values
y_train = data_train["rent"].values
LR = LinearRegression()
LR.fit(X_train, y_train)
作ったモデルにテストデータでを入れて、精度を検証する。
X_test = data_test[["area", "age"]].values
y_test = data_test["rent"].values
y_pred = LR.predict(X_test)
r2_score(y_true = y_test, y_pred = y_pred)
# モデル評価
0.8623439786705054
結果、テストデータでの決定係数が0.8以上になったため、
それなりの精度が出るモデルといえそうである。