はじめに
ChromeのDevToolsなどで見るように、ブラウザ上で読み込んだファイルを読み込む方法を紹介します。
seleniumから直接読み込むことで、
- リクエスト数を減らせる
- 適切な方法でリクエストできる (ヘッダ、Cookieなど)
といったメリットがあります。
特にリクエスト方法が複雑なサイトの場合、その条件をjsファイルなどから解析せずに自動化できるため便利です。
※スクレイピングが禁止されているサイトでの利用は控えてください
方法
以下の2つの方法があります。
-
selenium-wireを使う- メリット
- 簡単に使える
- デメリット
- 実行中にエラーが出ることがある
- 読み込んだデータが取得できないことがある
- 「保護されていない通信」になる
- メリット
- 自力で実装する
- メリット
- 自分の使い方に合ったように作成できる
- デメリット
- エラーなどには自分で対応する必要がある
- メリット
(私は最初 selenium-wire を知らなかったため、自力で実装することになりました...)
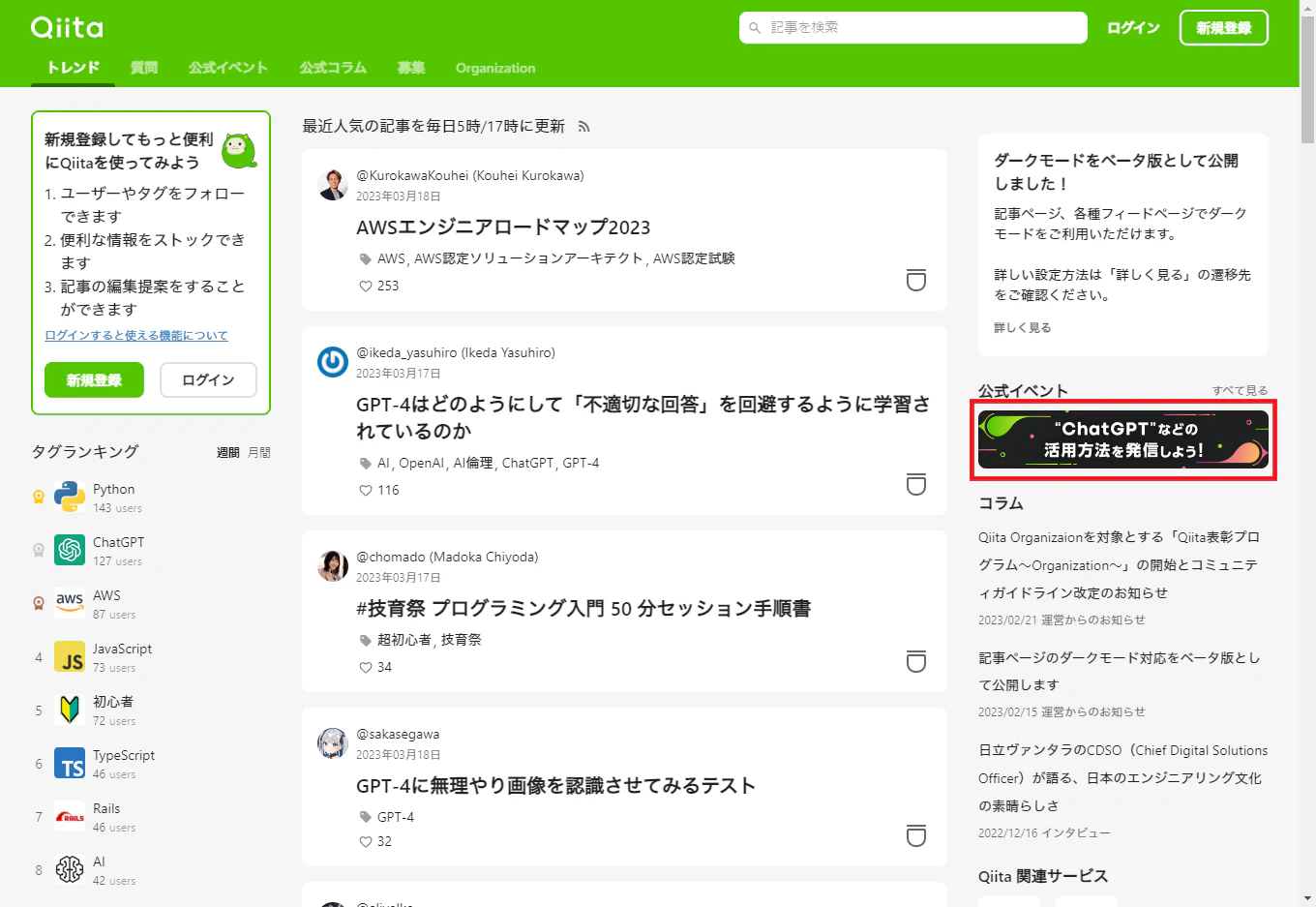
画像の保存
それでは、qiitaのページにある公式イベントの画像を取得してみましょう。
ファイル名: original.jpg
1. selenium-wire を使う
seleniumwireのdriverにはrequestsというインスタンス変数があり、
そこにはブラウザで行った通信が保持されます。
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# driverの作成
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://qiita.com/')
# URLに「original.jpg」が含まるリクエストを取得する
results = [item for item in driver.requests if 'original.jpg' in item.url]
if len(results) == 0:
raise Exception('original.jpgが見つかりませんでした')
# リクエスト情報にある取得データを保存する
with open('original.jpg', 'wb') as f:
f.write(results[0].response.body)
無事、画像が保存されていました。

2. 自力で実装する
実装部分は長くなってしまうため、selenium_loadというモジュールに書き、それを読み込んでいます。
1つ注意点として、使うseleniumのdriverには caps["goog:loggingPrefs"] = {"performance": "ALL"} という設定が必要です。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from webdriver_manager.chrome import ChromeDriverManager
import selenium_load
# driverの作成
caps = DesiredCapabilities.CHROME
caps["goog:loggingPrefs"] = {"performance": "ALL"}
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, desired_capabilities=caps)
driver.get('https://qiita.com/')
# original.jpgの情報を取得
network_dict = selenium_load.get_network_dict(driver)
results = [network_info for url, network_info in network_dict.items() if 'original.jpg' in url]
if len(results) == 0:
raise Exception('original.jpgが見つかりませんでした')
# 画像として保存
with open('original2.jpg', 'wb') as f:
f.write(results[0].body)
こちらも問題なく保存されていました。

自作モジュール
driver.get_log('performance') をすることでdriverのログを取得することができます。
そのログを種類ごとに分類し、Network.getResponseBody というコマンドからbodyを取得しています。
(詳しい説明は後日追加予定です。)
import json
import cv2
import numpy as np
import selenium.common.exceptions
class NetworkInfo(object):
def __init__(self, request_id):
self.request_id = request_id
self.url = None
self.status_code = None
self.content_type = None
self.body = None
self.request_headers = {}
self.response_headers = {}
self.is_full_request_headers = False
self.is_full_response_headers = False
def set_body(self, body):
self.body = body
def set_request_headers(self, headers, is_full):
if not self.is_full_request_headers:
self.request_headers = headers
self.is_full_request_headers = is_full
def set_response_headers(self, headers, is_full):
if not self.is_full_response_headers:
self.response_headers = headers
self.content_type = self.get_content_type(headers)
self.is_full_response_headers = is_full
@staticmethod
def get_content_type(response_headers):
content_type_list = [value for key, value in response_headers.items() if key.lower() == 'content-type']
if len(content_type_list) > 0:
return content_type_list[0]
else:
return None
def get_network_dict(driver):
events = _get_network_events(driver)
network_dict = _get_network_dict(events, driver)
return network_dict
def _get_network_events(driver):
net_log = driver.get_log('performance')
events = [json.loads(entry['message'])['message'] for entry in net_log]
return events
def _get_network_dict(events, driver=None):
results = {}
for event in events:
method = event['method']
if method == 'Network.requestWillBeSent':
request_id = event['params']['requestId']
url = event['params']['request']['url']
part_headers = _fix_headers_tuple(event['params']['request']['headers'])
if request_id not in results.keys():
results[request_id] = NetworkInfo(request_id)
results[request_id].url = url
results[request_id].set_request_headers(part_headers, False)
elif method == 'Network.requestWillBeSentExtraInfo':
request_id = event['params']['requestId']
headers = _fix_headers_tuple(event['params']['headers'])
if request_id not in results.keys():
results[request_id] = NetworkInfo(request_id)
results[request_id].set_request_headers(headers, True)
elif method == 'Network.responseReceived':
request_id = event['params']['requestId']
url = event['params']['response']['url']
part_headers = _fix_headers_tuple(event['params']['response']['headers'])
if request_id not in results.keys():
results[request_id] = NetworkInfo(request_id)
results[request_id].url = url
results[request_id].set_response_headers(part_headers, False)
if driver is not None:
try:
body_info = driver.execute_cdp_cmd(
'Network.getResponseBody', {'requestId': event['params']['requestId']})
results[request_id].set_body(body_info['body'])
except selenium.common.exceptions.WebDriverException:
print(f"Failed to fetch: {url}")
pass
elif method == 'Network.responseReceivedExtraInfo':
request_id = event['params']['requestId']
headers = _fix_headers_tuple(event['params']['headers'])
status_code = event['params']['statusCode']
if request_id not in results.keys():
results[request_id] = NetworkInfo(request_id)
results[request_id].status_code = status_code
results[request_id].set_response_headers(headers, True)
formatted_results = {result.url: result for result in results.values()}
return formatted_results
def _fix_headers_tuple(headers):
new_headers = {}
for key in headers.keys():
if type(headers[key]) is tuple:
new_headers[key] = headers[key][0]
else:
new_headers[key] = headers[key]
return new_headers
さいごに
今回はseleniumで読み込んだデータを抽出する方法について説明しました。
方法は selenium-wireを使った方法、自作モジュールを使った方法の2種類がありますが、
それぞれメリット・デメリットがあるので使い分けてみてください。
頻繁に使う場合は自作モジュールを使ったほうが調整できるので便利ですが、
たまに使う程度であれば selenium-wire のほうが楽で良い印象です。
それでは