はじめに
目的も計算コストも違うアルゴリズム?を並べて書いた記事です。
この記事ではirisデータセットを用いてロジスティック回帰とニューラルネットワークを、精度と時間で比べてみます。
irisデータセット
-
下記画像のような3種類のアヤメに関するデータセット

-
データは花弁の長さ、花弁の幅、がくの長さ、がくの幅
-
1種類につき50個のデータ。全部で150個
ロジスティック回帰
自分的にwikipediaの説明がわかりやすかったです。
入力xに対して確率p_{i}を出力するモデル
\\
\alpha と\betaはそれぞれ回帰係数と切片を表し、学習によって最適化される
\\
\operatorname {logit}(p_{i})=\ln \left({\frac {p_{i}}{1-p_{i}}}\right)=\alpha +\beta _{1}x_{{1,i}}+\cdots +\beta _{k}x_{{k,i}},
{\displaystyle i=1,\dots ,n,\\}
p = \frac{ 1 }{ 1 + \exp ( -(a_1x_1 + a_2x_2 + \cdots + a_nx_n + b) ) }
サンプル(青点)から学習した確率pのプロット(緑線)
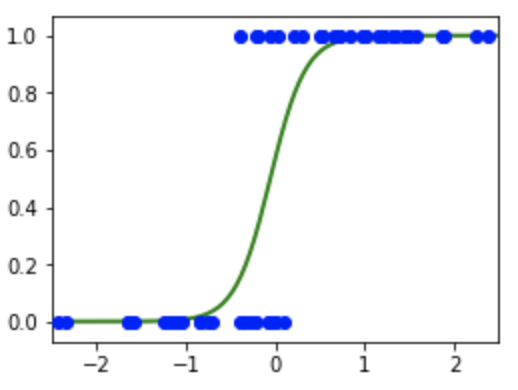
- 回帰と書いてあるが分類問題のためのアルゴリズム
- 特徴量空間が線形分離可能な場合のみ高い性能を発揮
二値分類っぽいがそれより上にも使えるアルゴリズム
ニューラルネットワーク
- 入力と出力の間に中間層と呼ばれる分岐点を儲けることで複雑な決定境界を学習できるモデル
- 生物の神経回路網(ニューロン)を模倣することから始まったとされている

この図は4次元の入力データを受け取り、16次元の中間層を経由して3次元のデータが出力されます。
中間層は隠れ層とも言って、ニューラルネットワークは入力、出力以外はユーザーが理解しにくい場所であるため、内部がブラックボックスであるとも言われています。
全結合層
ニューラルネットワークの基本はこの全結合層で、上の図で言う青い玉です。
- 次の層の全てのユニットと結合する(分岐する)
- ReLUやsoftmax関数が活性化関数として使用される
ReLU関数
0以下の出力は0に、それ以上の出力はそのままにする関数
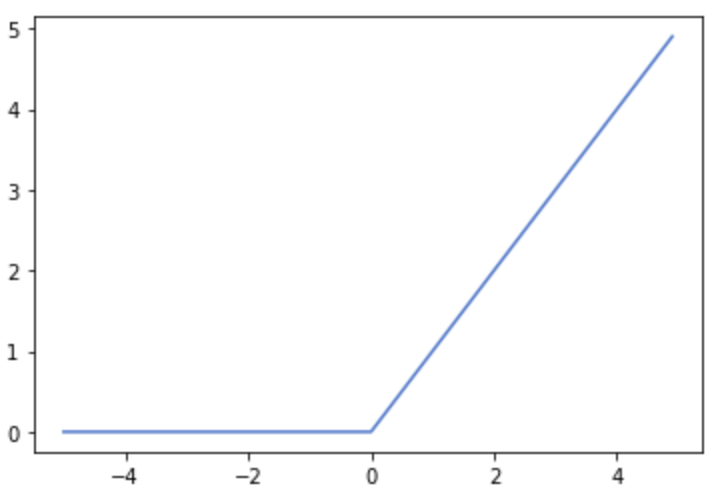
数式ちょっと難しいので割愛
softmax関数
ニューラルネットワークの出力はただの数値です。それを、その層全体の何%なのかにしてくれる関数
{\displaystyle \varphi (u_{k})={\frac {e^{u_{k}}}{\sum _{i=1}^{K}e^{u_{i}}}}}
\\
e^{u_{k}}:1つのユニットの出力\\K:ユニット数\\分母の式は、全ユニットの出力数値の総和
評価
- google colaboratoryで実行
- 学習データとテストデータの割合は8:2
- NNの精度がロジスティック回帰での精度に追いついたら時間比較
ロジスティック回帰
from sklearn.datasets import load_iris
import time
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split as split
from sklearn.metrics import confusion_matrix,accuracy_score
# データセットの読み込み
iris = load_iris()
# 学習データと評価データに分ける
X_train, X_test, Y_train, Y_test = split(iris_df.values,iris.target,train_size=0.8,test_size=0.2)
# ロジスティック回帰モデルインスタンスを作成
model = LogisticRegression(solver='lbfgs',verbose=1)
# 学習の時間を測る
start = time.time()
model.fit(X_train,Y_train)
end=time.time() - start
print('処理時間')
print(end)
# 評価データに対する予測ラベルを求める
Y_pred = model.predict(X_test)
# 混合行列とaccuracyを出力
print('confusion matrix = \n', confusion_matrix(y_true=Y_test, y_pred=Y_pred))
print('accuracy = ', accuracy_score(y_true=Y_test, y_pred=Y_pred))
ロジスティック回帰ー結果
| model | accuracy | time(s) |
|---|---|---|
| ロジスティック回帰 | 0.93 | 0.044 |
ニューラルネットワーク
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
import keras.backend as K
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.utils import np_utils
from sklearn import preprocessing
from sklearn.metrics import confusion_matrix
from pandas.plotting import scatter_matrix
import time
# モデルを構築する関数
def build_multilayer_perceptron():
model = Sequential()
model.add(Dense(16, input_shape=(4, )))
model.add(Activation('relu'))
model.add(Dense(3))
model.add(Activation('softmax'))
return model
nb_epoch=20
iris = datasets.load_iris()
X = iris.data
Y_tag = iris.target
# データの標準化とラベルのワンホットエンコーディング
X = preprocessing.scale(X)
Y = np_utils.to_categorical(Y_tag)
# 学習データと評価データに分ける
train_X, test_X, train_Y, test_Y = train_test_split(X, Y,train_size=0.8)
print(train_X.shape, test_X.shape, train_Y.shape, test_Y.shape)
# NNモデルを作成
model = build_multilayer_perceptron()
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
# モデル訓練
start = time.time()
result = model.fit(train_X, train_Y, nb_epoch=nb_epoch,batch_size=1,verbose=1)
end=time.time() - start
print('処理時間')
print(end)
loss, accuracy = model.evaluate(test_X,test_Y,verbose=2)
print("Accuracy = {:.2f}".format(accuracy))
pred = model.predict(X)
pred = np.argmax(pred, axis=1)
Y = np.argmax(Y,axis=1)
print(confusion_matrix(Y,pred))
ニューラルネットワークー結果ー
精度0.93にするには20Epoch学習しました
| model | accuracy | time(s) |
|---|---|---|
| ニューラルネットワーク | 0.93 | 3.62 |
結果まとめ
| model | accuracy | time(s) |
|---|---|---|
| ロジスティック回帰 | 0.93 | 0.044 |
| ニューラルネットワーク | 0.93 | 3.62 |
NNがロジスティック回帰に追いつくには10倍近くの時間がかかる!?なんて考えちゃダメです多分
irisって分類しやすいビギナー用のデータセットって言うし、NN使うまでもないのかもしれませんね。