はじめに
前回の記事で構築したOllama + Difyの環境でRAGの修行です。
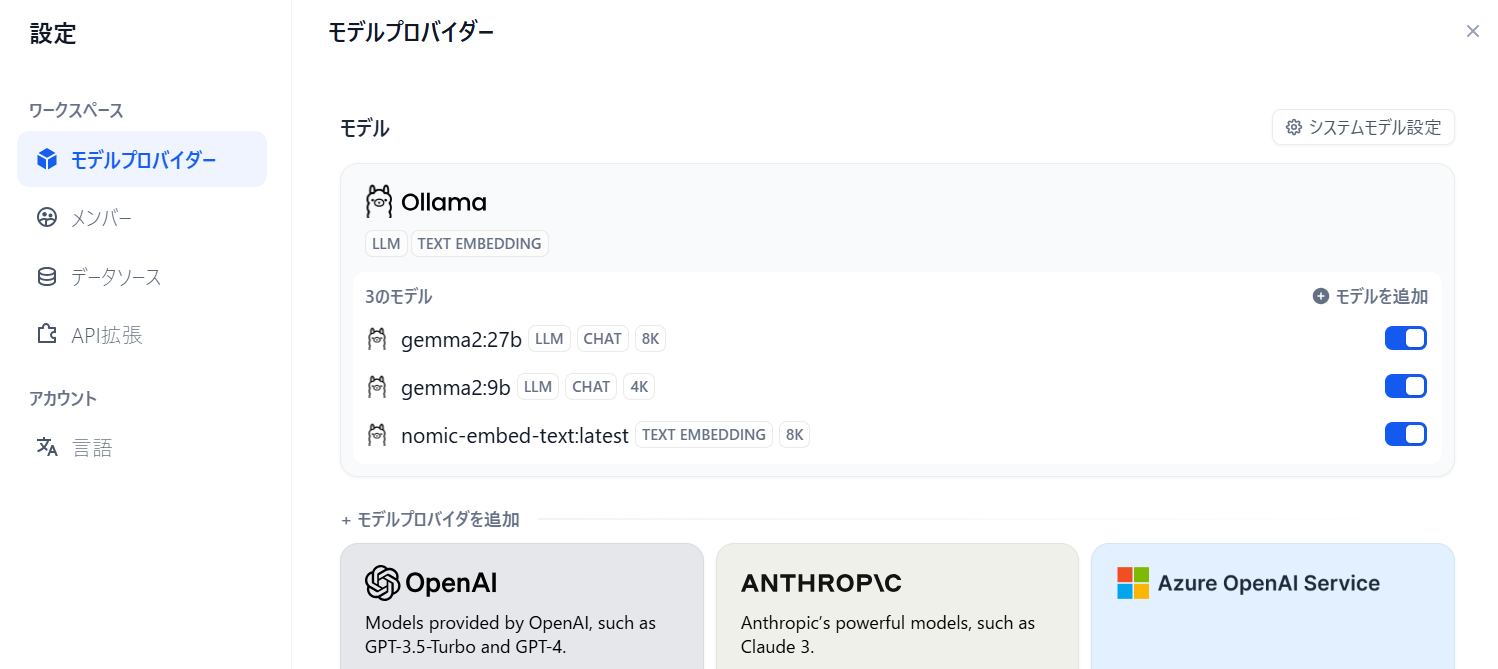
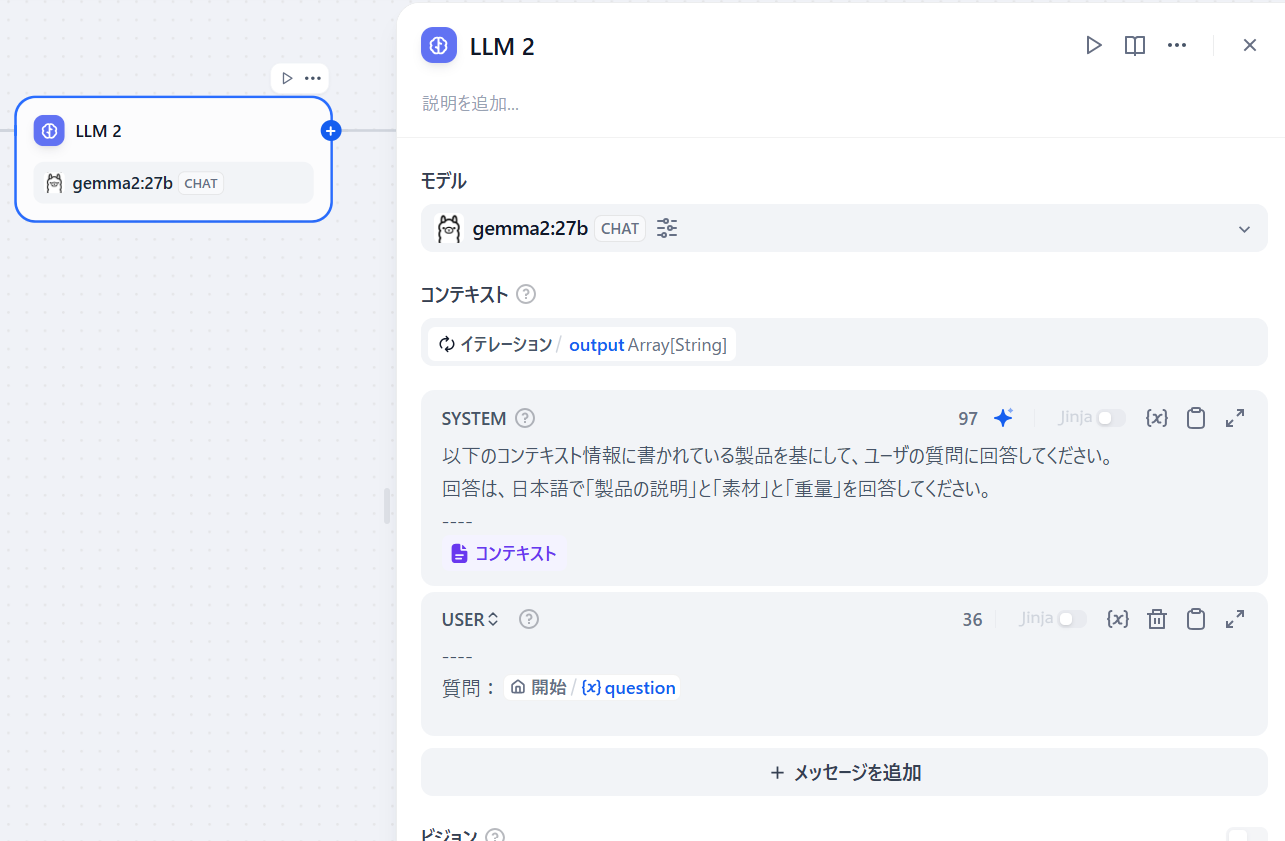
モデル
モデルは次のものを追加しました。
ナレッジ
アウトドアウェアでお世話になってるフルマークスストアの製品情報をテキストファイルでまとめてみました。
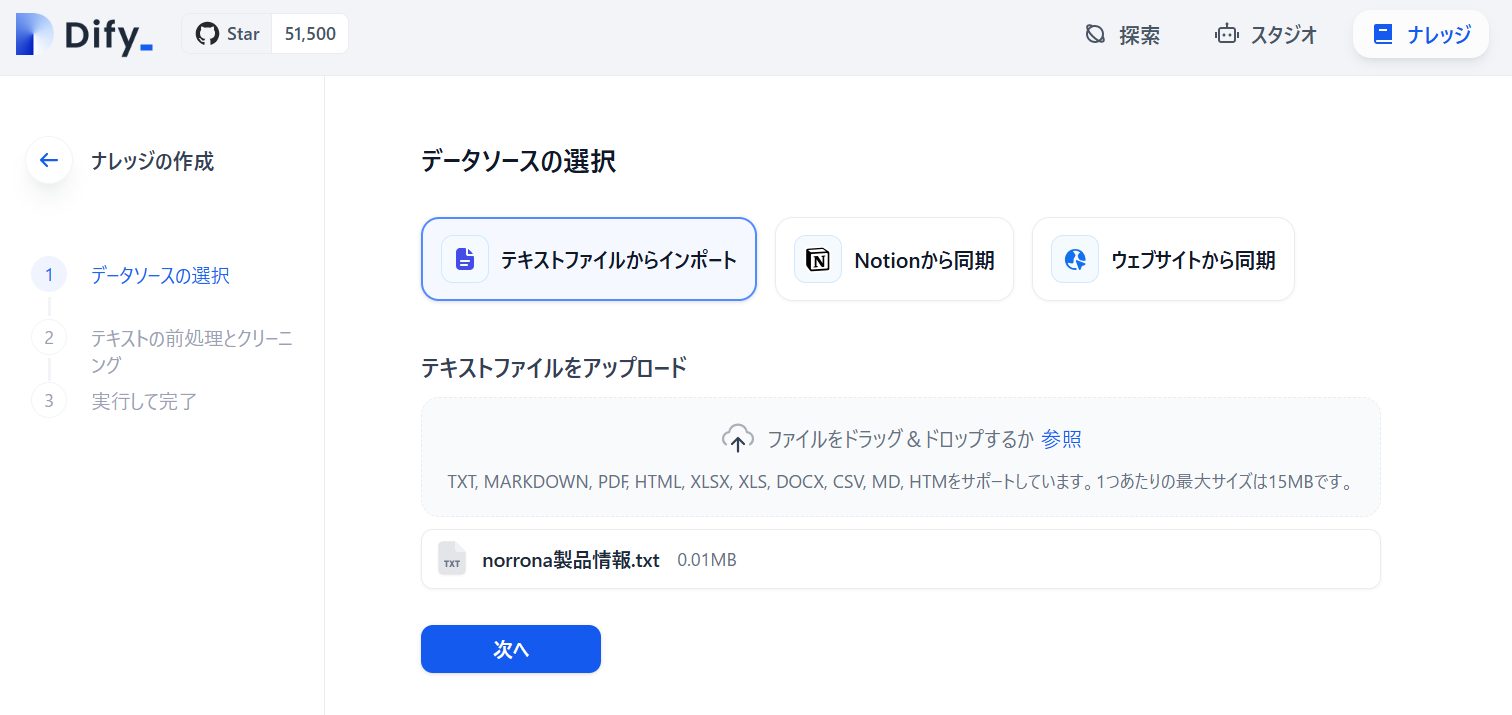
ナレッジの作成で、テキストファイルからインポートします。
自動で高品質のベクトル検索にしました。
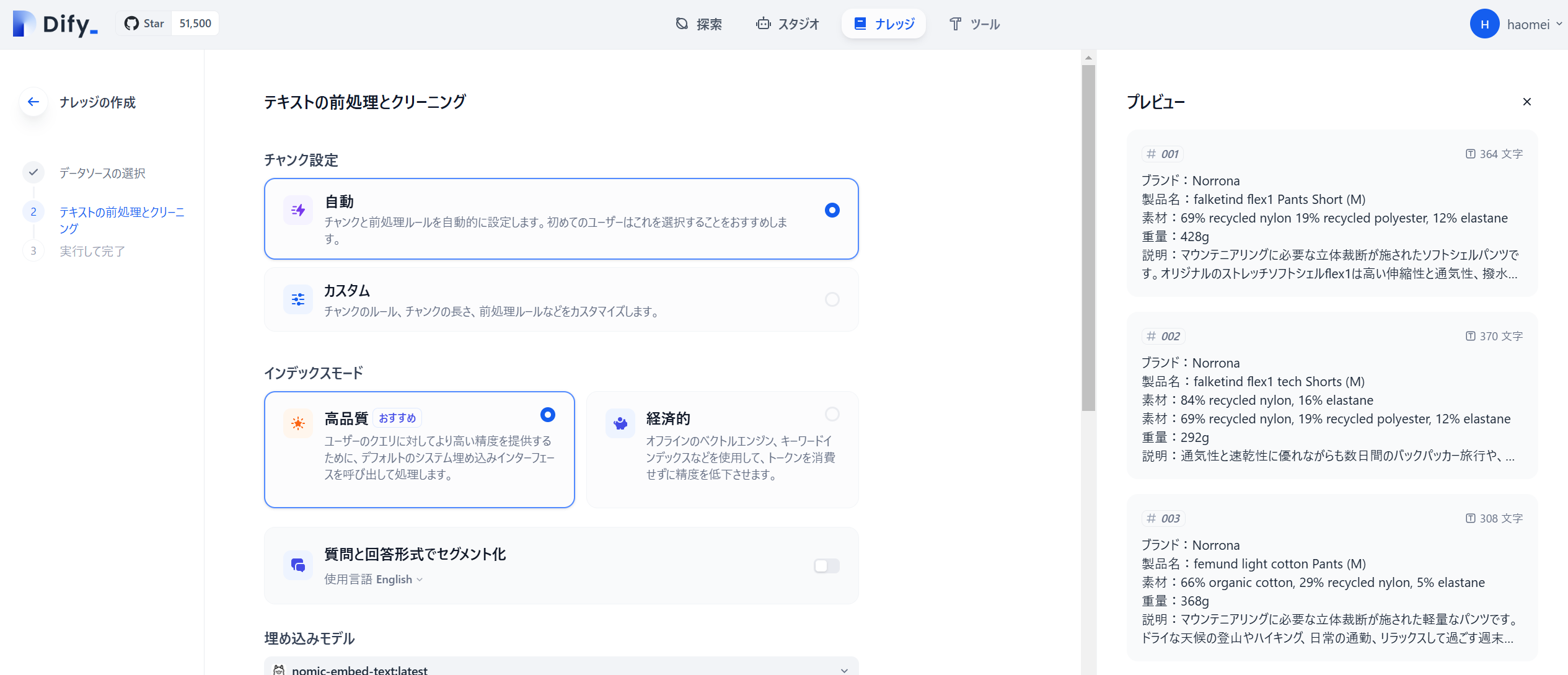
「保存して処理」をクリックするとナレッジの作成が完了します。
埋め込みの完了もすぐ100%で完了します。
アプリ
上部の「スタジオ」を開き、アプリを作成する画面で「最初から作成」をクリックします。
「BETA」がなかなか取れないですが、「ワークフロー」を選択します。
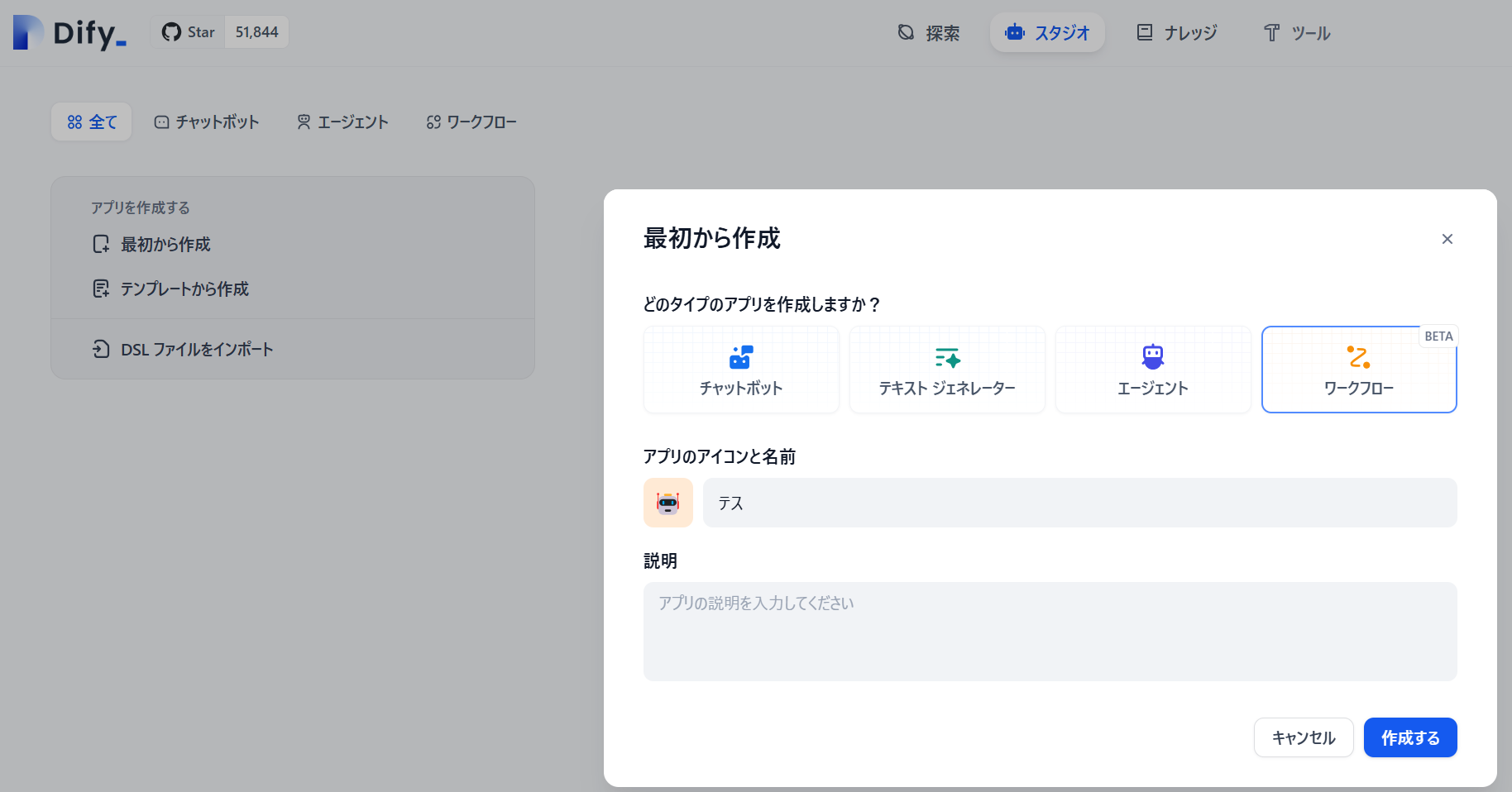
RAGのテンプレフロー
よく見るRAGのテンプレフローです。Difyに慣れてくると、1分で作れると思います。
有名なフローですが、精度が出ないテンプレなのであまり使い物になりません。
試しに「暑い日でも涼しいウェアとパンツを列挙してください。」と質問してみます。
結果は以下です。パンツを無視しちゃってますね。

原因は、ベクトル検索でのクエリを見れば分かると思います。このクエリの類似文を1回検索しているだけという事になります。
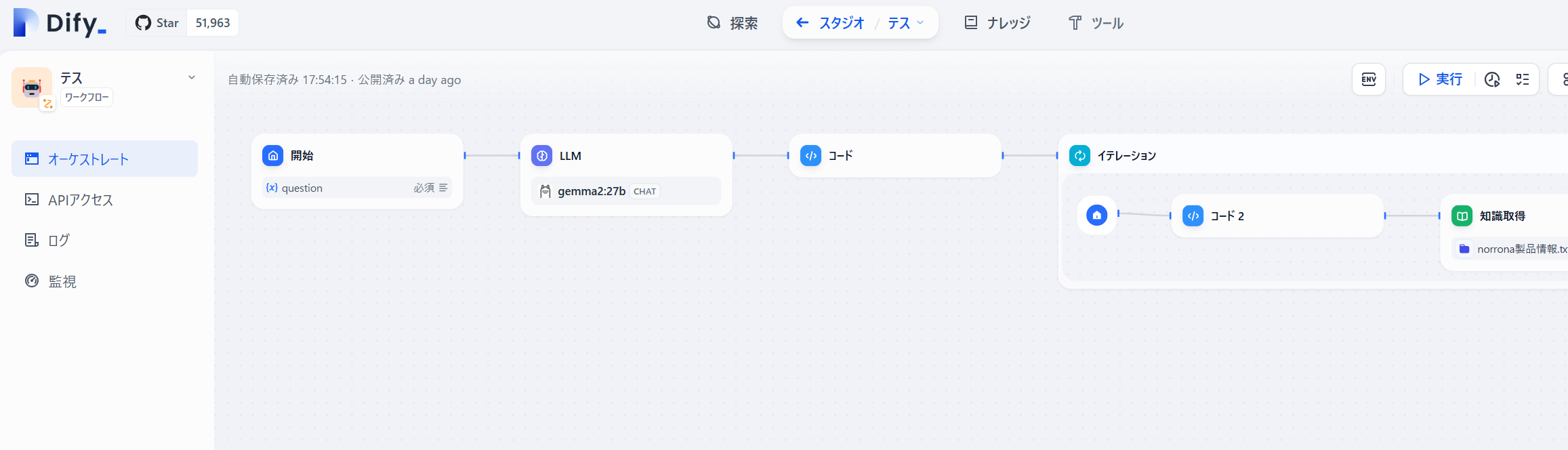
少し改良したフロー
ベクトル検索を細かく複数回に分けて実行した結果をまとめれば、大体のものはコンテキストに入るはずなので、少しフローを改良したものを作成します。
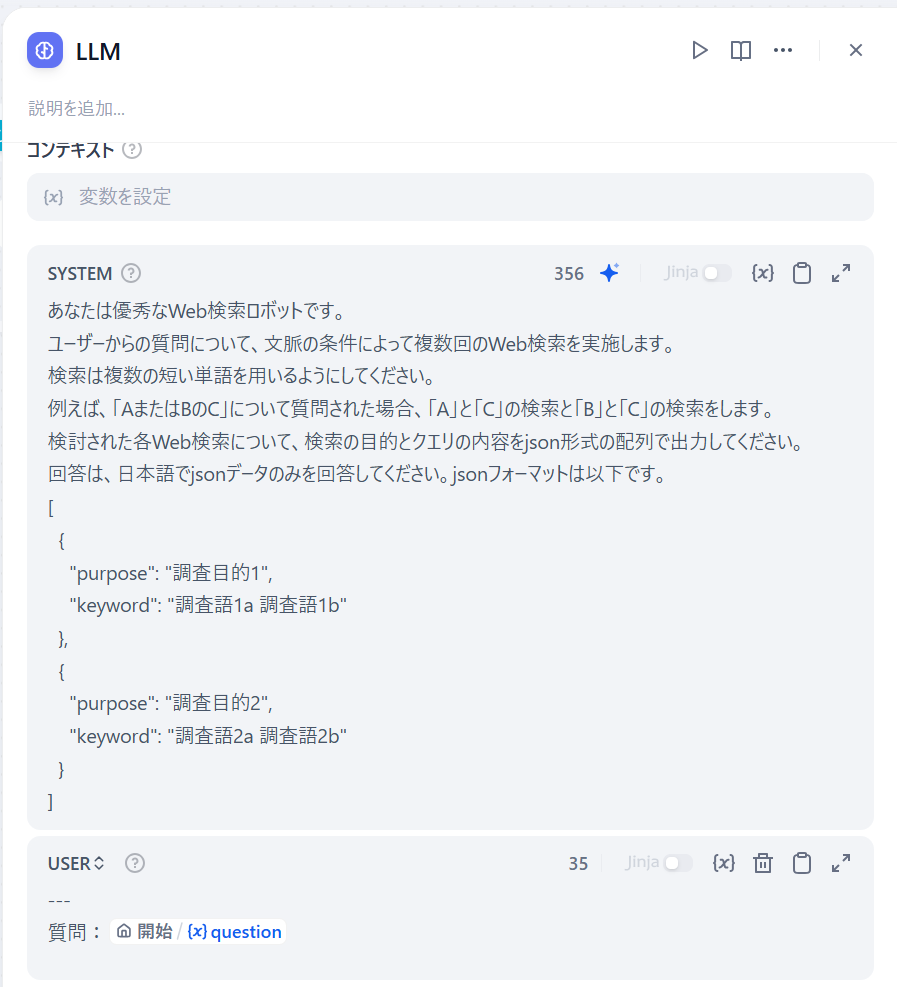
最初に「LLM」を仕込んで、複数回の単語検索をする事を想定とした場合の情報をJSON形式で出力してもらいます。
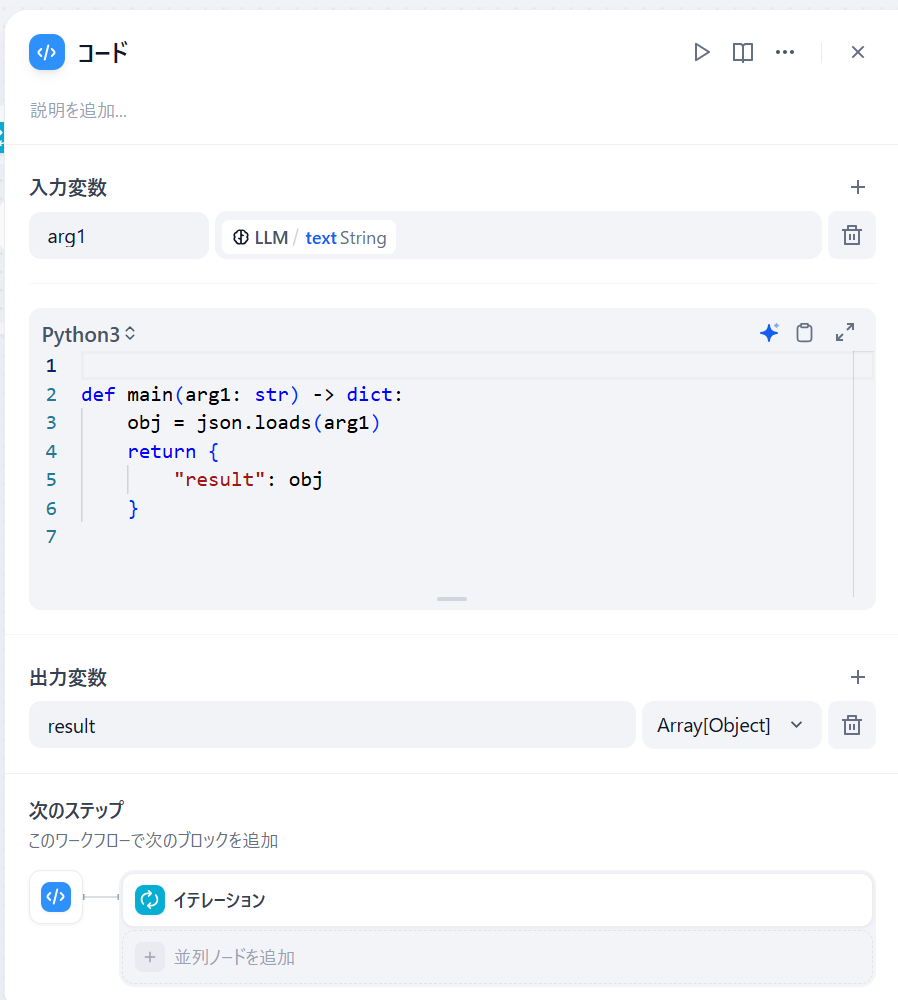
検索語をJSON文字列で出してもらったら、次に「コード」でオブジェクトに変換します。
コードの次は「イテレーション」を配置します。
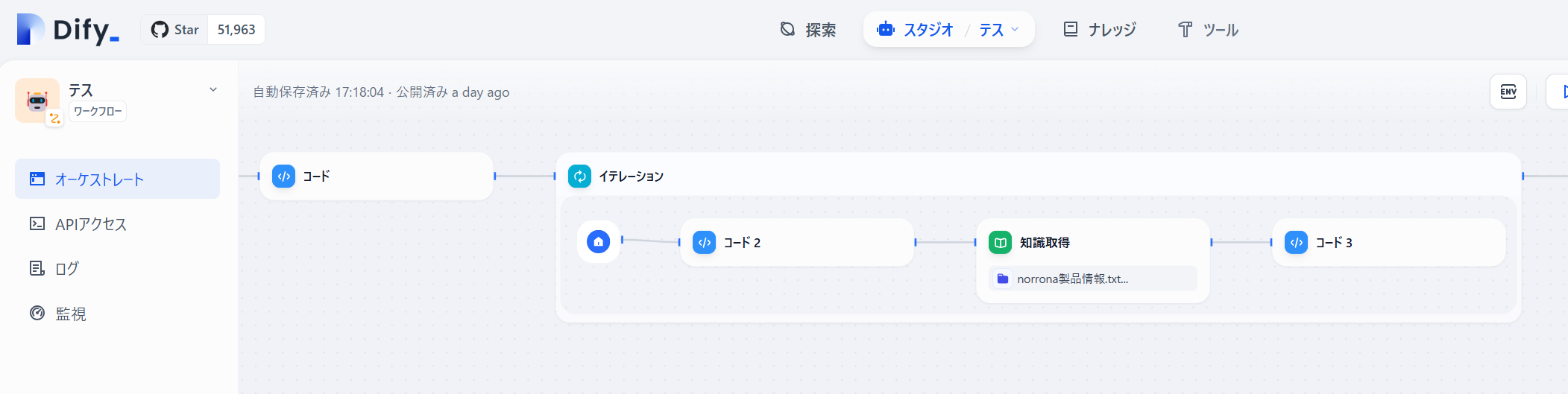
入力は「コード」で変換したオブジェクトです。
※出力変数はイテレーションの作成が終わってから設定します。

イテレーション内に「コード」を配置してオブジェクトから検索語を取得します。
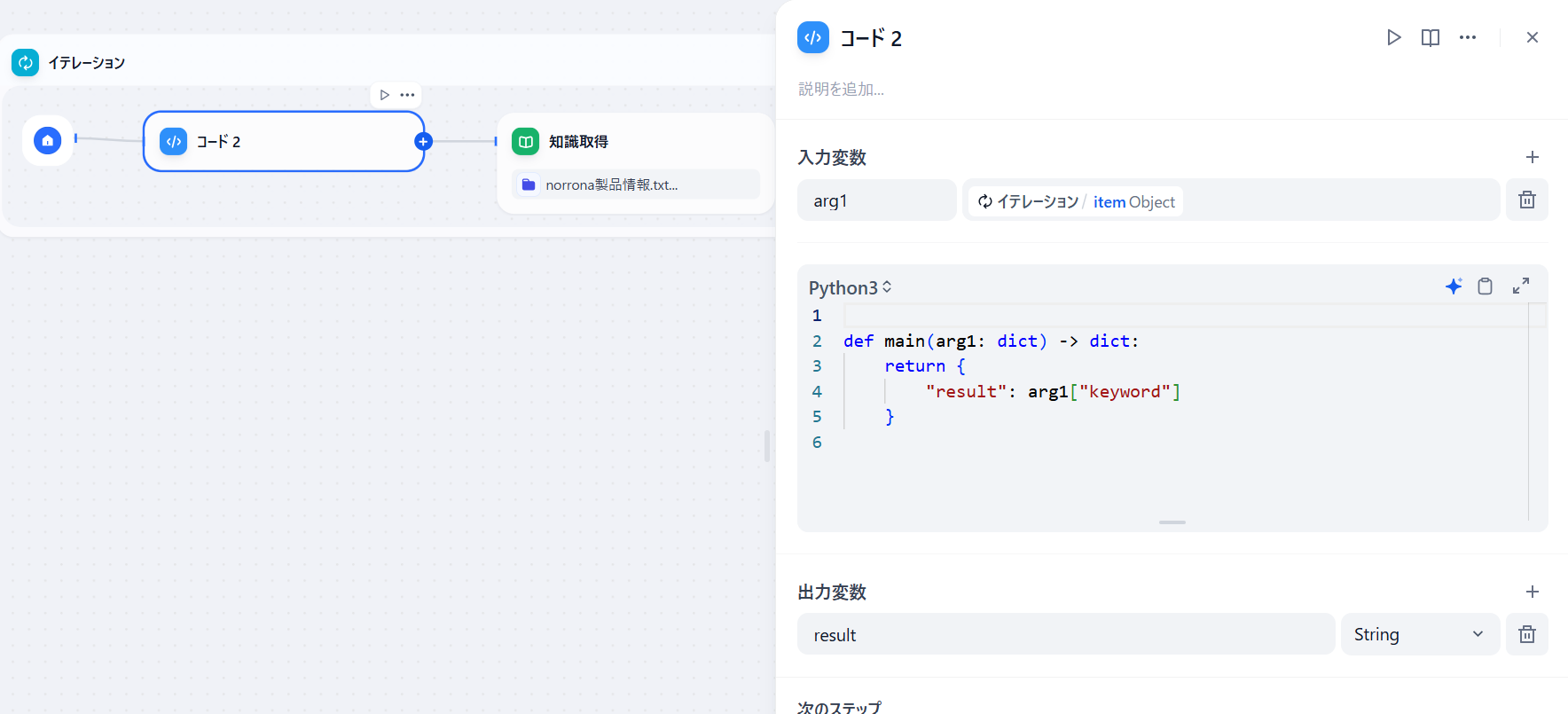
「知識取得」でコードの検索語を使って検索させます。

検索結果だけを「コード」で抜き取ります。
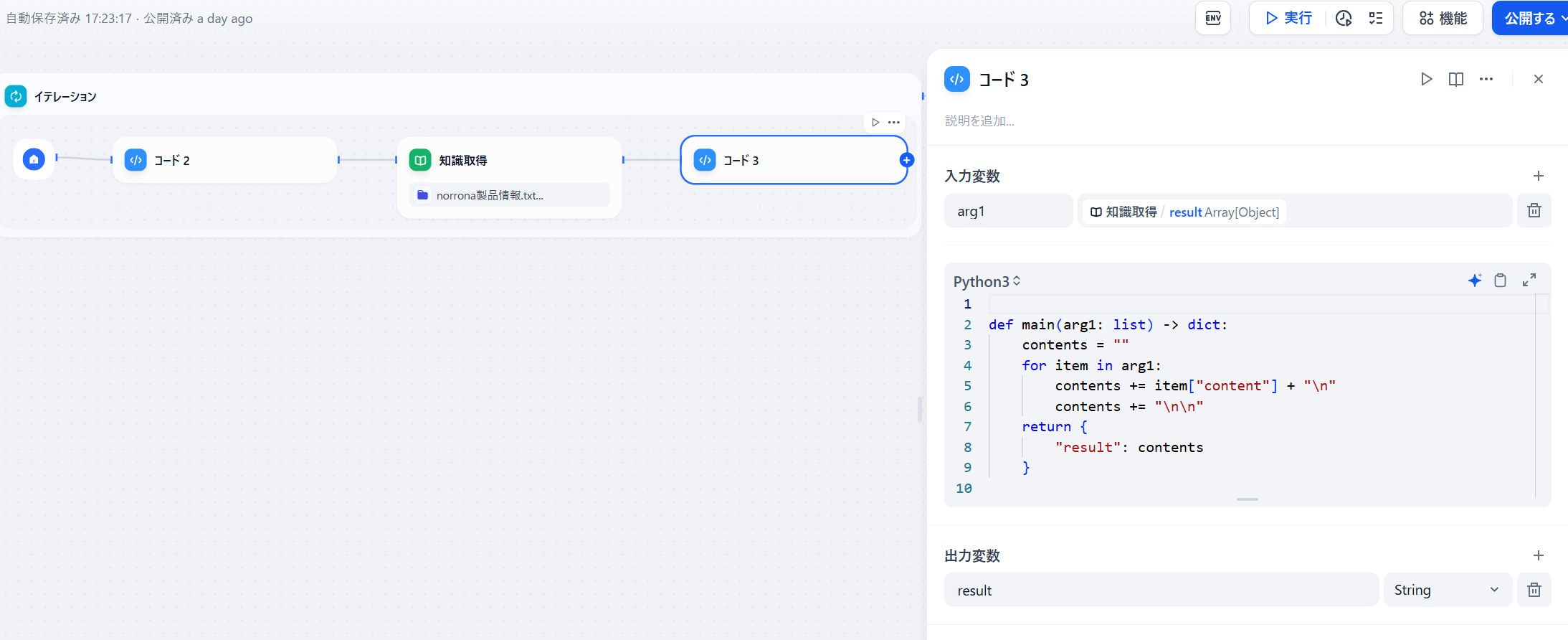
最後に「コード」の結果を「イテレーション」の出力変数に設定しておきます。
「イテレーション」に続けて「LLM」を配置します。
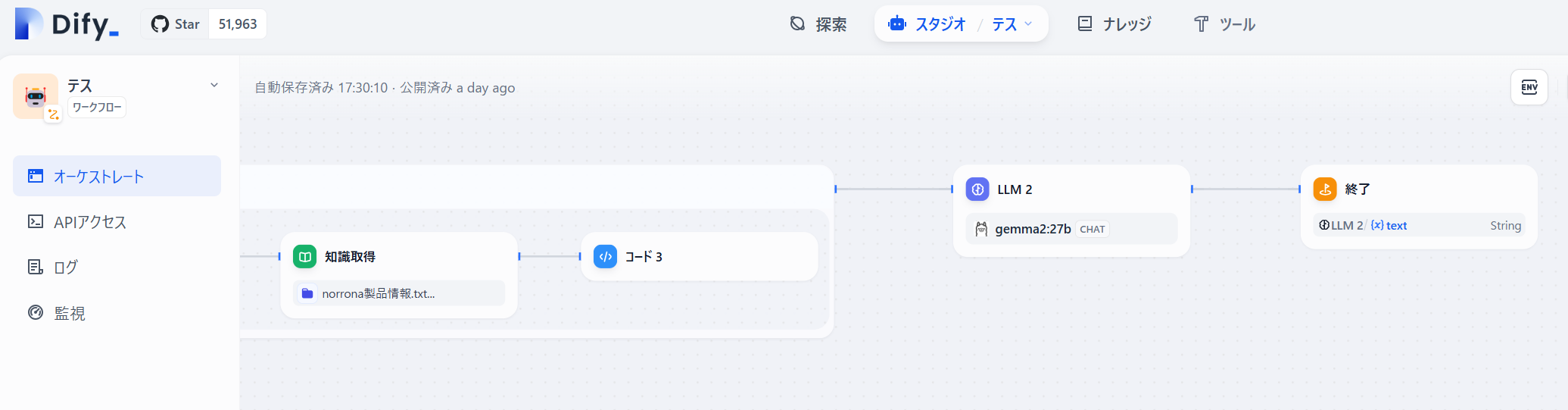
内容は通常のRAGで良いと思いますが、コンテキストにイテレーションの出力変数を指定しておきます。
再度同じ質問をすると、今度はパンツも回答しています。

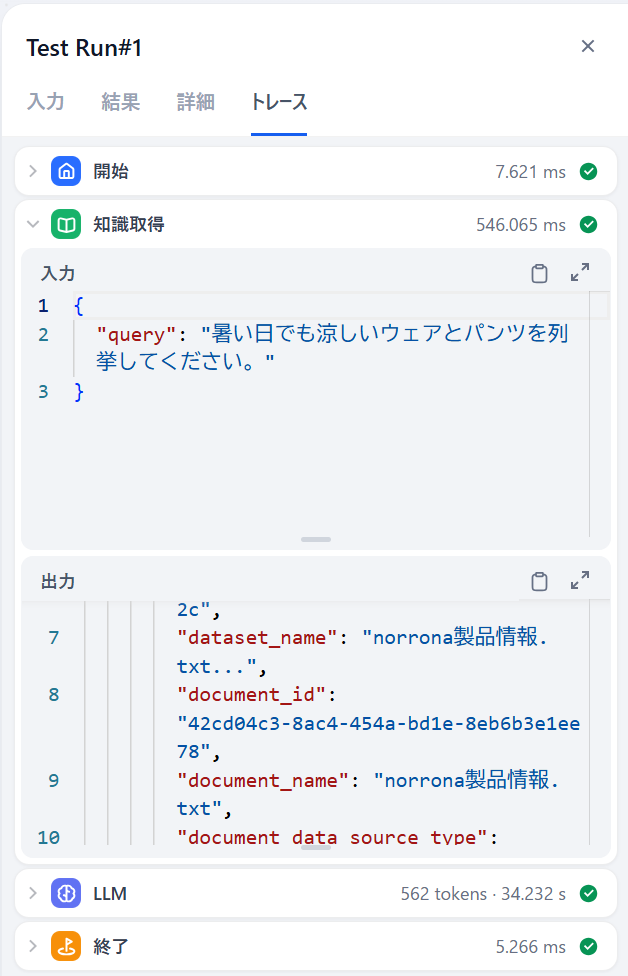
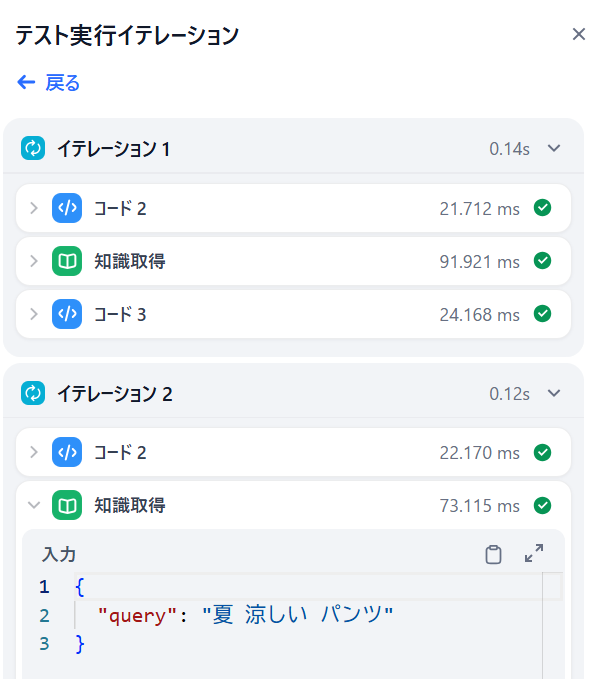
トレースを見ると、知識取得を2回実施しています。

知識取得の内容を見ると、単語検索LLMが「夏 涼しい ウェア」と「夏 涼しい パンツ」に分けてくれました。

パンツもウェアなのですが、「ウェア」と「パンツ」で分けているのは、単に私が類似検索を意識しているだけかもしれません。
ともあれ、若干精度の良くなったRAGができました。
フローやプロンプトを改良していけばもっと精度が良くなりそうですね。
おわりに
イテレーションで「知識取得」を使ってますが、GoogleなどのWeb検索や社内の検索システムに変えても面白そうですね。