TL;DR
- 機械学習や統計で基本となるCSVデータの扱い方を書きます。
- Juliaでは、CSVをDataFrameとして扱うことができます。
- RやPythonでCSVを扱ったことがあればすぐに使いこなすことができます。
下準備編
専用パッケージの追加
このコードを実行することでCSVを扱うために必要なパッケージが追加されます。
スクリプトでも実行可能ですが、Repl環境で実行することをおすすめします。
using Pkg
Pkg.add("CSV")
Pkg.add("DataFrames")
パッケージのロード
このコードを実行することでCSVパッケージがロードされます。
初回はビルドが走るので若干時間がかかります。
using CSV
using DataFrames
本編
前提条件
解説のためにこのCSVデータを扱います。タイタニック乗客のデータです。
http://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv
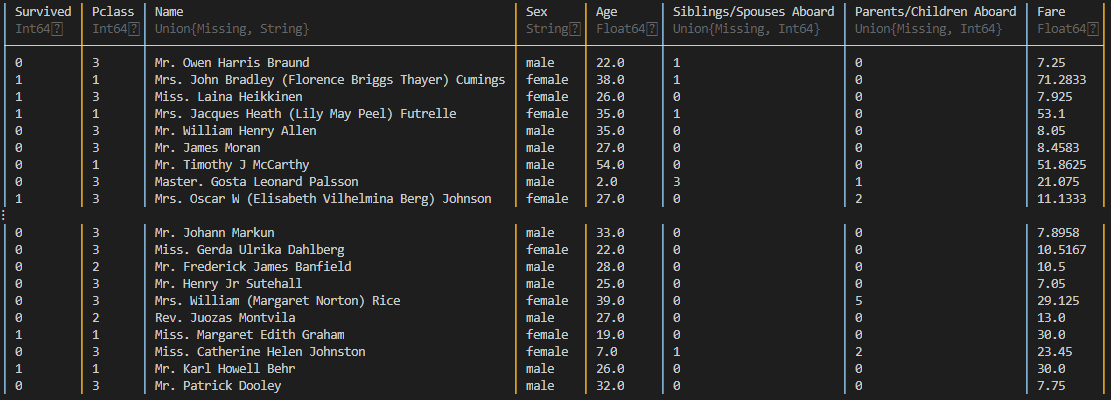
詳細を知りたい方は以下リンクを参照してください。
http://web.stanford.edu/class/archive/cs/cs109/cs109.1166/problem12.html
CSVをデータフレームとしてロードする
CSV.read(ファイルパス, DataFrame)を使います。
次のコードを実行することで、titanicにCSVがデータフレームとして代入されます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame) # ロード
データフレームをCSVとしてセーブする
CSV.write(ファイルパス,dataframe)を使います。
次のコードを実行することでoutput.csvという名前でセーブできます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
CSV.write("./output.csv",titanic) # セーブ
列を指定して配列として取得する
列番号で指定
dataframe[列番号]で取得できます。
※ Juliaはインデックス番号が1から始まるので注意。
次のコードを実行することで1列目のSurvivedを配列として取得することができる。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
survived = titanic[1]
列名で指定
dataframe.列名で取得できます。
次のコードを実行することでSexの列を配列として取得することができる。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
sex = titanic.Sex
dataframe[:列名]のように書くこともできます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
sex = titanic[:Sex]
dataframe[Symbol("列名")]のように書くこともできます。
列名に空白が入っている場合に便利です。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
parentChildren_Aboard = titanic[Symbol("Parents/Children Aboard")]
列を指定して切り抜く・並び替える
dataframe[[:列名1,:列名2,:列名3,...]]で列の切り抜き・並び替えができます。
次のコードでSex,Name,Ageのデータフレームを作成できます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
titanic2 = titanic[[:Sex,:Name,:Age]]
行を指定して切り抜く・並び替える
dataframe[[行番号1,行番号2,行番号3,...],:]で行の切り抜き・並び替えができます。
次のコードで3行目、4行目、8行目を切り抜いたデータフレームを作成できます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
titanic2 = titanic[[3,4,8],:]
ある行からある行までまとめて切り抜く場合はdataframe[行番号1:行番号2,:]のように書くこともできます。
次のコードで10行目から20行目までを切り抜いたデータフレームを作成できます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
titanic2 = titanic[10:20,:]
条件に合う行を切り抜く
dataframe[行数分のtrue/false配列,:]でtrueの行だけ切り抜きます。
次のコードでSexがfemaleの行だけ切り抜いたデータフレームを作成できます。
※Juliaでは、f.(array)のように.を付けて関数を実行するとmap(f,array)のように動作します。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
function isFemale(sex)
return sex == "female"
end
female = titanic[isFemale.(titanic.Sex),:]
このケースではもっと簡単に、次のように書くこともできます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
female = titanic[titanic.Sex .== "female",:]
Ageが20以上の行を切り抜く場合は次のように書きます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
over20 = titanic[titanic.Age .>= 20,:]
データの書き換え
dataframe[行番号,:列名] = 書き換えたい値で値を書き換えることができます。
次のコードでは一行目のSexをboyに書き換えます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
titanic[1,:Sex] = "boy"
例えば、Sexのfemaleをgirl、maleをboyに書き換えるには次のように書きます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
titanic[titanic.Sex .== "male",:Sex] = "boy"
titanic[titanic.Sex .== "female",:Sex] = "girl"
ソート
CSV.sort(dataframe,:列名)でデータフレームをソートすることができます。
次のコードではAgeを基準にソートします。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
ageSorted = CSV.sort(titanic,:Age)
行数、列数を取得する
size(dataframe)で取得できます。
列数はsize(dataframe)[1]、行数はsize(dataframe)[2]です。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
row = size(titanic)[1]
col = size(titanic)[2]
簡単な情報を表示する
CSV.describe(dataframe)で各列の中央値、平均値などの簡単な情報を確認できます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
CSV.describe(titanic)
出力

クロス集計
CSV.by(dataframe,:グルーピングする列名,:列名1 => 関数1,:列名2 => 関数2...)で行えます。
関数1にはグループの列名1から切り出した値の配列を引数として与えられます。
同様に関数2にはグループの列名2から切り出した値の配列を引数として与えられます。
例えば、性別による生存者、死者の集計は次のコードで行えます。
using CSV
using DataFrames
titanic = CSV.read("./titanic.csv", DataFrame)
by( titanic,
:Sex, # Sexでグルーピングする
:Survived => sum, # Survivedが1の場合は生存なので、合計すると生存者数になる
:Survived => x -> sum(x.==0) # Survivedが0の場合は死者なので、0の数を合計すると死者数になる
)
出力
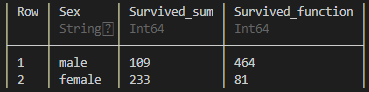
結合
vcat(dataframe1,dataframe2)で縦方向に結合できる。
hcat(dataframe1,dataframe2)で横方向に結合できる。
最後に
「dplyrないの?」「LINQ使いたい」って方はDataFramesMetaを使うと気持ちよくなれるかもしれません。
https://github.com/JuliaData/DataFramesMeta.jl
これについても書きたかったですが、力尽きました。
「●●が入ってないやん」
「●●が間違ってる」
「●●の方がスマート」
等のマサカリ大歓迎です。
「良かった」
「悪かった」
「タヒね」
等の感想いただけると大変うれしいです。