現役のWEBディレクターです。
一応、非エンジニアですが、wordpress、rails、spring bootなど改修程度で触ったことあるので初級プログラマーレベルの知識はあります。
今回は社内で「広告バナー作成のコスト低減」や、「ターゲットに合わせたデザインを出したい」などの課題や要望がありなんとか画像生成AIで作成できないか考えました。
結果的にはできなかったのですが、今後のヒントになるような気がしたので、自分なりに今回やったことをまとめました。
まずはChatGTPの画像生成を試してみる
ひとまずデフォの機能でどこまでできるか試してみました。
結果的には簡単な画像は作成できるけど、少しでもこだわると以下のようなことがあり、うまくできませんでした。
- 文字が絵と同化する
- 日本語がうまく読み込めない
- 背景と文字調整が難しい
▼作成された画像



ちなみにもうこの時点ですぐに上限が来たので有料プラン契約しました。
GPT-4oです。
Pythonを使えば?
画像生成すると、チャットの返答のところにコードがあることに気がつき、このコードについて調べてみました。
コードの正体はPython/Pillow(PIL)で、何やらコードで画像生成ができちゃうものらしいです。
▼参考
https://imagingsolution.net/program/python/pillow/create_new_image_data/
Pythonは使ったことなかったのでまず、まずは基礎知識を勉強し、PILを実行するための環境構築に時間を裂きました。
PILで画像作成
数時間〜ほぼ半日かけて、ローカル上で簡単なバナー画像が作成できるコードができました。
from PIL import Image, ImageDraw, ImageFont
# 変数で設定する部分
width = 600 # 背景画像の幅
height = 660 # 背景画像の高さ
background_color = 'white' # 背景色
output_path = './dist/img-pointBack.webp' # 保存するファイル名
# 背景画像の生成
img = Image.new('RGB', (width, height), color=background_color)
# アイコン画像の読み込み (item01)
item01_path = 'img/icon-point.png' # アイコン画像のパス
item01 = Image.open(item01_path)
# アイコンのXサイズを指定し、Yサイズはアスペクト比に基づき自動設定
item01_width = 200 # X軸のサイズ指定
aspect_ratio = item01.height / item01.width
item01_height = int(item01_width * aspect_ratio)
item01 = item01.resize((item01_width, item01_height))
# アイコンの配置位置を指定
item01_x = (width - item01_width) // 2 # X軸は中央
item01_y = 50 # 任意のY座標
img.paste(item01, (item01_x, item01_y), item01) # アルファチャンネルを保持
# 共通変数
black = "#000000"
orange = "#F95A35"
font01_path = "./fonts/Koruri-20210720/Koruri-Bold.ttf"
font02_path = "./fonts/Corporate-Logo-Rounded-Bold-ver3/Corporate-Logo-Rounded-Bold-ver3.otf"
font03_path = "./fonts/Koruri-20210720/Koruri-Regular.ttf"
gray = "#ccc"
# テキスト「お買い物ポイント」をアイコンの下から20pxの位置に配置 (item02)
item02 = "お買い物ポイント"
item02_font_size = 50 # フォントサイズ
item02_y = item01_y + item01_height + 20 # アイコンの下から20px
# フォントの読み込みとテキストの描画
font_item02 = ImageFont.truetype(font01_path, item02_font_size)
draw = ImageDraw.Draw(img)
item02_bbox = draw.textbbox((0, 0), item02, font=font_item02)
item02_width = item02_bbox[2] - item02_bbox[0]
item02_height = item02_bbox[3] - item02_bbox[1]
item02_x = (width - item02_width) // 2 # X軸は中央に設定
draw.text((item02_x, item02_y), item02, fill=black, font=font_item02)
# 追加のテキスト「48,000」の追加 (item03)
item03 = "48,000"
item03_font_size = 100 # フォントサイズ
item03_x = 80 # 任意のX座標
item03_y = item02_y + item02_height + 20 # item02 の下に20pxの位置
# フォントの読み込みと「48,000」の描画
font_item03 = ImageFont.truetype(font02_path, item03_font_size)
draw.text((item03_x, item03_y), item03, fill=orange, font=font_item03)
item03_bbox = draw.textbbox((0, 0), item03, font=font_item03)
item03_width = item03_bbox[2] - item03_bbox[0]
item03_height = item03_bbox[3] - item03_bbox[1]
# 追加のテキスト「(税込)※」の追加 (item04)
item04 = "(税込)※"
item04_font_size = 30 # フォントサイズ
item04_x = item03_x + item03_width + 10 # 任意のX座標
item04_y = item03_y # item03 と同じY座標
# フォントの読み込みと「(税込)※」の描画
font_item04 = ImageFont.truetype(font03_path, item04_font_size)
draw.text((item04_x, item04_y), item04, fill=orange, font=font_item04)
item04_bbox = draw.textbbox((0, 0), item04, font=font_item04)
item04_width = item04_bbox[2] - item04_bbox[0]
item04_height = item04_bbox[3] - item04_bbox[1]
# テキスト「円分」を item04 の下に配置 (item05)
item05 = "円分"
item05_font_size = 50 # フォントサイズ
item05_x = item04_x # 同じX座標に揃える
item05_y = item04_y + item04_height + 5 # item04の下に配置
# フォントの読み込みと「円分」の描画
font_item05 = ImageFont.truetype(font01_path, item05_font_size)
draw.text((item05_x, item05_y), item05, fill=orange, font=font_item05)
# 線を追加 (item05の下)
line_width = int(width * 0.9) # 線の幅(全体の90%)
line_height = 3 # 線の高さ
line_x = (width - line_width) // 2 # X軸は中央に配置
line_y = item05_y + item05_font_size + 70 # item05の下に配置
# 線の描画
draw.rectangle([line_x, line_y, line_x + line_width, line_y + line_height], fill=gray)
# テキスト「詳しくはこちら >」を線の下に追加 (text06)
text06 = "詳しくはこちら >"
text06_font_size = 45 # フォントサイズ
text06_y = line_y + line_height + 40 # 線の下から20px
font_text06 = ImageFont.truetype(font01_path, text06_font_size)
text06_bbox = draw.textbbox((0, 0), text06, font=font_text06)
text06_width = text06_bbox[2] - text06_bbox[0]
text06_x = (width - text06_width) // 2 # 中央揃え
# 「詳しくはこちら >」の描画
draw.text((text06_x, text06_y), text06, fill=orange, font=font_text06)
# 画像の保存 (WebP形式)
img.save(output_path, 'webp')
print(f"画像が{output_path}として保存されました。")
ひとまず、課題だった日本語のところはほとんどクリアできたかと。
また今後自分レベルの人間が改修を加えるとなった場合、可読性や拡張性を考えてかなり冗長な書き方にカスタマイズしました。
エンジニアが書いて、GPTにリファクタリングをお願いしたらもっと効率的なコードになると思いますが。
▼できた画像

コードを元に、派生バナーを作成
ここからが本来やりたかったことです。
このコードをまずGTPに読ませて、中身のテキスト追加修正したり、背景などに装飾をしてデザインパターンを増やしたいわけです。
とりあえず、マイGPTに登録をして簡単にコードを実行するようにしました。

結果は作成したコード通りのスタイルであれば、問題なく修正は可能でした。
- 48,000を64,000に変更
- オレンジ色のテキストカラーを青に変更
などです。
ただ、スタイルを少しでも変えたりしようした途端に崩れたり、何度かレスを重ねて誘導したりしないといけないのでここら辺はまだ弱いく、効率化なんて程遠いかなと思いました。

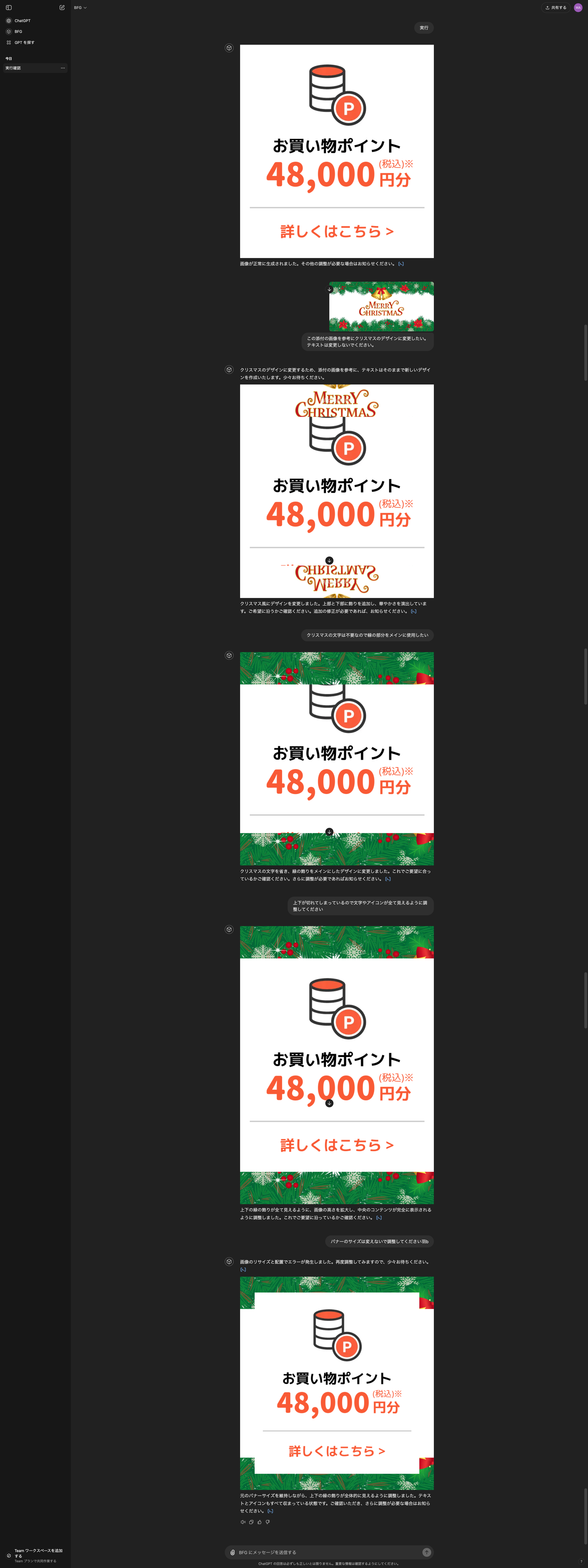
HTML/CSSをベースに画像作成を試してみる
ここで思いついたのは、html/cssを元に画像を生成できればと考えました。
-
- pythonよりはカバーできる人間が増えそう
-
- グループ化が楽
1は運用面ではメリットだと思います。
2は私がそこまでpythonを使いこなせなかったのもあるのですが、例えばテキストを追加すると、1部のテキストだけそのままの位置になったりというのがあったためです。
なのでHTMLであらかじめ、グループ化ができれば、意図せぬ崩れや、あとは条件分岐などもやりやすいかなって思いました。
▼できた画像

ただやってみた感じ、崩れはおこってしまうみたいです。
フォントなども上手く適用できず、そもそもCSS通りにスタイルが適用されなかったりしたのでここら辺も今後試していきたいところです。
まとめ
試行錯誤はしてみたものの理想とする形まではいきませんでした。
とはいえ、非エンジニアが1日2日で勉強しただけでも、なんとなく基盤みたいなのは作れました。
- パターン作成に強いベースのコードを作成
- その他画像生成AIの活用
ここら辺が課題になってくるので、引き続きトライエラーを繰り返して行きたいと思います。
AIに強い方や、何かアドバイスがあれば、ぜひ欲しいのでメッセージ頂けると嬉しいです!
その際は、非エンジニアであることを考慮いただけると幸いです🙇♀️