証券情報の取得にはGOOGLEFINANCE関数が便利ですが、残念ながら配当利回りは取得できないようです。
そこで https://finviz.com/ にある配当利回りの情報をGoogleスプレッドシートにインポートして表示することにします。
画像はアップル社の証券情報です。
一番右に配当利回りを表示しています。

IMPORTHTML関数
Webサイト上のデータをインポートするためにIMPORTHTML関数を使用します。
構文
IMPORTHTML(URL, クエリ, 指数)
第一引数 - URL
- URL - 検証するページの URL です。プロトコル(http:// など)も含めます。
- URL の値は二重引用符で囲むか、適切なテキストを含むセルへの参照にする必要があります。
今回はアップル社の証券情報が欲しいので第一引数は以下になります。
"https://finviz.com/quote.ashx?t=AAPL"
第二引数 - クエリ
- クエリ - 目的のデータを含むアイテムの種類を "list"(リスト)か "table"(表)で指定します。
目的のデータは以下の表です。
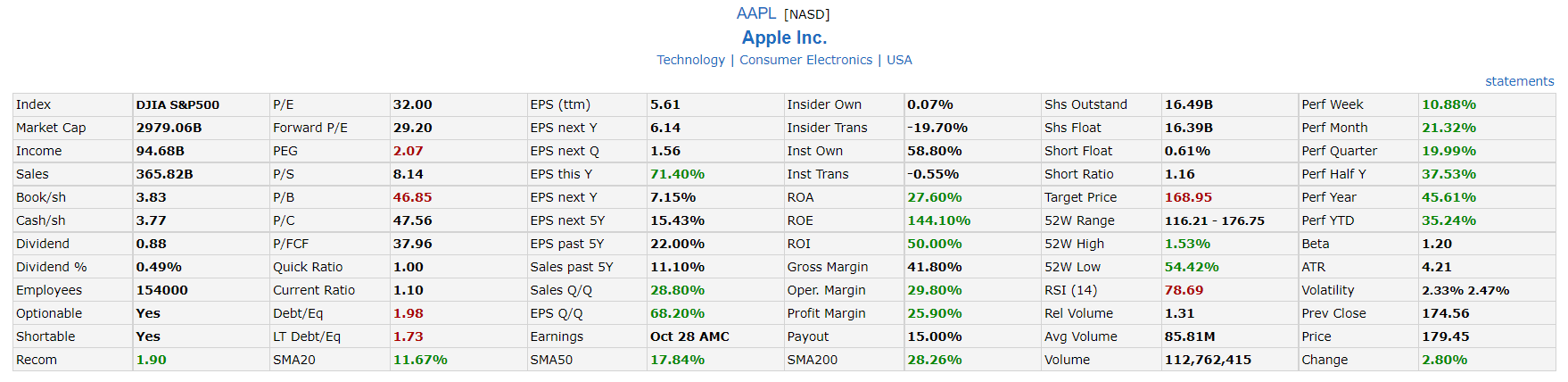
Webページのソースを見ると、目的のデータはtableタグで書かれています。
<table width="100%" cellpadding="3" cellspacing="0" border="0" class="snapshot-table2">
Webページのソースの確認方法
- Webページ上の何もない場所を右クリック(リンク、画像、フォーム等がない場所)
- 「ページのソースを表示」を選択
htmlファイルを見慣れていない場合、目的のデータの特定が少し難しいかもしれませんが、頑張ります。
第二引数には "table" を指定します。
第三引数 - 指数
- 指数 - 対象の表またはリストについて、HTML ソース内で定義されている番号で 1 から順に指定します。
- リストと表の番号は個別に管理されるため、HTML ページに両種類の要素が含まれている場合は番号 1 を持つリストと表が両方存在する場合があります。
Webページのソースを確認し、目的のデータが何番目のtableなのかを確認します。
# 1番目(62行目)
<table class="header" width="100%" cellpadding="0" cellspacing="0" border="0" style="min-width: 1000px">
# 2番目(68行目)
<table width="100%" cellpadding="0" cellspacing="0" border="0">
# 3番目(98行目)
<table class="navbar" width="100%" height="30" cellpadding="0" cellspacing="0" border="0">
# 4番目(213行目) ※tableタグは後ろの方にある
</script></div><div class="content" data-testid="quote-data-content"><div class="fv-container"><table width="100%"><tr>
# 5番目(215行目)
<table width="100%" cellpadding="3" cellspacing="0" bgcolor="#ffffff" class="fullview-title">
# 6番目(220行目)
<table width="100%" cellpding="0" cellspacing="0" class="fullview-links">
# 7番目(230行目) ※これが目的のデータ
<table width="100%" cellpadding="3" cellspacing="0" border="0" class="snapshot-table2">
※インデントは省略しています。
目的のデータは8番目のtableであることが分かりました。
第三引数は 8 です。
※2022/1/9更新
Webページのソースが更新され、目的のデータは7番目のtableになりました。
第三引数は 7 になります。
証券情報をインポートする
IMPORTHTML関数の引数が確認できたので実際に目的のデータをインポートしてみます。
=IMPORTHTML("https://finviz.com/quote.ashx?t=AAPL","table",7)
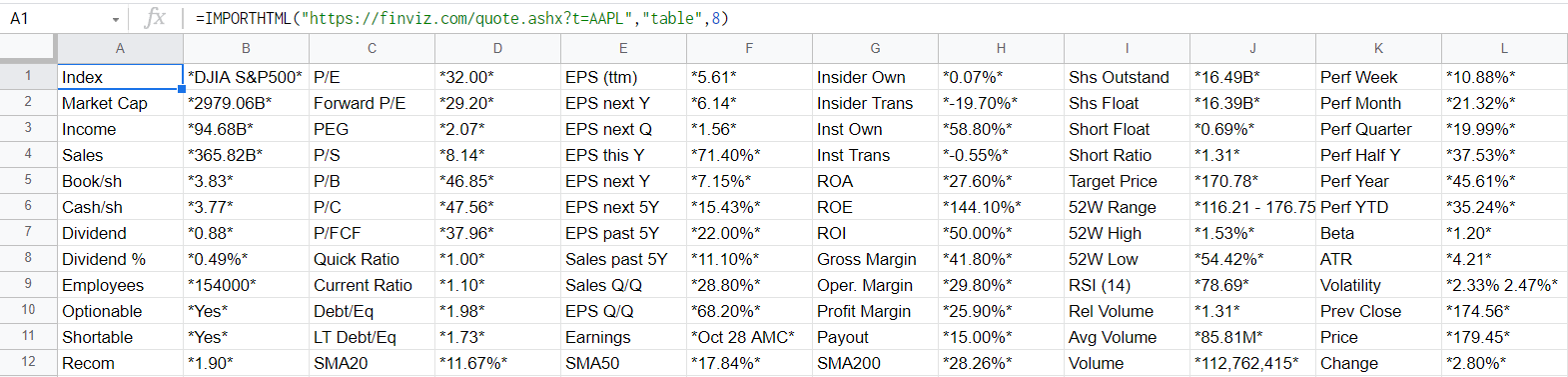
インポート成功です。
INDEX関数
インポートしたデータの中から目的の値(配当利回り)を取得するためにINDEX関数を使用します。
構文
INDEX(参照, [行], [列])
第一引数 - 参照
参照するのはインポートしたデータです。
上記のIMPORTHTML関数をそのまま指定します。
IMPORTHTML("https://finviz.com/quote.ashx?t=AAPL","table",7)
第二引数 - [行] / 第三引数 - [列]
配当利回りはインポートしたデータの "Dividend %" の値です。
8行目、2列目にあるので、第二、第三引数は 8,2 になります。
配当利回りを取得する
INDEX関数の引数も確認できたので配当利回りを取得してみます。
=INDEX(IMPORTHTML("https://finviz.com/quote.ashx?t=AAPL","table",7),8,2)

配当利回りを取得できました。
SUBSTITUTE関数
取得した配当利回りの値の前後に「*」があるので削除します。
構文
SUBSTITUTE(検索対象のテキスト, 検索文字列, 置換文字列, [出現回数])
検索対象のテキスト
検索対象のテキストは取得した配当利回りです。
上記のINDEX関数をそのまま指定します。
INDEX(IMPORTHTML("https://finviz.com/quote.ashx?t=AAPL","table",7),8,2)
検索文字列
削除したい「*」が検索文字列になります。
"*"を指定します。
置換文字列
「*」を削除したいので置換文字列は空白になります。
""を指定します。
配当利回りの前後の「*」を削除する
SUBSTITUTE関数の引数も確認できたので配当利回りの前後の「*」を削除してみます。
=SUBSTITUTE(INDEX(IMPORTHTML("https://finviz.com/quote.ashx?t=AAPL","table",7),8,2),"*","")

配当利回りの前後の「*」が削除されました。
これで配当利回りを取得することができました。
関連記事
参考サイト
以上、最後まで読んでいただき、ありがとうございました。