概要
Pythonでのスクレイピングを簡単に行えるシステムを紹介します。
今流行りのPythonに触れて何らかのアウトプットがしたいと思い、前々から興味があったスクレイピングにフォーカスしてシステムを開発しました。
※プログラミングやPython、スクレイピング初学者の方に少しでも参考になればと思います。
何か指摘やご意見がありましたらよろしくお願いします。
目次
1 制作したシステム
2 制作に到った経緯
3 インストールしたライブラリ
4 システム内容 - 詳細
5 ソースコード
6 最後に
1 制作したシステム
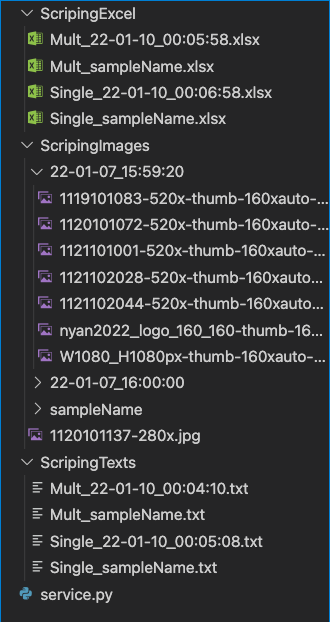
Pythonのinput()を使い、Webページの情報を簡単にスクレイピングできるシステム
具体的な内容としては、
1. Webサイトから「テキスト」「リンク」「画像」の取得
2. 取得したデータを「テキストファイル」「Excelファイル」に保存
画像の場合はディレクトリにまとめて保存
2 制作に到った経緯
- Pythonを只々触りたかった。
- スクレイピングに興味があった。
- Webサイトのデータを簡単な入力だけで収集できたらとても便利だと思った。
3 インストールしたライブラリ
-
requests
HTTP通信をpythonで行える。スクレイピングしたいWebページの取得ができる。 -
Beautiful Soup 4
HTMLファイルやXMLファイルからデータの取得や解析ができる。 -
openpyxl
Excelファイル(.xlsx)の読み書きやシート操作がきます
from bs4 import BeautifulSoup
import requests
import openpyxl
4 システム内容 - 詳細
①初めに
・URL
・CSSセレクタ
・ファイル名 and ディレクトリ名
以外の入力は半角数字での入力になっている。
※理由として、ユーザーアクション・入力チェックの簡略化と誤字脱字の防止。
②保存する際の拡張子
テキストとリンクの場合は.txtか.xlsxのどちらか
画像の場合は取得元の名前・拡張子
③ディレクトリ
テキストとリンクの場合
テキストファイル → ScripingText
エクセルファイル → ScripingExcel
画像の場合 → ScripingImages
④ファイル名
○ファイル名の先頭
・複数要素ではMult_
・単数要素ではSingle_をつけている
○テキストとリンク(ファイル名なし)
・単数ではSingle_年-月-日_時:分:秒 .txt か .xlsx
・複数ではMult_年-月-日_時:分:秒 .txt か .xlsx
その後ScripingTextかScripingExcelに保存
○テキストとリンク(入力名あり)
・単数ではSingle_入力名 .txt or .xlsx
・複数ではMult_入力名 .txt or .xlsx
その後ScripingTextかScripingExcelに保存
○画像(ディレクトリ名なし)
ScripingImagesに
ディレクトリ名を年-月-日_時:分:秒で作成し
その中に取得元の画像名前.拡張子を保存
○画像(入力名あり)
ScripingImagesに
入力名のディレクトリの中に、取得元の画像名前.拡張子を保存
⑤構造としては以下の通り
| ① | ② |
|---|---|
| 次へ進む | やり直し処理 |
○システム開始
URL入力 「http・httpsのチェック」 ー (False)②
① |
取得するデータの種類 ー (False)②
① |(txt・link・imgのどれか)
取得する要素数は単数か複数か ー (False)②
① | (単数 or 複数)
CSSセレクタ入力 ー (False) ②
① | (データを引っ張って来れているか)
○画像以外の場合(txtとlink)
保存形式 ー (False)②
① | (.txt or .xlsx)
ファイル名を自ら決めるか否か ー (False)②
①(はい) | | ②(いいえ)
ファイル名入力 現在時間をファイル名にする
① | | ①
ーーー完了ーーー
○img単数の場合
ファイル名は現在時刻にして保存 ー 完了
○img複数の場合
ディレクトリ名を自ら決めるか否か ー (False)②
①(はい) | | ②(いいえ)
ディレクトリ名入力 現在時間をディレクトリ名にする
① | | ①
ーーー完了ーーー
5 ソースコード
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from pathlib import Path
import requests
import os
import shutil
import re
import time
import datetime
import openpyxl
# ----------------- params ------------------
# 階層を表す
level = 1
check = 1
check2 = 1
check3 = 1
check4 = 1
# URLの一致チェック
pattern = "https?://[\w/:%#\$&\?\(\)~\.=\+\-]+"
# 日付
now = datetime.datetime.now()
# ----------------- function ------------------
def txt_write(text_answer_name):
name_file = Path(text_answer_name)
name_file.write_text(answer, encoding='utf-8')
if not os.path.isdir('ScripingTexts'):
os.mkdir('ScripingTexts')
shutil.move(name_file,'ScripingTexts')
def img_make(url_make):
img_res = requests.get(url_make)
img_name_pass = Path(url_make).name
img_path = Path(img_name_pass)
img_path.write_bytes(img_res.content)
if not os.path.isdir('ScripingImages'):
os.mkdir('ScripingImages')
shutil.move(img_path,'ScripingImages')
# user END comment
def warning(name):
print('\n' + name + '誤りがあります')
print('もう一度やり直してください')
def final(end_name):
print('\nスクレイピングに成功しました!!')
print('カレントディレクトリの '+ end_name +' フォルダに保存されております')
exit()
def finals(end_name):
print('\nスクレイピングに成功しました!!')
print('カレントディレクトリの '+ end_name +' フォルダに保存されております')
exit()
# ----------------- 処理開始 ------------------
while level == 1:
url = input('\nURLを入力してください: ')
# urlなのかの確認
if re.match(pattern, url):
# OK
res = requests.get(url, auth=('',''))
else:
name = 'URLに'
warning(name)
continue
# ----------------- URLが存在するか ------------------
if res.status_code != requests.codes.ok:
warning(name)
level = 1
else:
# OK
level = 2
soup = BeautifulSoup(res.text, 'html.parser')
# ----------------- 取得したい要素選択 ------------------
while level == 2:
while check == 1:
data_type = input('取得したい要素を「1. テキスト」・「2. リンク」・「3. 画像」のいずれかで半角数字で入力してください: ')
if data_type == '1' or data_type == '2' or data_type == '3':
check = 2
else:
name = '入力に'
warning(name)
while check2 == 1:
selecter = input('\n取得したい要素を 「1. 単数」もしくは「2. 複数」のどちらかで半角数字で入力してください: ')
if selecter == '1' or selecter == '2':
check2 = 2
else:
name = '入力に'
warning(name)
# CSSセレクタの取得
print('\n取得したい要素までの')
data_input = input('CSSセレクタを入力してください: ')
if selecter == '1':
data = soup.select_one(data_input)
elif selecter == '2':
data = soup.select(data_input)
# CSSセレクタが取得できているのかの判断
if data is None:
name = 'CSSセレクタが取得されていないか入力に'
warning(name)
else:
if selecter == '1':
level = 3
elif selecter == '2':
level = 6
keep_type = ''
# 複数選択の画像の場合
if data_type == '3' and selecter == '2':
level = 10
files_type = ''
# ----------------- 単数 処理 ------------------
while level == 3:
# テキストかリンク
if data_type == '1' or data_type == '2':
while check3 == 1:
print('\nデータをどの媒体に保存しますか?')
keep_type = input('「1. テキストファイル」・「2. エクセル」のどちらかを半角数字で入力してください: ')
if keep_type == '1' or keep_type == '2':
check3 = 2
# 単数 テキストの取得とファイル名作成
if data_type == '1':
level = 4
answer = data.text
text_answer_name = 'Single_{:%y-%m-%d_%H:%M:%S}.txt'.format(now)
# 単数 リンク作成
elif data_type == '2':
level = 4
answer = urljoin(url, data['href'])
# 入力に誤りがあった場合
if not answer:
name = 'これまでの入力に'
warning(name)
# ----------------- 単数 画像選択 ------------------
elif data_type == '3':
img_name = data['src']
url_make = urljoin(url, img_name)
img_make(url_make)
############### 単数 画像 終了 ###############
end_name = 'ScripingImages'
final(end_name)
# ----------------- 単数 ファイル名決定 and テキストファイル保存 ------------------
if keep_type == '1' or keep_type == '2':
while check4 == 1:
# テキストファイル and エクセルファイル 名前
file_type = input('\nファイル名を自ら決められますか?「1. はい」・「2. いいえ」どちらかを半角数字で入力ください: ')
if file_type == '1' or file_type == '2':
check4 = 2
else:
name = '入力に3'
warning(name)
if file_type == '2' and keep_type == '1':
text_answer_name = 'Single_{:%y-%m-%d_%H:%M:%S}.txt'.format(now)
txt_write(text_answer_name)
############### 単数 テキスト 終了 ###############
end_name = 'ScrapingText'
final(end_name)
elif file_type == '1' and keep_type == '1':
text_input_name = input('ファイル名を入力ください: ')
text_answer_name = 'Single_' + text_input_name + '.txt'
txt_write(text_answer_name)
############### 単数 リンク 終了 ###############
end_name = 'ScrapingText'
final(end_name)
# ----------------- 単数 Excelファイルに保存 ------------------
# 単数 ファイル名ありの場合
if file_type == '1' and keep_type == '2':
ex_input_name = input('ファイル名を入力してください: ')
ex_answer_name = 'Single_' + ex_input_name + '.xlsx'
# 単数 ファイル名入力無しの場合
elif file_type == '2' and keep_type == '2':
ex_answer_name = 'Single_{:%y-%m-%d_%H:%M:%S}.xlsx'.format(now)
wb = openpyxl.Workbook()
wb.active.title = 'スクレイピング結果'
wb.save(ex_answer_name)
wb.close()
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'スクレイピング結果'
sheet["A1"].value = answer
wb.save(ex_answer_name)
wb.close()
ex_path = Path(ex_answer_name)
if not os.path.isdir('ScripingExcel'):
os.mkdir('ScripingExcel')
shutil.move(ex_path,'ScripingExcel')
#################### 単数 Excelのテキスト or リンク 終了 ######################
end_name = 'ScripingExcel'
final(end_name)
# ----------------- 複数 input 処理 ------------------
# 取得するデータの選択
if level == 6:
while level == 6:
print('\nデータをどの形式で保存しますか?')
files_type = input('「1. テキストファイル」・「2. エクセル」のいずれかを半角数字で入力してください: ')
if files_type == '1' or files_type == '2':
level = 7
elif files_type == '3':
level = 10
else:
name = '入力に'
warning(name)
# 複数 ファイル名の選択
if level == 7:
while level == 7:
data_input_name = input('\nファイル名を自ら決められますか?「1. はい」・「2. いいえ」のどちらかを半角数字で入力ください: ')
if data_input_name == '1' or data_input_name == '2':
level = 8
else:
name = '入力に'
warning(name)
# 複数 ファイル名の処理
if files_type == '1':
if data_input_name == '1':
data_user_name = input('ファイル名を入力してください: ')
texts_files_name = 'Mult_' + data_user_name + '.txt'
elif data_input_name == '2':
texts_files_name = 'Mult_{:%y-%m-%d_%H:%M:%S}.txt'.format(now)
elif files_type == '2':
if data_input_name == '1':
data_user_name = input('ファイル名を入力してください: ')
texts_files_name = 'Mult_' + data_user_name + '.xlsx'
elif data_input_name == '2':
texts_files_name = 'Mult_{:%y-%m-%d_%H:%M:%S}.xlsx'.format(now)
# ----------------- 複数 テキストファイル処理 ------------------
if files_type == '1':
# 複数 テキスト ・ リンク処理
if data_type == '1' or data_type == '2':
answers = ''
count = 1
print('\n要素数 x 1秒分の時間がかかります。お待ちください。')
for row in data:
txt_data = ''
if data_type == '1':
txt_data = row.text
elif data_type == '2':
txt_data = urljoin(url, row['href'])
answers += txt_data
answers += '\n'
count += 1
time.sleep(1)
texts_file = Path(texts_files_name)
texts_file.write_text(answers, encoding='utf-8')
if not os.path.isdir('ScripingTexts'):
os.mkdir('ScripingTexts')
shutil.move(texts_file,'ScripingTexts')
#################### 複数 テキスト or リンク 終了 ######################
end_name = 'ScripingText'
finals(end_name)
# ----------------- 複数 Excelの処理 ------------------
if files_type == '2':
# 複数 テキスト ・ リンクの処理
if data_type == '1' or data_type == '2':
print('\n要素数 x 1秒分の時間がかかります。お待ちください。')
wb = openpyxl.Workbook()
wb.active.title = 'スクレイピング結果'
wb.save(texts_files_name)
wb.close()
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'スクレイピング結果'
count = 1
for row in data:
# テキスト or リンク
xl_data = ''
if data_type == '1':
xl_data = row.text
elif data_type == '2':
xl_data = urljoin(url, row['href'])
sheet['A{}'.format(count)].value = xl_data
count += 1
time.sleep(1)
wb.save(texts_files_name)
wb.close()
ex_path = Path(texts_files_name)
if not os.path.isdir('ScripingExcel'):
os.mkdir('ScripingExcel')
shutil.move(ex_path,'ScripingExcel')
#################### 複数 Excelのテキスト or リンク 終了 ######################
end_name = 'ScripingExcel'
final(end_name)
# ----------------- 複数 複数 画像の処理 ------------------
if level == 10:
while level == 10:
dir_name = input('\nディレクトリ名を自ら決められますか?「1. はい」・「2. いいえ」のどちらかを半角数字で入力ください: ')
if dir_name == '1' or dir_name == '2':
level = 11
else:
name = '入力に'
warning(name)
if dir_name == '1':
dir_images_name = input('ディレクトリ名を入力してください: ')
else:
dir_images_name = '{:%y-%m-%d_%H:%M:%S}'.format(now)
print('\n要素数 x 1秒分の時間がかかります。お待ちください。')
for row in data:
url_rel = row['src']
url_abs = urljoin(url, url_rel)
img_res = requests.get(url_abs)
img_name = Path(url_abs).name
img_path = Path(img_name)
img_path.write_bytes(img_res.content)
if not os.path.isdir(dir_images_name):
os.mkdir(dir_images_name)
shutil.move(img_path,dir_images_name)
time.sleep(1)
images_dir = Path(dir_images_name)
if not os.path.isdir('ScripingImages'):
os.mkdir('ScripingImages')
shutil.move(images_dir,'ScripingImages')
#################### 複数 画像 終了 ######################
end_name = 'ScripingImages'
finals(end_name)
6 最後に
このシステムを制作した事で得た事や思った事
- 益々プログラミングの楽しさを実感した。
- Pythonの書き方がなんとなくわかった。
- 変数名を決めるのが難しい
- ターミナルの基本的な使い方が学べた。
- ターミナルを使い外部ライブラリのインストールがわかった。
- スクレイピングがどういうものなのかがわかった。
追加したい事や機能
- URLである事の正確な判定処理
- Basic認証がかかっているサイトのスクレイピング処理
- CSSセレクタでデータが取得されているかの正確な判断処理
- 入力を間違えた時の戻る処理
- input()での入力が正しいか間違っているかの判断をもっと合理的にする事
- システムの設計がもっとシンプルでわかりやすい流れで書く事