はじめに
Database Critical events for DB systemsという機能が先日リリースされました。
The Events service now provides "critical" events for DB systems, and database nodes and databases located in DB systems. Critical events deliver information about several types of critical conditions and errors in Oracle Database software and related infrastructure. For example, there are critical events for database hang errors, and availability errors for databases, database nodes, and DB systems to let you know if a resource becomes unavailable. See the Database section section of the Events documentation for datails.
データベースやノードのハング・可用性エラーなどのクリティカルなイベントを拾って通知やファンクションなどを実行できるようになります。今回、この機能をお試ししてみました。
検証した環境
検証した環境は、DBCSのシングル(Enterprise Edition)構成です。DBは19cを選択しました。
Database Critical Eventsの有効化
マニュアルによると、前提条件としてAHF telemetoryなるものを有効化しておく必要があるそうです。
This event type is emitted by Oracle Databases running on Exadata Cloud Service instances, bare metal DB systems, and virtual machine DB systems. To receive database critical events for databases in bare metal or virtual machine DB systems, you must enable telemetry for the system using the dbcli ulitilty. See AHF Telemetry Commands for details on enabling telemetry for bare metal and virtual machine DB systems
DBCSのデプロイ完了後、OSにログインして、マニュアルに従って、AHF telemetoryを有効化します
$ sudo -i
### dbcliをアップデート
# cliadm update-dbcli
### DEVMODE環境変数を設定します。
# export DEVMODE=true
### AHF telemetryを起動します
# dbcli manage-ahftelemetry -a start
### ジョブの状態を確認し、SUCCESSになることを確認します
# dbcli list-jobs
ID Description Created Status
---------------------------------------- --------------------------------------------------------------------------- ----------------------------------- ----------
…
1926403a-9c94-4aaf-bc20-58ea558e67a3 Manage AHF telemetry Tuesday, June 22, 2021, 14:33:45 JST Success ★
### DEVMODE環境変数をもとに戻します。
# export DEVMODE=
/u01/app/oracle.ahf/data/dbcs01/diag/telemetry_adapter/ディレクトリ下にある、telemetry_adapter_client.logを見ていると、以下のように初期化されたようなログが出力されていました。
# tail -F /u01/app/oracle.ahf/data/dbcs01/diag/telemetry_adapter/telemetry_adapter_client.log
…
2021-06-22 13:03:25,859 multiprocessing INFO MainProcess [common_util.py:133 - _clsinit() ] Initialising common utilities...
2021-06-22 13:03:25,946 multiprocessing INFO MainProcess [common_util.py:179 - is_dev_mode() ] Adapter is in mode : PROD
2021-06-22 13:03:26,047 multiprocessing INFO MainProcess [common_util.py:251 - load_otto_endpoint_details() ] Otto Endpoint Details : {'ottoFnId': 'ocid1.fnfunc.oc1.ap-tokyo-1.xxxxxxxxxxxxxxxxxxxxxxxxx', 'imageVersion': 'nrt.ocir.io/atpadwdproduction/otto/odo/postcefevents:1.0.8.release.112', 'ottoFnInvokeURL': 'https://4k4tge5wzxq.ap-tokyo-1.functions.oci.oraclecloud.com/20181201/functions/ocid1.fnfunc.oc1.ap-tokyo-1
AHF telemetoryを起動すると、↓のpythonプロセスが起動するようです。これが実体?
# ps -ef |grep telemetry |grep -v grep
root 87713 1 1 14:34 ? 00:00:04 /u01/app/oracle.ahf/python/bin/python3 /u01/app/oracle.ahf/common/telemetry_adapter/oracle/telemetry_adapter_client.py
※試しに、上記のプロセスをkillしてみましたが、どうやらtfaが状態監視していて再起動してくれるようです。
通知の設定
つづいて、AHF Telemetryによって発報されたイベントを拾うため、「通知」を構成します。
ここでは、通知方法としてメールを選択しています。
-
[メニュー]⇒[開発者サービス]⇒[通知]を選択します

-
「トピックの作成」を押下します
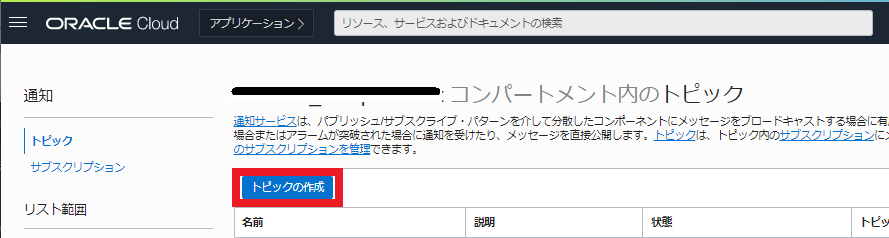
-
「名前」と「説明」を入力してトピックを作成します
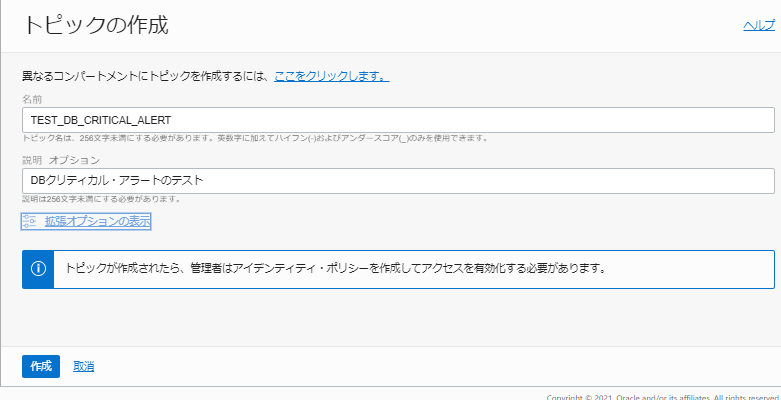
-
作成したトピックのリンクを押下します

-
「サブスクリプションの作成」ボタンを押下します
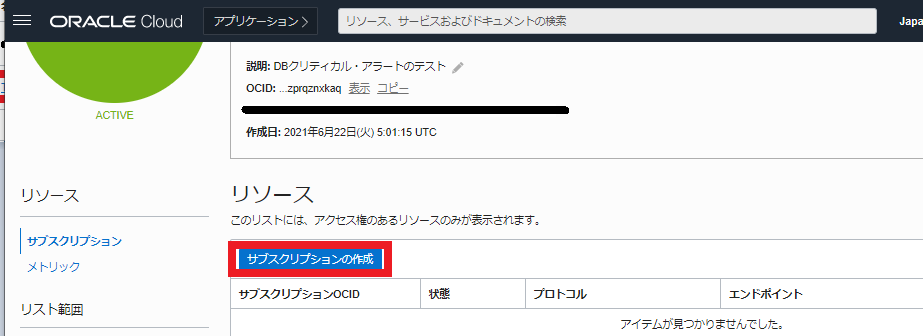
-
「プロトコル」に"電子メール"を選択し、通知先のメールアドレスを入力します

-
作成直後は、Pending状態です。メールアドレスをConfirmする必要があります

-
登録したアドレス宛にメールが届くので、リンクを押下してConfirmします。

※上記の画像は、メールの文面です。 -
リンクを押下すると、以下のようなページに遷移して承認が完了します

-
サブスクリプションの状態がActiveに代わることを確認します
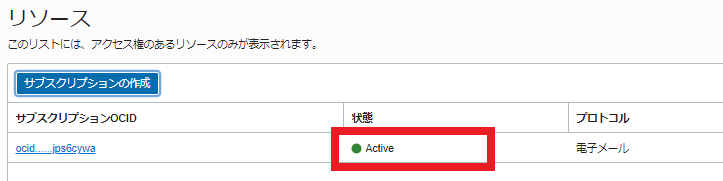
イベントの設定
イベント・ルールを作成して、特定のイベント発動時に、上記で作成した「通知」と連携するように設定します。
-
[メニュー]⇒[監視および管理]⇒[イベント・サービス]を選択します

-
「ルールの作成」ボタンを押下します
-
以下のように入力します。
-
「説明」を記入
-
「条件」に"イベント・タイプ"を選択し、「サービス名」に"Database"を選択、「イベント・タイプ」に、"Database - Critical"を選択
-
「アクション・タイプ」に"通知"を選択し、「通知コンパートメント」に、トピックを作成したコンパートメントを選択、「トピック」に上記で作成したトピック名を選択します。
※なお、イベント・タイプには他にも"DB Node - Critical"と"DB System - Critical"がありますが、ここでは試していません。

- イベント・ルールが正常に作成されることを確認します

通知のテスト
ここまでで設定が完了したので、クリティカル・イベントを発生させて通知できるか確かめてみます。
ここでは、pmonプロセスをSIGSEGVでkillして、ORA-7445を発生させてみました。
# pkill -11 ora_pmon
アラートログをtailで見ていると、以下のようにORA-7445が出力されます
# tail -F /u01/app/oracle/diag/rdbms/*/*/trace/alert_*.log
2021-06-22T14:46:35.873244+09:00
Exception [type: SIGSEGV, unknown code] [ADDR:0x17ED] [PC:0x7F75047EF28A, semtimedop()+10] [exception issued by pid: 6125, uid: 0] [flags: 0x0, count: 1]
Errors in file /u01/app/oracle/diag/rdbms/xxxxxx/xxxxxx/trace/xxxxxx_pmon_1261.trc (incident=14417) (PDBNAME=CDB$ROOT):
ORA-07445: exception encountered: core dump [semtimedop()+10] [SIGSEGV] [ADDR:0x17ED] [PC:0x7F75047EF28A] [unknown code] []
Incident details in: /u01/app/oracle/diag/rdbms/xxxxxx/xxxxxx/incident/incdir_14417/xxxxxx_pmon_1261_i14417.trc
Use ADRCI or Support Workbench to package the incident.
また、以下のログをtailしていると、ある程度イベントの通知状況がわかりそうです。
# tail -F /u01/app/oracle.ahf/data/*/diag/telemetry_adapter/telemetry_adapter_client.log
2021-06-22 14:47:35,244 multiprocessing INFO MainProcess [telemetry_adapter_monitor.py:70 - process_file() ] Detected event : tfa_telemetry_1624340854998.json
2021-06-22 14:47:35,346 multiprocessing INFO MainProcess [tfa_telemetry_json_handler.py:1296 - send_telemetry_data() ] Sending notification events...
2021-06-22 14:47:35,356 multiprocessing INFO MainProcess [otto_util.py:329 - send_signals_to_endpoint() ] Not refreshing otto endpoint details yet
2021-06-22 14:48:16,398 multiprocessing INFO MainProcess [otto_util.py:340 - send_signals_to_endpoint() ] [SAN] JSON Data : {"events":・・・・
2021-06-22 14:48:16,485 multiprocessing INFO MainProcess [otto_util.py:349 - send_signals_to_endpoint() ] Events sent...
2021-06-22 14:48:16,487 multiprocessing INFO MainProcess [custom_decorators.py:41 - wrapper() ] Time taken by process_tfa_json is 41.23664927482605 sec.
無事、メールが通知されました。pmonをSIGSEGVでkillした場合、インスタンスも再起動されるため、以下の3通のメールが通知されました。
・インスタンス・ダウン
・ORA-7445の発生
・インスタンス・起動
- 下の画像は、実際に通知されたメールの本文です

おまけ
他のORA-エラーはどうなの?と思い、v$DIAG_CRITICAL_ERRORに定義されているORA-エラーをアラートログに出力させて試してみました。
結果、実際に通知されたのはORA-32701・ORA-07445・ORA-00600でした。
なお、実際にエラーを発生させたわけではなく、dbms_system.ksdwrtを使用して疑似的にアラートログに書き込んだけですので、実際にエラーが発生した場合の挙動とは異なるかもしれません。
※任意のORA-エラーをアラート・ログに書き込みたい場合、以前のバージョンだとpragma exception_initだけでアラートログにも出力してくれた気がするのですが、19c/CDBの環境では出力してくれませんでした。挙動がかわったかな。。
下の表中、x(※)になっている項目は、通知はされなかったものの、telemetry_adapter_client.logを見ているとeventNameが"ERRORS.DB.GENERAL"となっているイベントとして発報していそうな項目です。将来的には通知できるようになるのかもしれません。現状は、Database Critical Eventsとしてはカテゴライズされてなさそうです。
| 通知 | メッセージ | 備考 |
|---|---|---|
| × | ORA-15335: ASM metadata corruption detected in disk group '' | |
| ×(※) | ORA-01578: ORACLE data block corrupted (file # , block # ) | |
| ×(※) | ORA-00227: corrupt block detected in control file: (block , # blocks ) | |
| ×(※) | ORA-00239: timeout waiting for control file enqueue: held by ' for more than seconds | |
| ×(※) | ORA-00240: control file enqueue held for more than seconds | |
| ×(※) | ORA-24982: deferred SGA segment allocation failed, index = location = | |
| ×(※) | ORA-25319: Queue table repartitioning aborted | |
| ×(※) | ORA-00255: error archiving log of thread , sequence # | |
| ×(※) | ORA-29740: evicted by instance number , group incarnation | |
| ×(※) | ORA-29770: global enqueue process (OSID ) is hung for more than seconds | |
| ×(※) | ORA-29771: process (OSID ) blocks (OSID ) for more than seconds | |
| ×(※) | ORA-03137: malformed TTC packet from client rejected: [] [] [] [] [] [] [] [] | |
| 〇 | ORA-32701: Possible hangs up to hang ID= detected | eventName: ERRORS.DB.HANGで通知 |
| ×(※) | ORA-32703: deadlock detected: | |
| ×(※) | ORA-32704: Oracle RAC deadlock detected: | |
| ×(※) | ORA-00353: log corruption near block change time | |
| ×(※) | ORA-00355: change numbers out of order | |
| ×(※) | ORA-00356: inconsistent lengths in change description | |
| ×(※) | ORA-04030: out of process memory when trying to allocate bytes (,) | |
| ×(※) | ORA-04031: unable to allocate bytes of shared memory ("","","","") | |
| ×(※) | ORA-04036: PGA memory used by the instance exceeds PGA_AGGREGATE_LIMIT | |
| ×(※) | ORA-00445: background process "" did not start after seconds | |
| ×(※) | ORA-00494: enqueue held for too long (more than seconds) by inst , osid | |
| × | ORA-05031: PDB SGA usage has exceeded the limit | |
| ×(※) | ORA-56729: Failed to bind the database instance to processor group | |
| × | ORA-00625: Internal error code within PDB: [], [], [], [], [], [], [], [], [], [], [], [] | |
| × | ORA-06544: PL/SQL: internal error, arguments: [], [interpreter cannot interpret pcode], [], [], [], [], [], [] | |
| 〇 | ORA-07445: exception encountered: core dump [] [] [] [] [] [] | eventName: ERRORS.DB.ORA7445で通知 |
| × | ORA-00800: soft external error, arguments: [], [], [], [], [] | |
| 〇 | ORA-00600: internal error code, arguments: [600], [], [], [], [], [], [], [], [], [], [], [] | eventName: ERRORS.DB.ORA600で通知 |
| (※) ERRORS.DB.GENERALとしてイベントは発報している |
*** 2021/6/22時点の結果です ***