pandasとは
Pythonにて、構造化データ(テーブル型のデータ)を扱うためのライブラリです。ファイルの読み込みやその後の加工・抽出処理などを簡単に行うことができ(SQL的な感覚で行うことができ)、機械学習などのデータの前処理で必須となるライブラリです。
他項目への目次はこちらになります。
はじめに
本記事では、Pivotテーブルについて記載します。Pivotとは何か等は省略します。基本的にはExcelではここの設定がpandas構文ではこうなりますという記載とします。
サンプルはタイタニックのデータで試してみます。タイタニックがわからない人は「kaggle タイタニック」で調べて下さい。
dataframe = pd.read_csv('train.csv')
使い方
まずはライブラリをインポートします。pandasにpdという名前をつけてimportします。
import pandas as pd
基本的なサンプル構文を下記に示します。
dataframe.pivot_table(index =['Age'], columns = 'Sex', values = 'Fare', aggfunc = 'count', margins=True, margins_name='Total')
ExcelのPivot機能と対比させるとindexが「行」 、columnsが 「列」、valuesが「値」 aggfuncが「フィールドの設定」に相当します。aggfuncは個数に相当するcountを設定しました。

marginsは「総計」に相当し、margins_nameは、そのラベル名称です。
aggfuncには平均であるmeanやmax min等が指定できます。併記したい場合は、['count','mean']として下さい。
欠損値の取り扱い
注意事項として、集計対象のデータに欠損値が含まれるとExcelでは「(空白)」として扱ってくれますが、pandasでは集計の対象となりません。そのため欠損値処理を実施する必要があります。欠損値処理についてはこちらを参照下さい。
次に集計結果の欠損値ですが、NaNで表示されます。それを埋めたい場合はfill_valueを指定して下さい。
例として欠損値をゼロで埋めます。
dataframe.pivot_table(index =['Age'], columns = 'Sex', values = 'Fare', aggfunc = 'count', margins=True, margins_name='Total',fill_value=0.0)
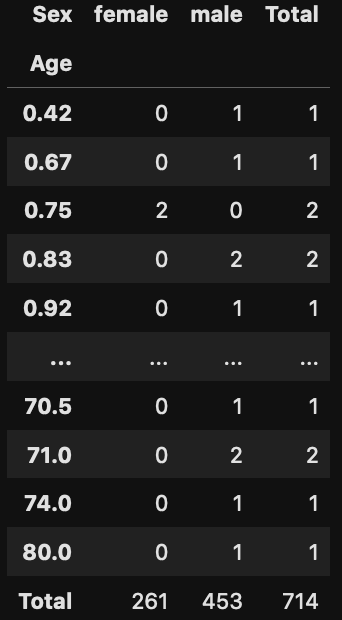
以上です。
最後に
初心者にもわかるように、Pythonで機械学習を実施する際の必要な知識を簡便に記事としてまとめております。
目次はこちらになりますので、他の記事も参考にして頂けると幸いです。