Advent Calendar 7回目の投稿では、第6回目の投稿で公開したデータセット(XBRLで記述されたデータから抽出した情報をデータクレンジングしたもの)を、プログラムで可視化してみます。
(本記事のプログラムは、一切の保証なく、現状で提供されるものであり、XBRLJapanは、本プログラムの利用に伴って発生した不利益や問題について、原因のいかんを問わず、一切の責任を負わないものとします。)
1. XBRLデータを可視化する
1.1 プログラム概要
本プログラムは「EDINET開示のXBRLデータから、平均給与等の従業員情報を自動で抽出してみよう(データセット共有)(6/10)」で公開している給与情報等(平均年間給与(円)、平均勤続年数(年)、平均年齢(歳))のデータセットを、matplotlibライブラリで可視化するPython言語のプログラムです。(「2. ソースコード」に全コード記載)
可視化の手法は、箱ひげ図、棒グラフ、そしてカーネル密度推定を選択しました。なお、給与情報等の各データが全て揃っていない企業は、欠損データとして今回の処理から対象外としました。
1.2 事前準備
以下内容について、プログラム実行前に対応してください。その他ライブラリ(japanize_matplotlib、seaborn など)のインストールも事前に実施が必要です。また、実行環境に応じて、encodingやパス指定の方法も適宜変更します。そして、CSVの作成方法により、read_csvのsep属性をsep=',',やsep='/t'に適宜変更してください。
1.2.1 データセットファイルパスの決定
データクレンジング済みのデータセット(CSV形式)ファイルを読み込むパスを決定します。
dataset_filepath ='C:\\Users\\xxx\\Desktop\\xbrlReport\\xbrl_cleansing_qiita.csv'
df_dataset = pd.read_csv(dataset_filepath, header=0,sep=',', engine="python")
※環境によっては、sep='ではなく、sep='\t'とすべきかもしれません。
1.2.2 出力ファイルパスの決定
画像ファイルを出力するファイルパスを決定します。
plt.savefig('C:\\Users\\XXX\\Desktop\\xbrlReport\\XXXX.png')
1.3 実行結果
実行すると、箱ひげ図(業種別平均年間給与額、業種別平均勤続年数、業種別平均年齢)、棒グラフ(平均年間給与額TOP50(情報・通信業))、3種類のKDEを可視化した結果が画像として出力されます。
1.3.1 箱ひげ図
業種別平均年間給与額の箱ひげ図については、まず、与えられたデータセットを業種毎にグルーピング、業種単位で平均年間給与額を算出しました。その後、業種別の平均年間給与額をソートし、得られた結果から平均年間給与額のソート済み業種名リストを作成しました。
df_groupby_mean =dropped_dataset.groupby(['業種'], as_index=False).mean()
df_groupby_mean_s_by_salary = df_groupby_mean.sort_values('平均年間給与(円)')
df_gyoshu_label_by_salary = df_groupby_mean_s_by_salary['業種']
gyoshu_label_list_by_salary=df_gyoshu_label_by_salary.tolist()
可視化の際に、当該リストをY軸の表示順に適用することで、業種別の平均年間給与額の可視化が可能となっています。boxenplotを活用した箱ひげ図により、平均値と中央値の乖離を視覚的に確認できます。加えて、stripplotにより点をプロットすることで、散らばりについても可視化しました。平均勤続年数、平均年齢も同様に処理を行うことで作成しています。
sns.stripplot(x='平均年間給与(円)', y ='業種',orient = 'h', data=df_dropped_dataset,size=3,edgecolor="gray",order=gyoshu_label_list_by_salary)
ax =sns.boxenplot(x='平均年間給与(円)', y='業種',orient = 'h', data=df_dropped_dataset,palette='rainbow',order=gyoshu_label_list_by_salary);



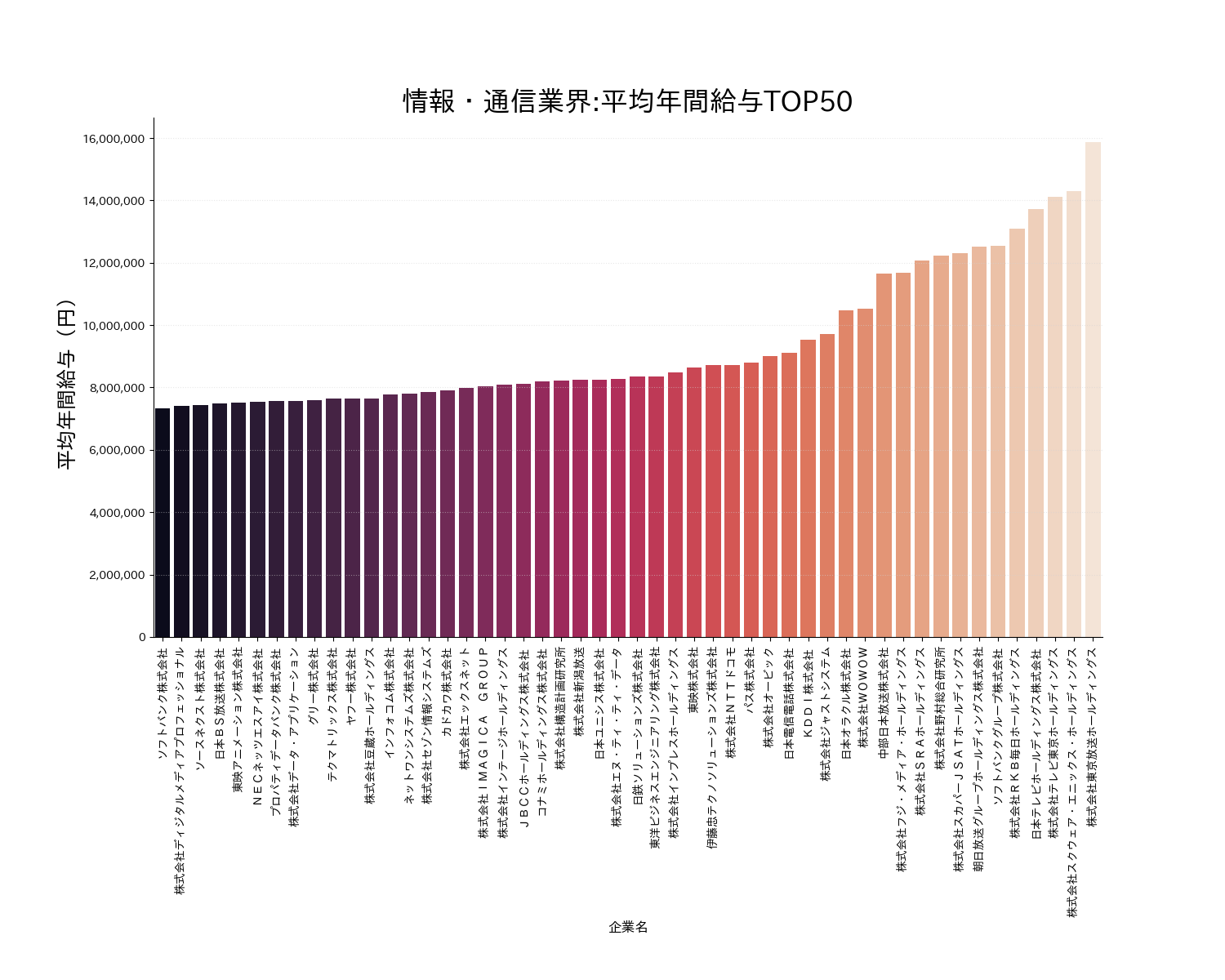
1.3.2 棒グラフ
業種が情報・通信業の企業のみを抽出、その後平均年間給与(円)でソートをかけた結果から上位50社を抽出しました。(Qiita閲覧者の層を考慮の上、情報・通信業を選択してみました)
df_info=df_dropped_dataset[df_dropped_dataset["業種"] == "情報・通信業"]
df_info_sortby_salary = df_info.sort_values('平均年間給与(円)')[-50:]
箱ひげ図のときと同様、給与でソート済みの企業名をリスト化し、X軸の表示順に利用しています。後は、barplotに情報・通信業のデータと、ソート済みのリストを渡すだけで、平均年間給与TOP50社を描画することができます。
df_info_label_list_sortby_salary=df_info_sortby_salary['企業名'].tolist()
ax =sns.barplot(x="企業名", y="平均年間給与(円)", data=df_info,palette='rocket',order=df_info_label_list_sortby_salary)
["業種"] == "情報・通信業"を好きな業種(水産・農林業、サービス業など)に変更することで、別業種のTOP50を可視化することができます。また、[-50:]の数値を変えることで、TOPいくつまで描画するかをコントロールもできます。そして、多少のカスタマイズは必要ですが、平均年間給与以外の、平均勤続年数(年)、平均年齢(歳)を条件に加えることで、フィルターをかけた結果を得ることもできます。
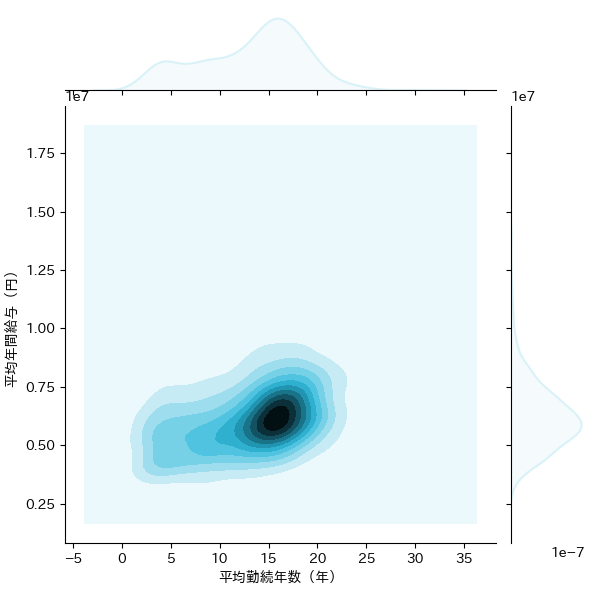
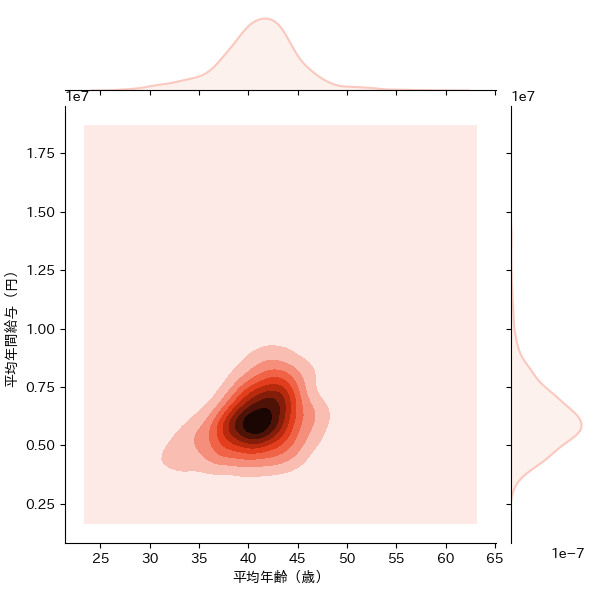
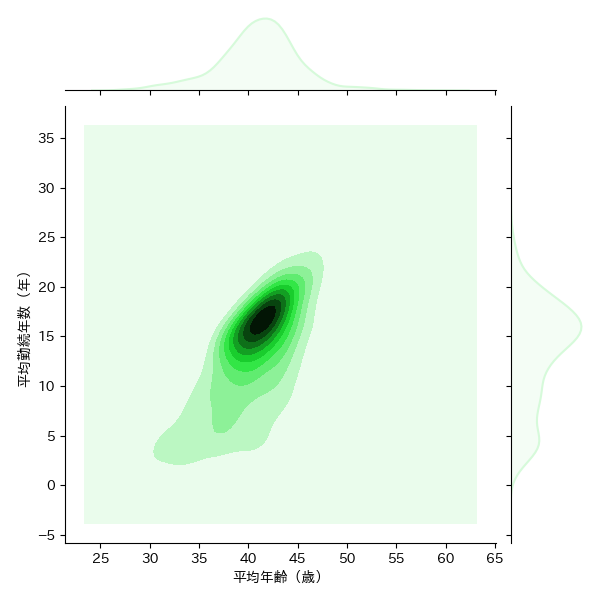
1.3.3 カーネル密度推定
平均勤続年数ー平均年間給与、平均年齢ー平均年間給与、平均年齢ー平均勤続年数の3パターンの組み合わせのKDEを描画しました。業種別とは異なり、全体を俯瞰した形で、EDINETに提出されている企業全体の大よその平均値を知ることができます。
sns.jointplot('平均勤続年数(年)', '平均年間給与(円)',data=df_dropped_dataset, kind="kde",color="#d9f2f8")
sns.jointplot('平均年齢(歳)', '平均年間給与(円)',data=df_dropped_dataset, kind="kde",color="#fac8be")
sns.jointplot('平均年齢(歳)', '平均勤続年数(年)',data=df_dropped_dataset, kind="kde",color="#d6fada")
2. ソースコード
# -*- coding: utf-8 -*-
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
import matplotlib.ticker as ticker
import japanize_matplotlib # https://yolo.love/matplotlib/japanese/
def drop_unnecessary_data(dataset_filepath):
df_dataset = pd.read_csv(dataset_filepath, header=0,sep=',', engine="python")
df_dropped_dataset = df_dataset.dropna()
df_dropped_dataset = df_dropped_dataset.drop('#', axis=1)
df_dropped_dataset = df_dropped_dataset.drop('EDINETCODE', axis=1)
print(df_dropped_dataset)
print(df_dropped_dataset.info())
print('行数',len(df_dropped_dataset))
return df_dropped_dataset
def make_label_list(dropped_dataset):
df_groupby_mean =dropped_dataset.groupby(['業種'], as_index=False).mean()
df_groupby_mean_s_by_salary = df_groupby_mean.sort_values('平均年間給与(円)')
df_gyoshu_label_by_salary = df_groupby_mean_s_by_salary['業種']
gyoshu_label_list_by_salary=df_gyoshu_label_by_salary.tolist()
df_groupby_mean_s_by_service = df_groupby_mean.sort_values('平均勤続年数(年)')
df_gyoshu_label_by_service = df_groupby_mean_s_by_service['業種']
gyoshu_label_list_by_service=df_gyoshu_label_by_service.tolist()
df_groupby_mean_s_by_age = df_groupby_mean.sort_values('平均年齢(歳)')
df_gyoshu_label_by_age = df_groupby_mean_s_by_age['業種']
gyoshu_label_list_by_age=df_gyoshu_label_by_age.tolist()
return gyoshu_label_list_by_salary,gyoshu_label_list_by_service,gyoshu_label_list_by_age
def visualize_boxenplot_salary(gyoshu_label_list_by_salary,df_dropped_dataset):
plt.figure(figsize=(15, 10))
sns.stripplot(x='平均年間給与(円)', y ='業種',orient = 'h', data=df_dropped_dataset,size=3,edgecolor="gray",order=gyoshu_label_list_by_salary)
ax =sns.boxenplot(x='平均年間給与(円)', y='業種',orient = 'h', data=df_dropped_dataset,palette='rainbow',order=gyoshu_label_list_by_salary)
ax.grid(which = "major",color='lightgray',ls=':',alpha = 0.5)
ax.xaxis.set_minor_locator(ticker.AutoMinorLocator())
ax.xaxis.set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
plt.xlabel("平均年間給与(円)", fontsize=18)
plt.ylabel("業種",fontsize=16)
plt.title("業種別平均年間給与額", fontsize=24)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().yaxis.set_ticks_position('left')
plt.gca().xaxis.set_ticks_position('bottom')
plt.savefig('C:\\Users\\xxx\\Desktop\\xbrlReport\\boxenplot_1.png')
plt.show()
def visualize_boxenplot_service(gyoshu_label_list_by_service,df_dropped_dataset):
plt.figure(figsize=(15, 10))
sns.stripplot(x='平均勤続年数(年)', y ='業種',orient = 'h', data=df_dropped_dataset,size=3,edgecolor="gray",order=gyoshu_label_list_by_service)
ax =sns.boxenplot(x='平均勤続年数(年)', y='業種',orient = 'h', data=df_dropped_dataset,palette='rainbow',order=gyoshu_label_list_by_service)
ax.grid(which = "major",color='lightgray',ls=':',alpha = 0.5)
ax.xaxis.set_minor_locator(ticker.AutoMinorLocator())
plt.xlabel("平均勤続年数(年)", fontsize=18)
plt.ylabel("業種",fontsize=16)
plt.title("業種別平均勤続年数", fontsize=24)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().yaxis.set_ticks_position('left')
plt.gca().xaxis.set_ticks_position('bottom')
plt.savefig("C:\\Users\\xxx\\Desktop\\xbrlReport\\boxenplot_2.png")
plt.show()
def visualize_boxenplot_age(gyoshu_label_list_by_age,df_dropped_dataset):
plt.figure(figsize=(15, 10))
sns.stripplot(x='平均年齢(歳)', y ='業種',orient = 'h', data=df_dropped_dataset,size=3,edgecolor="gray",order=gyoshu_label_list_by_age)
ax =sns.boxenplot(x='平均年齢(歳)', y='業種',orient = 'h', data=df_dropped_dataset,palette='rainbow',order=gyoshu_label_list_by_age);
ax.grid(which = "major",color='lightgray',ls=':',alpha = 0.5)
ax.xaxis.set_minor_locator(ticker.AutoMinorLocator())
plt.xlabel("平均年齢(歳)", fontsize=18)
plt.ylabel("業種",fontsize=16)
plt.title("業種別平均年齢", fontsize=24)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().yaxis.set_ticks_position('left')
plt.gca().xaxis.set_ticks_position('bottom')
plt.savefig("C:\\Users\\xxx\\Desktop\\xbrlReport\\boxenplot_3.png")
plt.show()
def visualize_jointplot(df_dropped_dataset):
sns.jointplot('平均勤続年数(年)', '平均年間給与(円)',data=df_dropped_dataset, kind="kde",color="#d9f2f8")
plt.savefig("C:\\Users\\xxx\\Desktop\\xbrlReport\\jointplot_1.png")
plt.show()
sns.jointplot('平均年齢(歳)', '平均年間給与(円)',data=df_dropped_dataset, kind="kde",color="#fac8be")
plt.savefig("C:\\Users\\xxx\\Desktop\\xbrlReport\\jointplot_2.png")
plt.show()
sns.jointplot('平均年齢(歳)', '平均勤続年数(年)',data=df_dropped_dataset, kind="kde",color="#d6fada")
plt.savefig("C:\\Users\\xxx\\Desktop\\xbrlReport\\jointplot_3.png")
plt.show()
def visualize_barplot(df_dropped_dataset):
df_info=df_dropped_dataset[df_dropped_dataset["業種"] == "情報・通信業"]
df_info_sortby_salary = df_info.sort_values('平均年間給与(円)')[-50:]
df_info_label_list_sortby_salary=df_info_sortby_salary['企業名'].tolist()
plt.figure(figsize=(15, 12))
ax =sns.barplot(x="企業名", y="平均年間給与(円)", data=df_info,palette='rocket',order=df_info_label_list_sortby_salary)
sns.set(style="ticks")
plt.xticks(rotation=90)
plt.subplots_adjust(hspace=0.8,bottom=0.35)
ax.grid(which = 'major',axis ='y', color='lightgray',ls=':',alpha = 0.5)
ax.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
plt.xlabel("企業名", fontsize=12)
plt.ylabel("平均年間給与(円)",fontsize=18)
plt.title("情報・通信業界:平均年間給与TOP50", fontsize=24)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().yaxis.set_ticks_position('left')
plt.gca().xaxis.set_ticks_position('bottom')
plt.savefig("C:\\Users\\xxx\\Desktop\\xbrlReport\\barplot_1.png")
plt.show()
def main():
dataset_filepath ='C:\\Users\\xxx\\Desktop\\xbrlReport\\xbrl_cleansing_qiita.csv'
df_dropped_dataset = drop_unnecessary_data(dataset_filepath)
gyoshu_label_list_by_salary, gyoshu_label_list_by_service, gyoshu_label_list_by_age = make_label_list(df_dropped_dataset)
visualize_boxenplot_salary(gyoshu_label_list_by_salary,df_dropped_dataset)
visualize_boxenplot_service(gyoshu_label_list_by_service,df_dropped_dataset)
visualize_boxenplot_age(gyoshu_label_list_by_age,df_dropped_dataset)
visualize_jointplot(df_dropped_dataset)
visualize_barplot(df_dropped_dataset)
print("visualize finish")
if __name__ == "__main__":
main()
3. 分析に向けて
本記事では生データの可視化に焦点を当てましたが、こういったデータに少し加工を加えることで企業分析が可能になります。例えば、平均年齢-平均勤続年数が25歳ぐらいであれば、概ね新卒で、退職者や中途採用が少ないことが知られていますので、そういった企業を抽出できます。ここに企業年齢を加えることで、更に深い分析ができます。(企業年齢はXBRLデータから要素名「jpcrp_cor:FiscalYearCoverPage」で取得可能)企業年齢が高く、平均勤続年数が42歳を超えている企業は高齢化傾向にあります。将来、高齢者がまとめて退職することで、平均年齢が突然下がり、結果、当期純利益が突然高くなったりします。(企業の利益率が高くなったのではなく、販管費でもっとも重い、支払給与の総額が下がるため)今後は、従業員の年齢分布が下がることにより、どの企業も利益率が高くなることが想定されるため、利益率の変化だけに注視するのではなく、こういった従業員の分布に注視するのも面白いですね。
その他、売上÷従業員数(前期と今期の平均)の時系列や従業員数を比較し分析することも考えられます。なぜならば、一人当たり売上高は、リストラ効果により数値が良く見えてしまうためです。
このように、EDINETから従業員情報が取得できるようになったことで、企業分析の幅が広がりました。ここに記載した内容以外でも、是非興味のある方は調査してみてください。
4. 問合せ先
本記事に関する問い合わせは、以下のメールアドレスまでお願いします。
e-mail:xbrl-tech-qa@xbrl.or.jp
(もちろん、qiita上でのコメントも歓迎します)
本メールアドレスは、qiitaの記事を執筆しているXBRLJapanの開発委員会の問合せ窓口になります。
そのため、組織に関する一般的な問合せなどは内容によって回答できかねますが、XBRLに関する技術的な質問、意見、要望、助言等はお気軽にご連絡ください。
なお、委員会メンバが有志で対応しているため、回答に時間がかかることもありますが、ご了承ください。