注意書き
この記事は、@youwht さんがQiitaに投稿されている平成の次の元号を、AIだけで決めさせる物語をとてもとても(パクリといっていいレベルで)参考にしています。
すごく面白い記事なのでおすすめです。
なお、Wikipediaを元にしたchar2vecモデルの作成法などはそちらを参考にしてください。
背景
新元号は4月1日に公表、5月1日に改元することが正式に発表されている。
でも発表が4月1日ということで嘘の新元号が発表されるのでは???
とネット上ではもっぱらの噂である。
さすがにそれは冗談だとしてもエイプリルフールに乗じて、
嘘(ネタ)の新元号の情報が大量に流れるのはありそうな話ではある。
そんな時に先の記事を見て、
AIだけで元号予想ができるなら、 AIだけで元号かどうかの判別もできるんじゃね?
と思ったのでAIだけで元号判別機を作ってみる。
元号のルール
ルールは以下のようにする。
(おくり名は面倒なので今回はパス)
- 国民の理想としてふさわしいようなよい意味を持つものであること
- 漢字2字であること
- これまでに元号として用いられたものでないこと
- 常用漢字であること
- 俗用されているものでないこと
- M(明治)、T(大正)、S(昭和)、H(平成)とアルファベットのイニシャルが異なること
方針
方針はシンプルに元号のルールで定めたルールに対応したフィルターを作り、
それらのフィルターを全て通過した文字列は元号の可能性があるとする。
逆にフィルターのどこかで引っかかれば、新元号ではないということにしよう。
やっぱり最大の難関は「よい意味の判断」
ルール1. 国民の理想としてふさわしいようなよい意味を持つものであること
よい意味ってなんだよ(哲学)
元記事では
発想として、良い意味の漢字=既に元号で使われたことのある漢字、として、
それに似たベクトルを持つ漢字が、元号の候補となる漢字なのではないか?
としてChar2Vecで過去の元号で使われた漢字とコサイン類似度が一定値以上の漢字を列挙。
その中から組み合わせを探していたが、決め打ちの漢字以外は元号として認めない判別機は判別機にあらず!
ということで別の手を探す。
ここでさっきの発想を1つ進めて、
- 過去の元号もそれ以前の元号で使われたことのある漢字と関連性がある
- 元号の一語目は他の元号の一語目と関連性があり、二語目も同様である
と仮定してみる。
つまり「平成」という漢字は、
一語目の「平」は昭和以前の元号の一語目との
二語目の「成」は昭和以前の元号の二語目との関連性があるのではないか?
そしてこの仮定が正しければ、
全ての元号の一語目・二語目どうしの組み合わせから
元号の一語目・二語目にふさわしい漢字が統計的に絞り込めるはず!
仮説が正しいのか確認するため、
元号の一語目・二語目どうしの組み合わせのコサイン類似度を見る。
(同じ漢字の場合コサイン類似度は 1 なのでそこは省く)
import numpy as np
import matplotlib.pyplot as plt
import random
dimension = 0 # 0 = 一語目のコサイン類似度, 1 = 二語目のコサイン類似度 を測る
distancelist=[]
for idxone in range(0, len(gengo)):
for idxtwo in range(idxone, len(gengo)):
distance = model.similarity(gengo[idxone][dimension], gengo[idxtwo][dimension])
if not (distance == 1.0):
distancelist.append(distance)
# データ数が多くてグラフが潰れたのでサンプルを抽出してグラフ化
sample_distance = random.sample(distancelist, 200)
# 折れ線グラフを出力
left = np.array(range(len(sample_distance)))
height = np.array(sample_distance)
plt.plot(left, height)
一語目の組み合わせのコサイン類似度
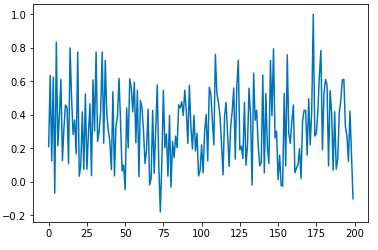
二語目の組み合わせのコサイン類似度
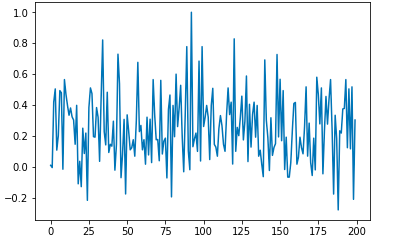
なんとなく、距離感を保っている気がする
仮説としては使えそうなので、これでいく!(他の方法が思いつかない)
実際に統計的に使える値を算出する。
m = np.mean(distancelist)
median = np.median(distancelist)
variance = np.var(distancelist)
stdev = np.std(distancelist)
print('平均: {0:.2f}'.format(m))
print('中央値: {0:.2f}'.format(median))
print('分散: {0:.2f}'.format(variance))
print('標準偏差: {0:.2f}'.format(stdev))
-----1語目の値-----
平均: 0.33
中央値: 0.30
分散: 0.06
標準偏差: 0.23
-----2語目の値-----
平均: 0.26
中央値: 0.24
分散: 0.05
標準偏差: 0.23
平均と中央値が近いのでいい感じに見える。
上の結果の平均と標準偏差を使用して漢字の範囲を絞ることにする。
前準備
import
import numpy as np
import MeCab
from gensim.models.word2vec import Word2Vec
mecab = MeCab.Tagger("-Ochasen")
# 後述の作成したモデル
model = Word2Vec.load('mychar2vec_fromWikiALL.model')
モデル作成
今回の判別に必要なchar2vecモデルを作成する。
学習データはWikipediaのダンプデータ。
先の記事の通りにやればできた。
ひとまず動くか確認。
print(*model.most_similar(positive = u'病', topn=10), sep="\n")
('患', 0.8373429775238037)
('罹', 0.7904560565948486)
('肺', 0.7740147113800049)
('癌', 0.7698979377746582)
('医', 0.7508054375648499)
('臓', 0.7485206723213196)
('胃', 0.7131659388542175)
('腫', 0.7036600112915039)
('瘍', 0.6957879662513733)
('症', 0.6940966844558716)
想像以上にヘビーな結果となったが、ちゃんと機能してそうに見える。
必要なデータを集める
必要なデータは2つ
- 過去の元号(2文字のみ)
- 常用漢字の一覧
使用する際にはPythonのリスト型にしておく。
必要なフィルター群
ルールに対応したフィルター群
前処理フィルター
タブを全角スペースに置換しておく。
# 前処理「\t」はトリムしておく。全角スペース化
def preprocessing(is_era_name):
return is_era_name.replace(u'\t', u' ')
2文字フィルター
ルール2. 漢字2字であることを実装。
2文字以外は弾く。
# 2文字か
def check_2word(is_era_name):
if len(is_era_name) == 2:
return True
else:
return False
常用漢字フィルター
ルール4. 常用漢字であることを実装。
常用漢字のリストをjoyo_kanjiとする。
常用漢字以外なら弾く。
# 常用漢字か
def check_joyo_kanji(is_era_name):
one = is_era_name[:1]
two = is_era_name[1:]
if one in joyo_kanji and two in joyo_kanji:
return True
else:
return False
過去元号フィルター
ルール3. これまでに元号として用いられたものでないことを実装。
過去の元号のリストをgengoとする。
過去の元号なら弾く。
# 過去の元号として使われていないか
def check_kakogengo(is_era_name):
if is_era_name in gengo:
return False
else:
return True
既存品詞フィルター
ルール5. 俗用されているものでないことを実装。
俗用されているもの = 品詞として存在するもの
として元記事にしたがってMeCabの形態素解析を行う。
Mecabによる形態素解析によって、
分かれる = 他の意味は無い。
分かれずに一語と認識 = 他の意味で認識された。
# 品詞として存在しないか
def check_hinsi(is_era_name, mecab):
wordHinsi = []
parsed_line = mecab.parse(is_era_name)
wordsinfo_list = parsed_line.split("\n")
for wordsinfo in wordsinfo_list:
info_list = wordsinfo.split("\t")
if len(info_list) > 2:
wordHinsi.append((info_list[0], info_list[1], info_list[3]))
# 分かれたかを判別
if(len(wordHinsi) == 2):
return True
return False
二語の距離フィルター
ルール1. 国民の理想としてふさわしいようなよい意味を持つものであること で元号の語の組み合わせについて、
元記事の「AIに「元号として適切な組み合わせ」を作らせる」項の仮説
過去元号の距離感に近づく組み合わせにする
がもっともらしいので適用してみる。
つまり、過去の元号たちの二語のコサイン類似度を計算し、
平均と標準偏差から二語の距離の範囲を絞る。
平均と標準偏差は元記事の値の平均: 0.30、標準偏差: 0.24を使う。
# 語と語の距離感が適切か(平均:0.3, 標準偏差:0.24 以内か)
def check_appropriate_distance(is_era_name, model):
distance = model.similarity(is_era_name[:1], is_era_name[1:])
print("適切な語と語の距離感 0.06 <= x <= 0.54")
print("語と語の距離感: {}".format(distance))
if(0.30-0.24 < distance and distance < 0.30+0.24):
return True
else:
return False
語の適正フィルター
ルール1. 国民の理想としてふさわしいようなよい意味を持つものであることを実装。
やっぱり最大の難関は「よい意味の判断」で求めた
一語目の平均: 0.33、二語目の平均: 0.26を中心として、
標準偏差: 0.23の範囲内に一語目・二語目が入っていればOKとする。
# 一語目と二語目がそれぞれ元号として適切な語か(一語目平均:0.33, 二語目平均:0.26, 標準偏差:0.23 以内か)
def check_meaning(is_era_name):
distancelist1=[]
distancelist2=[]
mean1 = 0.33
mean2 = 0.26
std1 = std2 = 0.23
# 一語目と過去の元号一語目との距離感を測る
for i in range(len(gengo)):
distance = model.similarity(is_era_name[:1], gengo[i][0])
if not (distance == 1.0):
distancelist1.append(distance)
# 二語目と過去の元号二語目との距離感を測る
for j in range(len(gengo)):
distance = model.similarity(is_era_name[1:], gengo[j][1])
if not (distance == 1.0):
distancelist2.append(distance)
distance1 = np.mean(distancelist1)
distance2 = np.mean(distancelist2)
print("適切な一語目 {} <= x <= {}, 適切な二語目 {} <= y <= {}".format(mean1-std1, mean1+std1, mean2-std2, mean2+std2))
print("一語目 平均: {}, 二語目 平均: {}".format(distance1, distance2))
if(mean1-std1 < distance1 and distance1 < mean1+std1 and mean2-std2 < distance2 and distance2 < mean2+std2):
return True
else:
return False
MTSHフィルター
実は最大の難関はここだった
MeCabを使って読み仮名を取ろうとしたが、訓読みで判別されたりして、上手くいかなかったので断念。
そこは人力でフィルタリングしてもらおう。
# 音読みなので「ガン・ゲン」で出て欲しい
'元\tモト\t元\t名詞-一般\t\t\nEOS\n'
1つの関数にまとめる
ifの深いネストを使って1つの関数にまとめあげる。
引数には ( 元号っぽい文字列, char2vecのモデル, MeCabのインスタンス ) を指定する。
def judge(is_era_name, model, mecab):
# 前処理
preprocessing(is_era_name)
# 2文字か
if check_2word(is_era_name):
# 過去の元号として使われてないか
if check_kakogengo(is_era_name):
# 常用漢字か
if check_joyo_kanji(is_era_name):
# 既存の品詞でないか
if check_hinsi(is_era_name, mecab):
# 語と語の距離感が適切か
if check_appropriate_distance(is_era_name, model):
# 一語目と二語目がそれぞれ元号として適切な語か
if check_meaning(is_era_name):
print("元号かもしれないです!\n(MTSHの確認は人がしてください)")
return True
else:
print("単語の意味が元号向きではないようです")
else:
print("単語間の距離が適切ではないようです")
else:
print("既存の品詞のようです")
else:
print("常用漢字ではないようです")
else:
print("過去に元号として使用されています")
else:
print("2語ではないようです")
print("元号ではなさそうです")
return False
デモ
ちゃんと動くか試してみる。
元記事でAIが導き出した元号「孝天」で実験。
元記事と評価基準がほぼ変わらないのでちゃんと動けば元号認定されるはず。
# 元記事でAIが導き出した元号
judge("孝天", model, mecab)
-----孝天-----
適切な語と語の距離感 0.06 <= x <= 0.54
語と語の距離感: 0.4474194347858429
適切な一語目 0.1 <= x <= 0.56, 適切な二語目 0.03 <= y <= 0.49
一語目 平均: 0.43369507789611816, 二語目 平均: 0.32817038893699646
元号かもしれないです!
(MTSHの確認は人がしてください)
ちゃんと元号認定された。
ついでに元記事第二候補の「元清」も元号認定されました。
-----元清-----
適切な語と語の距離感 0.06 <= x <= 0.54
語と語の距離感: 0.46765050292015076
適切な一語目 0.1 <= x <= 0.56, 適切な二語目 0.03 <= y <= 0.49
一語目 平均: 0.3887541890144348, 二語目 平均: 0.40423762798309326
元号かもしれないです!
(MTSHの確認は人がしてください)
せっかくなので他にも試してみよう。
- 予想数TOPランカー 「平和」、「安久」
- 鈴木洋仁氏の予想 「感永」
- 相田満氏の予想 「玉英」
- 藤井青銅氏の予想 「永元」
-----平和-----
既存の品詞のようです
元号ではなさそうです
-----安久-----
既存の品詞のようです
元号ではなさそうです
-----感永-----
適切な語と語の距離感 0.06 <= x <= 0.54
語と語の距離感: -0.050712406635284424
単語間の距離が適切ではないようです
元号ではなさそうです
-----玉英-----
既存の品詞のようです
元号ではなさそうです
-----永元-----
適切な語と語の距離感 0.06 <= x <= 0.54
語と語の距離感: 0.6839832067489624
単語間の距離が適切ではないようです
元号ではなさそうです
-----永元-----
適切な語と語の距離感 0.06 <= x <= 0.54
語と語の距離感: 0.6839832067489624
単語間の距離が適切ではないようです
元号ではなさそうです
全てあえなく撃沈。
ちゃんと機能してないのか???
単語間の距離が適切ではないと弾かれてるものが多いが、
過去の元号では距離がマイナスなものもそこそこあるので「感永」は結構いい感じかもしれない。