概要
こんにちは。とあるIT企業の新入社員です。
ここでは、オープンソース機械学習ライブラリであるPytorchを使って、sin波予測の回帰モデル学習プログラムをサンプルとして記載してみました。
(時系列予測ではないです。。。そのうち時系列予測もやりたいです。)
chainerがpytorchに移行するということで、
遅れましたが、今回キャッチアップしようということで書きました。
私が違いを感じた点も記載しています。
以前に書いた以下の記事のpytorch移行といった感じです。
今更、丁寧にsin波をchainerで学習させてみる
何かご指摘・質問等ございましたら、ご遠慮なくコメント欄にお願い致します。
コード全体
コードは以下のGitHubに置いています。
kazu-ojisan/NN-pytorch_PredictSinWave
環境
macOS Catalina 10.15.3
conda 4.7.12
python 3.7.6 (condaで仮想環境を作成)
pytorch 1.4.0
pytorchのインストールは秒殺。
以下の公式サイトでご自身の環境を選択すると、
インストールコマンドを表示してくれる。
Pytorch -公式サイト-
各パラメータ
- Input :0〜2π
- Output :sin(Input)
- 学習回数:200
- バッチサイズ:10 (ミニバッチ法)
- 学習データ数:1000
- テストデータ数:200
モデル構造
- 中間層:2層(ユニット数:10)
- 活性化関数:ReLU
実装
以下、実装のために参考にしたURLです。
使用モジュール
pytorchのモジュールは最低限以下がimportされていればOK。
import numpy as np # 配列
import time # 時間
from matplotlib import pyplot as plt # グラフ
import os # フォルダ作成のため
# pytorch
import torch as T
import torch.nn as nn # layer構成
import torch.nn.functional as F # 活性化関数
from torch import optim # 最適化関数
データセット
単純なy=sin(x)のデータセット(x,y)です。
# y=sin(x)のデータセットをN個分作成
def get_data(N, Nte):
x = np.linspace(0, 2 * np.pi, N+Nte)
# 学習データとテストデータに分ける
ram = np.random.permutation(N+Nte)
x_train = np.sort(x[ram[:N]])
x_test = np.sort(x[ram[N:]])
t_train = np.sin(x_train)
t_test = np.sin(x_test)
return x_train, t_train, x_test, t_test
Neural Network構造・順伝搬等
chainerからの違いは特になしでモジュールを置き換える程度。
強いていうなら、pytorchが扱うデータ型は、"Tensor型"なので変換が必要。
(chainerでいうValiable型)
class SIN_NN(nn.Module):
def __init__(self, h_units, act):
super(SIN_NN, self).__init__()
self.l1=nn.Linear(1, h_units[0])
self.l2=nn.Linear(h_units[0], h_units[1])
self.l3=nn.Linear(h_units[1], 1)
if act == "relu":
self.act = F.relu
elif act == "sig":
self.act = F.sigmoid
def __call__(self, x, t):
x = T.from_numpy(x.astype(np.float32).reshape(x.shape[0],1))
t = T.from_numpy(t.astype(np.float32).reshape(t.shape[0],1))
y = self.forward(x)
return y, t
def forward(self, x):
h = self.act(self.l1(x))
h = self.act(self.l2(h))
h = self.l3(h)
return h
学習
Chainerとの違いを感じた点(後に詳細あり)
①最適化関数の第一引数にmodel.parameter()が必要
②MSEはClassで定義されているため、インスタンスを作成しないと使えない
③"model.train()"と"model.eval()"による学習モード・テストモードの切替
(今回は無くても問題ない。)
④modelの拡張子は".pt"もしくは".pth"
def training(N, Nte, bs, n_epoch, h_units, act):
# データセットの取得
x_train, t_train, x_test, t_test = get_data(N, Nte)
x_test_torch = T.from_numpy(x_test.astype(np.float32).reshape(x_test.shape[0],1))
t_test_torch = T.from_numpy(t_test.astype(np.float32).reshape(t_test.shape[0],1))
# モデルセットアップ
model = SIN_NN(h_units, act)
optimizer = optim.Adam(model.parameters())
MSE = nn.MSELoss()
# loss格納配列
tr_loss = []
te_loss = []
# ディレクトリを作成
if os.path.exists("Results/{}/Pred".format(act)) == False:
os.makedirs("Results/{}/Pred".format(act))
# 時間を測定
start_time = time.time()
print("START")
# 学習回数分のループ
for epoch in range(1, n_epoch + 1):
model.train()
perm = np.random.permutation(N)
sum_loss = 0
for i in range(0, N, bs):
x_batch = x_train[perm[i:i + bs]]
t_batch = t_train[perm[i:i + bs]]
optimizer.zero_grad()
y_batch, t_batch = model(x_batch, t_batch)
loss = MSE(y_batch, t_batch)
loss.backward()
optimizer.step()
sum_loss += loss.data * bs
# 学習誤差の平均を計算
ave_loss = sum_loss / N
tr_loss.append(ave_loss)
# テスト誤差
model.eval()
y_test_torch = model.forward(x_test_torch)
loss = MSE(y_test_torch, t_test_torch)
te_loss.append(loss.data)
# 学習済みモデルの保存
T.save(model, "Results/model.pt")
詳細:Chainerとの違いを感じた点
①最適化関数の第一引数にmodel.parameters()が必要
model.parameters()は、モデル情報である重みやユニット数などが格納されている。
公式ドキュメント:model.parameters()
ドキュメント通りに出力してみると以下のように出力される。
$ python exportModelParam.py
<class 'torch.Tensor'> torch.Size([10, 1])
<class 'torch.Tensor'> torch.Size([10])
<class 'torch.Tensor'> torch.Size([10, 10])
<class 'torch.Tensor'> torch.Size([10])
<class 'torch.Tensor'> torch.Size([1, 10])
<class 'torch.Tensor'> torch.Size([1])
②MSEはClassで定義されているため、インスタンスを作成しないと使えない
Pytorchの"MSELoss"とChainerの"mean_squared_error"の公式ドキュメントを見ると納得する。
Pytorch:Pytorch -SOURCE CODE FOR TORCH.NN.MODULES.LOSS-
class MSELoss(_Loss):
Chainer:Chainer -mean_squared_error.py-
def mean_squared_error(x0, x1):
③"model.train()"と"model.eval()"による学習モード・テストモードの切替
.evalでテストモードにすると、DropoutやBatch Normalizationが無効になり、テスト仕様になるみたい。本コードでは、DropoutもBatch Normalizationも使っていないため、無くても変わらずに動作する。しかし、今後pytorchを使っていくのであれば、書くクセはつけておいた方が良い気がする。
④modelの拡張子は".pt"もしくは".pth"
以下、参照。
Tutorials > Saving and Loading Models
結果
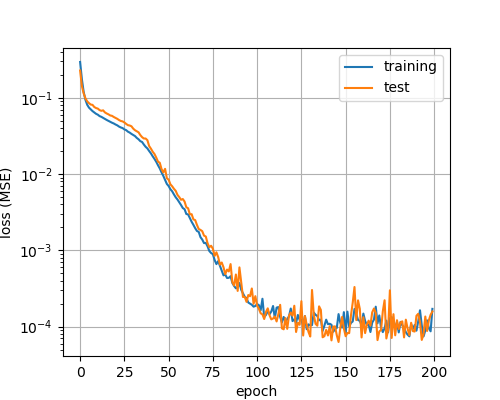
誤差グラフ
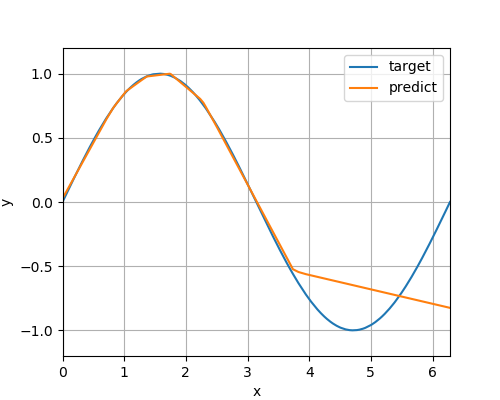
テストデータ予測グラフ
epoch:20
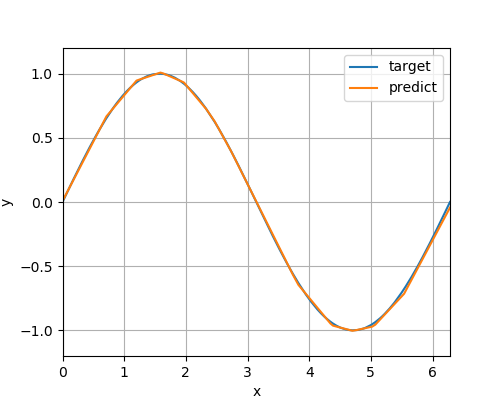
epoch:200
Trouble Shooting
- どうやら学習されていない?
- 勾配の初期化を忘れていた(optimizer.zero_grad())
- ミニバッチごとに勾配を初期化しないと学習できません。
参考URL
コード全体
コードは以下のGitHubに置いています。
kazu-ojisan/NN-pytorch_PredictSinWave
終わりに
情報通り、chainerとかなり似ていました。Pytorchは機能が整っているなぁと感じました。まだまだ理解不足なので何かご指摘ございましたら、ご遠慮なくコメント欄にお願い致します。