XBRLJapanのメンバーKです。
企業の決算情報を取得可能にするXBRLは、EDINETだけでなく様々な報告書に使われています。例えば、決算短信を提供するTDnetの 適時開示情報閲覧サービス でもXBRLデータを入手することができます。
今回は、決算短信のサマリ情報から売上高の増減率を抜き出して、前期時点の増減率(2019年から2020年にかけての増減率)と当期時点の増減率(2020年から2021年にかけての増減率)を比較してみましょう。
やること
- 四半期決算短信の1ページ目にある、「経営成績」の「売上高」の前年同期比を2期分取得
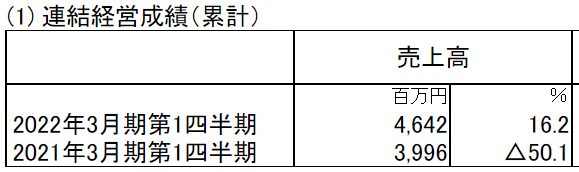
株式会社 あみやき亭の第1四半期決算短信を例にすると、16.2%と△50.1%の部分を取得します。
- 取得した2期分の売上高増減率を使って、ヒストグラムを描画する
- ヒストグラムを描画する際、前年同期と当期を色分けすることで当期の売上増加傾向を視覚的に把握
結果のイメージ
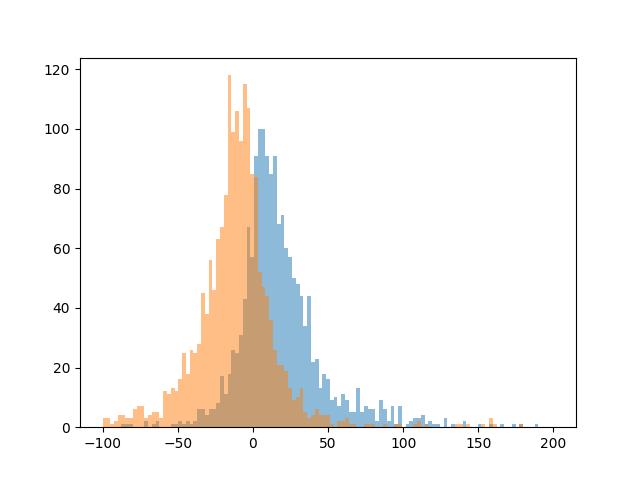
オレンジ色のヒストグラムは、前年同期(多くの企業がCOVID-19影響を受けた時期)の売上増減率のヒストグラム
青色のヒストグラムは、当期(多くの企業がCOVID-19影響から回復している時期)の売上増減率のヒストグラム
前提
- TDnetからXBRLデータをダウンロード・解凍し、解凍後のファイルが特定のフォルダ内に格納されていること
- 2022年3月31日が決算期の会社の第1四半期・第2四半期の決算短信を対象にすること
- 会計基準に日本基準を採用している企業を前提にすること
手順
- TDnetからXBRLデータをダウンロード
- XBRLデータからデータフレームを作成
- ヒストグラムの描画
1. TDnetからXBRLデータをダウンロード
TDnetの 適時開示情報閲覧サービス からXBRLデータをダウンロードしてください。
以下のアイコンをクリックすることでXBRLデータがダウンロードできます。

ダウンロードした複数のXBRLファイル(zipファイル)はそれぞれ解凍して、任意のフォルダ内にまとめて保存してください。
2. XBRLデータからデータフレームを作成
import re
import glob
import jaconv
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
def get_specific_nonfra(arg_path, arg_tag_nonfra):
'''
特定のファイルから、指定されたXBRLタグ名の数値要素を取得し、データフレームに変換する関数
引数1、対象となるXBRLデータのファイルパス
引数2、取得対象となるXBRLタグ要素名
戻り値、データフレーム
'''
# headerファイルの読み込み
with open(arg_path, encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
# nonFractionタグのみ抽出
tags_nonfraction = soup.find_all('ix:nonfraction', attrs={'name': arg_tag_nonfra, 'contextref': re.compile(r'.*ResultMember')})
if tags_nonfraction:
list_fs = []
# 各fsの各要素を辞書に格納
for each_item in tags_nonfraction:
dict_fs = {}
dict_fs['contextref'] = each_item.get('contextref')
dict_fs['escape'] = each_item.get('escape')
dict_fs['format'] = each_item.get('format')
dict_fs['decimals'] = each_item.get('decimals')
dict_fs['name'] = each_item.get('name')
dict_fs['scale'] = each_item.get('scale')
dict_fs['unitRef'] = each_item.get('unitref')
# マイナス表記の場合の処理+円単位への変更
if each_item.get('unitref')=='JPY':
if each_item.get('sign') == '-' and each_item.get('xsi:nil') != 'true':
amount = int(each_item.get_text().replace(',', '')) * -1 * 10 ** int(each_item.get('scale'))
elif each_item.get('xsi:nil') != 'true':
amount = int(each_item.get_text().replace(',', '')) * 10 ** int(each_item.get('scale'))
else:
amount = np.nan
else:
# マイナス表記の場合の処理+円単位への変更※比率の場合を除く
if each_item.get('sign') == '-' and each_item.get('xsi:nil') != 'true':
try:
amount = float(each_item.get_text().replace(',', '')) * -1
except:
amount = np.nan
elif each_item.get('xsi:nil') != 'true':
try:
amount = float(each_item.get_text().replace(',', ''))
except:
amount = np.nan
else:
amount = np.nan
dict_fs['content'] = float(amount)
# 辞書をリストへ格納
list_fs.append(dict_fs)
df_each_fs = pd.DataFrame(list_fs)
# 当期フラグをつける
df_each_fs['flg_current'] = np.where(df_each_fs['contextref'].str.startswith('Current'), 1, 0)
else:
df_each_fs = pd.DataFrame()
return df_each_fs
def get_text_nonfra(arg_soup, target_name):
'''
bs4オブジェクトから、指定されたnameのNonNumericタグで囲われたテキストを返す変数
引数は、bs4オブジェクトと取得対象となるname(文字列)
戻り値は、テキスト
'''
output_text = arg_soup.find_all('ix:nonnumeric', attrs={'name': re.compile('.*' + target_name)})
if output_text:
output_text = str(output_text[0].text)
else:
output_text = ''
return output_text
def get_tansin_outline(arg_path):
'''
指定されたdocIDに該当する短信の概要情報(会社名、決算期、提出日等)をデータフレームで返す関数
引数は、ファイルパス
戻り値は、概要情報を含むデータフレーム
'''
# output用の辞書を定義
dict_output = {}
# 文書IDの取得
dict_output['docID'] = re.search(r'\d{18}', arg_path).group()
# ファイルパスの取得
# Summaryフォルダがない(短信の1ページ目のXBRLデータがない)場合もあるため、tryで実行
try:
# headerファイルの読み込み
with open(arg_path, encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
except:
soup = None
# soupにNoneでない場合の処理
if soup:
# 証券コード取得
seccode = get_text_nonfra(soup, 'SecuritiesCode')
# TDNetの場合、証券コードが4桁の場合と5桁の場合がある。5桁は末尾の1桁に0が入っている。4桁にそろえる。
dict_output['SecCode'] = seccode if len(seccode) == 4 else seccode[:4]
# 会社名取得
dict_output['CompanyName'] = get_text_nonfra(soup, 'CompanyName')
# 書類名取得
doc_name = get_text_nonfra(soup, 'DocumentName')
doc_name = jaconv.zen2han(doc_name, kana=False, digit=True, ascii=True)
dict_output['DocumentName'] = doc_name
# 決算種別の取得
# 文書タイトルからの判断
q_period = re.search(r'\d', doc_name)
if q_period:
q_period = 'Q' + q_period.group()
else:
q_period = '期末'
dict_output['決算期種別'] = q_period
# 提出日取得
filing_date = get_text_nonfra(soup, 'FilingDate')
filing_date = jaconv.zen2han(filing_date, kana=False, digit=True, ascii=True)
# 提出年の取得。
filing_year = re.search(r'\d*年', filing_date).group().replace('年','')
# 和暦を西暦に変換(令和のみ対応)
filing_year = filing_year if len(filing_year)==4 else str(int(filing_year)+2018)
# 提出月を取得
filing_month = re.search(r'\d*月', filing_date).group().replace('月','')
filing_month = filing_month if len(filing_month)==2 else '0'+filing_month
# 提出日を取得
filing_day = re.search(r'\d*日', filing_date).group().replace('日','')
filing_day = filing_day if len(filing_day)==2 else '0'+filing_day
dict_output['FilingDate'] = filing_year + '-' + filing_month + '-' + filing_day
# 決算期末
dict_output['FiscalYearEnd'] = get_text_nonfra(soup, 'FiscalYearEnd')
else:
dict_output['SecCode'] = None
dict_output['CompanyName'] = None
dict_output['DocumentName'] = None
dict_output['決算期種別'] = None
dict_output['FilingDate'] = None
dict_output['FiscalYearEnd'] = None
df_output = pd.DataFrame([dict_output])
return df_output
# XBRLデータの検索
list_tdnet_xbrl = glob.glob('各XBRLデータを解凍・格納した親フォルダ' + '**/XBRLData/Summary/**.htm')
# 結果格納用のリストを定義
list_result_df = []
# 進捗表示用のカウンタ初期化
j = 0
for each_xbrl_file in list_tdnet_xbrl:
# ファイル数によって処理が長くなる可能性があるため、進捗率を示すカウンタを表示
j += 1
print(str(j) + '/' + str(len(list_tdnet_xbrl)))
print('')
# 任意のタグ要素を取得
# tse-ed-t:ChangeInNetSalesは日本基準の売上高を想定
df_fs = get_specific_nonfra(each_xbrl_file, 'tse-ed-t:ChangeInNetSales')
if not df_fs.empty:
# 増減率の値を取得できた場合のみ以下の処理を実行
# 増減率の値を取得した会社名等の概要情報を取得
df_outline = get_tansin_outline(each_xbrl_file)
df_outline['temp_joinkey'] = 1
df_fs['temp_joinkey'] = 1
# 決算短信の概要情報と増減率のDFを結合
df_temp = pd.merge(df_outline, df_fs, on='temp_joinkey').drop(columns='temp_joinkey')
# 結果をリストに格納
list_result_df.append(df_temp)
# 取得した各DFを縦結合
df_for_hist = pd.concat(list_result_df)
# 新規上場等で前年同期の増減率がない場合(NaNの場合)は、行ごと削除
df_for_hist = df_for_hist[df_for_hist['content']==df_for_hist['content']]
# 列の型変換
df_for_hist = df_for_hist.astype({'content': float})
今回は、日本基準を採用している企業を前提にXBRLタグの要素名を指定(tse-ed-t:ChangeInNetSales)しました。
IFRS採用企業や特殊な業種によって、対象となりうるXBRLタグの要素名は異なります。
決算短信用のタクソノミは こちら で公開されています。
先日タクソノミをデータフレームにする記事も 公開しました ので、取得すべきXBRLタグの要素名を調べてみてください。
なお、営業利益のように負の値(赤字)をとり得る科目の場合、増減率を計算しないことになっていますので、ヒストグラムを描画する場合は、売上高にするとよいでしょう。
3. ヒストグラムの描画
import matplotlib.pyplot as plt
# ヒストグラム描画用のパラメータ設定
param_period = 'Q2' # ヒストグラム描画対象の決算期定義
param_max = 200 # ヒストグラム描画の最大値を定義。いったん200%を上限にする
param_min = -100 # ヒストグラム描画の最小値を定義。いったんマイナス100%を下限にする
parm_binsize = 2.5 # 各ヒストグラムのサイズを定義。いったん2.5%ポイントに設定
# 設定したパラメータの条件でDFをフィルタ
df_target = df_for_hist[(df_for_hist['決算期種別']==param_period) & (df_for_hist['content']>=param_min) & (df_for_hist['content']<param_max)]
# ヒストグラムを描画する際のループ用にflg_currentの要素をリストに格納
list_target_period = df_for_hist['flg_current'].unique()
# 最大値と最小値の間をn_bin等分した幅でヒストグラムの棒を表示するように設定(各targetのbin幅を統一する)
n_bin = int((param_max - param_min)/parm_binsize)
x_max = param_max
x_min = param_min
bins = np.linspace(x_min, x_max, n_bin)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
for target in list_target_period:
# ヒストグラムの描画
ax.hist(df_target[df_target['flg_current'] == target]['content'], bins=bins, alpha=0.5, label=target)
fig.show()
可視化結果
オレンジ色のヒストグラムは、前年同期(多くの企業がCOVID-19影響を受けた時期)の売上増減率のヒストグラム
青色のヒストグラムは、当期(多くの企業がCOVID-19影響から回復している時期)の売上増減率のヒストグラム
第1四半期での比較
第2四半期での比較
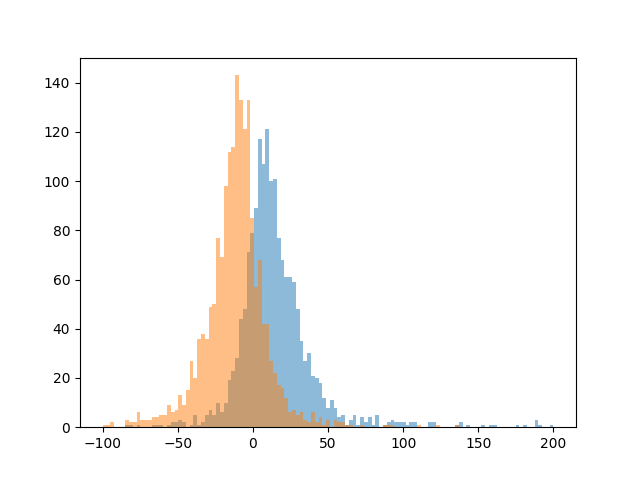
第1四半期から第2四半期にかけて、左右のオレンジと青の山が若干より離れていることから、COVID-19からの回復傾向が進んでいると見て取れるのではないかと思います。
まとめ
今回は、ダウンロードしたXBRLファイルを都度BeautifulSoupで処理してヒストグラムを描写する方法を記載しました。
しかしこの方法では、都度処理が必要になること、異なるタグ要素名を取得したい場合に処理しなおす必要がある、ヒストグラムを描画する対象企業がXBRLファイルをダウンロードした企業に依存するなど、あまり勝手がいいとは言えません。
MySQLやPostgreSQLなどのSQLサーバを構築して、事前にデータを格納しておくことで、より臨機応変に分析ができるようになるかと思います。
2022年1月以降、第3四半期の決算短信が開示されます。どのようなヒストグラムになるか、ぜひ試してみてください。