目的
データ収集ってめんどくさいよね.
将来的に競艇の分析とかしてみたいなぁって思ったので,データ収集の練習として競艇公式サイトのオッズ表をスクレイプします.
概要
- スクレイピングにあたって便利そうな言語=pythonしか思いつかないのでpython3.7を使う.
- python3.7にはbeatutiful soupっていう
ちょっとエロそうな名前のライブラリがスクレイピングでは便利らしい - beautifulsoupのcssセレクタを使うことで,いちいちhtmlを解読しなくてもテーブルの場所を特定できる!
- ブラウザに装備されている検証ツールを利用してCSSセレクタをコピーする(楽ちん)
- 実践beautifulsoupなので,メソッドの細かな解説はしない(他にいい記事がたくさんある!)
- 頑張って三連単テーブルの情報を抜いて,今回は辞書型に納める
スクレイピングしたいものと出力方法
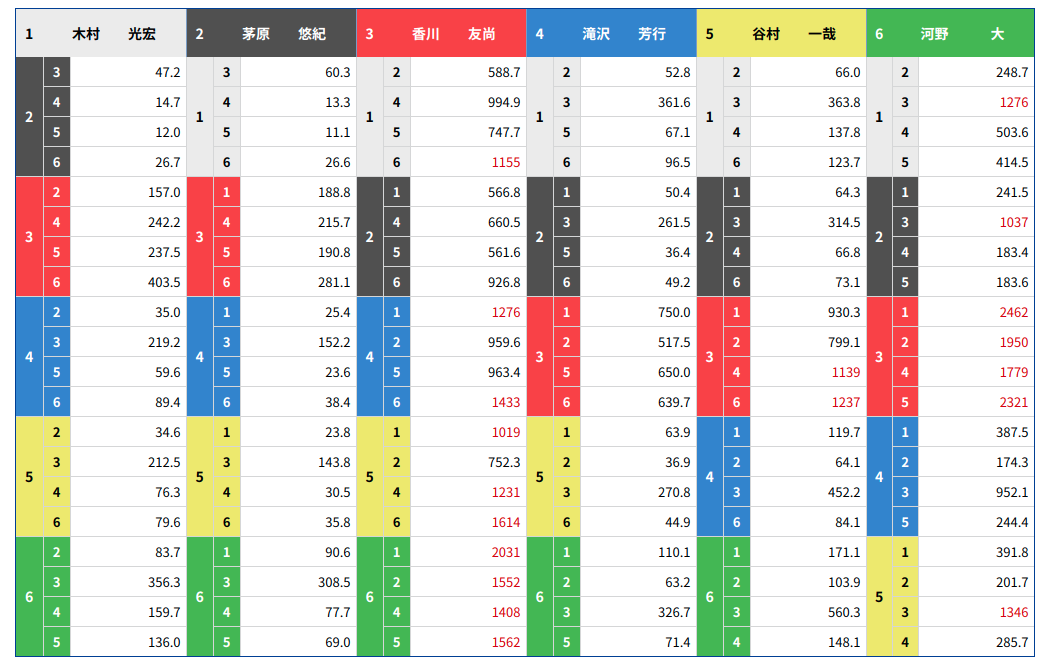 ↑これが3連単のテーブルです!
ギャンブル好きならみたことあるはず!
この図から,値を取得してpythonの辞書型にして次のように呼び出したい!
↑これが3連単のテーブルです!
ギャンブル好きならみたことあるはず!
この図から,値を取得してpythonの辞書型にして次のように呼び出したい!
print('sample1:', three_rentan_odds_dict['1']['2']['3'])
print('sample2:', three_rentan_odds_dict['6']['5']['4'])
# output:
# sample1: 47.2
# sample2: 285.7
もちろんリスト型でもいいんですけど,辞書型のほうがアクセス早いし,配列内の順序は関係ないのでここはあまり突っ込まないでください!
事前準備
開発はpython3.7を使用しますが,3系であればどれでも行けると思う!
jupyterとか使ってコピペすると楽かもしれないです!
インストールするパッケージ
- request
- beautifulsoup4
- numpy
pipで入ります
# pipの場合
pip install request, beautifulsoup4, numpy
# pipenvの場合
pipenv install request beautifulsoup4 numpy
ぜっっったいにやってはいけないこと
相手サーバーに負荷をかける行為
意図してもしなくても相手サーバーの負荷をかけるようなことは絶対しないでください.逮捕事例もあります.
具体的にはここで紹介するソースコードをそのままコピペして1回だけ実行するのは大丈夫ですが,for文をつかって全日程の情報をスクレイピングしようとするなどを行うとサーバーに負荷がかかり,迷惑をかけてしまう可能性がありますので,絶対におやめください.
なおデータ分析を目的としたスクレイピング自体は違法じゃないそうです.
詳しくはこちら
実装
URLを指定してHTMLを取り込む
from urllib.request import urlopen
from bs4 import BeautifulSoup
# 2020年5月11日の戸田競艇場第12レースの三連単オッズ表を例として使う
target_url = \
'https://www.boatrace.jp/owpc/pc/race/odds3t?rno=12&jcd=02&hd=20200511'
# htmlを読み込む
html_content = urlopen(target_url).read()
print(type(html_content))
# output
# <class 'bytes'>
スクレイピングするためにbeautifulsoupで読み込ませる
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
print(type(soup))
# output
# <class 'bs4.BeautifulSoup'>
beautifulsoupに用意されているselectメソッドを利用する.
selectメソッドでは,指定したcss セレクタを用いてhtmlタグの場所を指定してスクレイピングできる.
今回は3連単のオッズ表の部分を取り出したい.
そこで,ブラウザの検証ツールを使って対象箇所のcssセレクタを取得する.
具体的には
1.テーブルのところにカーソルを持っていって右クリックし,検証を開く(F12でもいいと思うが私はF12でtilixが立ち上がるのでマウスを使う)
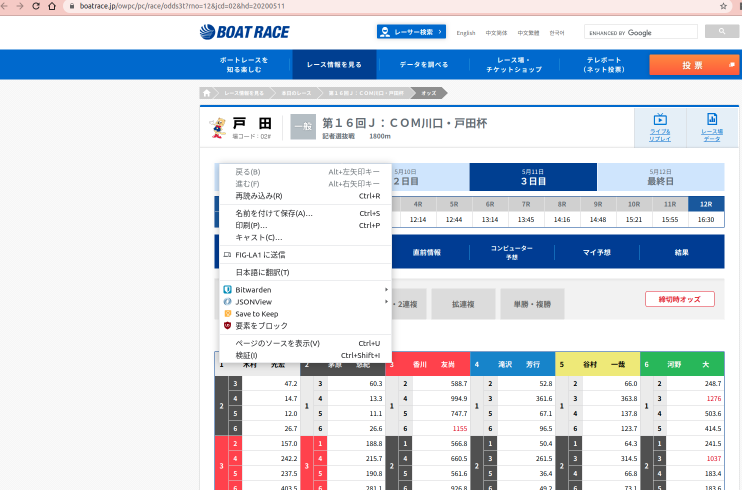
2. 検証ツールのhtml上にマウスを持ってくると,htmlの記述の該当箇所がページで編みがけされたようになるので,それでテーブルの部分が選択されるところを見つける.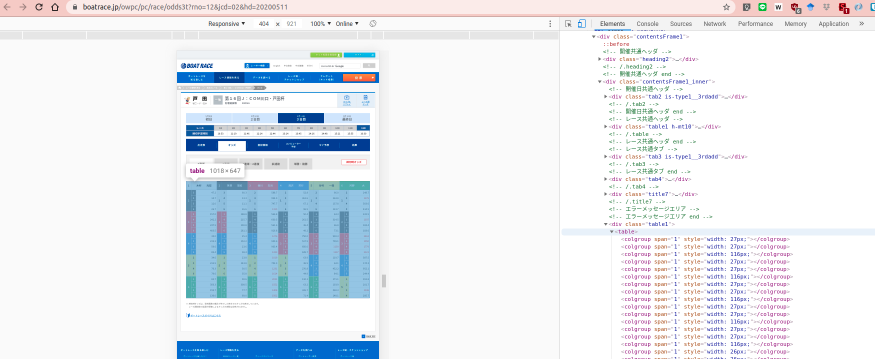
3. このタイミングで右クリックをしてCopy -> Copy Selectorを選択する 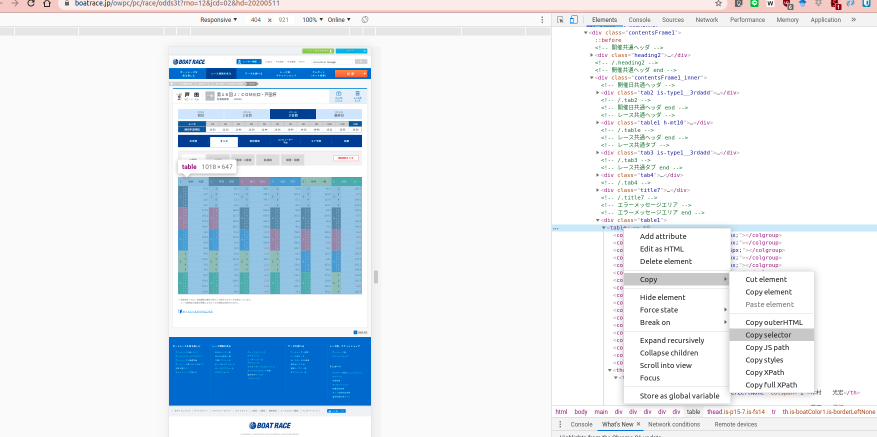
4. 変数target_table_selectorを用意してペーストする.
# コピーしたcss selectorを貼り付ける
target_table_selector = \
'body > main > div > div > div > '\
'div.contentsFrame1_inner > div:nth-child(6) > table'
# select_oneメソッドで指定したhtmlを取ってくる
odds_table = soup.select_one(target_table_selector)
print(type(odds_table))
# output:
# <class 'bs4.element.Tag'>
# print(odds_table)を実行すると,指定したテーブル部分のみのhtmlが表示される
オッズ表の要素を抜き取る
先程みたブラウザの検証ツールを見ると,要素を抜き取るためにはodds_tableの中で'tbody'の部分だけ必要なのでselect_oneで指定する.
そして,それぞれの行をリストとして格納するためにselectを使って'tr'部分を指定しリストにする.
# tbodyの指定
odds_table_elements = odds_table.select_one('tbody')
# trを指定しリストとして格納する
row_list = odds_table_elements.select('tr')
print(len(row_list))
# output:
# 20 : テーブルの行数と一致する
次に,要素であるオッズの値が格納されているタグに注目すると,tdタグ中のoddsPointというクラスであることがわかる.
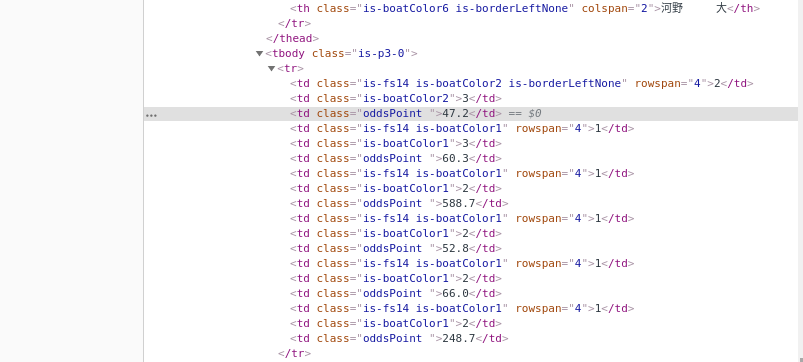
これを各行について抜き出したいため,先に関数を作っておく.
# 各行に対して行う処理
def getoddsPoint2floatlist(odds_tr):
# odds値が格納された部分のhtmlのリストを取得
html_list = odds_tr.select('td.oddsPoint')
print(html_list[0])
# example output:
# <td class="oddsPoint">47.2</td>
# textをつかうことでタグで囲まれた要素のみを抜き出せる
text_list = list(map(lambda x: x.text, html_list))
# print(text_list)
# example output:
# ['47.2', '60.3', '588.7', '52.8', '66.0', '248.7']
# oddsは小数値なのでflot型へキャスト
float_list = list(map(
lambda x: float(x), text_list))
return float_list
map関数を利用してテーブル全体の要素のみを抜き出した行列を生成する
odds_matrix = list(map(
lambda x: getoddsPoint2floatlist(x),
row_list
))
print(odds_matrix)
# output
# [[47.2, 60.3, 588.7, 52.8, 66.0, 248.7],
# [14.7, 13.3, 994.9, 361.6, 363.8, 1276.0],
# [12.0, 11.1, 747.7, 67.1, 137.8, 503.6],
# [26.7, 26.6, 1155.0, 96.5, 123.7, 414.5],
# [157.0, 188.8, 566.8, 50.4, 64.3, 241.5],
# [242.2, 215.7, 660.5, 261.5, 314.5, 1037.0],
# [237.5, 190.8, 561.6, 36.4, 66.8, 183.4],
# [403.5, 281.1, 926.8, 49.2, 73.1, 183.6],
# [35.0, 25.4, 1276.0, 750.0, 930.3, 2462.0],
# [219.2, 152.2, 959.6, 517.5, 799.1, 1950.0],
# [59.6, 23.6, 963.4, 650.0, 1139.0, 1779.0],
# [89.4, 38.4, 1433.0, 639.7, 1237.0, 2321.0],
# [34.6, 23.8, 1019.0, 63.9, 119.7, 387.5],
# [212.5, 143.8, 752.3, 36.9, 64.1, 174.3],
# [76.3, 30.5, 1231.0, 270.8, 452.2, 952.1],
# [79.6, 35.8, 1614.0, 44.9, 84.1, 244.4],
# [83.7, 90.6, 2031.0, 110.1, 171.1, 391.8],
# [356.3, 308.5, 1552.0, 63.2, 103.9, 201.7],
# [159.7, 77.7, 1408.0, 326.7, 560.3, 1346.0],
# [136.0, 69.0, 1562.0, 71.4, 148.1, 285.7]]
これにてスクレイピング完了!!
おまけ:辞書型に格納する
ここは,スクレイピングの本質的な部分ではないので,細かな解説は省く
import numpy as np
# numpy array化
odds_matrix = np.array(odds_matrix)
# 転置を取り,つなげてリスト化
odds_list = list(odds_matrix.T.reshape(-1))
# 辞書で格納する
three_rentan_odds_dict = {}
for fst in range(1, 7):
if fst not in three_rentan_odds_dict.keys():
three_rentan_odds_dict[str(fst)] = {}
for snd in range(1, 7):
if snd != fst:
if snd not in three_rentan_odds_dict[str(fst)].keys():
three_rentan_odds_dict[str(fst)][str(snd)] = {}
for trd in range(1, 7):
if trd != fst and trd != snd:
three_rentan_odds_dict[str(fst)][str(snd)][str(trd)] = \
odds_list.pop(0)
print('sample1:', three_rentan_odds_dict['1']['2']['3'])
print('sample2:', three_rentan_odds_dict['6']['5']['4'])
# output:
# sample1: 47.2
# sample2: 285.7