お久しぶりです、Xu です。
転職しすぎて今自分がどこにいるのかも微妙にわからない今日この頃、前回の投稿から一年くらい経ちましたね、またいつもの三日坊主です、ごめんなさい。
私事ですが、入籍しました。
言い訳になってないですね、はい。
さて、何を思い立ったかと言うと、皆さんも最近やたら AWS EC2 のインスタンス落ちるなと感じてませんか?
事あるごとに再起動してしばらく様子見てたので、そろそろ通知機能作ろうかと思いました。
年末に何やってんだって話です( ;∀;)
今回の話の要略
ShellScript による Ubuntu サーバー再起動時の LINE 通知を実装
CloudWatch によるサーバー状態監視の自動化
環境
AWS EC2 (Ubuntu 22.04)
AWS Lambda Python3.13
AWS SNS
ShellScript
LINE Developer Platform
1.とりあえず再起動通知作ってみよう
LINE Developer Platform で公式アカウントの作成方法や Webhook の設定の仕方は、以前の記事も参考になるかと思います。
https://qiita.com/Xudev/items/61c1f000eb1ee9a61fe0
Token 発行:https://developers.line.biz/ja/services/messaging-api/
まずは AWS Lambda 関数を作成
毎回 LINE と連携するときに、先にスクリプトのほう作るか、Lambda 関数作るか悩んでます、卵が先か鶏が先かってくらい悩んでます。
(急いでないならどっちでもいいよ)
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
作成時はこんな感じかと思います。
現時点で欲しいのは関数 URL なので、中身はまあ何でもいいです。
Shellス クリプト作成
上記で作成した Lambda を呼び出してごにょごにょさせたいので、シンプルに
#!/bin/sh
curl [AWS lambda IP]
権限変更
割と忘れがちですが、忘れずに権限を変更してあげましょう
$ chmod +x tellRestarted.sh
デーモンにサービスを登録
$ sudo vim /etc/systemd/system/tellRestarted.service
※管理者権限を必要とします
[Unit]
Description=Tells Linebot the instance is restarted
After=network.target
[Service]
User=[userName]
ExecStart=[pathToScript]/tellRestarted.sh
Restart=always
type=simple
[Install]
WantedBy=multi-user.target
サービス登録とデーモンのリロード
$ sudo systemctl enable tellRestarted.service
$ sudo systemctl daemon-reload
これで送信元のスクリプトの用意ができたので、AWS Lambdaのほうを完成させましょう。
AWS Lambda関数を完成させる
外部とのやり取りはすべて event 変数内に JSON 形式で定義されているので、困ったときはこまめに print(event) で中身を確認してください。
Messaging API 呼び出し部分は LINE 公式のドキュメントを確認
https://developers.line.biz/ja/reference/messaging-api/
import urllib.request
import logging
import json
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
botAlert = f"Instance Restarted"
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer [yourToken]'
}
data = {
'messages': [
{
"type": "text",
"text": botAlert
}
]
}
url = 'https://api.line.me/v2/bot/message/broadcast'
req = urllib.request.Request(url=url, data=json.dumps(data).encode('utf-8'), method='POST', headers=headers)
with urllib.request.urlopen(req) as res:
logger.info(res.read().decode("utf-8"))
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Request succeed!')
}
よっしゃー、完成だ、夕飯はチキンだ!
と思った矢先、そこで問題発生!
問題点
1 回のインスタンス再起動で繰り返し通知が来る。。。
おそらく daemon が何度もリスタートしているので、5 回くらい通知飛んできます。。。

これじゃあインスタンス増えたときにすぐ混乱するよね。。。
2.CloudWatch で自動化すればよくね?
Lambdaのデバッグで都度お世話になっているCloudWatchではアラート機能が提供されています。
参考:
『Lambda を使用して CloudWatch アラームを LINE Notify で通知してみる』
https://qiita.com/kobayashi_0226/items/21cd1a1244e3c6e5d9b4
上記記事では LINE Notify を使ってますが、現在サービス終了の状態なので、作成した公式アカウントに Messaging API でアラートを飛ばしてみます
まずは AWS SNS で受け渡しの準備をする
AWS SNS にて、右上 [ トピックの作成 ] をクリック

今回はエンドポイントに送信するため、スタンダードを選択して名前と表示名を任意に入力して [ トピックの作成 ]
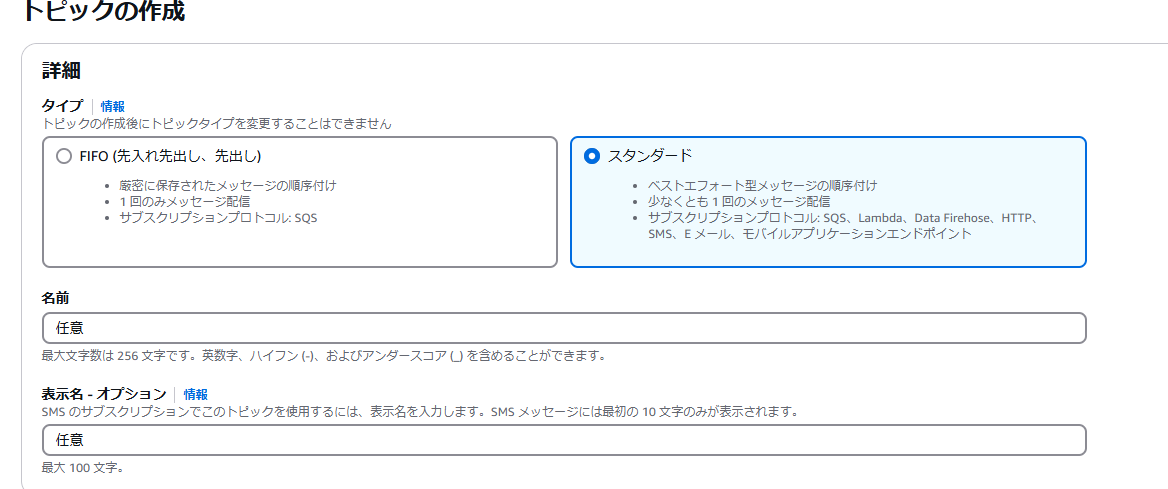
画面が切り替わったら画面の中央右側の [ サブスクリプションの作成 ] をクリック
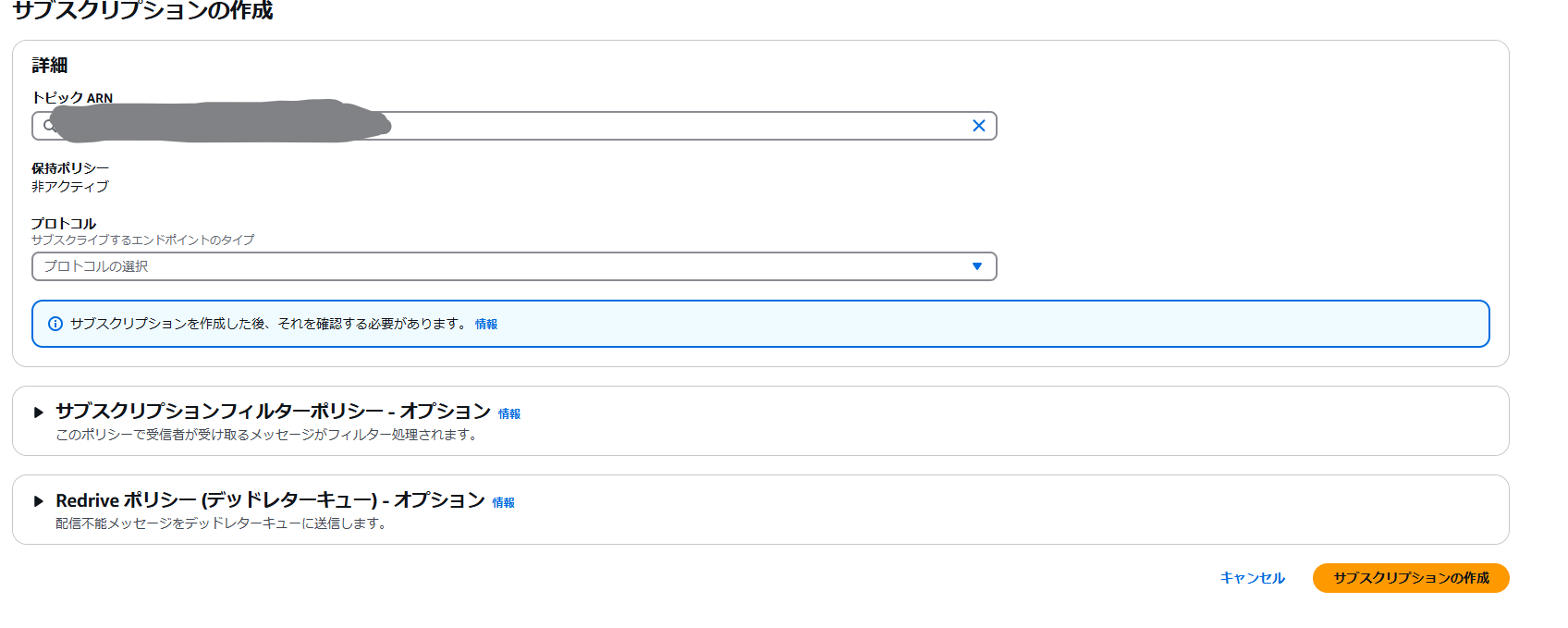
次の画面で「プロトコル」から以前作成した Lambda を選択して [ サブスクリプションの作成 ] をクリック
次にCloudWatch にてアラートを作成
CloudWatch では常に様々なメトリクス別にインスタンスの状態を監視してます。
状態異常検知に使うメトリクスの選定
CloudWatch にて、すべてのメトリクス→EC2→インスタンス別メトリクスに移動

ここで、特定のメトリクス名の項目にチェックを入れていくと、上部のグラフに該当メトリクスの状態遷移図が表示されます。
需要に応じて選択しましょう。
なお、今回の場合は StatusCheckFailed にチェックを入れています。
あまり頻繫にメッセージ来られても困るし、AWS 側が自動的にステータスチェックをやってくれているので、運用コスト的にもうれしいですね!
メトリクスの選定が終わったら [ グラフ化したメトリクス ] タブに遷移し、該当項目の右側「アクション」欄でベルマークをクリックします。
メトリクスと条件の指定
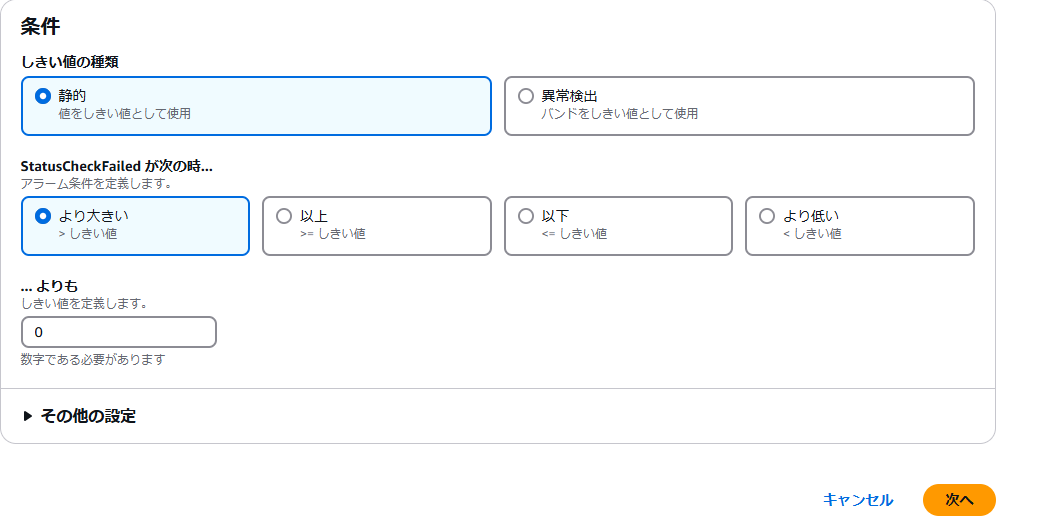
今回はステータスチェックの結果を元に異常検知をしているので、検出された不合格数が 0 でなければ障害発生中ということになります。
この場合、最大値を 0、期間を 1 分間として設定します。

※期間が 1 分間以内の場合は追加料金がかかります。
条件としては、検出数が 0 より大きい場合のため、下記のようになり、[ 次へ ] をクリックします。
アクションの設定
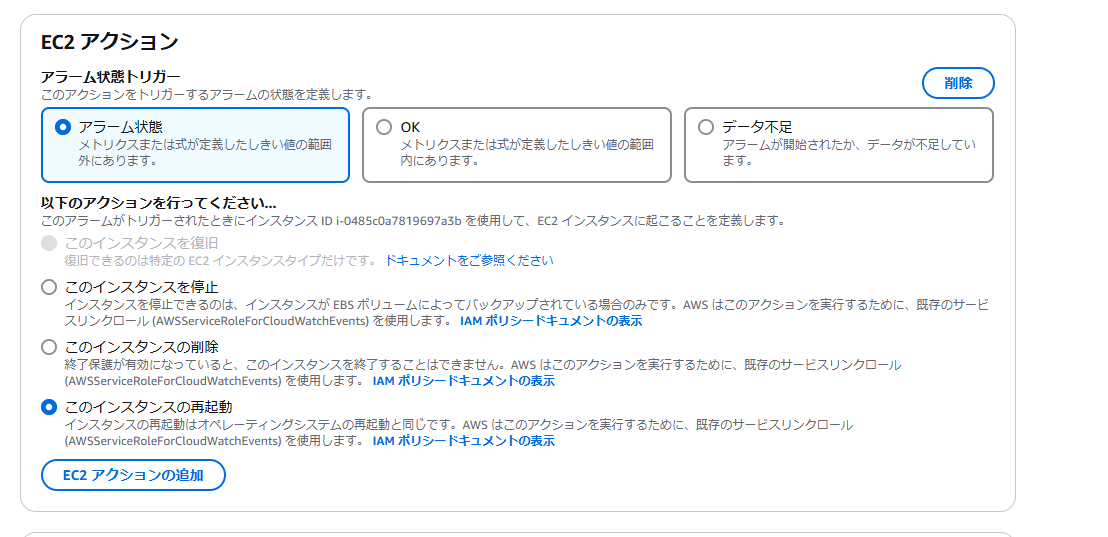
トリガーと通知の送信先を指定します。
[ 通知の追加 ] でそれぞれの状態の場合の送信先、又は複数の送信先を指定できます。
ここでは上記で作成した AWS SNS を指定します。

いつもはインスタンスの再起動で事象が解消するので、アラーム時に EC2 を再起動するようにアクションを指定します。
これで CloudWatch の設定は完了です。
最後に Lambda 関数の中身を編集
この際のSNSからのリクエストの中身は公式ドキュメントに書かれているので、気になる方はこちらをご確認ください。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-sns.html
import urllib.request
import logging
import json
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
Message = json.loads(event['Records'][0]['Sns']['Message'])
AlarmName = Message['AlarmName']
NewStateValue = Message['NewStateValue']
Instance = Message['Trigger']['Dimensions'][0]['value']
NewStateReason = Message['NewStateReason']
botAlert = f'CloudWatch EC2アラート\nアラーム名:{AlarmName}\n現在のステータス:{NewStateValue}\nインスタンス名:\n{Instance}\nステータス変更理由:\n{NewStateReason}'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer [yourToken]'
}
data = {
'messages': [
{
"type": "text",
"text": botAlert
}
]
}
url = 'https://api.line.me/v2/bot/message/broadcast'
req = urllib.request.Request(url=url, data=json.dumps(data).encode('utf-8'), method='POST', headers=headers)
with urllib.request.urlopen(req) as res:
logger.info(res.read().decode("utf-8"))
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Request succeed!')
}
テスト実行結果

お、これはいい感じじゃないのか!?
最初は再起動時のあやふやな状態が引っかかって無限再起動ループに入るんじゃないかと心配してたが、さすがにそれはなかったようだ!
(え?それくらいAWSがアラート機能作ってるときにとっくに考えたよって?)
全体図としてはこうなります。

最初の再起動通知サービスを削除
はい、君は完全にクビですね~
$ sudo systemctl disable tellRestarted.service
$ sudo systemctl daemon-reload
CloudWatch の有用な機能はまだまだ沢山あるので、もっと色々試したらこの記事ももしかしたらシリーズ化するかも、しないかも☆