はじめに
自宅でNode-RED+Elasticsearch+Kibanaの組み合わせでデータ分析基盤を整えようとしています。
データインポート用のツールとしてデータ変換や分析も手軽に行えるNode-REDは適任ではないかとの考えています。
手始めにYahoo!ニュースのRSSをクラウドワード化してみようと思います。
前提環境
- Raspberry Pi 3 B+ (Raspbian Buster)
- Elasticsearch + Kibana 7.2 (構築はこちらの記事)
- Node-RED
Elasticsearchへの設定
-
ElasticsearchにJapanese (kuromoji) Analysis Pluginをインストールします。※マニュアル参照
-
Elasticsearchに「newsrss」というインデックスを作成して、カスタムanalyzerの設定(settings)と、記事タイトルへのカスタムanalyzerの適用(mappings)をします。※再利用可能なように、インデックス削除も含んでいます。

[{"id":"dce02d95.fe23f","type":"template","z":"c7f7afdc.b6ec2","name":"JSON","field":"payload","fieldType":"msg","format":"json","syntax":"plain","template":"{\n \"settings\": {\n \"index\": {\n \"analysis\": {\n \"tokenizer\": {\n \"custom_tokenizer\": {\n \"type\": \"kuromoji_tokenizer\",\n \"mode\": \"search\",\n \"discard_punctuation\": \"true\",\n \"user_dictionary\": \"userdict.txt\"\n }\n },\n \"filter\": {\n \"lowercase\": {\n \"type\": \"lowercase\",\n \"language\": \"greek\"\n },\n \"length\": {\n \"type\": \"length\",\n \"min\": \"2\"\n },\n \"stop\": {\n \"type\": \"stop\",\n \"stopwords\": [\"undefined\"]\n },\n \"pos\": {\n \"type\": \"kuromoji_part_of_speech\",\n \"stoptags\": [\n \"名詞-数\",\n \"その他-間投\",\n \"フィラー\",\n \"感動詞\",\n \"記号-一般\",\n \"記号-括弧開\",\n \"記号-括弧閉\",\n \"記号-句点\",\n \"記号-空白\",\n \"記号-読点\",\n \"記号\",\n \"形容詞-自立\",\n \"形容詞-接尾\",\n \"形容詞-非自立\",\n \"形容詞\",\n \"語断片\",\n \"助詞-格助詞-一般\",\n \"助詞-格助詞-引用\",\n \"助詞-格助詞-連語\",\n \"助詞-格助詞\",\n \"助詞-間投助詞\",\n \"助詞-係助詞\",\n \"助詞-終助詞\",\n \"助詞-接続助詞\",\n \"助詞-特殊\",\n \"助詞-副詞化\",\n \"助詞-副助詞\",\n \"助詞-副助詞/並立助詞/終助詞\",\n \"助詞-並立助詞\",\n \"助詞-連体化\",\n \"助詞\",\n \"助動詞\",\n \"接続詞\",\n \"接頭詞-形容詞接続\",\n \"接頭詞-数接続\",\n \"接頭詞-動詞接続\",\n \"接頭詞-名詞接続\",\n \"接頭詞\",\n \"動詞-自立\",\n \"動詞-接尾\",\n \"動詞-非自立\",\n \"動詞\",\n \"非言語音\",\n \"副詞-一般\",\n \"副詞-助詞類接続\",\n \"副詞\",\n \"連体詞\"\n ]\n }\n },\n \"analyzer\": {\n \"custom_analyzer\": {\n \"filter\": [\n \"kuromoji_baseform\",\n \"kuromoji_stemmer\",\n \"cjk_width\",\n \"ja_stop\",\n \"lowercase\",\n \"length\",\n \"stop\",\n \"pos\"\n ],\n \"type\": \"custom\",\n \"tokenizer\": \"custom_tokenizer\"\n }\n }\n }\n }\n },\n \"mappings\": {\n \"properties\": {\n \"title\": {\n \"type\": \"text\",\n \"fields\": {\n \"keyword\": {\n \"type\": \"keyword\",\n \"ignore_above\": 1024\n },\n \"token\": {\n \"type\": \"text\",\n \"analyzer\": \"custom_analyzer\",\n \"fielddata\": true\n }\n }\n }\n }\n }\n}","output":"str","x":700,"y":70,"wires":[["e82201b0.b59cf"]]},{"id":"ec8ceb53.f4d8c8","type":"function","z":"c7f7afdc.b6ec2","name":"ES settings/mappings","func":"\nmsg.method = \"PUT\";\nmsg.url = \"http://localhost:9200/newsrss\";\nmsg.headers = { 'Content-Type' : 'application/json' };\n\nreturn msg;","outputs":1,"noerr":0,"x":520,"y":70,"wires":[["dce02d95.fe23f"]]},{"id":"e82201b0.b59cf","type":"http request","z":"c7f7afdc.b6ec2","name":"Elasticsearch","method":"use","ret":"txt","paytoqs":false,"url":"","tls":"","proxy":"","authType":"basic","x":850,"y":70,"wires":[["625fbb86.ddb844"]]},{"id":"495de69c.9cbe38","type":"debug","z":"c7f7afdc.b6ec2","name":"","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","x":1150,"y":70,"wires":[]},{"id":"625fbb86.ddb844","type":"json","z":"c7f7afdc.b6ec2","name":"","property":"payload","action":"","pretty":false,"x":1000,"y":70,"wires":[["495de69c.9cbe38"]]},{"id":"d01fe959.020678","type":"inject","z":"c7f7afdc.b6ec2","name":"Index initial","topic":"","payload":"","payloadType":"str","repeat":"","crontab":"","once":false,"onceDelay":0.1,"x":100,"y":70,"wires":[["d24d712e.520a7"]]},{"id":"d24d712e.520a7","type":"http request","z":"c7f7afdc.b6ec2","name":"ES DELETE (newsrss)","method":"DELETE","ret":"txt","paytoqs":false,"url":"http://localhost:9200/newsrss","tls":"","proxy":"","authType":"basic","x":290,"y":70,"wires":[["ec8ceb53.f4d8c8"]]}]
RSSデータのインポート
- RSSの読み込みに使う「node-red-node-feedparser」をインストールします。利用したいRSSのURLを設定するだけのノードで、デプロイ時に実行されるのが若干使い勝手が悪いです。できる方はXMLから自力で差分(同じ内容のドキュメントがあれば登録しない等)を取った方がいいでしょう。

[{"id":"aca517ed.5cc4e8","type":"template","z":"c7f7afdc.b6ec2","name":"data JSON","field":"payload","fieldType":"msg","format":"json","syntax":"mustache","template":"{\n \"date\": \"{{{date}}}\",\n \"provider\": \"{{{provider}}}\",\n \"title\": \"{{{title}}}\",\n \"getdate\": \"{{{getdate}}}\",\n \"link\": \"{{{article.link}}}\"\n}","output":"str","x":680,"y":400,"wires":[["77271957.74ed68"]]},{"id":"341ac9c.1fbbd36","type":"function","z":"c7f7afdc.b6ec2","name":"ES Query","func":"\nmsg.method = \"POST\";\nmsg.url = \"http://192.168.1.5:9200/newsrss/_doc\";\n\nmsg.headers = {};\nmsg.headers['Content-Type'] = 'application/json';\n\nvar now = new Date();\nmsg.getdate = now.toISOString();\n\nvar d = new Date(msg.article.date);\nmsg.date = d.toISOString();\n\nmsg.provider = msg.article.title.replace(/.*((.*))$/,'$1');\nmsg.title = msg.article.title.replace(/^(.*)(.*)$/,'$1');\n\nreturn msg;","outputs":1,"noerr":0,"x":520,"y":400,"wires":[["aca517ed.5cc4e8"]]},{"id":"77271957.74ed68","type":"http request","z":"c7f7afdc.b6ec2","name":"Elasticsearch","method":"use","ret":"txt","paytoqs":false,"url":"","tls":"","proxy":"","authType":"basic","x":850,"y":400,"wires":[["6781742a.e5771c"]]},{"id":"5802862.51d4778","type":"debug","z":"c7f7afdc.b6ec2","name":"","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","x":1150,"y":400,"wires":[]},{"id":"6781742a.e5771c","type":"json","z":"c7f7afdc.b6ec2","name":"","property":"payload","action":"","pretty":false,"x":1000,"y":400,"wires":[["5802862.51d4778"]]},{"id":"8f92d4dc.149618","type":"feedparse","z":"c7f7afdc.b6ec2","name":"","url":"https://headlines.yahoo.co.jp/rss/zdnet-c_sci.xml","interval":15,"x":210,"y":320,"wires":[["341ac9c.1fbbd36"]]},{"id":"f3965020.5631e","type":"feedparse","z":"c7f7afdc.b6ec2","name":"","url":"https://headlines.yahoo.co.jp/rss/ascii-c_sci.xml","interval":15,"x":210,"y":360,"wires":[["341ac9c.1fbbd36"]]},{"id":"6fddb74e.fe2068","type":"feedparse","z":"c7f7afdc.b6ec2","name":"","url":"https://headlines.yahoo.co.jp/rss/it_nlab-c_sci.xml","interval":15,"x":220,"y":400,"wires":[["341ac9c.1fbbd36"]]},{"id":"2ec0ca39.848046","type":"feedparse","z":"c7f7afdc.b6ec2","name":"","url":"https://headlines.yahoo.co.jp/rss/zdn_ait-c_sci.xml","interval":15,"x":220,"y":440,"wires":[["341ac9c.1fbbd36"]]},{"id":"5d258cf4.b0fcc4","type":"feedparse","z":"c7f7afdc.b6ec2","name":"","url":"https://headlines.yahoo.co.jp/rss/cnetj-c_sci.xml","interval":15,"x":210,"y":480,"wires":[["341ac9c.1fbbd36"]]}]
Kibanaのタグクラウドで可視化する
- インデックスパターンでElasticsearchのnewsrssを割り当てます。フィールド名の「link」はURL型に変更しておきます。
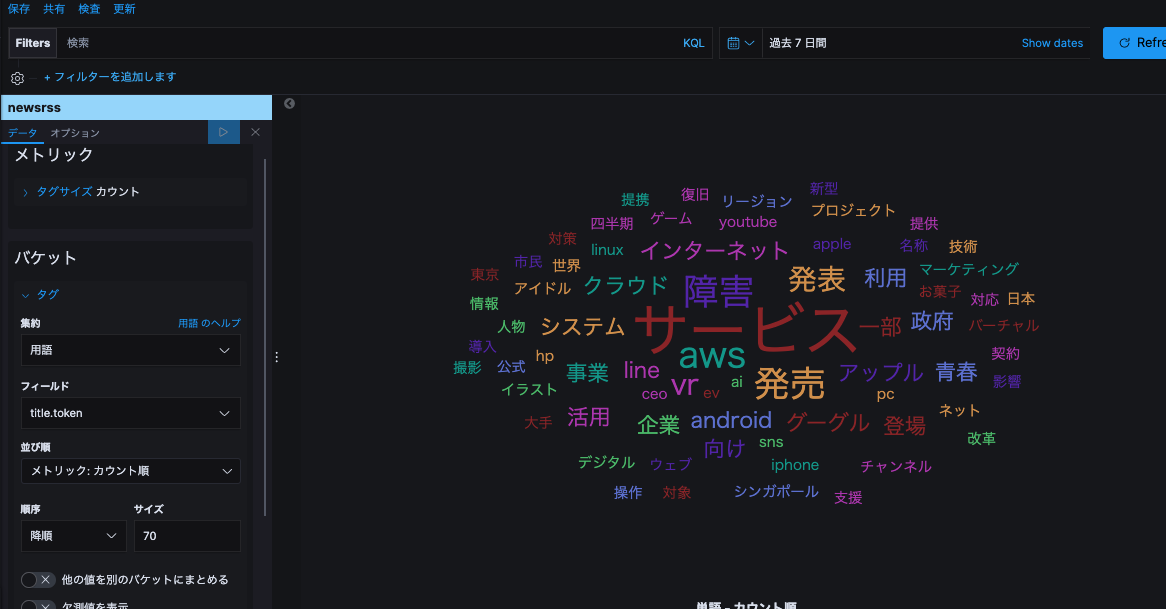
- 「可視化」(Visualize)で「タグクラウド」を選択し、バケットの集約に「用語」フィールドに「title.token」を指定します。
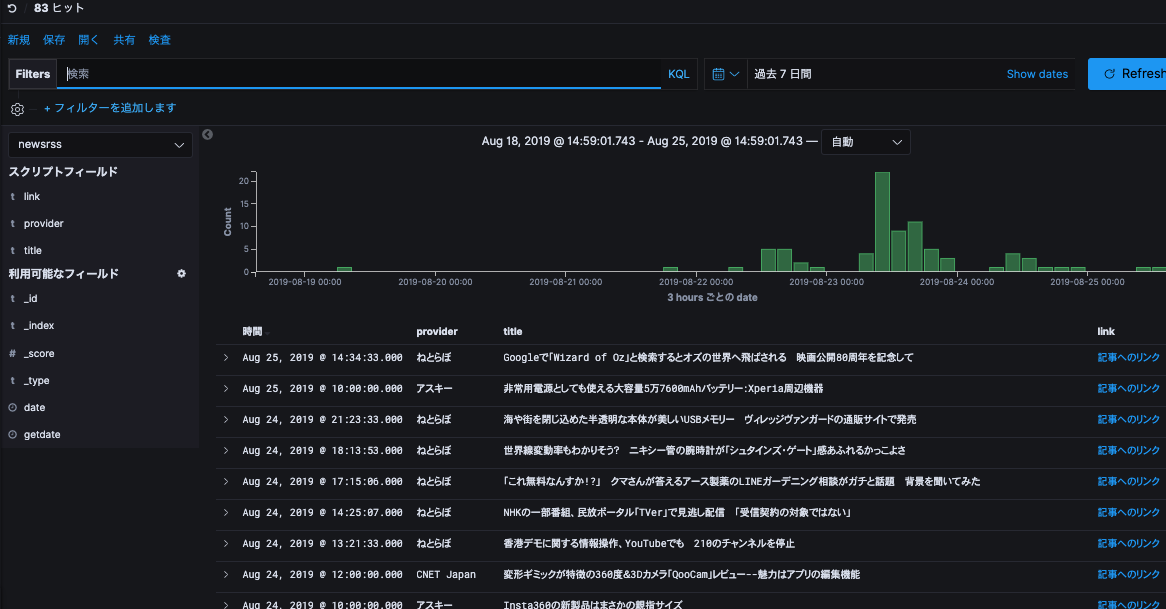
- 「ディスカバリ」で「newsrss」を選択し、「provider」「title」「link」を追加して保存します。
- 「ダッシュボード」で作成したタグクラウドとディスカバリ検索結果を配置すればできあがりです。
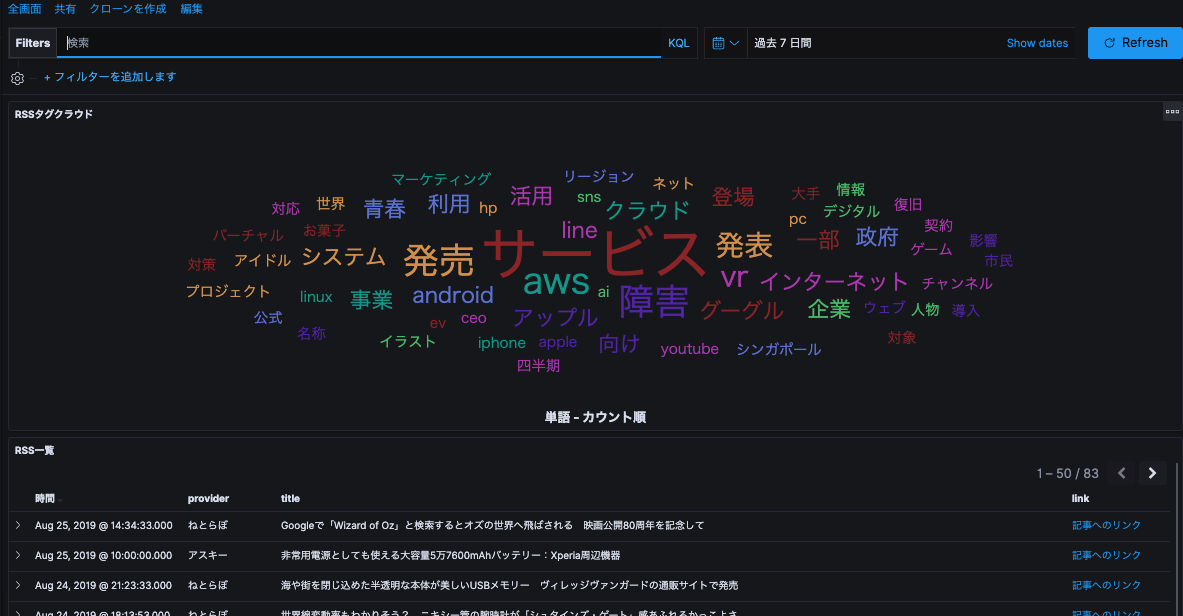
タグクラウドの「AWS」をクリックすると、絞り込んだ内容で可視化画面がアニメーションします。
記事を読まなくても大体わかってきますよね。それにしても、このアニメーションは気持ちいいですね。

ユーザ辞書
カスタムtokenizerの定義時にユーザ辞書を利用できるようにしています。「user_dictionary」を「userdict.txt」としていますが、これはElasticsearchのconfig直下がルートディレクトリになっているので、そこのファイルを編集するようにNode-REDで辞書管理を実装してみましょう。
辞書の更新手順については、以下のElasticのブログも参考にしています。
CJK アナライザーの辞書更新時の挙動について
フローは以下のようになります。ユーザ辞書のファイルパスは自分の環境に合わせてください。

[{"id":"6894f9bd.ab1d98","type":"inject","z":"c7f7afdc.b6ec2","name":"","topic":"","payload":"","payloadType":"str","repeat":"","crontab":"","once":false,"onceDelay":0.1,"x":90,"y":170,"wires":[["6e13004f.5c569"]]},{"id":"6e13004f.5c569","type":"template","z":"c7f7afdc.b6ec2","name":"カスタム名詞","field":"payload","fieldType":"msg","format":"text","syntax":"plain","template":"クラウド,クラウド,クラウド,カスタム名詞","output":"str","x":270,"y":170,"wires":[["ff0cba05.703458"]]},{"id":"ff0cba05.703458","type":"file","z":"c7f7afdc.b6ec2","name":"ユーザ辞書","filename":"/home/ami/elasticsearch/config/userdict.txt","appendNewline":false,"createDir":true,"overwriteFile":"true","encoding":"utf8","x":450,"y":170,"wires":[["5cbe0e53.efa17"]]},{"id":"2edda65.361b05a","type":"http request","z":"c7f7afdc.b6ec2","name":"Elasticsearch","method":"use","ret":"txt","paytoqs":false,"url":"","tls":"","proxy":"","authType":"basic","x":800,"y":270,"wires":[["c9bcd1d6.66045"]]},{"id":"a4834a86.a7b2b8","type":"debug","z":"c7f7afdc.b6ec2","name":"","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","x":1090,"y":270,"wires":[]},{"id":"c9bcd1d6.66045","type":"json","z":"c7f7afdc.b6ec2","name":"","property":"payload","action":"","pretty":false,"x":940,"y":270,"wires":[["a4834a86.a7b2b8"]]},{"id":"c55b212c.235a7","type":"template","z":"c7f7afdc.b6ec2","name":"JSON","field":"payload","fieldType":"msg","format":"json","syntax":"plain","template":"{\n \"query\": {\n \"match_all\": {}\n }\n}","output":"str","x":650,"y":270,"wires":[["2edda65.361b05a"]]},{"id":"3c8b199f.1a82e6","type":"function","z":"c7f7afdc.b6ec2","name":"ES update_by_query","func":"\nmsg.method = \"POST\";\nmsg.url = \"http://localhost:9200/newsrss/_update_by_query?conflicts=proceed\";\nmsg.headers = { 'Content-Type' : 'application/json' };\n\nreturn msg;","outputs":1,"noerr":0,"x":470,"y":270,"wires":[["c55b212c.235a7"]]},{"id":"c24de607.475f68","type":"http request","z":"c7f7afdc.b6ec2","name":"Elasticsearch","method":"use","ret":"txt","paytoqs":false,"url":"","tls":"","proxy":"","authType":"basic","x":540,"y":220,"wires":[["7ab94729.2de8f8"]]},{"id":"52d7c476.e016fc","type":"http request","z":"c7f7afdc.b6ec2","name":"Elasticsearch","method":"use","ret":"txt","paytoqs":false,"url":"","tls":"","proxy":"","authType":"basic","x":1010,"y":220,"wires":[["3c8b199f.1a82e6"]]},{"id":"804a1d05.c6c9","type":"function","z":"c7f7afdc.b6ec2","name":"ES open","func":"\nmsg.method = \"POST\";\nmsg.url = \"http://localhost:9200/newsrss/_open\";\nmsg.headers = { 'Content-Type' : 'application/json' };\nmsg.payload = \"{}\";\n\nreturn msg;","outputs":1,"noerr":0,"x":850,"y":220,"wires":[["52d7c476.e016fc"]]},{"id":"5cbe0e53.efa17","type":"function","z":"c7f7afdc.b6ec2","name":"ES close","func":"\nmsg.method = \"POST\";\nmsg.url = \"http://localhost:9200/newsrss/_close\";\nmsg.headers = { 'Content-Type' : 'application/json' };\nmsg.payload = \"{}\";\n\nreturn msg;","outputs":1,"noerr":0,"x":380,"y":220,"wires":[["c24de607.475f68"]]},{"id":"7ab94729.2de8f8","type":"delay","z":"c7f7afdc.b6ec2","name":"","pauseType":"delay","timeout":"1","timeoutUnits":"seconds","rate":"1","nbRateUnits":"1","rateUnits":"second","randomFirst":"1","randomLast":"5","randomUnits":"seconds","drop":false,"x":700,"y":220,"wires":[["804a1d05.c6c9"]]}]
templateノードを編集してデプロイする運用になるので、feedparserノードがデータを再取得する事になり相性が悪いです。お仕事用で同じようにkuromojiの辞書管理をしていますが、Webのインタフェースにしてデプロイを発生させないようにしています。「お試し」でなければ真似しないでください。
少ないデータなので確認していませんが、update_by_queryはsizeを指定するべきかもしれません。
例として、「クラウド」を登録する前後のタグクラウド比較です。
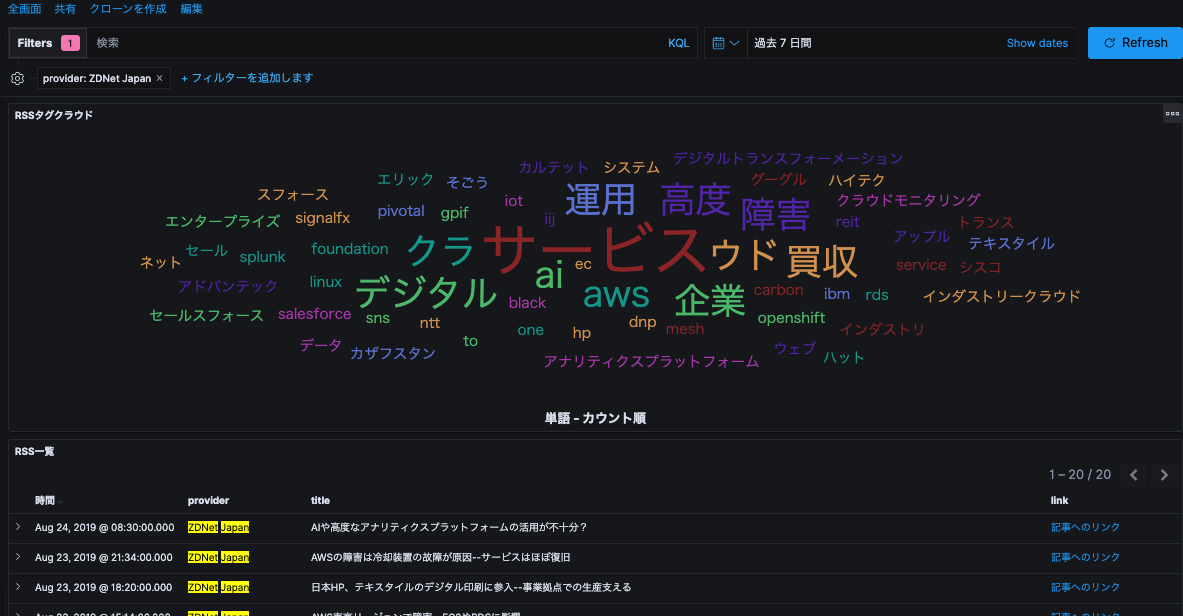
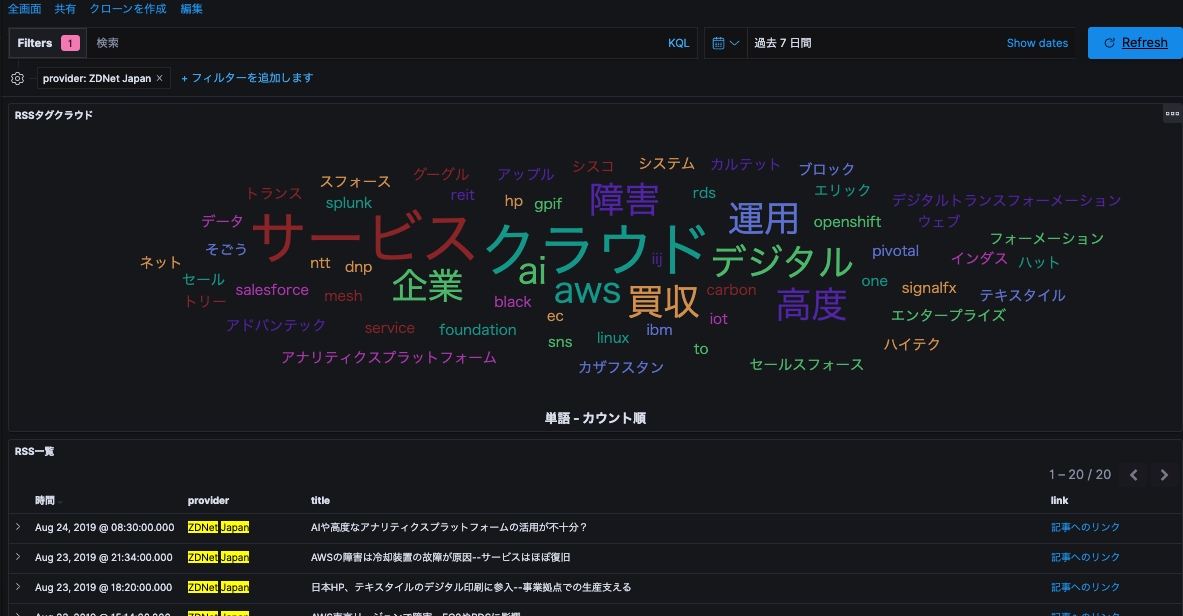
おわりに
正直なところElasticsearch側の設定はかなり時間を費やして調べましたが、settings/mappingsを理解すれば、1日かからずに構築できて非常に良いツールです。
肝心な部分は単語のゴミ除去(フィルタの設定)ですので、興味のある方はsettingsの設定内容を調べてみてください。
参考になるかわかりませんが、なんとなく理解した内容でコメントを記載しています。
{
"settings": {
"index": {
"analysis": {
"tokenizer": { =>トークナイザの設定
"custom_tokenizer": { =>カスタムトークナイザの設定(名前は任意につける)
"type": "kuromoji_tokenizer", =>ベースにkuromoji_tokenizerを使う
"mode": "search", =>「search」により長い単語でも部分一致する単語でも検索できるようにしている(つもり)※好みで変更した方がいい
"discard_punctuation": "true", =>句読点除外
"user_dictionary": "userdict.txt" =>ユーザ辞書ファイル
}
},
"filter": { =>フィルタの設定
"lowercase": {
"type": "lowercase", =>大文字を小文字に変換する
"language": "greek" =>ギリシャ文字対象?
},
"length": {
"type": "length",
"min": "2" =>単語の最低文字数
},
"stop": {
"type": "stop",
"stopwords": ["undefined"] =>「undefined」を除外する単語とする
},
"pos": {
"type": "kuromoji_part_of_speech", =>品詞除外フィルタ
"stoptags": [ =>除外する品詞
"名詞-数",
"その他-間投",
"フィラー",
"感動詞",
"記号-一般",
"記号-括弧開",
"記号-括弧閉",
"記号-句点",
"記号-空白",
"記号-読点",
"記号",
"形容詞-自立",
"形容詞-接尾",
"形容詞-非自立",
"形容詞",
"語断片",
"助詞-格助詞-一般",
"助詞-格助詞-引用",
"助詞-格助詞-連語",
"助詞-格助詞",
"助詞-間投助詞",
"助詞-係助詞",
"助詞-終助詞",
"助詞-接続助詞",
"助詞-特殊",
"助詞-副詞化",
"助詞-副助詞",
"助詞-副助詞/並立助詞/終助詞",
"助詞-並立助詞",
"助詞-連体化",
"助詞",
"助動詞",
"接続詞",
"接頭詞-形容詞接続",
"接頭詞-数接続",
"接頭詞-動詞接続",
"接頭詞-名詞接続",
"接頭詞",
"動詞-自立",
"動詞-接尾",
"動詞-非自立",
"動詞",
"非言語音",
"副詞-一般",
"副詞-助詞類接続",
"副詞",
"連体詞"
]
}
},
"analyzer": { =>解析器の設定
"custom_analyzer": { =>カスタム解析器の設定(名前は任意で)
"filter": [ =>使用するフィルタの設定
"kuromoji_baseform", =>単語の原形化「行こ(う)」「行き(ます)」→「行く」
"kuromoji_stemmer", =>語尾の長音削除
"cjk_width", =>CJK正規化(全角英数→半角英数、半角カナ→全角カナ)
"ja_stop", =>一般的な単語除外(「今回」「前回」「下記」「上記」など)
"lowercase", =>以降は、フィルタ設定で定義したフィルタ
"length",
"stop",
"pos"
],
"type": "custom", =>アナライザのタイプ
"tokenizer": "custom_tokenizer" =>トークナイザ設定で定義したトークナイザ
}
}
}
}
},
"mappings": {
"properties": {
"title": { =>「title」というフィールドのマッピング定義
"type": "text",
"fields": { =>追加フィールドの設定
"keyword": { =>「title.keyword」の設定
"type": "keyword", =>そのままの長い文字列で保持
"ignore_above": 1024 =>可視化で表示できる最大の長さ?
},
"token": { =>「title.token」の設定
"type": "text", =>テキスト型(アナライザ使用時の既定)
"analyzer": "custom_analyzer", =>カスタムアナライザの利用
"fielddata": true =>タグクラウドで扱えるようにする
}
}
}
}
}
}