あのー、一個言っていいすか?
「日本のサイトはどいつもこいつも広告多すぎね?」
これとかこれとか、これとか!!
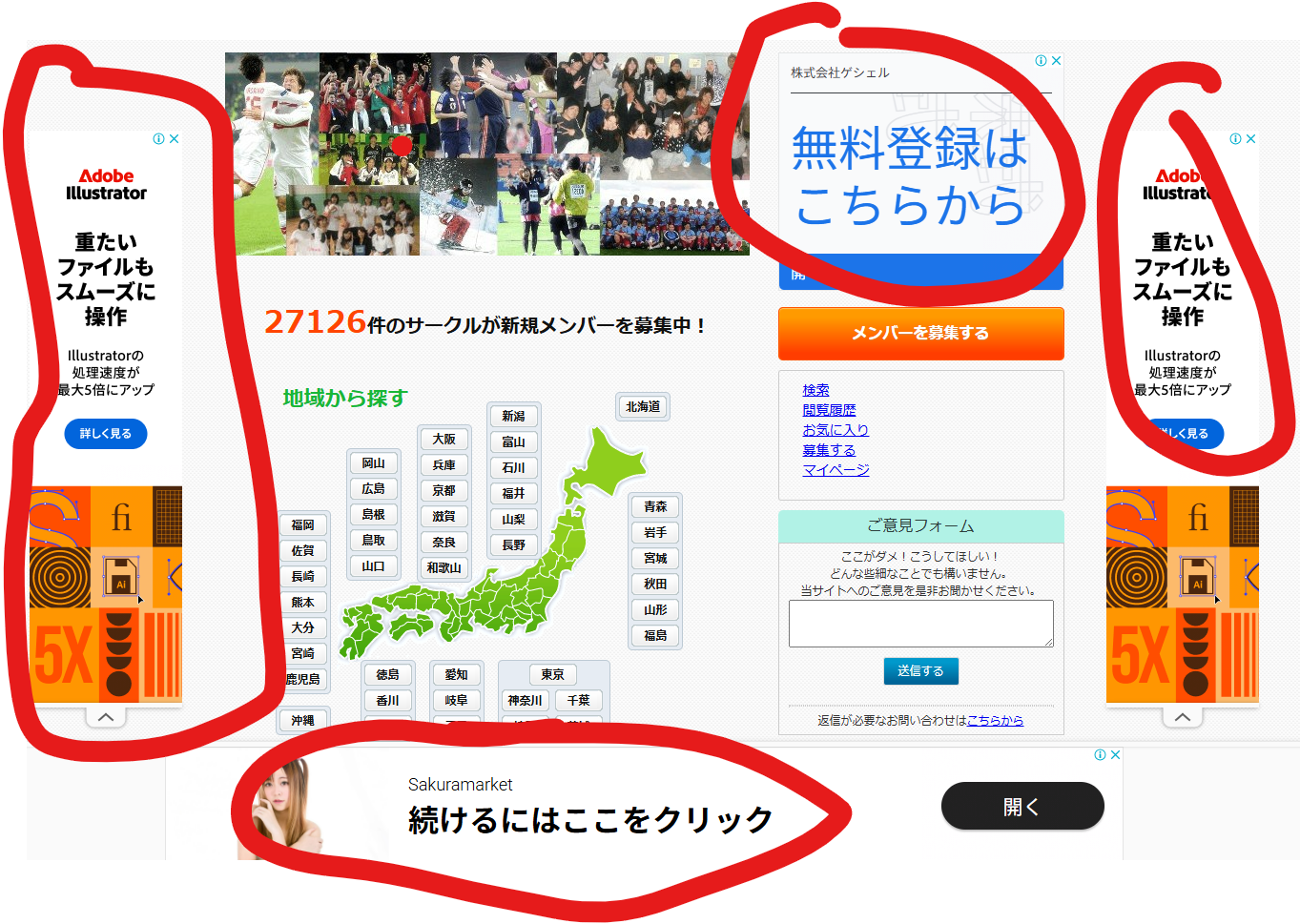
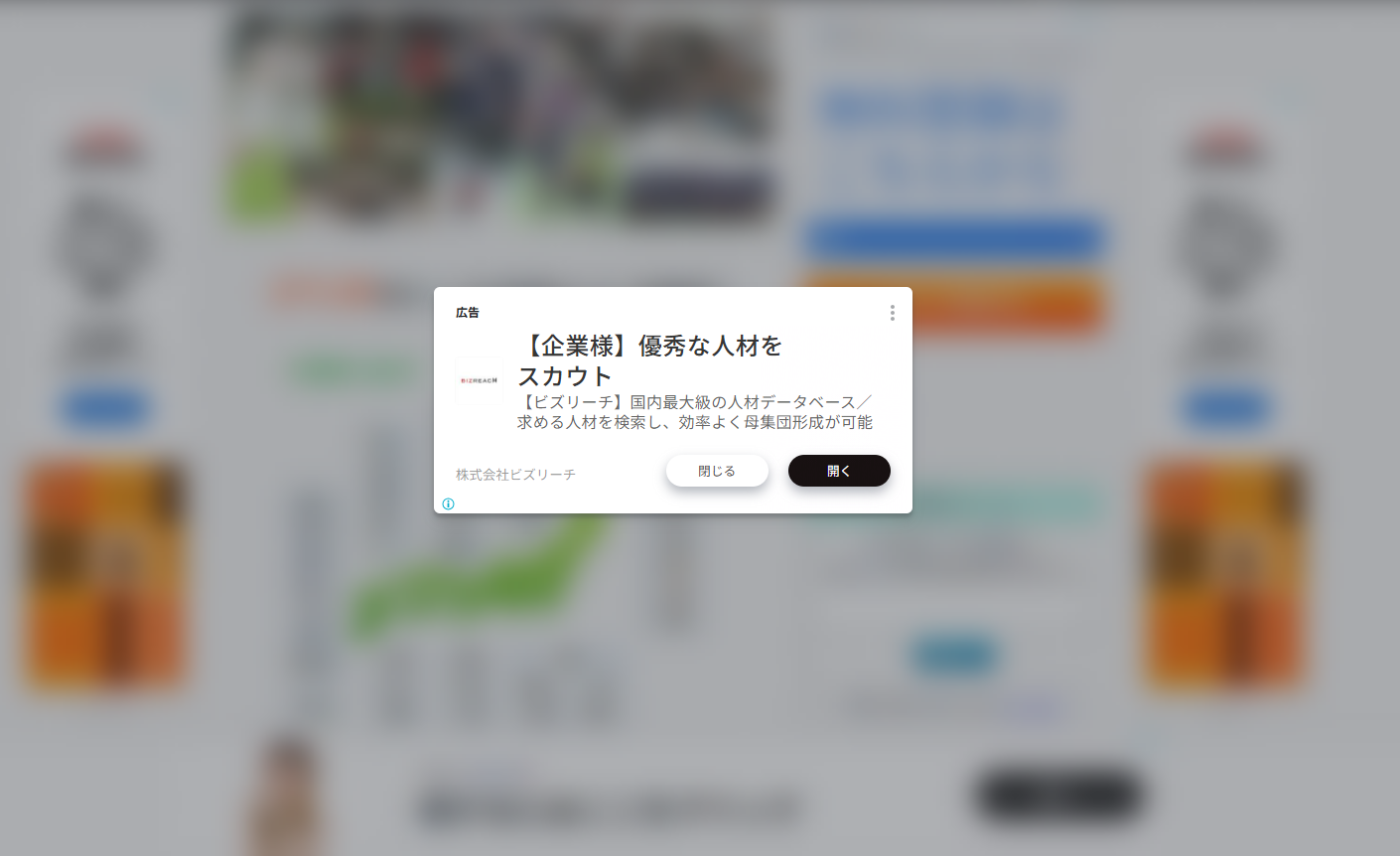
僕はただ単にバスケがやりたいだけなんですよ、安西先生。

広告ブロック系の Add-on、広告ブロック機能付いてるブラウザー、ありとあらゆる手段を試しても予想の斜め上の形式で入ってくる WEB 広告、もはや自分で広告がないサイトを作るしかないと思った今日このころです。
スポーツサークル業界の実態
スポーツサイトを作るにあたって、まずはこの業界を知らないといけない。
スポーツサークルのイベント主催者は大抵副業でやってます。
例えば、中学校や区立の体育館を利用してバスケをやるとします。
コートを貸してもらうにはまず利用者登録をしないといけない、これが結構厄介でめんどくさい。
同じ市町村や区に住まいの参加者が 10 人以上(市町村や体育館の決まりによって人数は異なる)在籍しないと団体登録ができない。
いざ団体登録出来たら 1 時間~ 1 時間半 1 コマで、大体一回 2 コマ借りてるサークルが多い。
公立の機関であるため、利用料金は 2000 円程度だが、1 人 500 ~ 1500 円参加費を取るサークルが多い。
バスケは 10 人いないとできないので、主催者入れて 11 人集まったとして、500 円/人でも 3000 円儲けが出る訳だ。
これをほかの運営者と協力して一日に異なる場所で何回も開催すると毎月そこそこ儲けが出る。
だから主催者にとってはいかにサークルに集客するかが大事だ。
サイトに募集を複数投稿したり、しつこくメーリスに追加をしたり、Instagram や LINE 公式アカウント運用がほとんど。
現状としてすべてを網羅できるサイトはいないが、下記 2 サイトが最も一般的な募集サイトと思われる。
クリックしてみるとわかるだろう、広告があまりに多すぎる。
逆に考えれば、これらのサイトは必ずしも直接閲覧しなければならないサイトでもないと考えられる。
実際に UI と広告を見るのはイベント主催者側だけでいいのではないか。
我々利用者側は単純にデータベースが欲しいのである。
そうするとやることは明白:
そうだ、コピーサイトを作ろう
まずはサイトのスクレイピングから始めよう。
個人的には東京周辺でしか活動しない(現実的に行けて千葉埼玉)ため、スクレイピング範囲は容易に制限できるし、サーバーに過度に負荷を与えることもない。
埋め込み JavaScript だけを飛ばして募集項目だけを表示。
import json
import logging
import asyncio
from urllib.parse import quote
import urllib.request
from bs4 import BeautifulSoup
logger = logging.getLogger()
logger.setLevel(logging.INFO)
itemId = 0
def getsoup(url):
try:
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
soup = BeautifulSoup(html, "html.parser")
return soup
except Exception as e:
return '404'
def getdetails(soup):
global itemId
lis = soup.select('#main-list > li')
res = {}
for li in lis:
detail_keys = li.select('.clearfix > dt')
detail_values = li.select('.clearfix > dd')
link = li.select('.clearfix > dd > a')[0].get('href')
itemId += 1
details = {}
jsonKeys = ['teamname', 'requirements', 'time', 'address']
for i in range(0, len(detail_keys)-1):
details[jsonKeys[i]] = detail_values[i].text
details['link'] = 'https://www.net-menber.com' + link
res[str(itemId)] = details
return res
async def getGames(kw):
url_base = 'https://www.net-menber.com/list/baske/index.html?ken='
kens = {'東京':8, '埼玉':10, '千葉':11}
res = {}
for ken, num in kens.items():
url = url_base + str(num) + "&q=" + quote(kw)
soup = getsoup(url)
if soup == '404':
continue
pager = soup.select('.pager')[0].select('li > a')
pages = len(pager)
if pages == 0:
res = {**res, **getdetails(soup)}
else:
for page in range(0, pages):
url += "&p=" + str(page+1)
soup = getsoup(url)
res = {**res, **getdetails(soup)}
return res
def lambda_handler(event, context):
logger.info(event)
method = event.get("requestContext", {}).get("http", {}).get("method", "")
if method == "OPTIONS":
return {
'statusCode': 200,
'body': 'Preflight Passed'
}
if method == "POST":
global itemId
itemId = 0
try:
body = json.loads(event['body'])
kw = body['kw']
loop = asyncio.new_event_loop()
res = loop.run_until_complete(getGames(kw))
# TODO implement
return {
'statusCode': 200,
'body': json.dumps(res, ensure_ascii=False)
}
except Exception as e:
logger.error(f"Error Occurred:{e}\nRequest:{event}")
res = {'1': 'Basketball scrapying error @Lambda#82'}
# TODO implement
return {
'statusCode': 500,
'body': json.dumps(res, ensure_ascii=False)
}
実行結果としてこのような JSON を得ることができる。
{
"1":{
"address": "東京:主に草加市内体育館(東武スカイツリーライン沿線沿い、竹ノ塚、北千住などから近いです!体育館も駅から徒歩8分以内!)",
"link": "https://www.net-menber.com/look/data/211440.html",
"requirements": "中高バスケ部経験者以上の男女!(バスケ経験部活動を含め6年以上)定期継続で参加できる方!",
"teamname": "【次回5/15(木)空き有!継続参加希望者募集】木曜草加バスケ🏀モクバス☁!男女ともに募集中!",
"time": "平日木曜日19-21時 月に平均3回ほど"
},
・・・
}
あとは Next.Js で作った UI にデータを渡して表示するだけ。
レポジトリー:https://github.com/pyxudev/letsplaybasketball
Vercel でホスティングして誰でも利用できるようにしました(現状個人で利用することを想定した仕様になってます)。
App URL: https://letsplaybasketball.vercel.app/
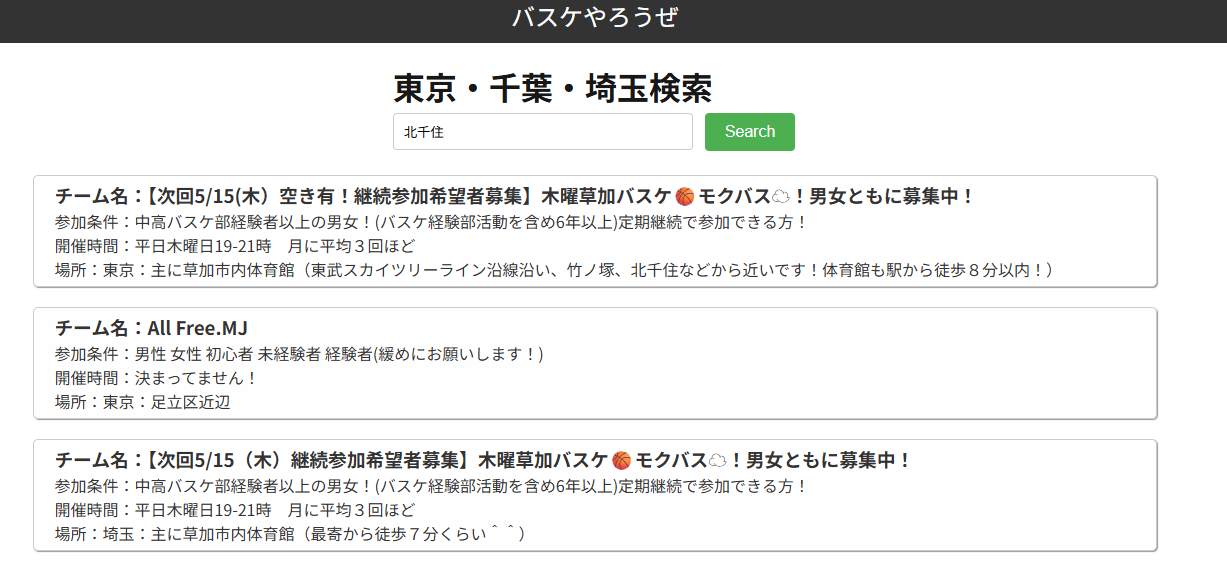
※「東京」とか「バスケ」とかいくらでも検索結果出てきそうなワードを使うと Lambda 側がタイムアウトしてしまうことがあります。
これで一旦広告がない自分だけの検索アプリを作ることができました。
さらば広告だらけの汚ねー募集サイトども!