この記事は ゆる言語学ラジオ非公式 Advent Calendar 2022 - Adventar の8日目の記事です。
はじめに
ゆる言語学ラジオという、「ゆるく楽しく言語の話をする」というコンセプトのYoutubeチャンネルにハマってしまい、あっという間に1年ほど経ちました。
いつの間にか「ゆるコンピュータ化学ラジオ」や「ゆる学徒ハウス」などといった派生系が生まれ、動画の数は今や200を超えています。
そんな中「あの話、どの回だっけ?」となることが増えてきました。
そこで、「検索できるサイトを作っちゃおう!どうせなら言語学っぽく、形態素解析もしてコーパスにしちゃおう!」くらいのノリで2ヶ月ほど前から作り始めました。
この記事では、現時点での経過をまとめていきます。
インフラなど
フロントエンドはNex.jsをVercelにデプロイしています。
バックエンドはFlaskAPIをAWS Lambda上に立て、HTTP API Gateway経由で叩いています。
機能説明
完成系では、以下のような機能を予定しています。
- 全動画の文字起こしデータの閲覧
- 字幕データの閲覧
- だれでも上記データを修正可能にする
- 発話の形態素解析
- 特定の単語の出現箇所の検索
現状ある機能はいたってシンプルで、大きく分けて2つのみです
- ゆる言語学ラジオ初回~生成文法回までの文字起こしの閲覧、編集
- 形態素解析を用いない、完全一致の検索
1. 文字起こしの閲覧、編集
UIはこんな感じです。
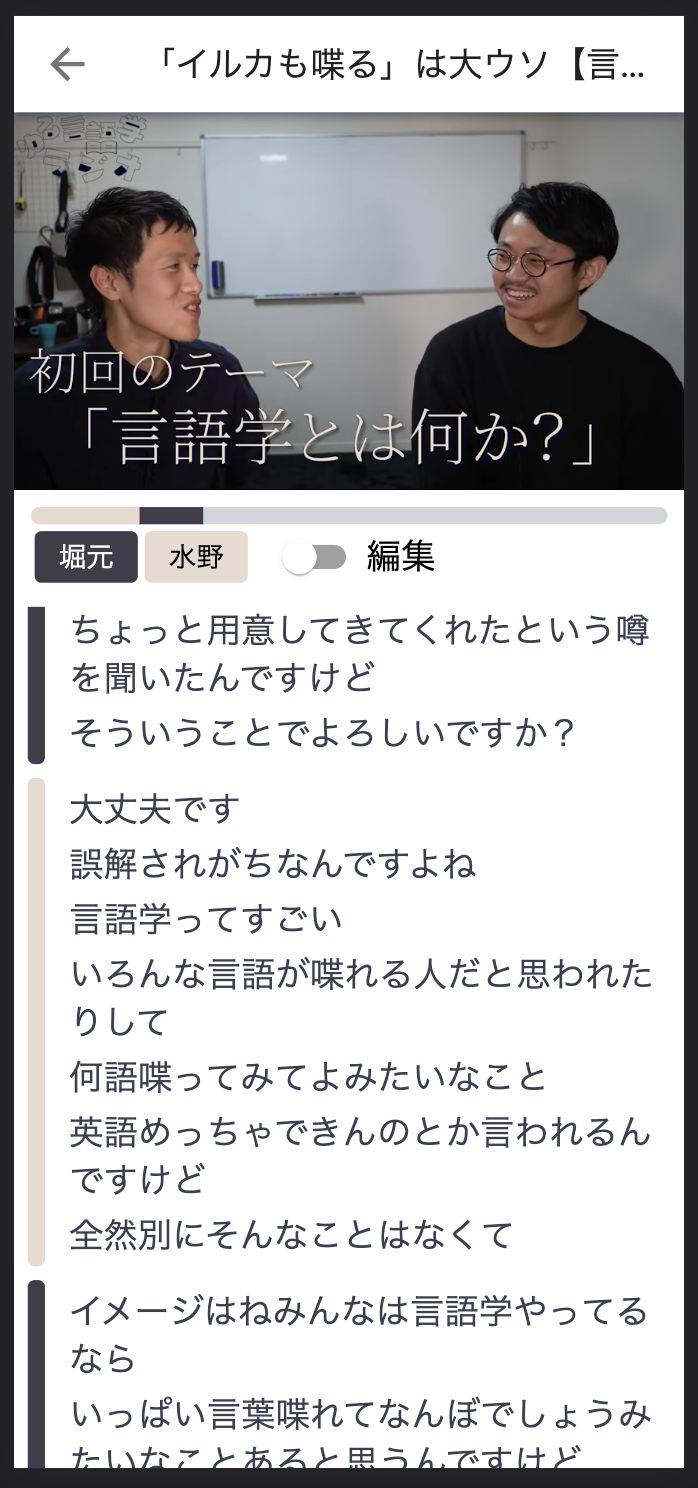

OpenAIのWhisperを使って作成したものを初期データとし、それを誰でも修正できるようにしています。
Whisperに関して
Whisperは割と精度が高く、Largeモデルを使うとそれなりの確率で手直し不要のクオリティーが出ます。
00:00:00.000 --> 00:00:03.480
【テロップ】
00:00:03.480 --> 00:00:05.480
ポリモさんこんな単語知ってます?
00:00:05.480 --> 00:00:07.040
トリコトゥース
00:00:07.040 --> 00:00:08.740
トリコトゥース?
00:00:08.740 --> 00:00:09.740
全く聞いたことない
00:00:09.740 --> 00:00:11.280
ツズリ一応言いましょうか
00:00:11.280 --> 00:00:16.780
T-R-I-C-O-T-E-U-S-E
00:00:16.780 --> 00:00:18.840
聞いても知らんもん知らんけど
そのため初期データはほとんど手直しを加えず、Whisperの出力をそのまま使用しています。
ただし、1/50くらいの割合で【はじめしゃちょーエンディング】としか出力されない地獄の回があったりします。
また、学習データに多く使われたことが原因だと思いますが、コテンラジオのパーソナリティーの方々の名前が出ることもありました。
冒頭のタイトルコールを削るなどしたら変わるのかもしれません。
また、ちょうど新しいモデルが公開されたばかりで、今後そちらも試す予定です。
00:00.000 --> 00:03.500
【はじめしゃちょーエンディング】
00:30.000 --> 00:33.500
【はじめしゃちょーエンディング】
01:00.000 --> 01:03.500
【はじめしゃちょーエンディング】
01:31.000 --> 01:34.500
【はじめしゃちょーエンディング】
01:34.500 --> 01:37.500
【はじめしゃちょーエンディング】
01:37.500 --> 01:40.500
【はじめしゃちょーエンディング】
00:00:00.000 --> 00:00:07.080
ヤンヤン 今回は第4回ですねタだけで4回
00:00:07.080 --> 00:00:10.440
目 まだまだ後半戦始まったよみたいな
00:00:10.440 --> 00:00:12.940
感じなんですけど 樋口 そろそろみんなビビり始めて
00:00:12.940 --> 00:00:15.720
くるでしょうね ヤンヤン リスナーが泣くまでやりましょう
00:00:15.720 --> 00:00:17.280
深井 はいもうギャン詰めしていきましょう
00:00:17.280 --> 00:00:21.080
樋口 やりましょうやりましょう 深井 今回はタの本質ですねタって
00:00:21.080 --> 00:00:26.020
だってこんなにいろいろ意味あって 日本の人日本の僕はわしゃってなんと
編集に関して
編集機能の設計で最も意識したのは、ユーザーの負荷をできるだけ下げることです。
そのため、最も頻度の高いであろう「文字起こしは修正せず、発話者だけを選択する」という動作を2クリックで行えるようにしました。
しかし、編集画面の描画コストが発話数に対してO(N)の関係にあるため、長尺回では重すぎてまともに編集できない状態になっています。
パフォーマンスの問題が解決した後は、編集のUXをもっと楽しいものにする予定です(何のアイデアもないですが)。
というのも、形態素解析を導入するためには正しい文字起こしが不可欠であり、そのためにはユーザーによる文字起こしの修正をかなり活発にする必要があるからです。
検索

検索機能のゴールは、ユーザーの入力を形態素解析し、原形での検索を行うことです。
例えば「途方もない」という単語を入力した時、「途方もなく」でも「途方もなかった」でもヒットするようなイメージです。
現時点では入力に一致する発話を含むすべての回を表示する機能になっています。
また、データベースにDynamoDBを使用しているため、部分一致でクエリできないという制約があります(先頭一致は一応できますが、検索には向きません)。
そのため、すべての発話をJSONファイルにしてS3に保存し、そこから検索する方法を取っています。
そして、その処理ががO(n^2)のためかなり遅いです。
おわりに
アドベントカレンダーの日にちを「せっかくだし誕生日にしよう!どうせ完成してるでしょ」と適当に選んでしまったことを後悔してます(とほまち)
ただ、最低限動くものくらいは作れたと思うので、ぜひ触ってみてください!