この記事について
記事作成者が理解できていなかった用語についての説明をまとめています。
今回はDS検定対策講座の資料や公式テキストなどを参考にしながら作成していますが、
内容に間違いがある場合は、コメント欄で出典先と間違えている点ご教授いただければ幸いです。
公式テキスト
最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック [ 菅由紀子 ]
公式テキストの修正箇所

講座テキスト、模擬試験内容
9
階層クラスター分析
階層化するというのは、似ているもの同士を順番にまとめていく方法
クラスター分析では、データが持つ特性の差を距離で表し、距離が小さいものを似ていると判断します。
距離が小さいものから順にトーナメント表のようにまとめていく
クラスター数によって、トーナメント表の上から分けていく
ウォード法
公式p71
11
データ可視化
データの可視化をすることにより
・データの異常値や外れ値の存在
・周期性とノイズ
・対象間の類似性
・なぜそのような分布になっているのか
・この分布や法則性の背後に何が隠れているか
相関係数は可視化しても分かりません。
公式p94
15
公式p121
画像データのクリーニング処理
リサイズ
全ての画像の縦横比(アスペクト比)を保った状態、
もしくはアスペクト比を固定しない状態(縦か横に画像が引き伸ばされる)で拡大・縮小し、画像サイズを変更する
顔が歪んだりしないようにするため、アスペクト比を固定してリサイズしたりする
アスペクト比 → 縦横比
トリミング
画像を特定のサイズになるようにはみ出した部分を切り落とす
パディング
不足する部分を適当な色の幅セルで埋め合わせる
正規化
最大値や最小値で統一する
標準化
平均と分散で統一する
17
ER図
公式p136
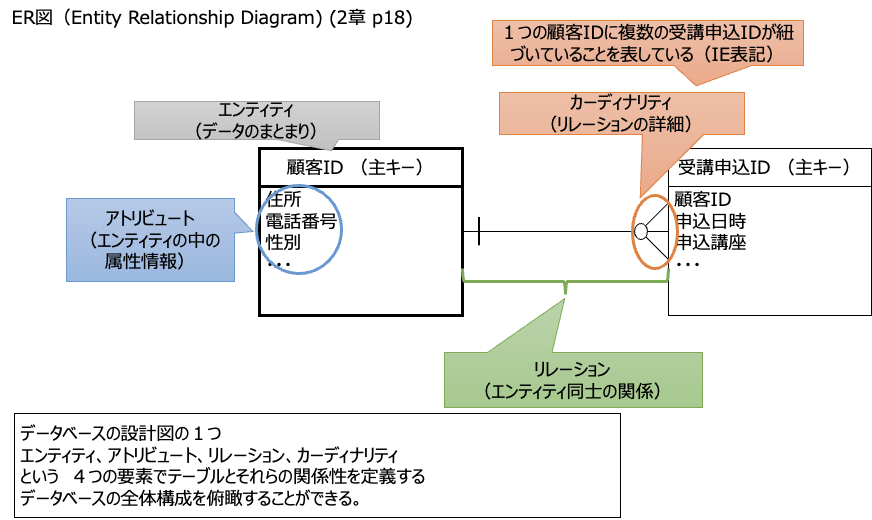
データベースに関するER図を構成する要素は、
エンティティ、リレーション、アトリビュート、カーディナリティの4つです。
エンティティはデータのまとまりを表す概念です。
リレーションはエンティティ間の結びつきを表します
アトリビュートはエンティティ内における属性のことです。
カーディナリティは、「1対1」「1対多」「多対多」など、
リレーションの関係を表します。 多重度とも呼びます。
レコードは、データベースのテーブルにおける行のことです。
ER図を用いることで、角テーブルの関係性を整理された状態で見渡すことができ、
データベース設計者以外の人が設計内容を理解しやすくなリます。
リレーションは
データが双方存在の依存関係
データが片方しか存在しない非依存関係
n:mの関係
18
公式p137
テーブルの正規化
データの重複を無くし、テーブルから冗長性を取り除いた状態にすること
- データの追加や更新、削除などの操作がしやすくなり、メンテナンス効率が向上
リレーショナルデータベースの設計においては、「正規形」という概念が用いられる
リレーショナルデータベース(RDB)において
テーブルから冗長性や不整合を取り除くことをテーブルの正規化という。
非正規形
データの冗長性が不整合がある状態
第一正規形
下記のようなデータ状調整が不整合が解消された状態
・同じ列が複数ある
・1つのセルの中に複数の値が入っている
・結合セルが存在する
同一行内における繰り返しなどを解消したものを第一正規形と呼ぶ
⇨同じ属性の繰り返しがあるデータの繰り返しの排除をする。
⇨講座名は講座コードに従属している状態はまだ第一正規形
名前 講座名 講座名 講座名
Aさん B講座 C講座 D講座
↓
名前 講座名
Aさん B講座
Aさん C講座
Aさん D講座
第二正規形
第一正規形を満たし、
「主キーのいずれかが定まれば非キーのいずれかが定まる状態」
が解消された状態
第一正規形を満たし、非キーの一部に従属するものを別のテーブルに分離したものを第二正規形と呼ぶ
⇨講座コードと講座名を元のデーブルから分離し、テーブルが2つある状態
名前 年齢 講座No 講座名
Aさん 28 BBBB B講座
↓
主キー
名前 年齢 講座No
Aさん 28 BBBB
非キー
講座No 講座名
BBBB B講座
このようにテーブルを分けることでみやすくする
第三正規形
第二正規形を満たし、
「非キーのいずれかが定まれば、他の非キーのいずれかが定まる状態」
が解消された状態
第二正規形を満たし、主キー以外の項目同士が従属関係をもつものを別のテーブルに分離したものを第三正規形
非キーのテーブルでさらに第二正規形のように行う
まとめ
リレーショナルデータベース(RDB)において
テーブルから冗長性や不整合を取り除くことをテーブルの正規化という。
同一行内における繰り返しなどを解消したものを第一正規形と呼ぶ
第一正規形を満たし、非キーの一部に従属するものを別のテーブルに分離したものを第二正規形
第二正規形を満たし、主キー以外の項目同士が従属関係をもつものを別のテーブルに分離したものを第三正規形
同じもの繰り返していると長くなりやすいのと、修正した際に全ての行を修正するのは面倒なので
第一正規で繰り返して横に長いものを解消させる
第二正規で主キーと非キーのテーブルを分け、
第三正規で非キーと非キーのテーブルを分ける
第二正規、第三正規で分けることによって
コードNoや内容が変わった際に、対応しやすくする。
リレーショナルデータベースの運用をしやすくするために、正規化を行っていく。
19
分散技術
HadoopやSparkの分散技術とは、ネットワークで接続した複数のコンピュータで分担して処理を行う技術
一般的なRDBMSと比較して、対象データが大規模で更新が少なく、構造が変化しやすい場合に向いている。
処理の性能を上げたい場合は、ノード数を増やすという方法で対応できるのも特徴
Hadoop
実際には複数サービスを組み合わせたもので、多様な環境構成になっている
特定のレコードを指定したデータの更新はあまり推奨されていない。
・単純なサーバの追加によってスケーラビリティを実現
・非定型データの格納を想定した処理の柔軟性を実現
・コモディティ品の利用を前提とした基盤構成・耐障害性
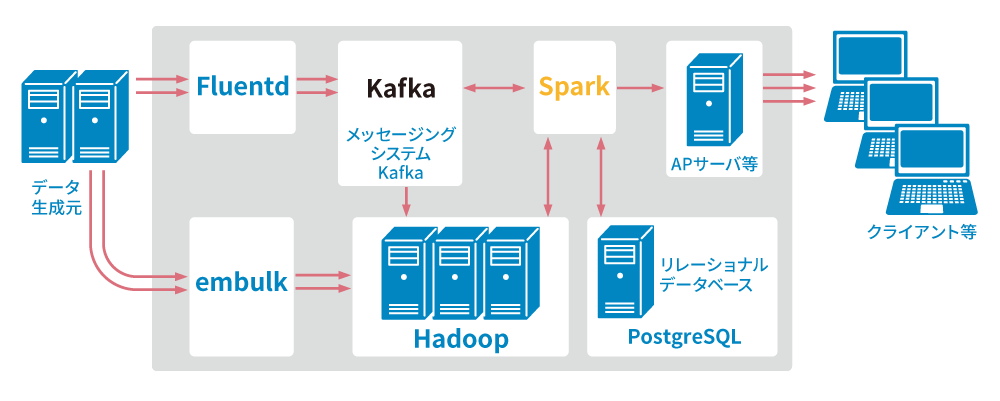
Spark
Hadoop関連プロジェクトに含まれており、環境構成のパターンがより複雑になる。
分散技術そてい特徴的な機能であり、
Sparkでも用いられるHadoopベースの技術としては、大規模クラスタ上の分散ファイルシステムであるHDFS(Hadoop Distributed File System)と、
分散技術における汎用的なクラスタ管理システムであるYARNがある。
23
json
"JavaScript Object Notation"
「JavaScriptの中でオブジェクトを記述する書式」
データフォーマット(データを扱う際の決まりごと、CSVやXML)の一種。
特に表で表しにくい構造のデータに適している。
拡張子は.json
CSV
CSVとは、テキスト(文字)データの形式の一つで、項目をカンマ「,」で区切って列挙したもの。複数の項目をレコードとしてまとめる場合は、改行でレコードの区切りを表す。標準のファイル拡張子は「.csv」。
XML
XMLは、文章の見た目や構造を記述するためのマークアップ言語の一種です。
主にデータのやりとりや管理を簡単にする目的で使われ、記述形式がわかりやすいという特徴があります。
HTML
WEBページにある文字
HTMLとは「Hyper Text Markup Language」の略です。Webページを記述するための表示用言語で、XMLと同じく文章中の文字列をタグで挟むことで、Webページに装飾を施すのが目的です。簡単にいうと、人間に情報をわかりやすく表示するための言語といえます。
24
公式p163
SQLのコード
3章を参考
SELECT 列名 FROM テーブル名 ;
テーブルから列を取得する。
列名を「*」にすると、全部の列を選択することができる。
複数列数を取る場合は「, 」で区切ればできる。
SELECT
データ参照
INSERT
データ挿入
DELETE
データ削除
FROM
操作対象のテーブルを指定
JOIN
2つ異常のテーブルの結合の設定
WHERE
操作対象データの条件抽出
GEOUP BY
データの集計
HAVING
GROUP BUで集計した後のデータに対する条件抽出
EXISITS
外側のSQLとEXISTS句内SQLの存在判定や相関副問い合わせ
CASE
SQLの中で条件分岐
DISTINCT
重複行の削除
ASC
昇順
DESC
降順
GROUP BY
データをグループ化して集計関数を適用する場合に使用される句
ORDER BY
データを並び替えるときに使用される句
LIMIT
最終的に取得(表示)するデータ件数を指定するために使用される句
ただし、SQLサーバーのデータ読み取り量は変わらないので注意
→クラウドサーバーなど使用している場合、多額な請求になる場合もある
WHERE
WHERE 列名 条件 ;
指定した条件に該当する行を取得するときに使用される句
AND、OR、NOTを用いて複数条件の指定が可能
BETWEEN
~以上〜以下
IN
~に含まれている
LIKE
文字列検索に用いる
%
任意の長さの文字
"A%" : Aから始まる任意長さの文字列を取得する
_
1文字
A_y : Aからはじまりyで終わる3文字の文字列を取得(Amyなど)
HAVING
グループ化したデータに対して、条件にあったデータを選択するときに使用
3章p95
JOIN
テーブル結合