はじめに
自然言語について勉強を始めたばかりの初心者です。
ニュース記事の文章を、いくつか用意して、TF-IDFで類似性を解析しました。
ブログの方向性の説明としては、ブログの方向性は、tf-idfだけに限定した類似性解析をおこない
TF-IDFの尺度の使い勝手の理解を深めることが目的となります。
TF-IDFについて
TF-IDFとは、文書内の単語の重要度(重み)を示す手法の一つです。
各データが文書で、その特徴が単語になっているときを考えます。
このとき特徴量として選べるのは、単語の出現回数かこのTF-IDFになります。
さて、重要度の大きい単語は、その文書の特徴語として扱うことができます。
逆に、重要度が小さい単語は、その文書内ではクラス分類などに大きな影響を及ぼさないものだと
考える事ができます。
TF-IDFはTFとIDFという二つの指標をかけ合わせた値です。
なぜ形態素解析しないのか
自然言語処理では、形態素解析するのが一般的のようです。
しかし、ニュースの記事は「公選法違反容疑」のような熟語と熟語の組み合わせが
多くあります。こういった場合、「公選法」と「違反」と「容疑」に分割されてしまうので
別途、自前でユーザ辞書作成など処理が必要です。
色々試しましたが、うまいことするには、まだ私のレベルが不足しているので
一旦は、漢字だけ抜き出して解析することにしました。
環境
Google Colaboratory
使用するデータについて
ニュース記事は、最初の文章に記事の要約が記載されているのが特徴です。
その最初の文章を解析することにしました。
ですが、そのまま利用するわけにもいかないため
実際にあったニュース記事を参考にし、架空のニュース記事を作成しました。
・日付も重要なので漢数字に手で修正
例) 10月31日 ⇒ 十月三十一日
・年齢なども解析対象としたいので漢数字に手で修正
import regex
import numpy as np
a = '投開票の衆院選で山口三区から出馬して当選した民自党の田中外相の後援会入会を神奈川県職員に勧めたとして、県警は、公選法違反容疑で、同県の松早川副知事らを書類送検した。'
b = '衆院選(十月三十一日投開票)の比例代表で、憲法立民主党と日本民自主党が同一の党名略称である「主民党」を使用したことで、県内の約二万票が投票先の判然としない案分票となったことが十五日、県選管への取材で分かった。'
c = '憲法立民主党の金本呂治参院議員(七十三)=北海道選挙区=は二十一日、改選を迎える来年夏の参院選道選挙区(改選数三)に立候補をしない意向を表明した。'
d = '憲法立民主党の金本呂治参院議員(七十三)=道選挙区=は二十一日、来年夏の参院選道選挙区(改選数三)に立候補しない意向をフェイスブックで明らかにした。'
e = '英国では四二十万人の子供が貧困に苦しんでいる、ほぼ三人に一人だ。衝撃的な数字だ。'
f = '憲法立民主党の金本呂治参議院議員が、来年行われる参院選に立候補しない意向を表明しました。'
docs = [a, b, c, d, e, f]
cとdとfが同じニュースについて、別々の文章で記載された記事となります。
ですので、cとdとfが類似性が高いようになれば成功です。
aとb、eは、まったく別のニュースとなります。
TF-IDFの計算
TF-IDFの関数
def tfidf(word, sentence):
# term frequency
#文章sentenceの中で指定した単語wordが
#どの程度出現するのか頻度を計算します。
tf = sentence.count(word) / len(sentence)
#ある単語の文書間でのレア度を計算します。
# inverse document frequency
idf = np.log10(len(docs) / sum([1 for doc in docs if word in doc]))
return round(tf*idf, 4)
TF-IDFの関数を動かしてみる
ニュース記事aの中で、「憲法立民主党」TF-IDFを確認します。
tfidf('憲法立民主党', a)
結果
0.0
0となりました。'憲法立民主党'という単語はニュース記事aには
ありませんので、想定した通りの結果となりました。
続いて、ニュース記事b,c,d,eについてもそれぞれ確認していきます。
ニュース記事bの中で、「憲法立民主党」のTF-IDFを確認します。
tfidf('憲法立民主党', b)
結果
0.0017
ニュース記事cの中で、「憲法立民主党」のTF-IDFを確認します。
tfidf('憲法立民主党', c)
結果
0.0024
ニュース記事dの中で、「憲法立民主党」のTF-IDFを確認します。
tfidf('憲法立民主党', d)
結果
0.0024
ニュース記事eの中で、「憲法立民主党」のTF-IDFを確認します。
tfidf('憲法立民主党', e)
結果
0.0
ニュース記事eは、関係のない記事です。想定どおり、結果が0となりました。
最後にニュース記事fの中で、「憲法立民主党」のTF-IDFを確認します。
tfidf('憲法立民主党', f)
結果
0.004
TF-IDFベクトルの計算
すべての文書に含まれるすべての単語の集合を、リストvocabとして作成します。
次に、すべての文書のすべての単語について、TF-IDFスコアを計算します。
全記事のボキャブラリーリスト作成
ニュース記事aから漢字のみを取り出して、リスト化します。
la = [] #a用リスト
la = regex.findall("\p{Han}+", a)
print(la)
実行結果
['投開票', '衆院選', '山口三区', '出馬', '当選', '民自党', '田中外相', '後援会入会', '神奈川県職員', '勧', '県警', '公選法違反容疑', '同県', '松早川副知事', '書類送検']
このようにして、リストvacabに全単語を登録します。
lb = [] #b用リスト
lb = regex.findall("\p{Han}+", b)
lc = [] #c用リスト
lc = regex.findall("\p{Han}+", c)
ld = [] #d用リスト
ld = regex.findall("\p{Han}+", d)
le = [] #e用リスト
le = regex.findall("\p{Han}+", e)
lf = [] #f用リスト
lf = regex.findall("\p{Han}+", f)
vocab = set(la+lb+lc+ld+le+lf)
print(vocab)
実行結果
{'分', '金本呂治参院議員', '道選挙区', '山口三区', '十月三十一日投開票', '判然', '苦', '七十三', '約二万票', '勧', '三人', '英国', '四二十万人', '子供', '民自党', '貧困', '松早川副知事', '参院選', '二十一日', '来年行', '使用', '党名略称', '投票先', '取材', '比例代表', '同県', '同一', '田中外相', '一人', '公選法違反容疑', '県選管', '書類送検', '当選', '出馬', '十五日', '北海道選挙区', '意向', '主民党', '衝撃的', '明', '金本呂治参議院議員', '衆院選', '表明', '後援会入会', '県警', '投開票', '日本民自主党', '県内', '改選', '参院選道選挙区', '改選数三', '迎', '立候補', '来年夏', '数字', '案分票', '憲法立民主党', '神奈川県職員'}
TF-IDFベクトルの計算
各ニュース記事について、TF-IDFベクトルを計算します。
# initialize vectors
vec_a = []
vec_b = []
vec_c = []
vec_d = []
vec_e = []
vec_f = []
for word in vocab:
vec_a.append(tfidf(word, a))
vec_b.append(tfidf(word, b))
vec_c.append(tfidf(word, c))
vec_d.append(tfidf(word, d))
vec_e.append(tfidf(word, e))
vec_f.append(tfidf(word, f))
結果確認
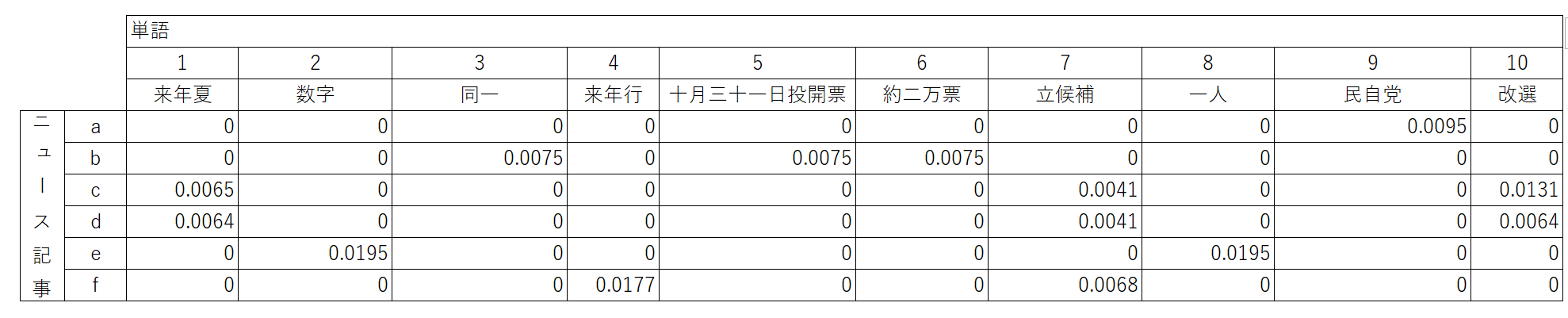
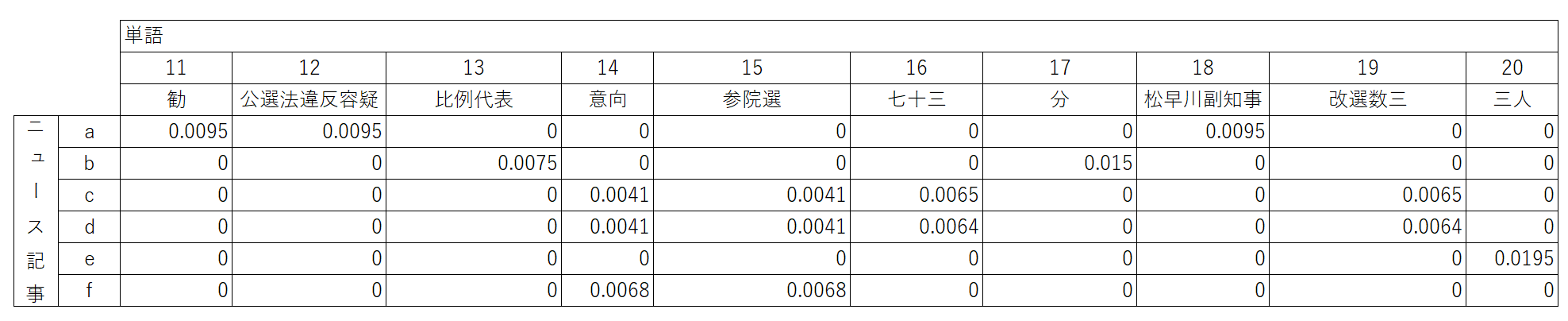
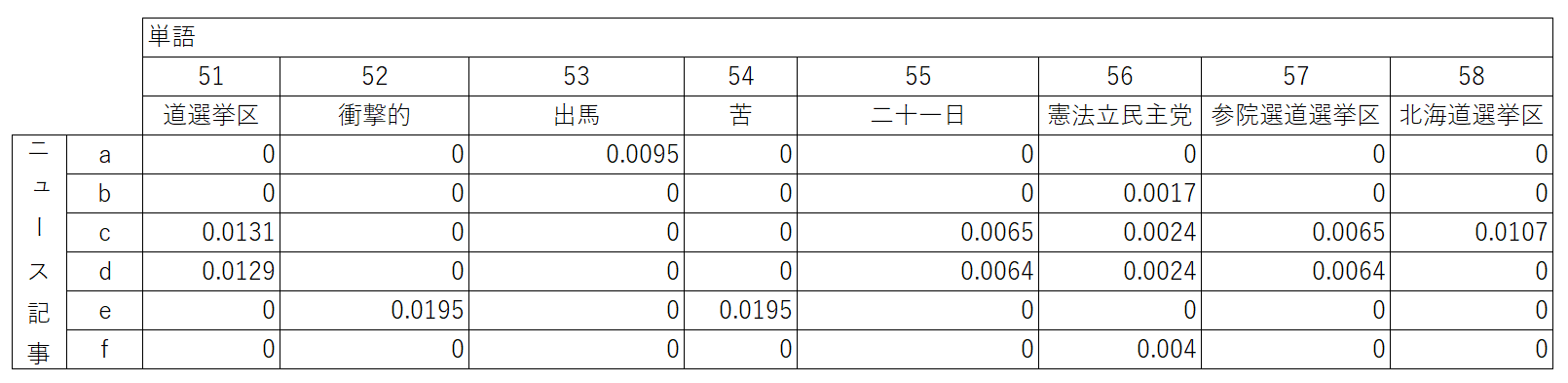
結果を確認します。print()で値を表示させるだけだとわかりにくいので
エクセルで、結果をまとめて表にしました。
同じ内容を扱っているニュース記事cdfとそれ以外で、異なる傾向が見られます。
例えば、「金本呂治参院議員」などがcdで数値が入っています。
なんとなく区別はつくのかなぁという感じはしますが
ぱっと見て、まあいまいちの結果かなぁという感は否めないですね…



まとめ
ブログ作成や勉強を通して、自然言語処理の基本を理解することができました。
テーマ選びが非常に重要だということや、様々な手法があるなか、どの手段を選ぶか
といったことなど、考えるべきことが多いですね。
また、形態素解析をおこない、トリグラムを指標に使うことも類似性評価の1手段になる
というアドバイスをいただきました。次回は挑戦してみたいと思います。
参考
以下の記事を参考にしました
・Google Colaboratory 「TF-IDF」