はじめに
ALSはNetflix Prizeで精度が高かった事で知られるMF(Matrix-Factorization)の手法の1つで、レコメンドシステムの中では協調フィルタリングに分類されます。MFについてはこちらのサイトがとても分かり易いと思います。
このALSについて、1~5の評価値推定(rating-prediction)の例を用いて説明します。
協調フィルタリング概要
協調フィルタリングは、各ユーザーに対応するアイテムの評価値行列(Rating行列)の類似度に基づいて推薦をする手法です。特にアイテムの類似度に基づく推薦をアイテムベース、ユーザーの類似度に基づく推薦をユーザーベースと言います。また、協調フィルタリングには推薦前にモデルを作成しておくモデルベースと推薦と同時にモデルを作成するメモリベース(近傍ベース)の2種類の方式があります。以下に協調フィルタリングの中でもモデルベース・メモリベースに特徴的な長所と短所を上げます。
- モデルベース方式
- 長所
- ・推薦時に時間がかからない
- ・次元圧縮によるコールドスタート問題解消
- 短所
- ・データの変化への対応性が低い(モデル構築に時間を要する)
- 長所
- ・データの変化への適応性が高い
- 短所
- ・推薦時に多くの時間を要する
- ・Rating行列が極端に疎である場合に各userとitem間の情報量が少なく、
類似度計算が上手く出来ず精度が出ない(コールドスタート問題)
モデルベースとメモリベースが互いに短所を補い合う関係性であることがわかります。
今回は行列分解を用いて次元圧縮を行うALS_WRについて説明します。
ALS_WR
図を用いた概説
ALS(Alternating-Least-Squares : 交互最小二乗法)はユーザーの数がm、アイテムの数がnのRating行列(m×n)を共通の長さを持つユーザーの特徴を持つU行列(r×m)と、アイテムの特徴を持つM行列(r×n)の行列積で再現する事を目標とします。
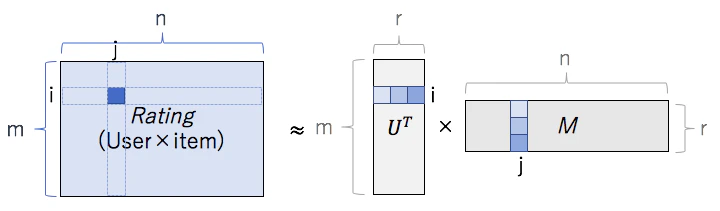
ここで気をつけないといけないのは、協調フィルタリングの問題においてRating行列内の欠損値が0で表されている事です。もし、Rating行列をそのまま学習させてしまうと、欠損値部分つまり予測値が0になるような学習結果になってしまいます。そのため、行列分解といってもそのまま分解するのではなく、評価値が入っているところのみを学習させます。
コスト関数と更新方法
論文 : Large-scale Parallel Collaborative Filtering for the Netflix Prizeを参考にしました。
ALS_WRはALSに正則化項を加えたもので、コスト関数 J は次の式で表されます。
J(U,M) = \sum_{(i,j)\in I} \left(r_{ij} - {\bf u}_i^T {\bf m}_j\right)^2 + \lambda \left( \sum_i n_{u_i}\|{\bf u}_i\|^2 + \sum_j n_{m_j}\|{\bf m}_j\|^2\right)
数式で用いられている記号
- $I$ : 評価値が格納されているインデックスの集合
- $r_{ij}$ : Rating行列の $i$ 行 $j$ 番目の値 ( $i \in$ [1,m], $j \in$ [1,n] )
- $\lambda$ : 正則化項の強さを指定する値
- $n_{u_i}$ : $I$ の $i$ 行のランク ( ユーザー $i$ が評価したアイテムの数)
- $n_{m_j}$ : $I$ の $j$ 列のランク ( アイテム $j$ を評価したユーザーの数)
前述したように学習に用いる値は欠損値を除いて行うので、第1項での $i$ , $j$ は $I$ に含まれる元を用いています。
UとMの更新は他方を固定して行われます。ここでは特にUの更新について説明します(Mも同様に更新を行う事ができます)。
Uについてのコスト関数Jの微分を整理すると(1)の式になるので、Uの更新は(2)の式で表されます。
\sum m_{kj}{\bf m}_j^T{\bf u}_i + \lambda n_{u_i}u_{ki} = \sum_{j\in I_i} m_{kj}r{ij}\,\,\,-(1)
\\
{\bf u}_i = \left(M_{I_i}M_{I_i}^T+\lambda n_{u_i}E\right)^{-1})V_i\,\,\,-(2)
- $V_i : M_{I_i}R^T(i,I_i)$
この更新を繰り返す事でUとMを学習します。
具体例
まず、次の表のように縦軸をuser、横軸をitemとして各ユーザーが評価した値の行列(4×5)を作成します。
| user\item | おしるこ | お味噌汁 | ヨーグルト | チョコレート | はちみつレモン |
|---|---|---|---|---|---|
| A | 5 | 0 | 2 | 0 | 0 |
| B | 0 | 0 | 0 | 4 | 5 |
| C | 4 | 5 | 0 | 0 | 0 |
| D | 0 | 2 | 0 | 5 | 0 |
この行列をALSを用いて2つの密行列U行列(4×2)とM行列(2×5)に行列分解します。

このU(4×2)とM(2×5)の行列積を計算すると、元の行列(4×5)の欠損値には値が補完され、評価値があった場所には近似値が入っている事がわかります。
| user\item | おしるこ | お味噌汁 | ヨーグルト | チョコレート | はちみつレモン |
|---|---|---|---|---|---|
| A | 4.87 | 3.99 | 1.98 | 2.09 | 3.57 |
| B | 5.92 | 5.30 | 3.85 | 3.98 | 4.95 |
| C | 4.01 | 4.81 | 6.41 | 6.49 | 4.97 |
| D | 0.85 | 2.15 | 4.88 | 4.89 | 2.56 |
ALS_WRの実装
- 実装に用いたデータ : MovieLensのMovieLens 100K Dataset
- 実装環境 : python3.5.2
common_len = 5 # 共通の長さを指定
noize_rate = 0.01 # 正則化項のlambdaの値を指定
epochs = 5 # epoch数の指定
# id_rating_lilにはscipy.sparse.lil_matrixで圧縮されたuser×itemの行列が入っています。
u_len, m_len = id_rating_lil.shape
# Iにはid_rating_lilの中で評価されている場所を格納(bool値)
I = id_rating_lil > 0
# U行列とM行列を1~5の間の値でランダムに初期値を設定
u = np.random.uniform(1, 5, u_len * common_len).reshape(u_len, common_len)
m = np.random.uniform(1, 5, m_len * common_len).reshape(common_len, m_len)
# 全データ数が100000でテスト用には各userのratingを1つだけ入れています。
training_len = 100000 - u_len
test_len = u_len
# training
for epoch in range(5):
# updata
for i in range(u_len):
I_i = np.array(I.getrow(i).todense())[0]
u[i] = np.dot(np.linalg.inv(np.dot(m[:, I_i], m[:, I_i].T) +
noize_rate * I[i].sum() *
np.eye(common_len)),
np.dot(m[:, I_i], id_rating_lil[i, I_i]
.transpose().todense())).transpose()
# 非負行列にするために0以下のものは強制的に0に変換
u[u<0] = 0
for j in range(m_len):
I_j = np.array(I.transpose().getrow(j).todense())[0]
m[:, j] = np.squeeze(np.array(np.dot(np.linalg.inv(np.dot(u[I_j].T, u[I_j]) +
noize_rate * I[:, j].sum() *
np.eye(common_len)),
np.dot(u[I_j].transpose(),
id_rating_lil[I_j, j].todense()))))
m[m<0] = 0
# predict
pred = np.dot(u, m)
# rmse算出
loss = np.sqrt((np.power((id_rating_lil - pred)
[np.array(I.todense())], 2).sum() / training_len))
# test_loss
test_loss = 0
for pair in rating_test_pair:
true_rating = rating_test_pair[pair]
test_loss += ((true_rating -
pred[pair[0] - 1, pair[1] - 1])**2) / test_len
print('epoch : {0:>3}, loss : {1:.7f}, test_loss : {2:.7f}'
.format(epoch + 1, loss, np.sqrt(float(test_loss))))
参考
- Y. Zhou, D. Wilkinson, R. Schreiber, and R. Pan, Large-scale parallel collaborative filtering for the netflix prize, 2008
- X. Su and T. M. Khoshgoftaar, A Survey of Collaborative Filtering Techniques, 2009
- http://blog.echen.me/2011/10/24/winning-the-netflix-prize-a-summary/
- https://www.slideshare.net/hamukazu/introduction-to-behavior-based-recommendation-system
- http://qiita.com/ysekky/items/c81ff24da0390a74fc6c