はじめに
機械学習のデータの前処理工程において、pandas等を用いて、いろいろとデータを眺めながら探索的データ分析をすると思いますが、データの可視化を1コマンドで簡単にやってくれるツール「pandas-profiling」というものがあるので、それを紹介します。
導入
ターミナル
$ pip install pandas-profiling
ライブラリインポート
import pandas as pd
import pandas_profiling as pdp
仕様
タイタニックのデータで試してみます。タイタニックがわからない人は「kaggle タイタニック」で調べて下さい。
dataframe = pd.read_csv('train.csv')
コマンドは1文のみです。
pdp.ProfileReport(dataframe)
出力結果は結構なボリュームなのでhtmlファイルに落とす方が見やすいです。
html = pdp.ProfileReport(dataframe)
html.to_file(output_file='dump.html')
アウトプット
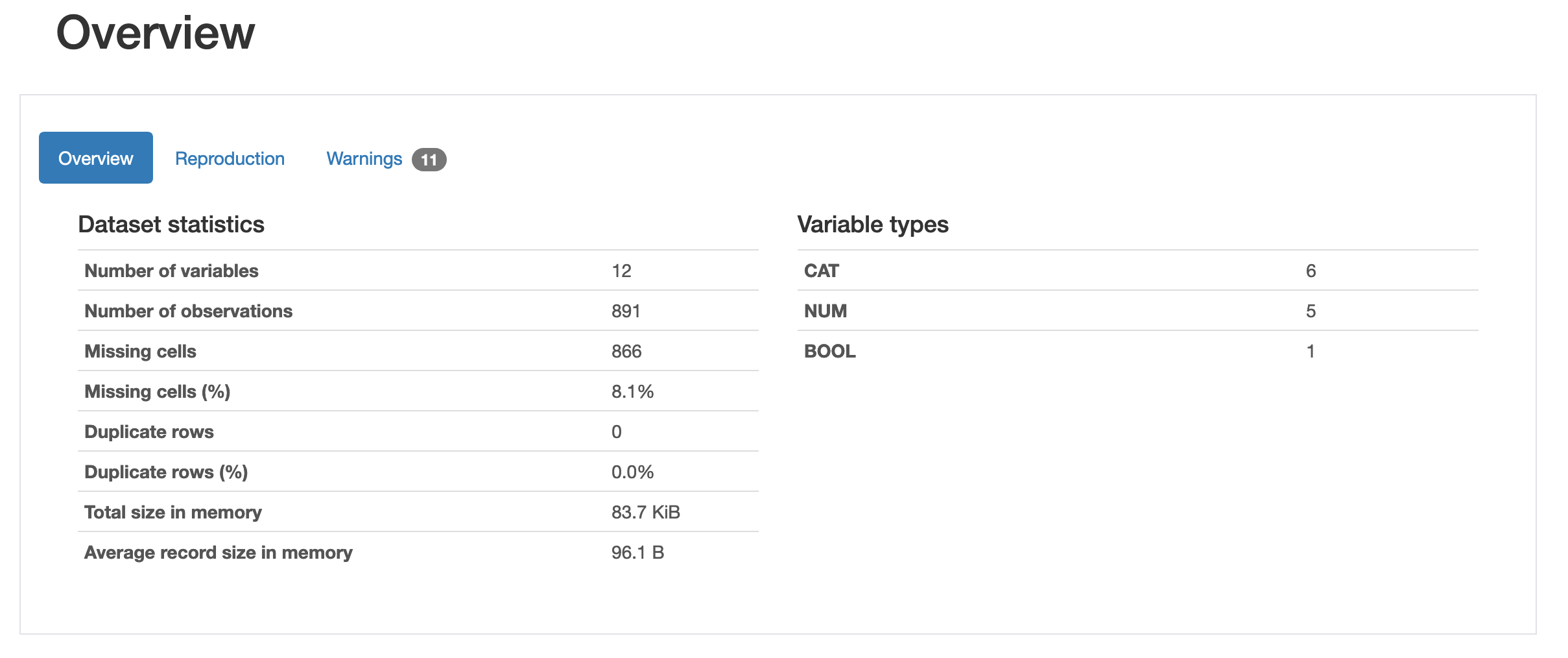
Overview
データの概要を教えてくれます。列数(Number of variables)、行数(Number of observations)、欠損値数(Missing cells)、重複列(Duplicate rows)
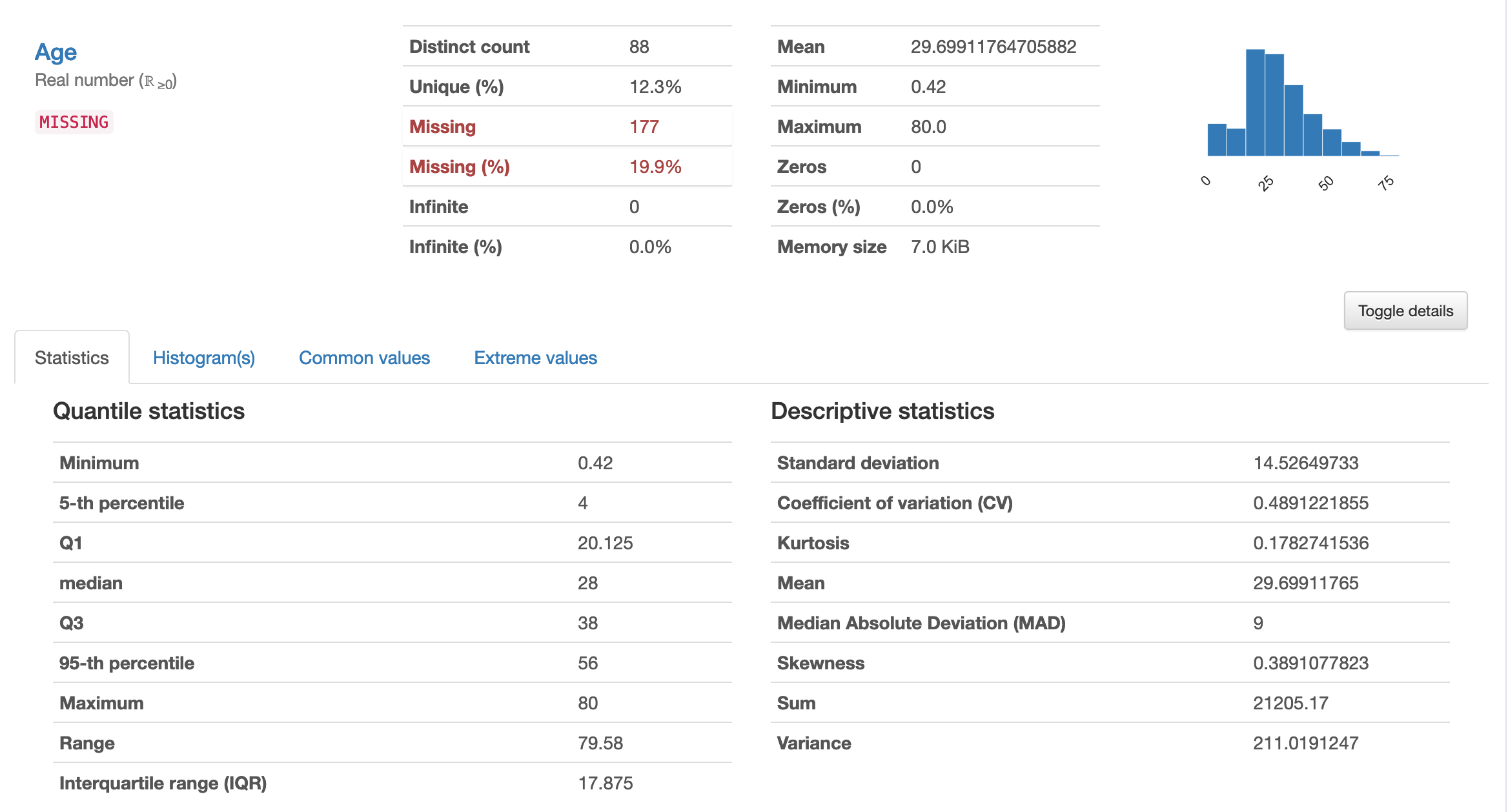
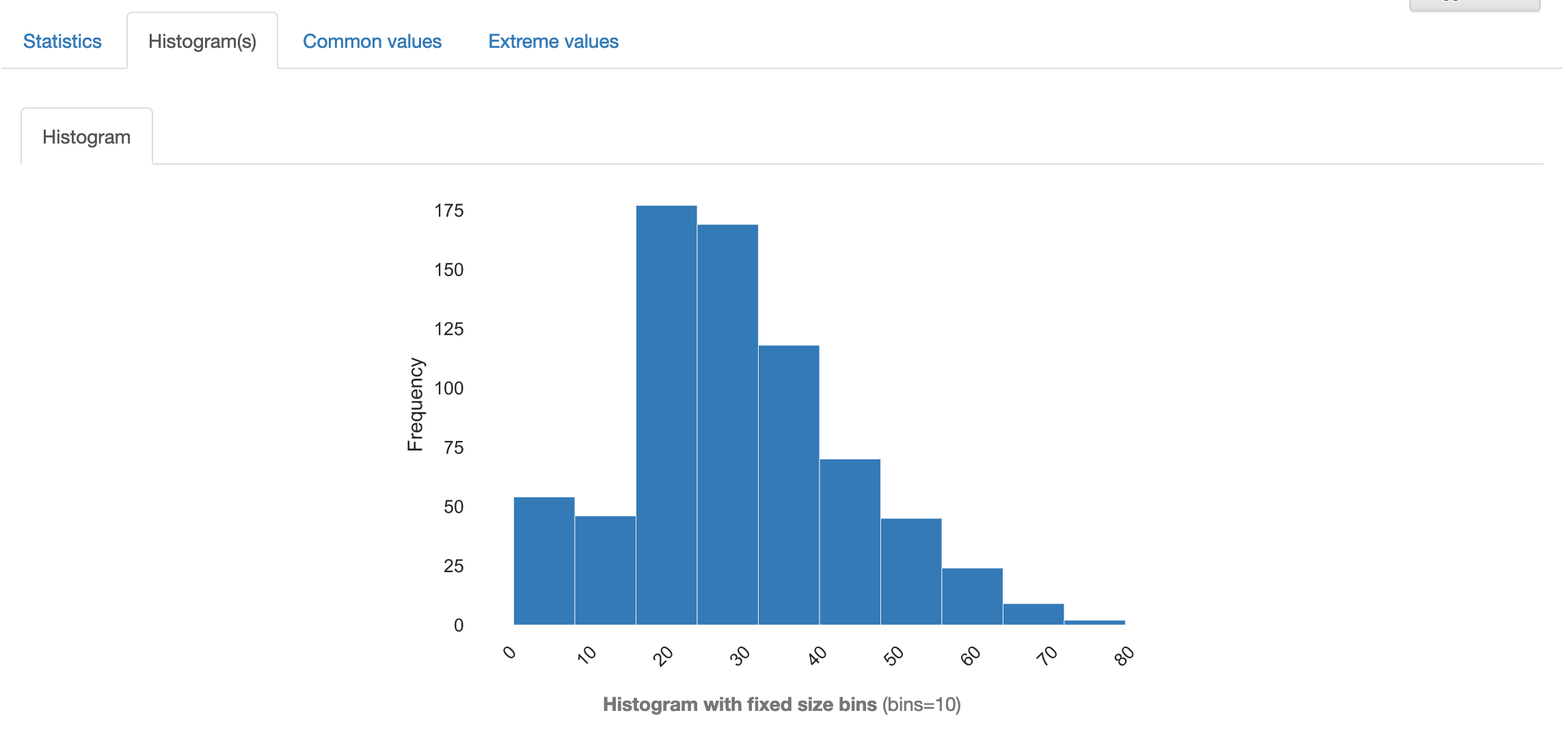
Variables
各項目(列)毎のデータ概要を教えてくれます。年齢(Age)のアウトプット例です。
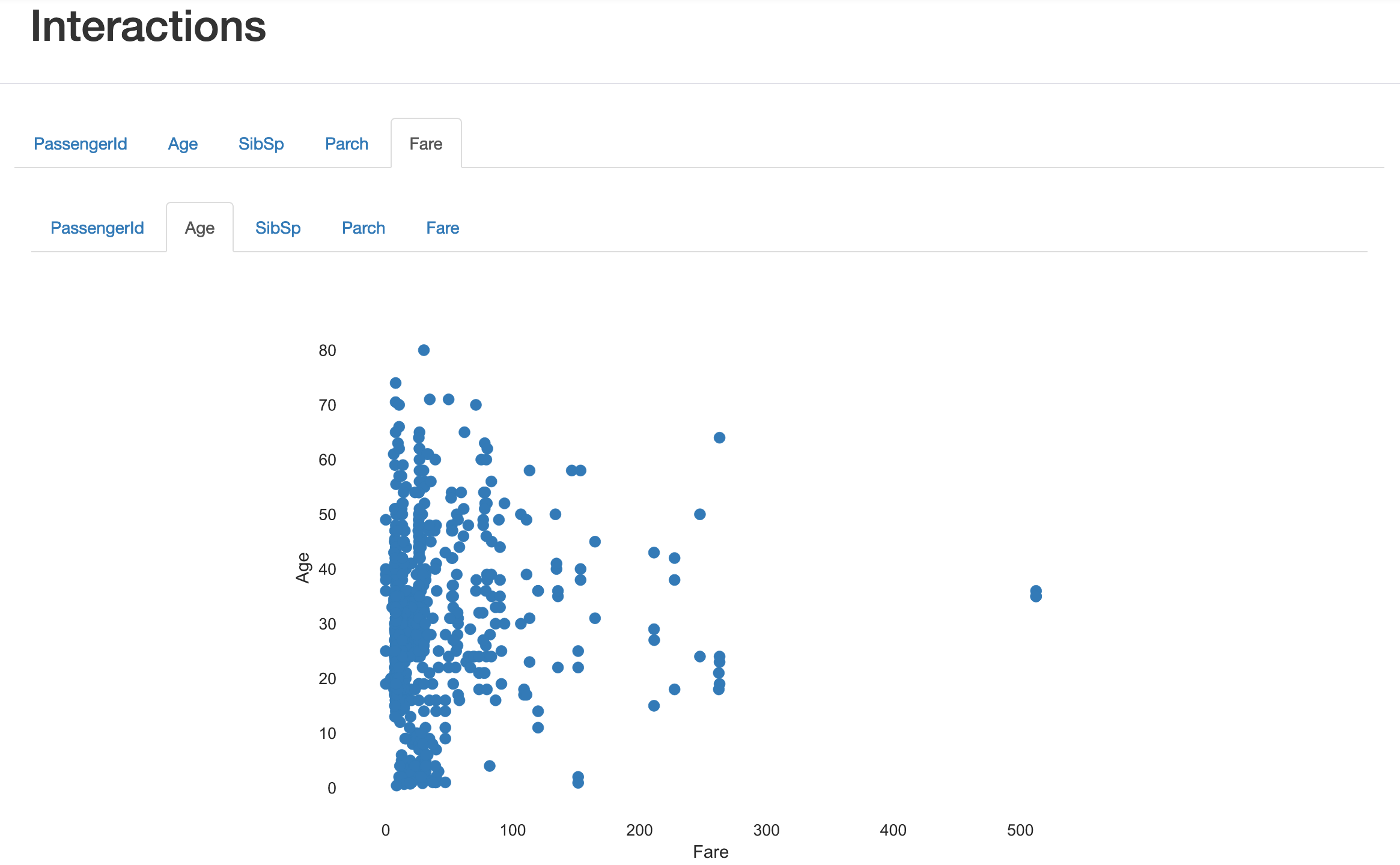
Interactions
列と列の関係を教えてくれます。年齢と運賃のアウトプット例です
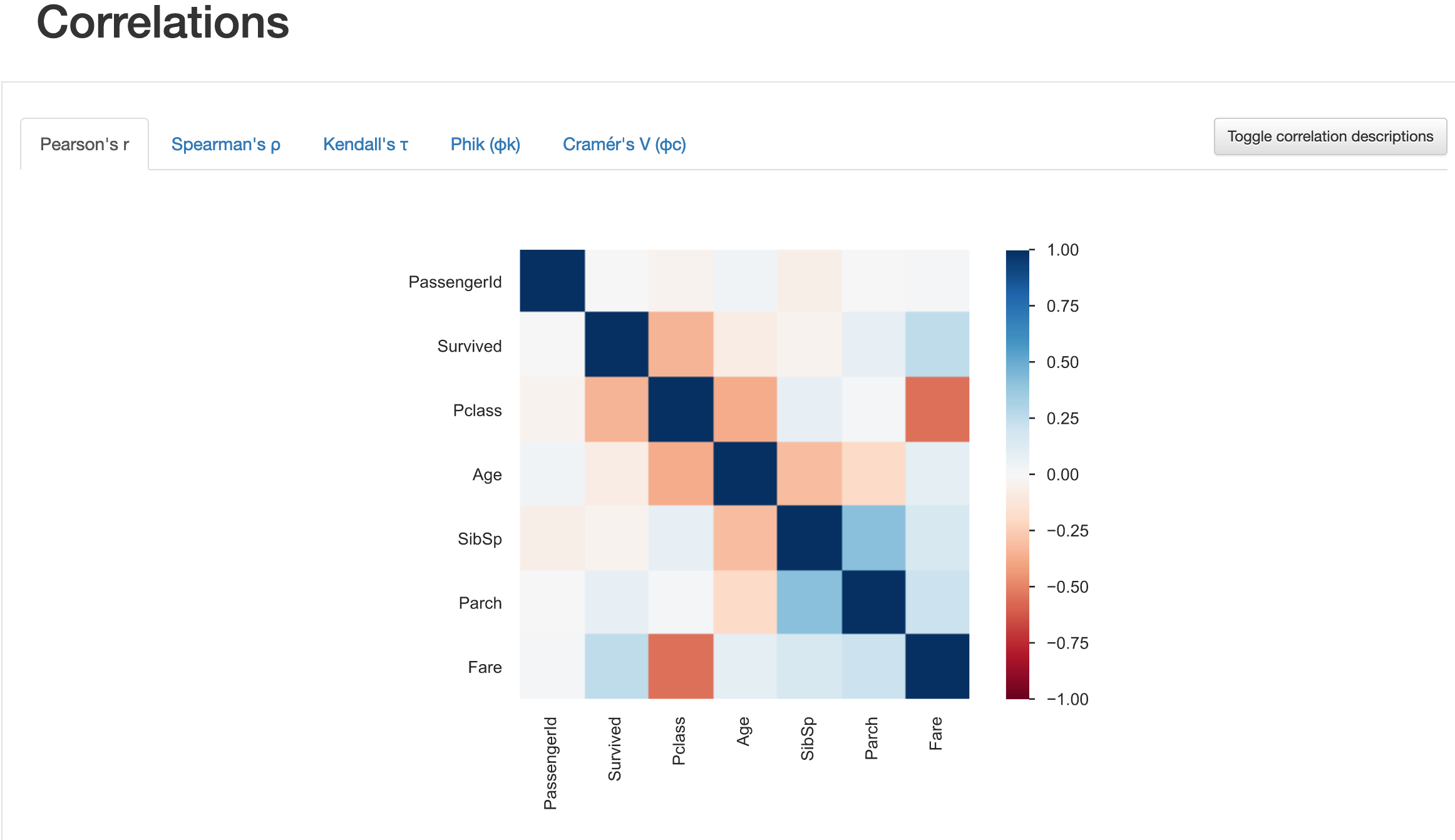
Correlations
列と列との相関を教えてくれます。
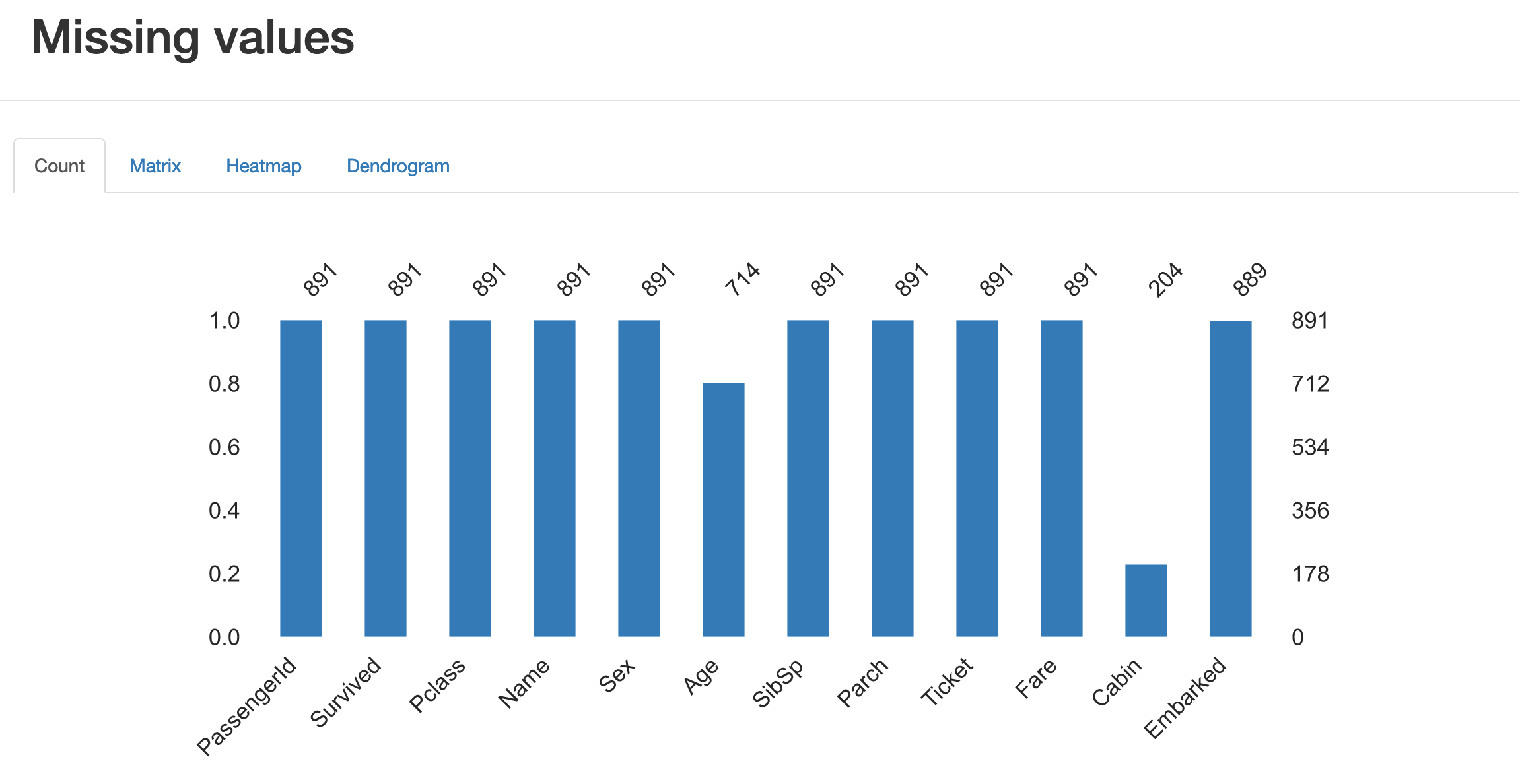
Missing values
欠損値の情報を教えてくれます。
最後に
初心者にもわかるように、Pythonで機械学習を実施する際の必要な知識を簡便に記事としてまとめております。
目次はこちらになりますので、他の記事も参考にして頂けると幸いです。