はじめに
今回記事作成者のE資格受験勉強のために記事を作成しています
間違いなどありましたらコメントにてご指摘いただけると幸いです。
目的
E資格受験対策としてGANの種類について学ぶ。
そのため、GANの実装は行わない。
GANの実装の詳細については、
最後の参考書籍に記載しているものを参考にしていただけると幸いです。
参考書籍
徹底攻略ディープラーニングE資格エンジニア問題集 第2版 [ スキルアップAI株式会社 小縣 信也 ]

GANとは
GAN(Gererative Adversarial Network)
敵対的生成ネットワーク
Generative Adversarial Netwark
Generative : 生成
Adversarial:敵対的
GANは、正解データを与えることなく特徴を学習する「教師なし学習」の一手法
実在しない画像を生成する
多様性と画質はトレードオフの関係にある
-多様性を重視すると画質が荒くなる
-画質を重視すると多様性が失われる
VAE(オートエンコーダー)はデータ分布をパラメータをもつモデル分布で表現されるが生成画像がぼやける問題が発生する
GANはニューラルネットワークを用いて、確率分布を最適化することで鮮明な画像を生成できるが、学習が収束しない難しさがある。
GANの学習目標
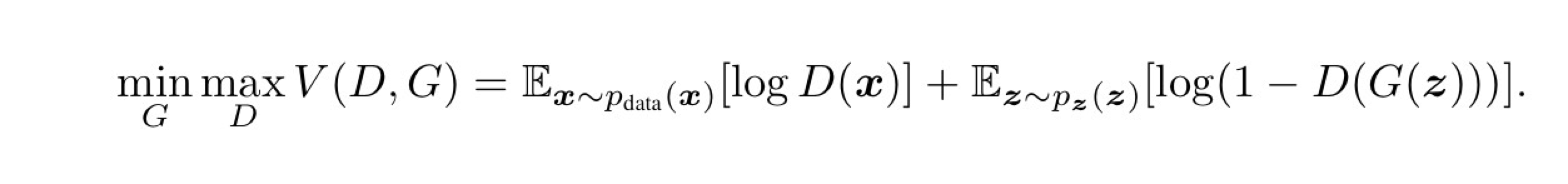
x:訓練データ
z:ノイズ
D(x):Dが予測した、訓練データxが人材データである確率
G(z):ノイズzを入力としてGが生成するデータ
G (Generator)
生成器
詐欺師に例えられることが多い
Discriminatorにバレないように訓練データそっくりの画像を生成する
Generatorはlog(1-D(G(z)))を最小化しようとする
つまり、Generator自身が生成したデータ「G(z)」をDiscriminatorに本物だと思わせること
D (Discriminator)
識別器
鑑定士に例えられることが多い
Generatorが生成したサンプル化、訓練データとしてあたえられたサンプルかを識別する
Discriminatorは訓練データxと生成データG(z)に対して、正しいラベル付を行う確率を最大化しようとする
参考URL:
GAN:敵対的生成ネットワークとは何か ~「教師なし学習」による画像生成
GAN(敵対的生成ネットワーク)について説明します!
GANの種類について
画像生成のGAN
GAN (2014)
画像生成のGAN
出力サイズは28×28の低解像度画像生成する。
GとDの学習バランスの調整が難しいことが課題である。
GANの学習が困難である原因としては、GeneratorよりもDiscriminatorの方が早く学習が進んでしまうことである。
この対策としては、Unrolled GANが有用である。
他にも、
mode collapseが起きてしまうことなどが挙げられる。
mode collapseとは、Generatorの能力が不足していることによって一つのデータ(最頻値)しか出力されなくなってしまう状態のことである。
この対策としてはMinibatch Discimination(ミニバッチを作成し、その中の画像がにているかどうかのスコアを算出し、その値をDiscriminatorに与える手法),Wasserstein GAN(EMDを用いることで学習を安定させる)が有用である。
Generatorと訓練データの分布の近さを測る際、通常のGANではJSDを用いる。
EMDとは特徴量と重みの集合で与えられる分布Pと分布Qの間の距離のことである。
参考URL:①Q41
Wasserstein GAN
Generatorと訓練データの分布の近さを測る際、通常のGANではJSDを用いるが、
Wasserstein GAN(EMDを用いることで学習を安定させる)が有用である。
(EMDとは特徴量と重みの集合で与えられる分布Pと分布Qの間の距離のことである。)
学習の安定化のため、通常のGANでは、Generatorと訓練データの分布を近づける際にJSDという距離を用いるところを、EMDという距離を用いている
GANに比べて学習が安定しやすく、mode collapse問題を避けることができる。
プロットが収束するのでいつGANの学習を終えればいいか判断できる。
参考URL:①Q75
高解像度画像生成のGAN
LAPGAN (2015)
256×256の中解像度画像生成のGANである。
GANから低解像度と高い解像度の差を学習させることにより改善したGANである。
低解像度と高解像度の画像の差を学習することにより、低解像の画像からだんだんと高解像度の画像を生成できるようにするモデルである。
何段にも分けて画像を生成する必要があることと、複数のGereratorを用意する必要があり、計算コストが高いのは問題である。
①Q75
DCGAN (2015)
64×64の中解像度画像生成のGANである。
LAPGANにCNNを導入することでピクセル間の関係性を学習し改善したGANである。
2つのネットワークにCNNを用いて、可視化することで生成モデルに解釈性を与え、GPUを有効活用し、計算コストを下げることができる。
オリジナルのGANのようにGeneratortorとDiscriminatorに全結合層を使用するのではなく、畳み込み層と転置畳み込み層を用いたモデルである。
プーリングは用いられていない。
学習の安定化のため、Batch Normalization,ReLU,tanh,LeakyReLUを用いていることも特徴である
クラス分類は行わず、ネットワークにたたみ込みそうと転置たたみ込み層を使用することで、鮮明な画像生成を可能とした。
①Q75
PGGAN (2017)
1024×1024の高解像度画像生成のGANである。
DCGANから段階的な高精度画像生成手法を使ったGANである。
低解像度画像生成から段階的に高解像度生成を実現したが、一つのモデルで何階もやらないといけないため、計算コストは高い。
初期段階は低解像度の画像を与え、少ないそうで学習を行い、学習がすすむにつれて与える画像の解像度を上げ、層を深くしていくモデルである
学習が進むにつれて徐々に層を深くすることで、1024 × 1024 という従来では困難であった高解像度の画像生成に成功した。
①Q75
SinGAN (2019)
単一の画像を使って学習し、超解像・ハーモナイズ・アニメーション化といった様々なアプリケーションへの応用が可能なGANである。
単一の画像を高解像度化するように学習を行う。
[Generator]低解像度画像と高解像度画像の残差を学習をし、
[Discriminator]アーキテクチャはGと同じである。
高解像度化、絵から画像へ、編集、調和の4種類ある。
1枚の学習画像から、類似した画像を生成できる。
Generatorは、たたみ込みそうのみから構成され、任意の画像サイズで出力することができる。
損失関数は、通常のadversarial lossとCycleGAN等でも使われているreconstruction lossの和で表せれる。
SinGANのDiscriminatorでは、バッチ(画像をいくつかに区切ったうちの1区間)ごとに真偽を判定する。
SinGANは、1枚の画像から類似した画像の生成が可能である。
1枚の画像から生成を行うことのできるGANは他にも存在したものの、テクスチャ画像に適用できなかった。
(テクスチャとは、3Dグラフィックスにおいて物体の質感を表現するために使われる画像のこと)
テクスチャ画像に限定せずに1枚の画像から生成できる点が大きな特徴である。
Generatorは5つのたたみ込みブロックを持つ全てたたみ込みそうからなるネットワークである。
ノイズマップの次元を変えることで、任意のサイズやアスペクト比の画像生成が可能である。
損失関数は、通常のadversarial lossと、CycleGAN等でも使われる reconstruction lossの和で表され、それぞれの比率有αで調整する小僧となっている。
SinGANは超解像(低解像度の画像の入力として、高解像度の画像を生成する操作)などに応用される。
参考URL:①Q100
クラス指定画像生成のGAN
CGAN (2014) (ラベル付必要)
Conditional GANともいう。
データセットのクラス情報をGeneratorとDiscriminatorに与える。
データセットのクラス情報を学習に用いることで、従来のGANより生成画像の質と識別性を向上させたGANである。
①Q76
ACGAN (2016) (ラベル付必要)
入力画像にラベル付(クラス分類)を行い生成器で学習させ、識別器でもクラス分類結果を出力するGANである。
Generatorに入力画像のラベルを与えることに加え、
Discriminatorは生成画像の真偽判定だけでなくクラスの分類も行う。
ImageNetの画像において、DCGANより高精度な画像生成を実現した。
Discriminatorに補助のクラス分類器をつけたGANである。
Dは精製画像の真偽判定とクラスの分類タスクを担う。
識別性の高い+高解像度の画像精製を目標として、結果として「ノイズzは”大局的な構造”をclassは”局所的な特徴”を表現できるのではないか」という仮説を提唱した。
①Q76
InfoGAN (2016) (ラベル付不要)
データのラベル付が不要であり、画像生成の際に重要となる潜在変数を獲得することで性能向上を図ったGANである。
生成時に利用価値の高い特徴量を教師なし学習で獲得するため、cGANのようにラベル付されたデータの準備は不要である。
生成時に利用価値の高い特徴量を教師なし学習で獲得するGANである。
cGANの「class」を「Intent(潜在変数)」で代用することにより改善したGANである。
潜在変数は「クラス」「太字」「斜め」などの意味を内在することがわかる。
①Q76
SAGAN (2018)
Self-attention GAN(SAGAN)ともいう。
PGGANからSelf-AttentionでConvそうの課題を乗り越えるGANである。
局所的な特徴に注目するConv層 には「長期依存性」と「高い計算コスト」の課題があると提唱した。
Self-Attention を用いることで、画像のより大局的な特徴に注目し、さらに計算コストを抑え、局所的な情報を持ってくるデメリットを解消したモデルである。
GeneratorとDiscriminatorで異なる学習率を使った手法で、SAGANで用いられている
GANに安定性に大きく貢献したSpectral Noramlizationを、SNGANはD(Discriminator)だけ使っていたが、このSAGANではG(Generator)にも使うのが大きな特徴
D:G=1:1は訓練が不安定になりがちだが、TTUR(Two Time-Scale Update Rule)を使用することで安定性を確保している。
Self-sttention
一つの系列内において各要素が他の要素に対して、どのような関連性があるのかを見る。
参考URL:①Q77
BigGAN (2018)
SANGAN に Truncation Trickを導入したGANである。
BigGANはSAGANを、ベースラインとして構成されている。
出力画像のカテゴリーもコントロールできる高解像度画像生成のGANである
Truncated Trickという手法が用いられている。
ノイズの閾値を設けることで多様性と画質のバランスを調整がk脳
閾値が大きいと多様性が出る
閾値が小さいと画質が上がる(自然な仕上がり)
スケールが大きく学習コストがかかる。
出力画像のカテゴリーもコントロールできる高解像度画像生成のGANである。
参考URL:追Q13
StyleGAN (2018)
StyleGANはPGGANをベースラインとして構成されている。
PGGANのGにStyle要素を与えられたGANである。
PGGANのGにFC層×8で学習したStyleを組み込み、StyleはAdaINによって調整される。
画像の雰囲気を残し、本物とみちがえるような高解像度画像の生成を行うGANである。
各層に入力する(スタイル情報となる潜在空間)を途中で切り替えることでスタイルミックスが可能である。
StyleGANにおけるAdaINの式はURLを参考。
学習対象のパラメータは存在しない。
参考URL:追Q13
画像変換のGAN
pix2pix (2016)
画像から画像を作るGANである。(手書きの絵を写真のような画像出力する)
cGANからconditional vectorを画像(林間、白黒)として入力し改善したGANである。
GAN画像変換の礎になっている。
同一のモデル構造で様々なタスクを解くことができる。
1ペアの画像の関連性を学習する。
画像をなにかしらの加工を施した画像へと変換して生成するGANである。
Discriminatorの損失関数にL1lossを加えることでGeneratorにU-Netが使用されている。
①Q77
CycleGAN (2017)
馬⇄シマウマのように画像のドメインを変換するGANである。
ドメインの違う二つの画像のデータセット間において、ドメイン間の対応関係を学習するモデルである。
2画像群を用意し、それぞれからランダムに色・形状の異なる画像の「変換の変換」と元画像との差を埋めるように学習する。
①Q77
StarGAN (2017)
複数ドメインのデータを1つのGeneratorで変換可能にしたモデルである。
単一モデルで複数のドメイン変換を可能にしたGANである。
顔の表情変換させる画像作成を可能にした。
CycleGANから複数群間の変換が可能にし、1つのGANで複数の画像群の対応関係を学習する。
どのドメインの画像かを表現できるmask vectorを導入することで、複数画像群間のGAN学習を効率化し、1対1から1対多数まで行えるようになった。
①Q77
その他のGAN
テキストから画像生成するGAN
StackGAN (2016)
テキストから画像を生成するGANである。
第一段階としてテキストから荒い画像を生成(スケッチ)、第二段階としてその画像とテキスト埋め込みベクトルを用いて高品質の画像を生成(精製)する。
テキスト埋め込みベクトルの平均μと分散Σを用いてGeneratorへの潜在変数をN(μ,Σ)からサンプリングすることによって学習を安定させている。
①Q78
異常検知のGAN
AnoGAN (2017)
AnoGANは異常検知に用いられるモデルである。
画像内の異常検知を行うGANである。
GANの入力を変化させて入力画像にできるだけ近い画像を生成する。
入力画像が潜在空間に含まれていない場合(正常画像でない場合)、うまく画像生成ができないため異常と判断する。
正常画像のみで通常のGANと同じような学習を行い、入力画像を潜在空間に逆写像し、元の画像と同じになるようなzを探索する。
AnoGANの損失関数は、Residual LossとDiscrimination Lossが用いられる。
①Q78
参考書籍
GANの詳細や実装方法については下記書籍をおすすめします。

物体検出とGAN、オートエンコーダー、画像処理入門 PyTorch/TensorFlow2による発展的・実装ディープラーニング [ チーム・カルポ ]

最短コースでわかる PyTorch &深層学習プログラミング [ 赤石 雅典 ]

E資格試験対策には下記書籍をおすすめします。
徹底攻略ディープラーニングE資格エンジニア問題集 第2版 [ スキルアップAI株式会社 小縣 信也 ]
ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装 [ 斎藤 康毅 ]

ゼロから作るDeep Learning 2 自然言語処理編 [ 斎藤 康毅 ]
