自己紹介
機械学習エンジニアを目指しており、現在は社内SEをしております。
今回は、自分が大学生時代からやりたかったことを題材にして、学習結果として残そうと思います。Qiita初投稿や機械学習勉強中でもあるため、至らない点があると思いますが、ご容赦ください。また、気づいた点等ございましたら、ご指摘いただければ嬉しいです。
目的
Yahooファイルナスから取得できるFXのデータを用いて、デイトレードの予測をしたい。
環境
言語:Python(Google Colaboratory)
予測データ:USD/JPY(Yahooファイナンス)
使用モデル等
モデル:RNN(再帰型ニューラルネットワーク), LSTM(長・短期記憶)
損失・評価関数:mse(平均二乗誤差), rmse(平均二乗平方根誤差)
データ:高値, 安値
目次
- はじめに
- 必要なライブラリを取得
- Yahooファイナンスから取得したデータを保存
- 取得したデータを表示
- 訓練データと検証データの作成
- モデルの作成~結果の出力
- 考察
- 反省と課題
- 感想
- 参考
1. はじめに
今回は、終値ではなく高値と安値について各モデルの予測を行う。また、高値と安値を予測する理由は、デイトレードを行うときに終値よりもどれだけボラティリティが大きいのかを知るほうが賢明ではないかと考えたからです。
2. 必要なライブラリを取得
Yahooファイナンスからデータを取得する際に必要なライブラリをインストールする。
!pip install yfinance
3. Yahooファイナンスから取得したデータを保存
import pandas_datareader.data as pdr
import datetime
import yfinance as yf
# 今日の日付を取得
today = datetime.date.today()
# 5年間分のデータを取得するための設定
start = today - (datetime.timedelta(days=365) * 5)
end = today
# yahoo financeでのシンボルを設定
ticker = 'JPY=X'
# データ取得をdatareaderからyfinanceに変更する
yf.pdr_override()
# データフレーム形式で[USDJPY]のデータ取得
df = pdr.get_data_yahoo(ticker, start, end)
# データをcsvファイルに保存
df.to_csv('USDJPY.csv')
pandas_datareaderから直接、データを取得できなかったため、yfinanceのライブラリを使うことで自動でダウンロード可能になった。
4. 取得したデータを表示
約5年間のデータの推移を表とグラフで確認。
import pathlib
import pandas as pd
import matplotlib.pyplot as plt
# 保存データの読み込み
csv_file = pathlib.Path('/content/USDJPY.csv')
csv_data = pd.read_csv(csv_file)
# データを表示
display(csv_data)
# グラフを表示
interval = list(range(0, len(csv_data), 100))
plt.figure(figsize=(10, 7))
plt.plot(csv_data['Close'])
plt.title('USD / JPY - 5 years data')
plt.xticks(interval, csv_data.loc[interval, 'Date'], rotation=70)
plt.grid()
plt.show()
5. 訓練データと検証データの作成
高値と安値で分け、それぞれの過去10日間を特徴量としてデータを作成。
# 訓練データサイズ
train_size = int(len(csv_data) * 0.8)
# 特徴量追加
High_df, Low_df = csv_data[['High']], csv_data[['Low']]
for i in range(1, 11):
High_df['High' + str(i)] = High_df['High'].shift(i)
Low_df['Low' + str(i)] = Low_df['Low'].shift(i)
# 入力値作成
High_input = High_df.iloc[-10:, :10]
Low_input = Low_df.iloc[-10:, :10]
High_df = High_df.dropna().reset_index(drop=True)
Low_df = Low_df.dropna().reset_index(drop=True)
# 訓練データと検証データを作成
HighX_train, LowX_train = High_df.iloc[:train_size, :], Low_df.iloc[:train_size, :]
HighX_test, LowX_test = High_df.iloc[train_size:, :].reset_index(drop=True), Low_df.iloc[train_size:, :].reset_index(drop=True)
HighY_train, LowY_train = HighX_train['High'], LowX_train['Low']
HighY_test, LowY_test = HighX_test['High'], LowX_test['Low']
HighX_train.drop('High', axis=1, inplace=True)
LowX_train.drop('Low', axis=1, inplace=True)
HighX_test.drop('High', axis=1, inplace=True)
LowX_test.drop('Low', axis=1, inplace=True)
6. モデルの作成~結果の出力
ここでは、全結合・RNN・LSTMの各モデルを作成し、それぞれの結果をRMSEで1年間分出力し、グラフで計10日間(内訳:過去9日+未来1日)の予測を表示している。ここでは、力量不足もあり複雑なモデルは作成できませんでした...。
また、以下2つの出力(RMSEとグラフ)に関しては、どのモデルが一番正解に近い結果を出し(RMSEの結果)、どのくらいのボラティリティが出そうか(グラフの結果)を取引する際の指標にできればと思って出力しております。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN, LSTM
from tensorflow.keras.optimizers import Adam
from tensorflow.random import set_seed
from sklearn.metrics import mean_squared_error
import numpy as np
from datetime import date, timedelta
# 乱数を固定
#set_seed(0)
# ディープラーニングのモデルを3つ用意
class DL_models:
def __init__(self, train, label, features, n_mid, activation, loss, optimizer, epochs, verbose=0):
self.train = train
self.label = label
self.features = features
self.n_mid = n_mid
self.activation = activation
self.loss = loss
self.optimizer = optimizer
self.epochs = epochs
self.verbose = verbose
self.validation_split = 0.2
def SimpleModel(self):
model = Sequential()
model.add(Dense(self.n_mid, activation=self.activation, input_shape=(self.features,)))
model.add(Dense(1))
model.compile(loss=self.loss, optimizer=self.optimizer)
model.fit(self.train, self.label, epochs=self.epochs, verbose=self.verbose, validation_split=self.validation_split)
return model
def RnnModel(self):
model = Sequential()
model.add(SimpleRNN(self.n_mid, activation=self.activation, input_shape=(self.features, 1)))
model.add(Dense(1))
model.compile(loss=self.loss, optimizer=self.optimizer)
model.fit(self.train, self.label, epochs=self.epochs, verbose=self.verbose, validation_split=self.validation_split)
return model
def LstmModel(self):
model = Sequential()
model.add(LSTM(self.n_mid, activation=self.activation, input_shape=(self.features, 1)))
model.add(Dense(1))
model.compile(loss=self.loss, optimizer=self.optimizer)
model.fit(self.train, self.label, epochs=self.epochs, verbose=self.verbose, validation_split=self.validation_split)
return model
# 高値のモデル
High_model = DL_models(HighX_train, HighY_train, len(HighX_train.columns), 32, 'relu', 'mse', Adam(lr=0.001), 50, 0)
High_models = [High_model.SimpleModel(), High_model.RnnModel(), High_model.LstmModel()]
# 安値のモデル
Low_model = DL_models(LowX_train, LowY_train, len(LowX_train.columns), 32, 'relu', 'mse', Adam(lr=0.001), 50, 0)
Low_models = [Low_model.SimpleModel(), Low_model.RnnModel(), Low_model.LstmModel()]
# 各モデルの予測
HighYear_preds = []
LowYear_preds = []
HighWeek_preds = []
LowWeek_preds = []
for Hmodel, Lmodel in zip(High_models, Low_models):
HighYear_preds.append(Hmodel.predict(HighX_test))
LowYear_preds.append(Lmodel.predict(LowX_test))
HighWeek_preds.append(Hmodel.predict(High_input))
LowWeek_preds.append(Lmodel.predict(Low_input))
# 予測結果をRMSEで出力
models_name = ['SimpleModel', 'RnnModel', 'LstmModel']
print('RMSE予測結果')
for n, h, l in zip(models_name, HighYear_preds, LowYear_preds):
print(n)
print('High:', np.sqrt(mean_squared_error(HighY_test, h)), 'Low:', np.sqrt(mean_squared_error(LowY_test, l)))
# 10日間の値動きの予測をモデル毎にプロット
fig = plt.figure(figsize=(15, 10))
ax1 = fig.add_subplot(3, 1, 1)
ax2 = fig.add_subplot(3, 1, 2)
ax3 = fig.add_subplot(3, 1, 3)
x_date = [csv_data.iloc[-9, 0]]
next_day = date.today() + timedelta(1)
if next_day.weekday() == 5:
next_day = next_day + timedelta(2)
elif next_day.weekday() == 6:
next_day = next_day + timedelta(1)
x_date.append(str(next_day))
ax1.plot(HighWeek_preds[0], label='High', color='b')
ax1.plot(LowWeek_preds[0], label='Low', color='r')
ax2.plot(HighWeek_preds[1], label='High', color='b')
ax2.plot(LowWeek_preds[1], label='Low', color='r')
ax3.plot(HighWeek_preds[2], label='High', color='b')
ax3.plot(LowWeek_preds[2], label='Low', color='r')
ax1.set_xticks([0, 9])
ax1.set_xticklabels(x_date)
ax2.set_xticks([0, 9])
ax2.set_xticklabels(x_date)
ax3.set_xticks([0, 9])
ax3.set_xticklabels(x_date)
ax1.set_title('SimpleModel')
ax2.set_title('RnnModel')
ax3.set_title('LstmModel')
ax1.grid()
ax2.grid()
ax3.grid()
ax1.legend()
ax2.legend()
ax3.legend()
plt.show()
約1年間のRMSE結果は、以下のように出ました。0に近ければ近いほど高精度です。
RMSE予測結果
SimpleModel
High: 0.792593037872089 Low: 1.3613739653671932
RnnModel
High: 1.7324559776637019 Low: 1.777714472195145
LstmModel
High: 0.8112607077685047 Low: 1.0672531407420633
10日間(内訳:過去9日+未来1日)の予測推移は、以下のように出ました。
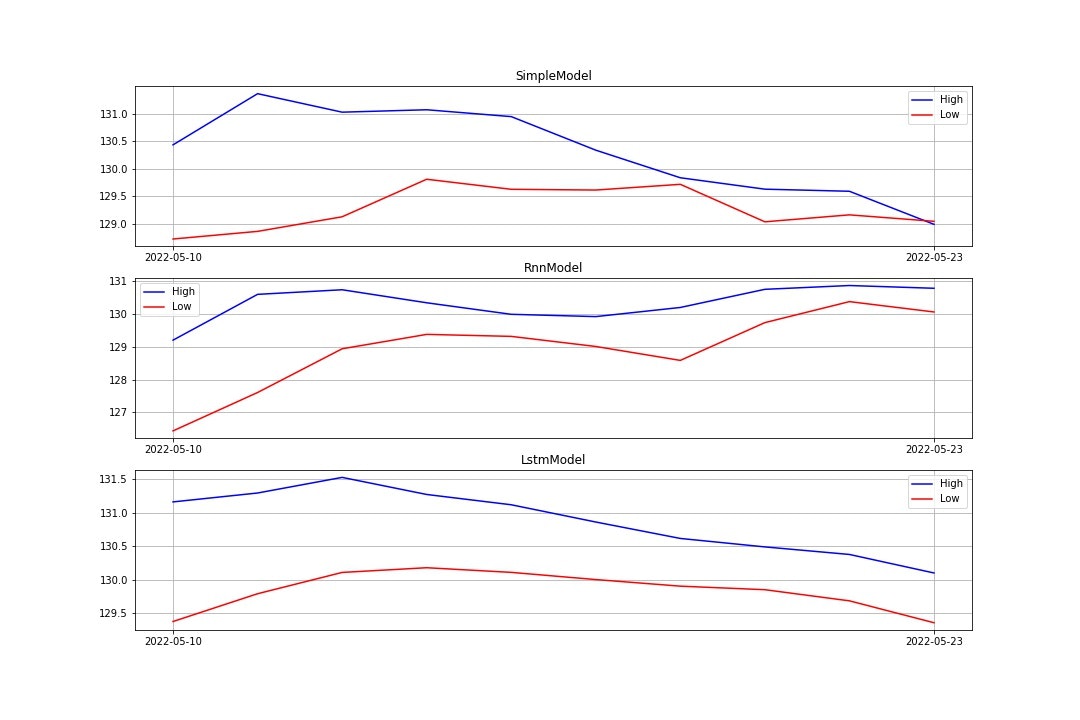
7. 考察
今回の予測は、約5年間の相場のデータをもとに学習させました。
RMSEの予測結果は精度が高いとあまり言えないものになった。これは、パラメータ設定が上手く合致していなかったのかもしれない。学習回数は30~40程度で損失関数が収束したために、中間層の追加や活性化関数、学習率のパラメータ等を再設定すればRMSEはより小さくなるかもしれない。
グラフでは、HighとLowの値が交差するような普通の相場ではありえない事象が起きている。これは、HighとLowで別々の出力をしているために予測上、価格の逆転が起きてしまったと考えられる。そのため、HighとLowを2つの正解、出力として設定すればそのようなことは起きなくなるかもしれない。また、デイトレードをする際に終値よりも高値と安値を予測するほうが取引をする点では合理的な気がするため、間違った選択はしていないと思う。
8. 反省と課題
反省としてはFXの勉強を長い間していなかったのもあり、上手く訓練(検証)データについて深く考察できなかった。そのため、単純な特徴量となってしまった。また、RNNやLSTMについて表面的な使い方しか知らなかったためにより単純なモデルになってしまった。
課題として、今回のデータは相場の値動きのみに着目したので、テクニカル分析やファンダメンタル分析も取り入れて、よりよい精度に近づけていきたい。
9. 感想
今回、このような課題に取り組みましたが、とても疲れました。何本もQiita等に記事を挙げている人には頭が上がりません。しかし、この課題は自分にとっても大きな前進になったので、これからの学習の励みになると思います。お付き合いいただきありがとうございました。