1. 概要
「AWSのS3バケットにファイルとかフォルダがアップロードされたら、GCPの2つのプロジェクトのGCSバケットへ自動で上書きアップロードするシステム」を構築したときのお話。
前提
- Macで作業(チップはM2, Docker Desktop for Mac インストール済み)
- Lambdaコードの記述言語はPython3
- 2つのGCPプロジェクトに対する操作は、別のプロジェクトのサービスアカウントを介して行う。
- LambdaからGCS操作する際の認証はWorkload Identityを利用
2. システム構成図
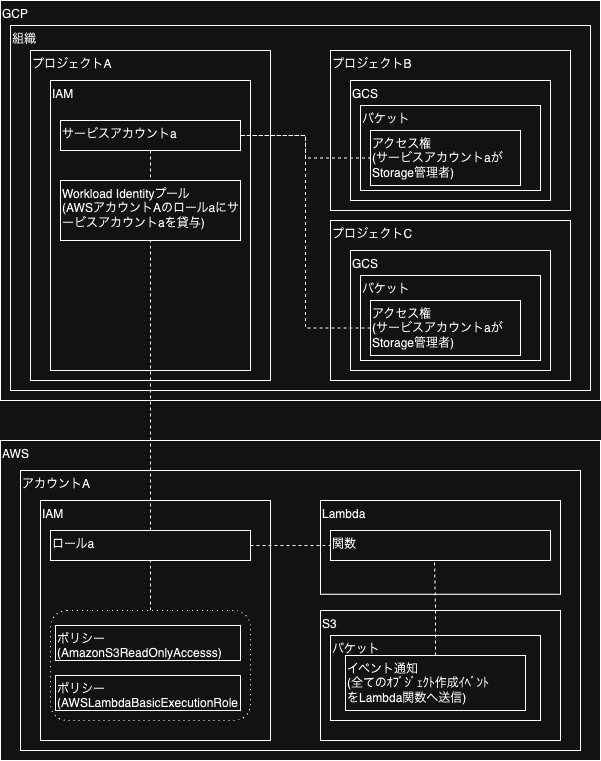
破線は紐づき関係。
3. 構築
の記事の情報をベースに構築(2プロジェクトのGCSへコピー、ファイル・ディレクトリ構成そのままにコピーという点で、pythonのコードや環境変数は結構違う)
3.1. 設定一覧
3.1.1. AWS
Lambda
- コードソース: pythonプロジェクトをzipで固めてアップロード(コードの中身、プロジェクトの構成、zipまでの作成手順は後述)
- ランタイム: python3.11
- ハンドラ: lambda_function.lambda_handler(デフォルト値)
- アーキテクチャ: x86_64
- タイムアウト: <コピーするのに十分な時間>
- トリガー: 対象のS3バケットについて、Event types: All object create events
- アクセス権限: AmazonS3ReadOnlyAccess と AWSLambdaBasicExecutionRole のポリシーを付与したロール
- 環境変数:
-
S3_BUCKET_NAME: <アカウントAのS3バケット名> -
GCP_PROJECT_ID_A: <GCPプロジェクトAのプロジェクトID> (プロジェクト名じゃないので注意) -
GCP_PROJECT_ID_B: <GCPプロジェクトBのプロジェクトID> -
GCS_BUCKET_NAME_A: <GCPプロジェクトAのGCSバケット名> -
GCS_BUCKET_NAME_B: <GCPプロジェクトBのGCSバケット名> -
GOOGLE_APPLICATION_CREDENTIALS:
-
Lambda関数のPythonコード
lambda_function.py
import os
import json
import shutil
import glob
import boto3 # AWSクライアント
from google.cloud import storage # GCSクライアント
# Lambdaの一時保存ディレクトリのパス
LAMBDA_TMP_DIR = "/tmp/"
# メイン関数
def lambda_handler(event, context):
s3_bucket_name = os.environ["S3_BUCKET_NAME"]
gcp_project_id_a = os.environ["GCP_PROJECT_ID_A"]
gcs_bucket_name_a = os.environ["GCS_BUCKET_NAME_A"]
gcp_project_id_b = os.environ["GCP_PROJECT_ID_B"]
gcs_bucket_name_b = os.environ["GCS_BUCKET_NAME_B"]
clear_lambda_tmp_dir()
download_all_files_from_s3(s3_bucket_name)
upload_all_files_to_gcs(gcp_project_id_a, gcs_bucket_name_a)
upload_all_files_to_gcs(gcp_project_id_b, gcs_bucket_name_b)
return {
'statusCode': 200,
'body': json.dumps('finish')
}
# Lambdaの一時保存ディレクトリ配下のファイルをすべて削除
def clear_lambda_tmp_dir():
dir = LAMBDA_TMP_DIR
for files in os.listdir(dir):
path = os.path.join(dir, files)
try:
shutil.rmtree(path)
except OSError:
os.remove(path)
# 指定したS3バケットに存在する全てのファイルをLambdaの一時保存ディレクトリにダウンロード
def download_all_files_from_s3(s3_bucket_name):
s3_client = boto3.client("s3")
response = s3_client.list_objects_v2(Bucket=s3_bucket_name)
contents = response["Contents"]
for content in contents:
# DL元になるS3オブジェクトのフルパス, ディレクトリまでのパス, ファイル名
s3_file_path = content['Key']
# パスがディレクトリで終わる場合は無視
if s3_file_path.endswith("/"):
continue
s3_dir_path = os.path.dirname(s3_file_path)
s3_file_name = os.path.basename(s3_file_path)
# DL先になるlambda一時保存領域上のファイルのフルパス
local_dir_path = os.path.join(LAMBDA_TMP_DIR, s3_dir_path)
local_file_path = os.path.join(local_dir_path, s3_file_name)
# DL先のディレクトリがないならば作成
if not os.path.exists(local_dir_path):
print(f"mkdir: {local_dir_path}")
os.makedirs(local_dir_path)
# S3からLambdaへのDL実行
s3_client.download_file(s3_bucket_name, s3_file_path, local_file_path)
print(f"downloaded s3 object({s3_bucket_name}:{s3_file_path}) to local file({local_file_path})")
print_lambda_tmp_dir_files()
# Lambdaの一時保存ディレクトリに存在する全てのファイルを指定したGCSバケットにアップロード(ファイル・ディレクトリ構成そのまま)
def upload_all_files_to_gcs(gcp_project_id, gcs_bucket_name):
gcs = storage.Client(project=gcp_project_id)
bucket = gcs.bucket(gcs_bucket_name)
for root, dirs, files in os.walk(top=LAMBDA_TMP_DIR):
for file in files:
# UL先になるGCSオブジェクトのフルパス
local_file_path = os.path.join(root, file)
print(f"local_file_path: {local_file_path}")
# UL元のlambda一時保存領域上ファイルのフルパス
gcs_file_path = os.path.relpath(local_file_path, LAMBDA_TMP_DIR)
print(f"gcs_file_path: {gcs_file_path}")
blob = bucket.blob(gcs_file_path) # /から始まると無駄に/ディレクトリがバケット上にできるので注意
blob.upload_from_filename(local_file_path)
print(f"uploaded localfile({local_file_path}) to object({gcs_bucket_name}:{gcs_file_path})")
# Lambdaの一時領域(/tmp/以下)のファイルを一覧表示
def print_lambda_tmp_dir_files():
for root, dirs, files in os.walk(top=LAMBDA_TMP_DIR):
for dir in dirs:
dir_path = os.path.join(root, dir)
print(f"dir_path: {dir_path}")
for file in files:
file_path = os.path.join(root, file)
print(f"file_path: {file_path}")
コードソースのプロジェクト構成 と 作成手順
# 1. 作業用ディレクトリ作成(ディレクトリ名はなんでもいい)
mkdir <作業用ディレクトリ>
# 2. 移動
cd <作業用ディレクトリ>
# 3. google-cloud-storage を lambda_work 内にインストール
# PythonパッケージをMac上で直接インストールしてしまうと、Arm64向けになってしまうため、x86_64なDockerコンテナ内でインストールしたものをアップロード
docker run --rm -v $(pwd):/work -w /work python:3.11 pip install google-cloud-storage -t .
# 4. lambdaの実行コードを記述したlambda_function.py と GCPからDLしたクレデンシャルの.json を 作業用ディレクトリ直下に配置
# 最終的なプロジェクト構成は以下のようになる。
# <作業用ディレクトリ>/
# lambda_function.py
# <クレデンシャルの.json>
# <pip install google-cloud-storageで生成されたファイル群>
# 5. zipで固める
zip -r ../<任意のファイル名>.zip .
3.1.2. GCP
プロジェクトA
IAM
- サービスアカウント: 任意の名前でサービスアカウント(コピー先のGCSバケットを操作する用)を作成
- Workload Identity: Lambda関数に付与したロールについて、上記のサービスアカウントを貸与する設定(先述の記事を参照)
プロジェクトB, Cそれぞれ
GCS
- バケット: コピー先のバケットについて、プロジェクトAで作成したサービスアカウントが「Storageオブジェクト管理者(上書き可能になる)」として操作できる設定(先述の記事を参照)
4. 本件での学びや工夫したこと
AWS
- Lambda
- トリガー
-
「同一S3バケットかつ同一のイベント通知条件」を複数のLambda関数にトリガーとして設定できない仕様がある。
- 本件は、当初GCPプロジェクトB向け、C向けでLambda関数を分ける(ソースコードが同じで、GCPのプロジェクトIDの環境変数は1つで値を変える)想定だったが、上記の仕様があることがわかった。
- 今回は、同一のLambda関数で直列で処理する形で回避した(特に並列処理させる必要も、処理速度が求められるわけでもなかったため)。
-
「同一S3バケットかつ同一のイベント通知条件」を複数のLambda関数にトリガーとして設定できない仕様がある。
- 同期呼び出しと非同期呼び出し
- トリガーによって分類が異なり、非同期呼び出しの場合は「非同期呼び出し - 再試行」で設定した回数分、関数の実行失敗時に再試行される。
- トリガー
GCP
- GCSバケットに対するサービスアカウントのアクセス権
- バケット個別にアクセス権を設定できるが、IAMでバケットに対するアクセス権を設定した場合、そのGCPプロジェクト配下のバケット全てに適用される。
- ロールが「Storageオブジェクト作成者」だと上書きコピーできないが、「Storageオブジェクト管理者」だとできる。
- Workload Identity
- 外部システムからのGCPの操作にあたっての認証は、サービスアカウントから払い出した秘密鍵を使う方式でも可能だが、この場合は漏洩のリスクがあるし、秘密鍵の有効期間もあるので都度ローテーションしないとダメ。
- Workload Identityではサービスアカウントの秘密鍵が不要。
- あらかじめGCP側で外部システムのIDと特定のサービスアカウントを紐づけつつ、外部システムのアプリケーションからはWorkload Idnetity向けのクレデンシャルを使ってGCPにアクセスさせることで、外部システムのIDをGCPのサービスアカウントになりすまさせることができる。
Python
- 関数でデフォルト引数が利用可能な言語である。慣習的に引数=値(スペース空けずくっつける)と書く。
- 「文字列を扱う際、囲いにダブルクォーテーション(
")かシングルクォーテーション(')どっちを使うの?については、一般的な慣習がない」らしい - S3のクライアント
boto3.client("s3")と GCSのクライアントstorage.Client()- バケット内のオブジェクトのパス指定の違い
- S3ではパスの先頭は
/から。GCSでは先頭は/から始めない(/から始めると/ディレクトリできちゃう)
- S3ではパスの先頭は
- 双方ともにディレクトリごと指定して操作というのができず、再帰的な処理を自分で組む必要があるので結構めんどい(他の言語のライブラリでもそうかもしれないけど)
- バケット内のオブジェクトのパス指定の違い
-
print(f"{変数} hoge huga")って書くと変数を展開しつつ出力できる(これまでprint(変数 + "hoge huga"))ってやってた - GCSのクライアント
storage.Client()について、環境変数GOOGLE_CLOUD_PROJECTでGCPのプロジェクトIDを設定していた場合で、引数に何も与えない場合は、環境変数の値が使われる。storage.Client(project="<プロジェクトID>")とすると、引数で与えたプロジェクトIDが優先して使われる。
5. 参考