はじめに
とあるWebサーバーのログを解析していますが、与えられたログファイルのフォーマットはCommon Log Format(CLF)とも微妙に違うフォーマットではあるもののApache(NCSA)ベースのログなのでCLFに変換をして使うことにしました。
2003年頃の話しなのでまだ社会人3年目だった頃の話しですが、仕事で某大企業のWebサーバーのアクセスログを解析しなければならなくなりました。まだExcelでは65536行の限界があったり、ノートPCの主記憶が64MB、HDDが20GBぐらいだった時代なので、毎日1GBぐらいになるログファイルの解析は工夫する必要があったわけです。
学生時代はWebサーバーのログ解析は、主に日本語化したWebalizerに任せていたのですが、注文は特定のエラーの頻度を調べること、処理に時間がかかったリクエストの抽出だったので、Webalizerを使うわけにもいかず手製のパーサーとRRD Toolを使ってJPEG画像を日毎、週毎、月毎に生成するスクリプトを作った事を思い出します。
そもそもオリジナル版のWebalizerは32bitだったので、アクセス数が多いと簡単にオーバーフローしてしまうのでした。
その仕事は週末の時間を使ってプロトタイプを作成してから、グラフを毎日生成する仕事に移行するまで1週間ぐらいだったと思います。Webログファイルの解析は、いろいろ懐しさを覚えます。
さて、ひさしぶりにWebalizerがまだUbuntuのパッケージにあることに感動を覚えつつ、アクセス元の解析を行ないたかったので、GeoIP2/GeoLite2に対応しているStoneStepsWebalizerを利用してみることにしました。
参考資料
主な課題
Google Analyticsのようなツールでも悪くないのですが、手元にあるログファイルを元に情報を生成したいニーズは一定あると思います。
今回、StoneStepsWebalizerを利用する主な理由は以下のとおりです。
- 手元にあるWebサーバーのアクセスログを元に解析を始めたい
- いくつかのサーバーのログを統合して処理をしたい
- 特定のアクセス先に注目して処理を行いたい
- イベントページだけを抽出して処理したい
- 日本語版・英語版の比較をしたい
- 特定のアクセス元毎に処理を行いたい
- 自組織からのアクセスのみを or 自組織外からのアクセスを除いて、処理したい
- 特定のCrawlerについて、これを除いて or これに注目して、処理したい
- IPアドレスから国別のアクセスを抽出したい (GeoIP2を利用したい)
- GeoIP2/Cityを(可能であれば)使いたい
- ちゃんと64bit化されている!! (これはとても大事)
後出しジャンケンのような条件が追加されると、Google Analyticsのようなツールに依存していると対応できないことや、対応がものすごく難しくなることがあるかもしれません。
人間の役割は比較できるデータを抽出したり、User-Agentを偽装してくるようなCrawlerを除外するルールを考えることで、これらもAIが得意そうですが、グラフの作成自体は本質的なことではないので、webalizerに任せることにしました。
StoneStepWebalizerの使い方
添付されているwebalizer.confは通常のwebalizerのものです。
基本的な使い方は昔のwebalizerと同じですので、他の適当なリソースを参照してください。
コマンドラインオプションに頼らずにwebalizer.confを使う場合に最低限編集しなければいけない項目は次のとおりです。
webalizer.confの設定
- LogFile "input web server log filepath"
- HostName "FQDN of the target web server name"
- DNSCache "DNS cache filepath"
- DNSChildren "Number of process to perform the DNS lookup job"
- DNSLookups no
- ASNDBPath ./geolite2/GeoLite2-ASN.mmdb
- GeoIPDBPath ./geoip/GeoLite2-Country.mmdb
LogFile
入力に渡すCLF形式のログファイルを指定します。相対パスでも絶対パスでも大丈夫ですし、gzip形式で圧縮されていれば展開する必要はありません。
## カレントディレクトリに"access_log.gz"ファイルがある場合
LogFile access_log.gz
HostName
出力するWebブラウザに表示するテキストを指定します。
そのためFQDNでなくても、適当な文字列を指定すればindex.htmlを見た時に何のログかすぐに分かります。
DNSCahce
GeoIP2/GeoLite2を利用する場合には必ず、任意のファイル名を指定します。
DNSCache dns_cache.db
DNSChildren
子プロセスの数を指定します。DNS Lookupを行なわなくても、0にしているとDNS初期化エラーとなります。
libmaxminddbの処理がpthreadに対応しているか確認していませんが、GeoIP2/GeoLite2関連の処理も個々のスレッドで処理されるようになっているので、適切な数を指定すれば性能は上がるはずです。
DNSLookups
これをONにするとアクセス元のIPアドレスをホスト名に変換します。一般的なインターネットサイトの場合には、逆引きできないホストからのアクセスも相当数はるはずなので、イントラネットサイトでない限りは、noにすることをお勧めします。
ASNDBPath / GeoIPDBPath
MaxMind社製のGeoIP2 Databaseを指定します。無料のGeoLite2も問題なく利用できるので、ASNDBPathは指定するとIPアドレスが適当な粒度のグルーピングされるので利用すると良いと思います。
GeoIP2/GeoLite2を利用する際の注意点
特にDNSCacheは指定しない場合にはGeoIPDBPathの処理だけが行なわれるように書かれていますが、実際にはDNSCacheの設定は必須です。DNSLookup no を設定に加えることでDNSサーバーへのアクセスは抑制され、GeoIP2/GeoLite2関連の処理だけがローカルで行われるようになります。
Stone Steps Webalizerのビルドと利用
UbuntuでBuildするために次ようなパッケージを導入しています。
libgd-dev
libmaxminddb-dev
libdb++-dev
zlib1g-dev
この状態でStoneStepWebalizerをgit cloneしてmakeするだけで、build/webalizer が構成されます。
$ git clone https://github.com/StoneStepsInc/StoneStepsWebalizer.git
$ cd StoneStepsWebalizer
$ make
$ ./build/webalizer --version
Stone Steps Webalizer v6.3.0 build 0 (Linux 5.15.0-47-generic) English
Copyright (c) 2004-2022, Stone Steps Inc. (www.stonesteps.ca)
This program is based on The Webalizer v2.01-10
Copyright 1997-2001 by Bradford L. Barrett (www.webalizer.com)
sswebalizer.conf の構成
デフォルトの設定も含めえ、空行とコメントアウトを除いた設定ファイルは次のようになっています。
複数の設定ファイルを準備しているので、webalizer.confの名前は使わずにsswebalizer.confとしています。
カレントディレクトリにwebalizer.confが存在すると、暗黙に読み込まれてしまいます。
-c オプションで指定するファイルの設定と衝突する可能性があるので注意してください。
LogFile ./access_log.gz
LogType clf
OutputDir webalizer/
HostName www.example.com
PageType htm*
PageType cgi
DNSCache dns_cache.db
DNSChildren 20
HideURL *.gif
HideURL *.GIF
HideURL *.jpg
HideURL *.JPG
HideURL *.png
HideURL *.PNG
HideURL *.ra
SearchEngine yahoo.com p=
SearchEngine google.com q=
SearchEngine bing.com q=
SearchEngine lycos.com query=
SearchEngine hotbot.com MT=
SearchEngine infoseek.com qt=
SearchEngine webcrawler searchText=
SearchEngine excite search=
SearchEngine mamma.com query=
SearchEngine alltheweb.com query=
ASNDBPath ./geolite2/GeoLite2-ASN.mmdb
TopASN 30
DumpASN yes
GeoIPDBPath ./geoip/GeoLite2-Country.mmdb
GeoIPCity no
TopCities 30
DNSLookups no
OutputFormat json
OutputFormat html
このファイルを指定して、webalizerを起動します。
先ほどビルドしたwebalizer (StoneStepsWebalizer/build/webalizer) を、カレントディレクトリにコピーしています。
必ずOutputDirで指定するディレクトリを作成しておいてください。
$ mkdir webalizer
$ ./webalizer -c sswebalizer.conf
無事に処理が終わるとOutputDirに指定したディレクトリにファイル一式が生成されます。
CSS, JavaScriptファイルの配置
CSS, JavaScriptファイルは配置されないため、リポジトリから以下のファイルをOutputDirにコピーする必要があります。
- webalizer.css
- webalizer.js
- webalizer_highcharts.js
ファイルは、git cloneをした StoneStepsWebalizer/src/ 以下に3つとも配置されています。
GitHubのReleasesページからバイナリをダウンロードした場合には、src/ディレクトリにこの3つのファイルだけが残されています。
これらのファイルをコピーすると、index.htmlをWebブラウザで開くと、センタリングされた見栄えの良いページが表示されます。
WebサーバーのログファイルをCLFに変換する
標準的なApacheのcombined形式ではないけれど、限りなく似ているフォーマットの場合には、Pythonのapache-log-parserが便利でした。とはいえ特殊な表現を使っていない**%aや%A**で受け指定すると、IPアドレスしか受け付けないので、"-"やホスト名が書かれている場合にはエラーになってしまって使えません。。任意の文字列を受け取る時には、一箇所だけしか使えませんが、 %R を使って凌ぎました。
もっと特殊であればPEG等で字句・構文解析器を作ることになるでしょう。
一部テーブルのパーセント表記がゼロになる問題について
適当なaccess_logを作成してmasterブランチでmakeしたwebalizerを使うと次のように転送量(Transfer)のパーセント表示が全てゼロになる現象に遭遇しました。
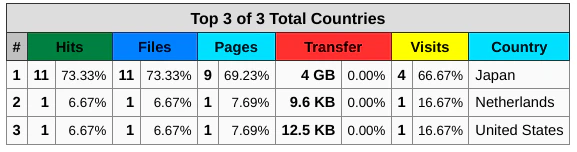
他のテーブルでもTransferやVisitsで同様の問題が発生するので、以下のようなパッチを作成してGitHub上ではpull requestを上げています。(Pull Request#14)
diff --git a/src/html_output.cpp b/src/html_output.cpp
index 1450c6d..0977f91 100644
--- a/src/html_output.cpp
+++ b/src/html_output.cpp
@@ -1293,7 +1293,7 @@ void html_output_t::top_hosts_table(int flag)
hptr->files, (state.totals.t_file==0)?0:((double)hptr->files/state.totals.t_file)*100.0,
hptr->pages, (state.totals.t_page==0)?0:((double)hptr->pages/state.totals.t_page)*100.0,
hptr->xfer, fmt_xfer(hptr->xfer),
- (state.totals.t_xfer==0)?0:(hptr->xfer/state.totals.t_xfer)*100.0,
+ (state.totals.t_xfer==0)?0:((double)hptr->xfer/state.totals.t_xfer)*100.0,^M
hptr->visits,(state.totals.t_visits==0)?0:((double)hptr->visits/state.totals.t_visits)*100.0,
hptr->visit_avg/60., hptr->visit_max/60.);
@@ -1705,7 +1705,7 @@ int html_output_t::all_urls_page(void)
unode.count,
(state.totals.t_hit==0)?0:((double)unode.count/state.totals.t_hit)*100.0,
unode.xfer, fmt_xfer(unode.xfer, true),
- (state.totals.t_xfer==0)?0:(unode.xfer/state.totals.t_xfer)*100.0,
+ (state.totals.t_xfer==0)?0:((double)unode.xfer/state.totals.t_xfer)*100.0,^M
unode.avgtime, unode.maxtime,
html_encode(unode.string.c_str()));
}
@@ -1736,7 +1736,7 @@ int html_output_t::all_urls_page(void)
unode.count,
(state.totals.t_hit==0)?0:((double)unode.count/state.totals.t_hit)*100.0,
unode.xfer, fmt_xfer(unode.xfer, true),
- (state.totals.t_xfer==0)?0:(unode.xfer/state.totals.t_xfer)*100.0,
+ (state.totals.t_xfer==0)?0:((double)unode.xfer/state.totals.t_xfer)*100.0,^M
unode.avgtime, unode.maxtime,
unode.get_url_type_ind());
@@ -3237,7 +3237,7 @@ void html_output_t::top_ctry_table()
ccnode.pages,
(t_page==0)?0:((double)ccnode.pages/t_page)*100.0,
ccnode.xfer, fmt_xfer(ccnode.xfer),
- (t_xfer==0)?0:(ccnode.xfer/t_xfer)*100.0,
+ (t_xfer==0)?0:((double)ccnode.xfer/t_xfer)*100.0,^M
ccnode.visits,
(t_visits==0)?0:((double)ccnode.visits/t_visits)*100.0,
ccnode.ccode.c_str(),
@@ -3306,9 +3306,9 @@ void html_output_t::top_city_table()
ctnode.pages,
(state.totals.t_page==0)?0:((double)ctnode.pages/state.totals.t_page)*100.0,
ctnode.xfer, fmt_xfer(ctnode.xfer),
- (state.totals.t_xfer==0)?0:(ctnode.xfer/state.totals.t_xfer)*100.0,
+ (state.totals.t_xfer==0)?0:((double)ctnode.xfer/state.totals.t_xfer)*100.0,^M
ctnode.visits,
- (state.totals.t_visits==0)?0:(ctnode.visits/state.totals.t_visits)*100.0,
+ (state.totals.t_visits==0)?0:((double)ctnode.visits/state.totals.t_visits)*100.0,^M
ctnode.ccode.c_str(),
html_encode(state.cc_htab.get_ccnode(ctnode.ccode).cdesc.c_str()),
ctnode.geoname_id(),
@@ -3376,9 +3376,9 @@ void html_output_t::top_asn_table()
asnode.pages,
(state.totals.t_page==0)?0:((double)asnode.pages/state.totals.t_page)*100.0,
asnode.xfer, fmt_xfer(asnode.xfer),
- (state.totals.t_xfer==0)?0:(asnode.xfer/state.totals.t_xfer)*100.0,
+ (state.totals.t_xfer==0)?0:((double)asnode.xfer/state.totals.t_xfer)*100.0,^M
asnode.visits,
- (state.totals.t_visits==0)?0:(asnode.visits/state.totals.t_visits)*100.0);
+ (state.totals.t_visits==0)?0:((double)asnode.visits/state.totals.t_visits)*100.0);^M
fputs("<td class=\"stats_data_item_td\">", out_fp);
if(asnode.nodeid)
これを適用してビルドすると無事に正しい結果を表示してくれるようになりました。
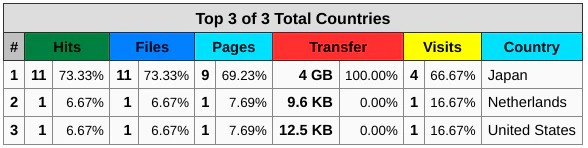
Bot/Crawlerにみられる特徴的な挙動
ログを確認していると、User-Agentを正しく設定していない通常のブラウザーを装っているものもあります。Seleniumなどによるブラウザ自動化の可能性もありますが、多くのスクリプトによるCrawlingはcssやjavascriptなどのファイルを読み込まないか、画像ファイルなどだけにアクセスするといった挙動に特徴があります。
Webalizerでみると、HitsとPagesの項目がほぼ変動しないなどの特徴が確認できたり、あらかじめキャッシュした情報を元に画像ファイルだけを巡回しているとPages数がほぼゼロに貼り付くといったアクセスが確認できます。
場合によっては再帰的にWebアプリケーションを巡回する場合もありますので、robot.txtを適切に配置することは自己防衛として最低限できることだと思います。
'OutputFormat JSON' と 'OutputFormat HTML' を指定すると、HTML出力に加えて集計結果をJSONファイルでも出力してくれます。この条件に合うようなHostを抜き出そうとするスクリプトは次のように作成することができます。
#!/usr/bin/ruby
# Usage: ./check_bots_byhost_json.rb webalizer/host_2022*.json
require 'json'
require 'csv'
result = {}
for json_file in ARGV
open(json_file) do |f|
JSON.load(f).each do |data|
next unless data.has_key?("hits") and data.has_key?("pages")
hits = data["hits"]["$numberLong"].to_i
pages= data["pages"]["$numberLong"].to_i
next if ((hits-pages) / hits.to_f) > 0.15 ## skip if over 15% diffs
next if hits < 1000
print [data["ipaddr"], hits, pages].to_csv
end
end
end
まだ作りかけでいろいろ足りていませんが、とりあえず動いてはくれます。
$ ./check_bots_byhost_json.rb webalizer/host_2022*.json | awk -F, '{print $1}' | sort | uniq
xxx.xxx.xxx.xxx
....
remote_hostと出力結果をリストにしたオブジェクトと比較することで、Bot/Crawlerのログと、それ以外を区別して、それぞれのログと結合したログをWebalizerで処理することで全体と各アクセスの特徴を比較しています。
usage_*.jsonファイルの誤りについて
json_output.cppファイルの他の部分では対応できているのですが、おそらく項目を追加したタイミングで最後の要素に不要な","を付けてしまったJSONファイルが生成されるバグがあります。
この問題は以下のようなパッチで対応できます。
diff --git a/src/json_output.cpp b/src/json_output.cpp
index 730e22b..789b087 100644
--- a/src/json_output.cpp
+++ b/src/json_output.cpp
@@ -260,9 +260,9 @@ void json_output_t::dump_totals(void)
fprintf(out_fp,"\"files\": {\"avg\": %.6f, \"max\": {\"$numberLong\": \"%" PRIu64 "\"}},\n", (double) state.totals.t_file/state.totals.t_visits, state.totals.max_v_files);
fprintf(out_fp,"\"pages\": {\"avg\": %.6f, \"max\": {\"$numberLong\": \"%" PRIu64 "\"}},\n", (double) state.totals.t_page/state.totals.t_visits, state.totals.max_v_pages);
fprintf(out_fp,"\"xfer\": {\"avg\": %.6f, \"max\": {\"$numberLong\": \"%" PRIu64 "\"}},\n", (double) state.totals.t_xfer/state.totals.t_visits, state.totals.max_v_xfer);
- fprintf(out_fp,"\"duration\": {\"avg\": %.6f, \"max\": %.6f},\n", state.totals.t_visit_avg/60., state.totals.t_visit_max/60.);
+ fprintf(out_fp,"\"duration\": {\"avg\": %.6f, \"max\": %.6f}", state.totals.t_visit_avg/60., state.totals.t_visit_max/60.);
if(state.totals.t_visits_conv)
- fprintf(out_fp,"\"duration_converted\": {\"avg\": %.6f, \"max\": %.6f}\n", state.totals.t_vconv_avg/60., state.totals.t_vconv_max/60.);
+ fprintf(out_fp,",\n\"duration_converted\": {\"avg\": %.6f, \"max\": %.6f}\n", state.totals.t_vconv_avg/60., state.totals.t_vconv_max/60.);
fputs("}\n", out_fp);
}
このコードもpull requestを出したいと思います。
またJSONファイルが正しいフォーマットかどうか確認するのは、pythonのjsonモジュールを使うと便利です。
$ python3 -m json.tool hoge.json
正しくパースできれば整形されて標準出力に書き出されますが、問題があった場合には、エラーメッセージが表示されます。
$ python3 -m json.tool hoge.json
Expecting property name enclosed in double quotes: line 30 column 1 (char 922)
これは連想配列の最後の要素の末尾にカンマ(,)を付けてしまった場合です。
[
{ "key1": "value1" },
{ "key2": "value2" }, ## <- この行末尾のカンマ(,)が不要
]
$ python3 -m json.tool foo.json
Expecting value: line 1 column 47 (char 46)
トップページのDaily Averageが正しくない
Webalizerの平均値を出す際の母数は、経過時間数です。そのためMonthly Totalsから日数の(例えば9月なら)"30"で割った場合には数値が一致しない場合があります。毎日、24時間アクセスが途絶えなければ、30日の場合には24時間を掛けた"720"が母数になります。もし、アクセスのない時間帯があった場合には、母数が720よりも小さくなり、日毎の平均という数値からは乖離した数字が出力されます。
平均値は、(n1 + n2 + ... + nN) / N のような式で表現されますが、これを展開すると、n1/N + n2/N + ... + nN/Nのような形になるわけです。Webalizerの場合には、条件によって、n1/N + n2/(N-2) + ... + nN/N のように母数が変化するアルゴリズムになっているので、24/7 アクセスがないWebサイトのログについて、トップページのDaily Averageは一般的な認識とは異なるものになります。
全般的にWebalizerは便利ですが、出力の見方については少し注意が必要です。
他にもTop Entry URLsのようなリストのVisitsの数とその割合は何を母数としているのか、戸惑う場面があるかもしれません。基本的に各テーブルに出力されているデータは、各テーブル毎に個別に集計を行っています。Top Entry URLsについていえば、Entry URLsとして計上されている全体の一部を母数として、その割合などが表示されています。
PNGファイルで出力される画像についていえば、積算値だけなので、こういった問題はないはずです。
まとめ
Stone Steps Webalizerはドキュメントは揃っていますが、適切なオプションを選ぶためには、コードも確認する必要がまだ多少は残っています。
文書化されていないオプションは現在ではまずないと思いますが、各オプションの実際の挙動はコードを念のため確認することをお勧めします。
例えば、ドキュメントだけではHit数と、Files数の違いを説明することは少し難しいです。コード上では、Hit数からRC_NOMODフラグを除いたアクセス数が、Files数に計上されます。
RC_NOMODは、304コード(Not Modified)に該当するので、Files数は実際にファイル転送が発生したアクセス数を表します。これは206コード(Partial Content)を含みますので、実際のファイルへのアクセスを全て含む事になります。Pages数からは206コードに該当するものがさらに省かれ、この他にPDFファイルなどのいわゆる"ダウンロード"も除外されます。
一般的なユースケースではGoogle Analyticsで十分だと思いますが、v4に移行してどうなるか見えない部分もありますし、手元でWebサーバーのログファイルを解析できることはGoogle Analyticsの結果を検証することもできるにもなりますので、そういったログ解析にwebalizerは完璧ではないですが手軽な自分用のツールとして使えると思っています。
以上