本記事の目的
業務でAWSを触る方にとってCloudWatchに対してなんとなく苦手意識をもっている人は多いのではないでしょうか。特に私のようなDevOps/SRE領域を開発業務の片手間で担っている人たちにとって監視領域は後回しにしがちです。
今回の記事では、このCloudWatch、そして本サービスの軸となるCloudWatch Metrics,CloudWatch logsを自分自身の学習の備忘録がてらハンズオン形式で学べる記事を書いてみました。
対象となる読者は以下を想定します。
対象読者
- AWSを業務で使い始めた&使いたい人
- DevOps/SRE担当で
CloudWatchを使った監視業務を求められてしまった人 -
CloudWatch logs,CloudWatch Metricsを実際に手を動かして確認したい人
なお利用するサンプルAPIは全てGoで書かれていますが、コード箇所は読み飛ばして頂いても構いません。
参考資料に関して
本記事では、以下の"AWS BlackBelt 2023 Amazon CloudWatchの概要と基本"をメインに参考しております。本記事で紹介しているスライドは同資料から引用・抜粋しているものになります。
CloudWatch 概要編

Amazon CloudWatchは、AWSサービスおよびアプリケーションを監視するためのツールです。リアルタイムでダッシュボードを通じてパフォーマンスデータを表示し、ログを分析する機能があります。さらに、アラームを設定して通知を受け取り、問題が発生した場合に自動的に対応することができます。CloudWatchは、システム全体の運用を効率的かつ効果的に管理するために重要な役割を果たします。
"オブザーバビリティ"とは

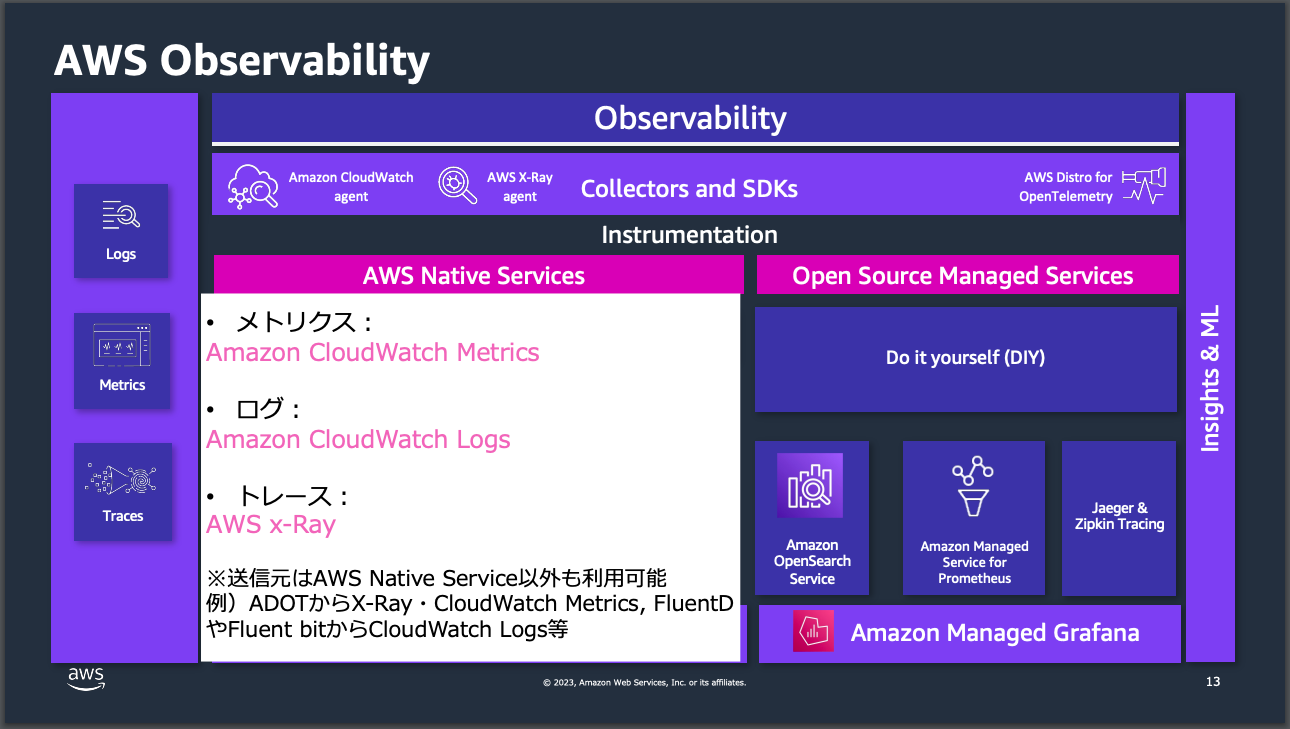
AWSの最新のBlack Beltが非常にわかりやすいので引用しました。この画像にあることが全てです。オブザーバビリティとは、抽象的な概念ではありますが、これまでのモニタリングを内包するものであり、ざっくり以下のようなものだと個人的に理解してます。
- システム全体の状態をより深く把握できる状態
- かつ変化・成長するシステムに対応すべくオブザーバビリティ強化を継続的に行える状態
- 上記を実現することで運用上の優秀性・ビジネス目標を達成できる
このオブザーバビリティを高めるための手段としてCloudWatchは中心的な役割を担っています。
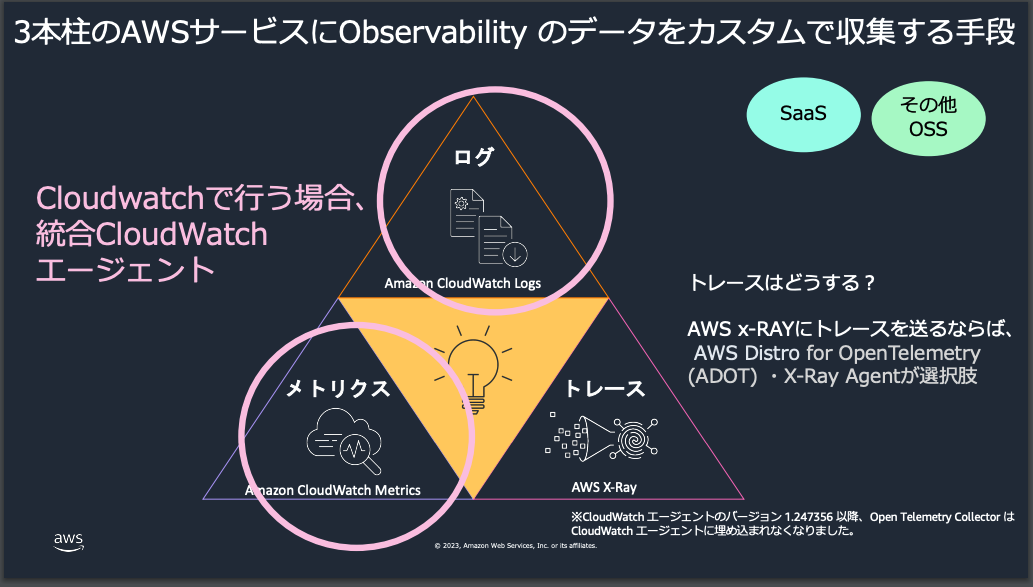
3つの柱
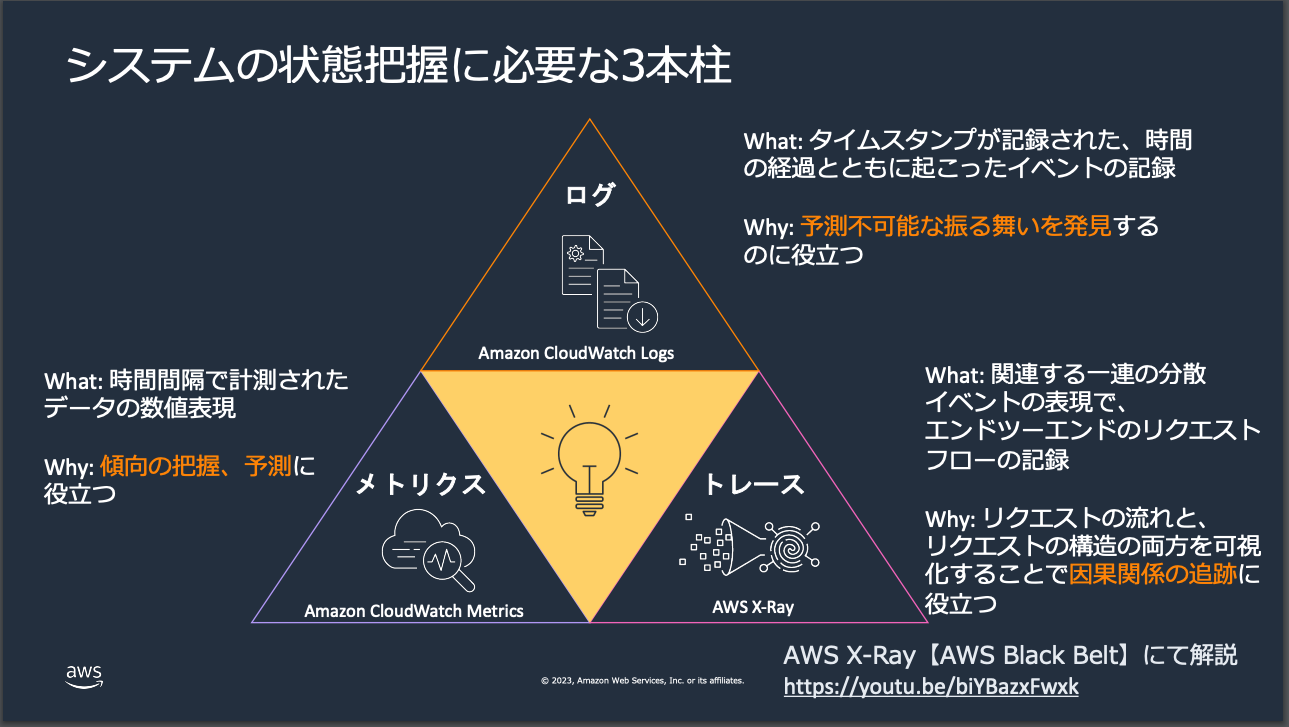
CloudWatchの理解しづらさの所以はそのサービス数の多さです。マネージメントコンソールから確認するだけでも合計で20近い機能がリリースされています。
一方で、この中でも上記オブザーバビリティを実現する上で中心となっているのが以下の画像の通り、ログ, メトリクス, トレースになります。
※上記に加えてEvent Bridge(旧CloudWatch Event)が担うイベントも中心的な役割を担いますが、本記事では説明は割愛します。
監視・運用の基本的な流れ
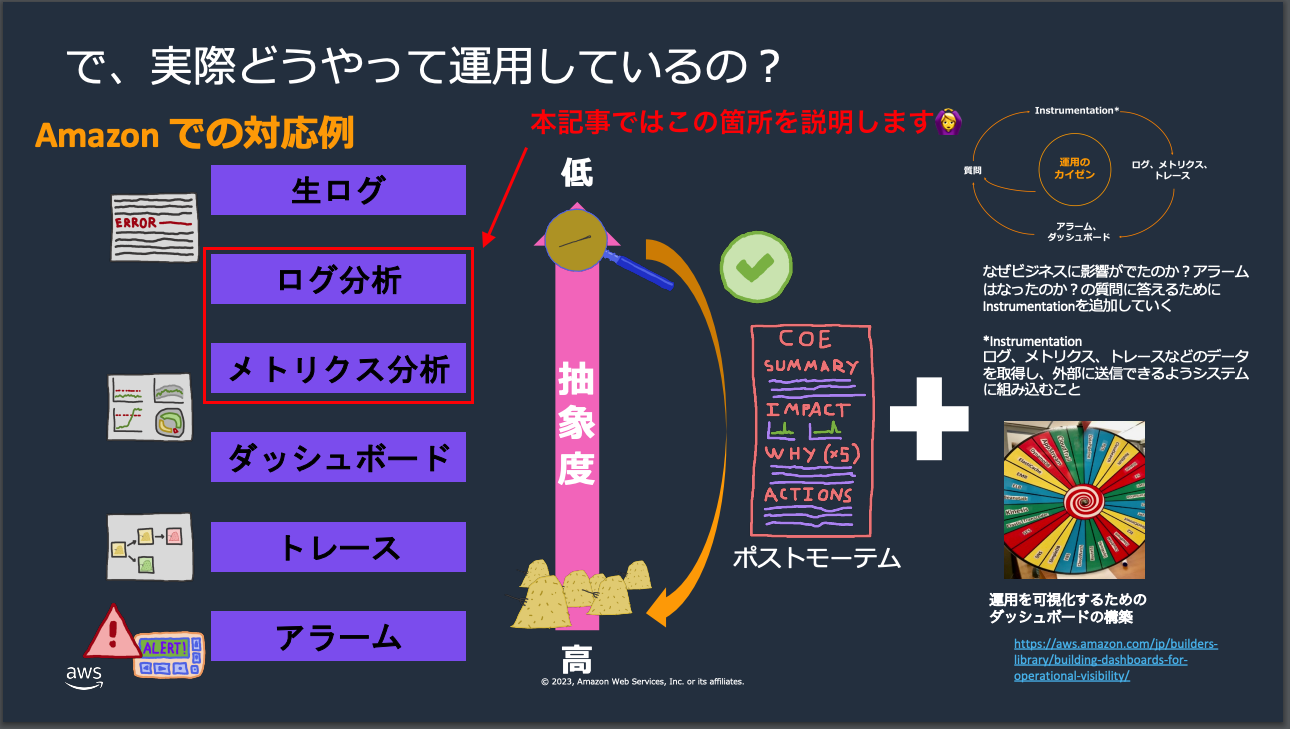
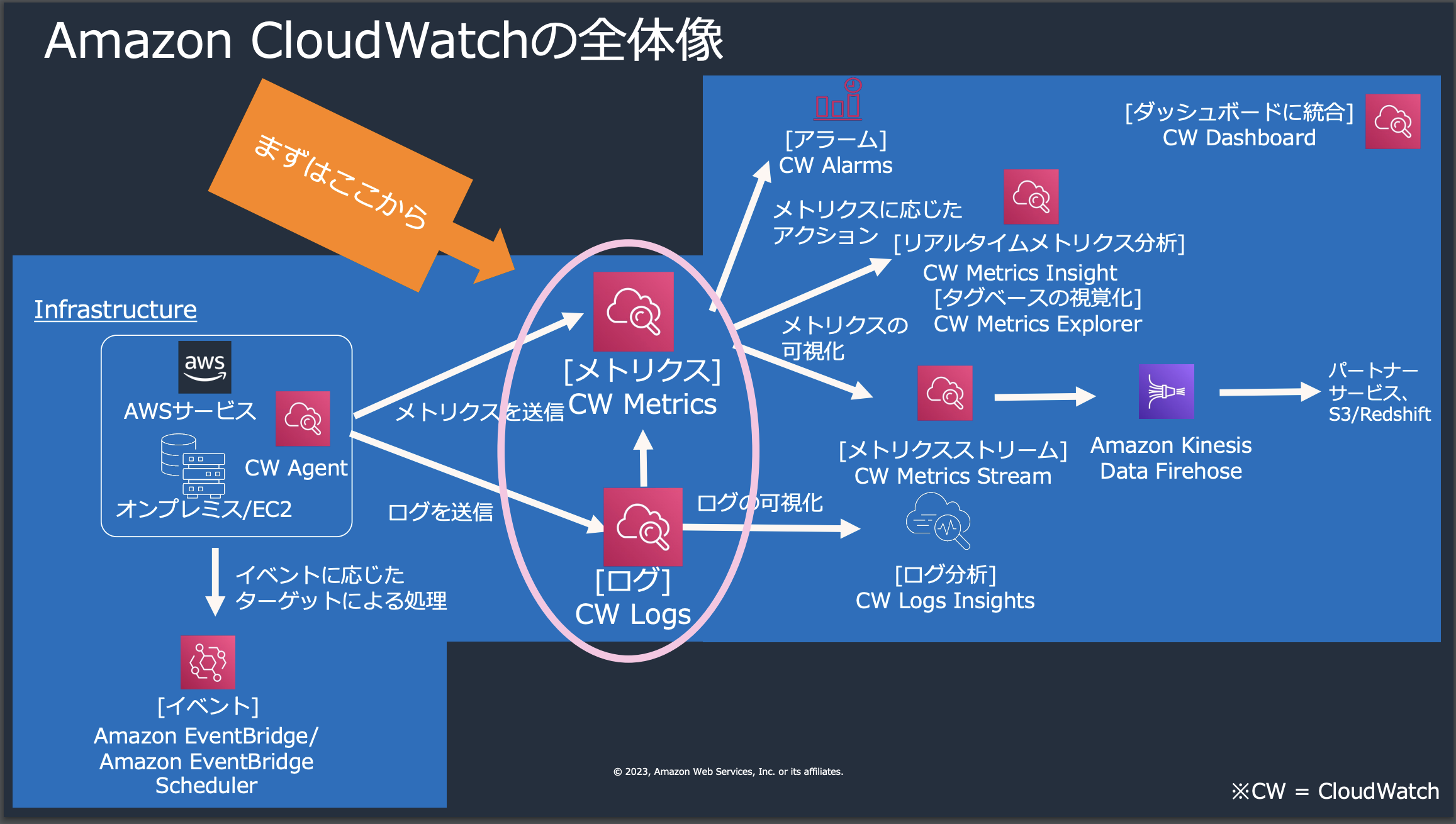
参考にさせて頂いたAWS-Black-Belt_2023_AmazonCloudWatchの資料のYoutube版でも紹介がありますが、実際の運用の流れは"干し草の山から針を探す"のようなものです。
事前に設定されていたアラームや通知を受ける > AWS X-Ray等のトレースを確認して対象リソースを特定する > ダッシュボードを確認 > メトリクス分析 > ログ分析 > 実際の生ログを確認
という流れが大枠になります。そして、ダッシュボード以降の全ての根幹の元になっているのが、CloudWatch Logs・Metricsになのです。
CloudWatch Metricsとは
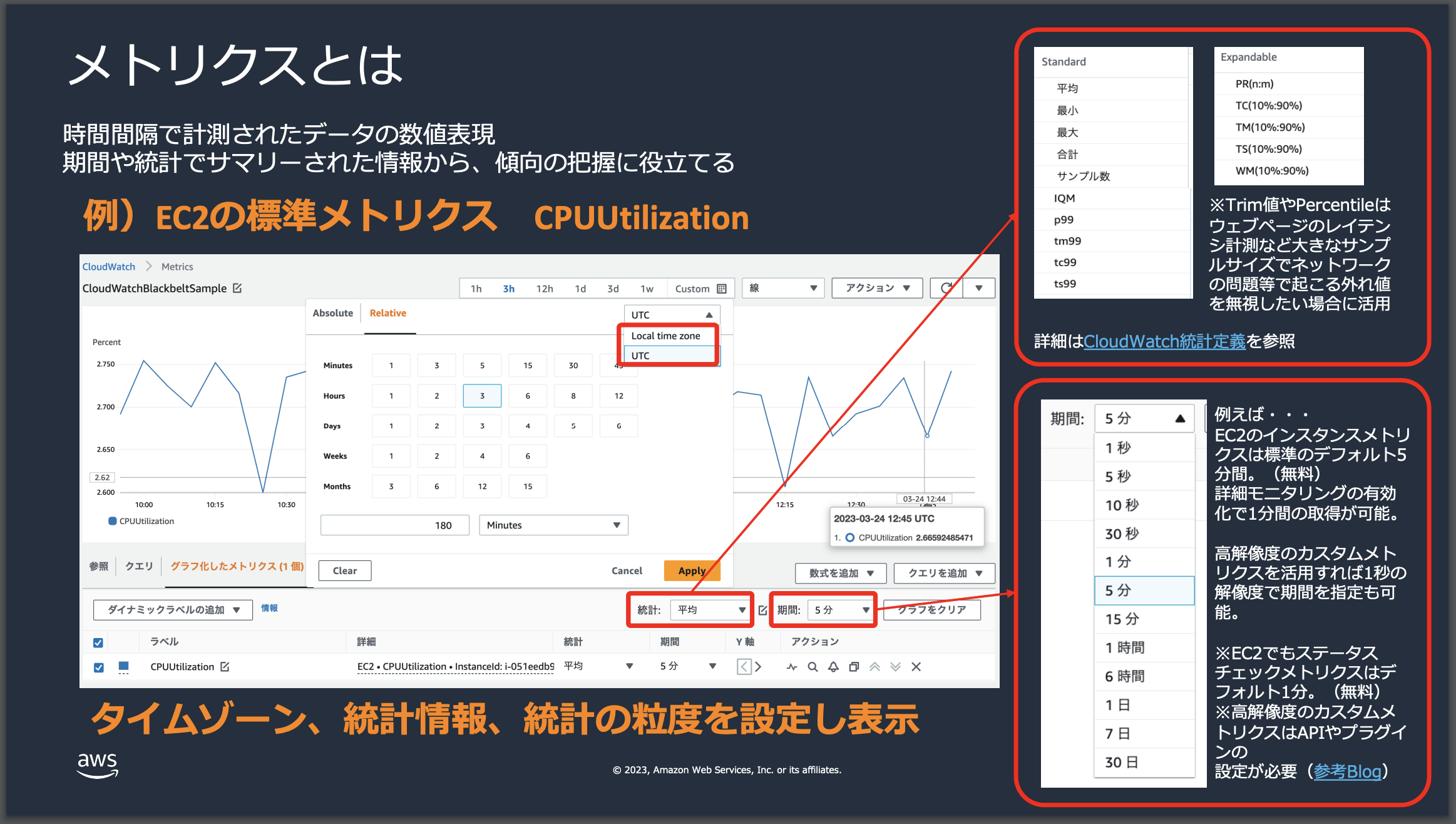
CloudWatch Metricsは、AWSリソースとアプリケーションを監視するためのAWSサービスです。CloudWatch Metricsは、特定のリソースやアプリケーションのパフォーマンスデータを収集し、これをメトリクスとして保存します。これにより、ユーザーはリソースの使用率、アプリケーションのパフォーマンス、および運用上の健全性を監視し、適切なアクションを実行するためのアラートを設定することができます。
名前空間/メトリクス名/ディメンション/データポイント
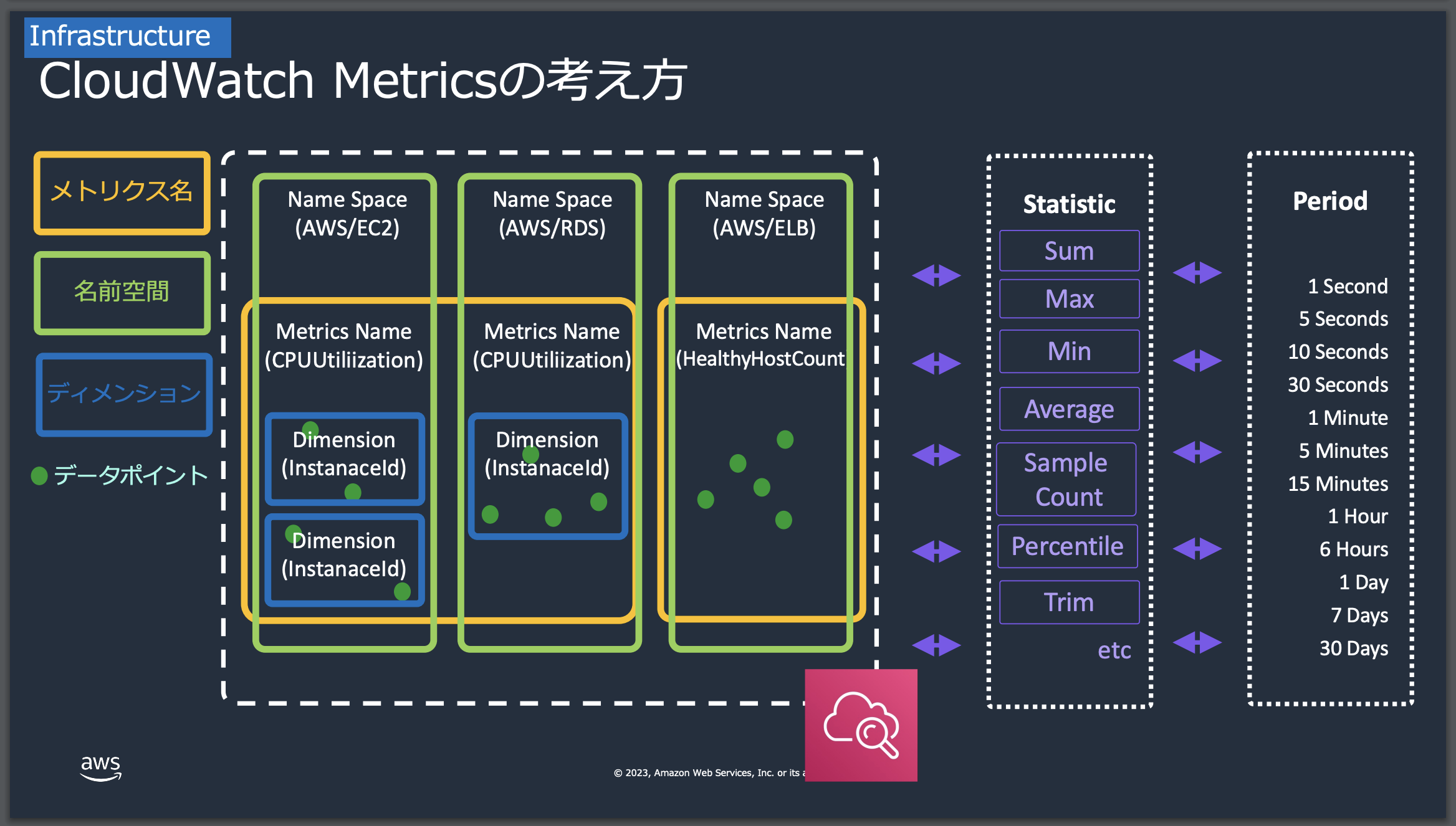
CloudWatch Metricsが少しとっつきにくい 理由として、サービスを利用する上でその仕組み/概念を理解する必要がある点が挙げられます。
具体的には、名前空間・メトリクス名・ディメンション・データポイントというもので構成されています。
上記の画像のにもある通り、それぞれの"切り口"を組み合わせることで対象となるデータポイントを取得してメトリクスとして扱えるようになります。
| 項目 | 内容 |
|---|---|
| 名前空間 | CloudWatchメトリクスのカテゴリです。これは、メトリクスを整理し、同じグループに属するメトリクスを分離するためのコンテナです。AWSサービスのメトリクスには通常、そのサービス名に基づく名前空間があります(例:AWS/EC2)。 |
| メトリクス名 | CloudWatchで収集されるデータの種類を識別する名前です。例えば、CPU使用率、ディスク読み取り回数、ネットワークトラフィックなど、特定のリソースまたはアプリケーションの性能に関する具体的な情報を示します。 |
| ディメンション | メトリクスをさらに具体的な単位で分類するためのキーと値のペアです。例えば、EC2インスタンスのCPU使用率メトリクスでは、インスタンスIDをディメンションとして使用して特定のインスタンスを識別します。 |
| データポイント | 特定の時点でのメトリクスの具体的な値です。 |
Cloud Watch logsとは
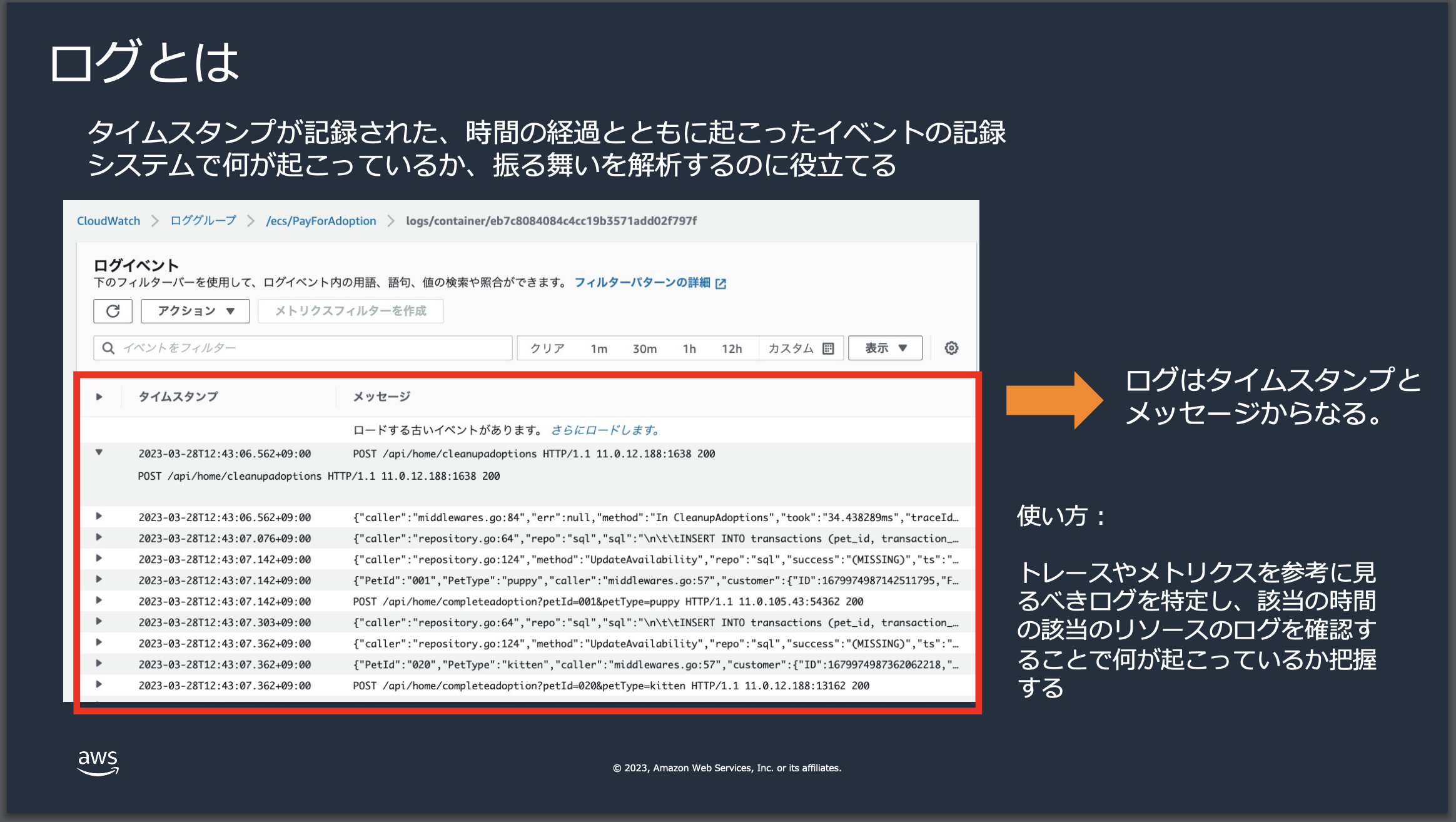
CloudWatch LogsはAWSの監視サービスの一部で、アプリケーションとシステムのログデータを監視して保存する機能を提供します。ユーザーはこれらのログをリアルタイムで監視し、特定のパターンを検索したり、リソースの問題を特定したりするのに使用できます。また、ログデータを長期間保持することも可能であり、適切なアクセス制御と共にセキュリティ分析やコンプライアンスの要件を満たすために利用されます。
ロググループ/ログストリーム/ログイベント
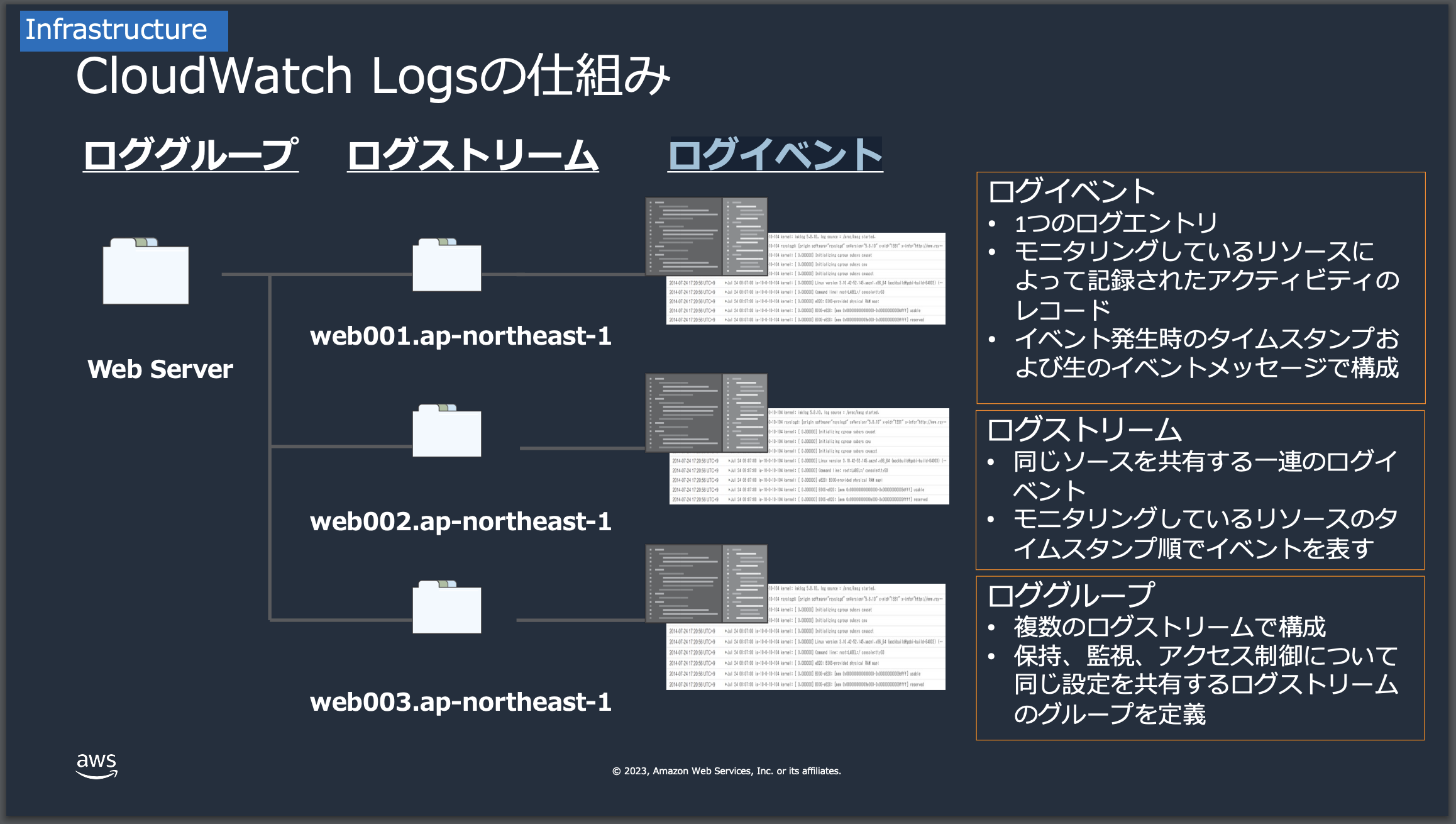
CloudWatch Metrics同様にCloudWatch logsにおいても、構成要素を理解する必要があります。具体的には三つになります。
| 項目 | 内容 |
|---|---|
| ロググループ | ロググループは、関連するログストリームのコンテナです。設定やアクセス権を共通して管理するために使用されます。 |
| ログストリーム | ログストリームは、特定のソースからのログイベントのシーケンスです。たとえば、アプリケーションのインスタンスごとにログストリームを作成します。 |
| ログイベント | ログイベントは、アプリケーションやシステムからCloudWatch Logsに送信される記録です。タイムスタンプとメッセージで構成されます。 |
CloudWatch Metricsやlogsはどのように発行されるのか

多くのAWSサービスでこれらの指標を標準でCloud Watchに発行しています。そのため、利用者は特に追加設定を行うことなくメトリクスの集計やログ分析を行う事ができます。
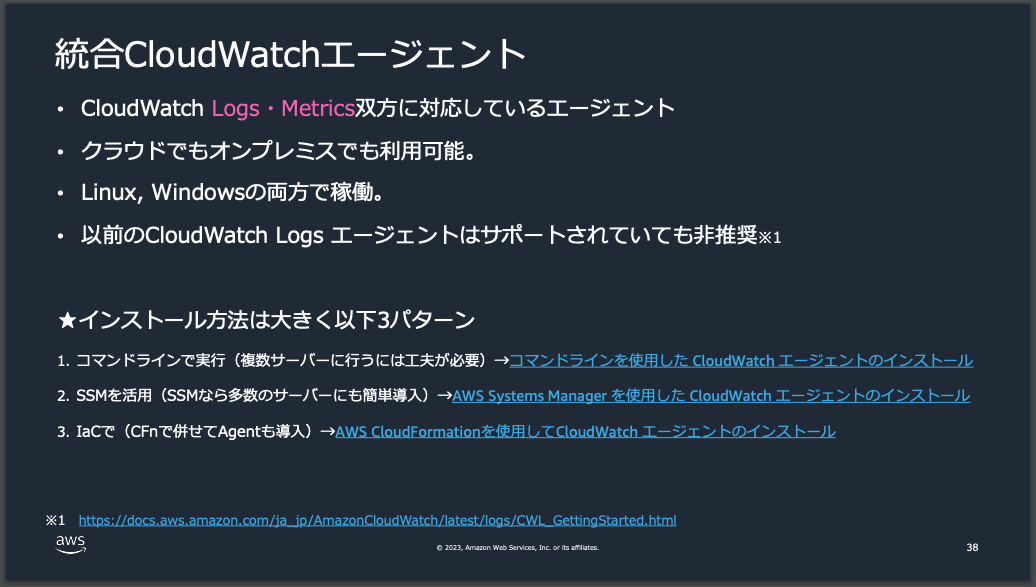
CloudWatch Agentを使ってメトリクス・ログ転送
全てのAWSのリソースが標準でCloudWatchに出力されるわけではありません。また、オンプレミス環境やAWS以外の環境などでも、同様にメトリクスやログを標準でCloudWatchに出力できるわけではありません。
そこで、CloudWatch Agentを監視対象のリソースにインストール、CloudWatch側にメトリクスとログ情報を転送することでリソースのパフォーマンス監視をCloudWatch側で行う事ができます。
メトリクスやログを独自に定義して分析する
あるケースではAWSが標準で設定されているメトリクスでは目的となる監視を行うには不十分なケースがあります。その場合、独自でMetricsを作成することができ、これがカスタムメトリクスと呼ばれるものです。
ハンズオン編
前段が多くなってしまいましたが、ここからは実際に本題のハンズオン内容に入っていきます。説明は割愛しますが以下の設定が事前に必要になります。下記記事を参考にそれぞれ設定をお願いします。
- AWS CLIのインストール
- rootに近い権限を持つIAMユーザーの作成
サンプルアプリの環境構築
本ハンズオンでは私が事前に作成したアプリケーション、各種AWSリソース構築テンプレートを用いて実施します。必要に応じてリポジトリクローンと設定をお願いします。
注意点
利用するAWSの各リソースは課金対象となるものが多く含まれています。個人利用される方は特に注意してください。また、発生した費用やトラブルに関しては一切責任を負いかねます。
| ハンズオン編 | 必要な環境 |
|---|---|
CloudWatch logs編, CloudWatch Metrics編
|
環境構築1 |
CloudWatch Agent編 |
環境構築2 |
環境構築1
CloudWatch logs編, CloudWatch Metrics編で利用するサンプルアプリケーションになります。
このサンプルアプリケーションは、AWS Copilotを利用してECS上にGo製のサンプルAPIをデプロイします。README.mdをご覧頂き環境構築をお願いします。
環境構築2
CloudWatch Agent編で利用するサンプルアプリケーションになります。
このサンプルアプリケーションは、AWS CloudFormationを利用してEC2上にnginxを起動していきます。同様にREADME.mdをご覧頂き環境構築をお願いします。
CloudWatch metrics編
ここからは実際にAWS上でCloudWatch Metricsの関連機能を手を動かしながら確認していきます。環境構築とデプロイが完了していない方はご対応をお願いします。
例1:レイテンシ計測
まず初めに、TargetResponseTimeというメトリクスを用いて、ロードバランサがリクエストをターゲット(たとえば、EC2インスタンス、Lambda関数など)に転送、ターゲットが応答をロードバランサに送信するまでの時間(秒)、つまり、バックエンド処理の遅延を計測してみます。
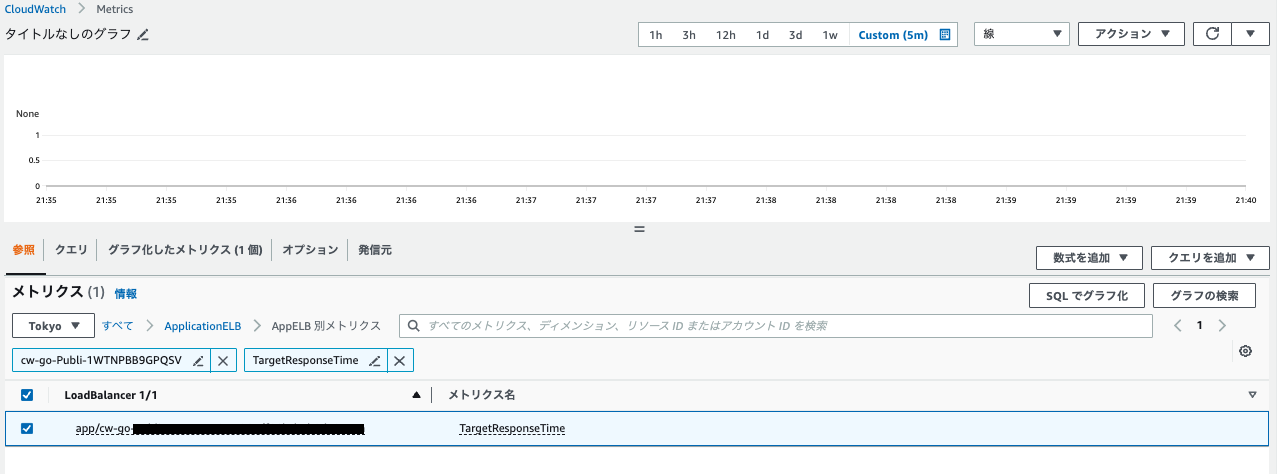
(1)メトリクス選択
マネジメントコンソール > CloudWatch > メトリクス > すべてのメトリクス > ApplicationELB > AppELB 別メトリクス
(2)ロードバランサーのDNS名を取得
ここで一旦別タブを開き、EC2 > Load balancers > 今回新規で作成したロードバランサーのnameをコピーします。
(3)メトリクス選択
(2)でコピーしたロードバランサーのnameとTargetResponseTimeを検索窓で検索 > チェックボックスに選択
(4)統計情報の収集方法と期間を選択
グラフ化したメトリクスを選択して以下を設定します。
| 項目 | 値 |
|---|---|
| 統計 | p99 |
| 期間 | 1分 |
パーセンタイルは統計的な指標の1つで、データセット内の値が特定のパーセンテージ以下であることを示します。例えば、ここでのp99とは、データセットの99%がこの値以下であることを示しています。
(5)レスポンス遅延を発生させる
以下のスクリプトをAPIで叩きます。URLはEC2 > ロードバランサー > 今回新規で作成したロードバランサーのDNS nameをコピーしてください。
for i in {1..10}; do curl -sS http://${新規で作成したDNSから取得}.ap-northeast-1.elb.amazonaws.com/delayedResponse; sleep 1; done
このAPIは以下のような処理でリクエストが発生した場合に、3秒待機したのちレスポンスを返却します。
func delayedResponseHandler(w http.ResponseWriter, r *http.Request) {
// 3秒遅延
time.Sleep(3 * time.Second)
response := Response{
Message: "Delay occurred",
}
if err := json.NewEncoder(w).Encode(response); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
}
}
func main() {
// 省略
http.HandleFunc("/delayedResponse", delayedResponseHandler)
if err := http.ListenAndServe(":8080", nil); err != nil {
panic(err)
}
}
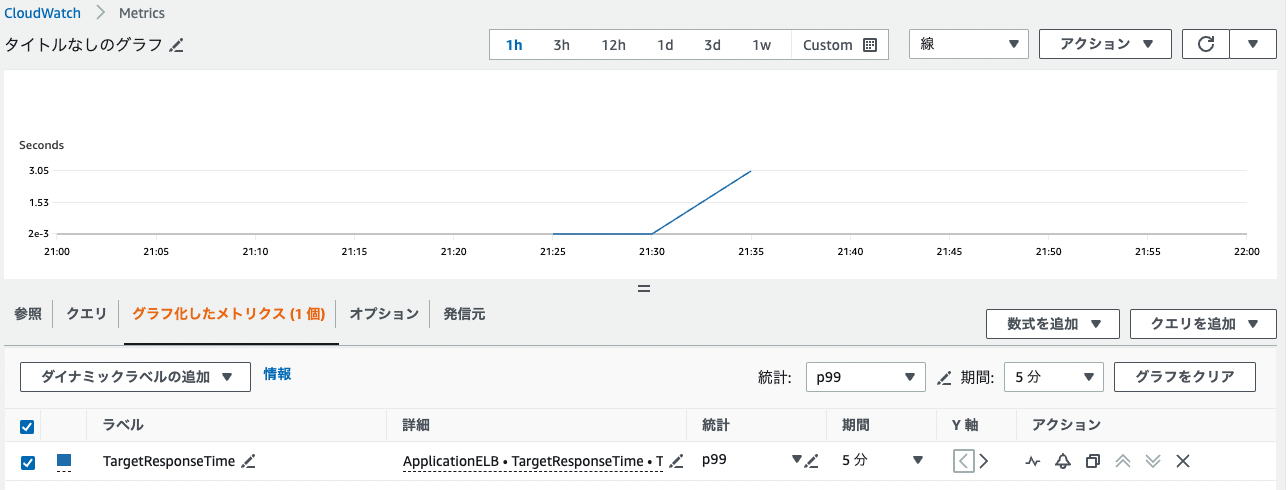
(6)メトリクスを確認
メトリクスの値が急激に上昇しているのが確認できるかと思います。
例2:ECS Service単位でのCPU利用率の計測
ここでは、CloudWatch Metrics Insightsという機能を使って、ユーザーがAWSリソースとアプリケーションのパフォーマンスデータを監視、分析していきます。この機能は、柔軟なクエリ言語を使用して、カスタム分析を行うことができます。
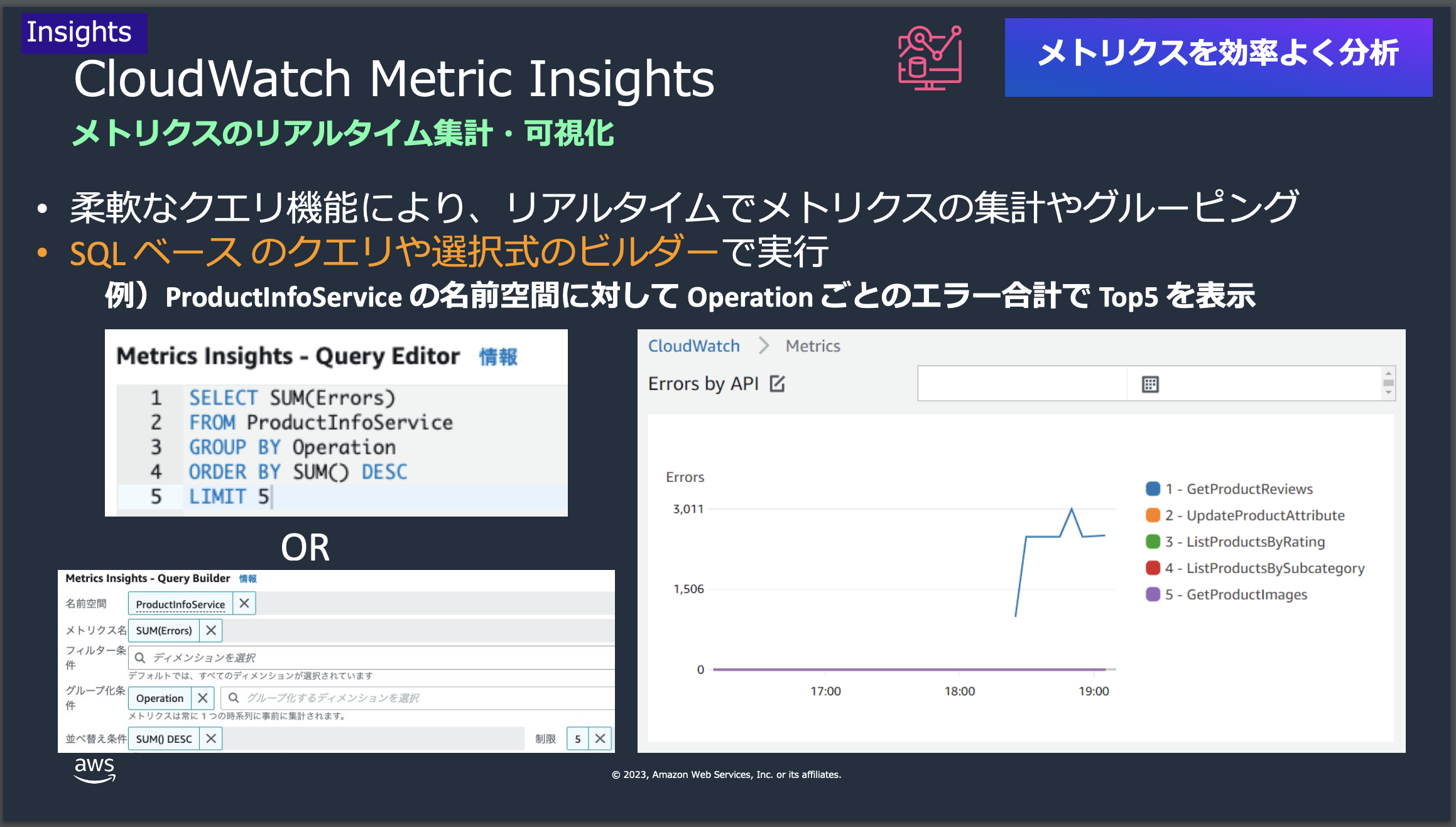
(1)ECS Service名を選択
Amazon Elastic Container Service > クラスター > サービス名
ここではECS ServiceのCPU利用率を確認するために一旦、Service Nameをコピーしておきます。
(2)クエリ設定
マネジメントコンソール > CloudWatch > メトリクス > すべてのメトリクス > クエリタブ
画像と以下を参考に指定の内容を入力していきます。
| 項目 | 値 |
|---|---|
| 名前空間 | AWS/ECS |
| メトリクス名 | MAX(CPUUtilization) |
| フィルター条件 | ServiceName = 上記でコピーした内容 |
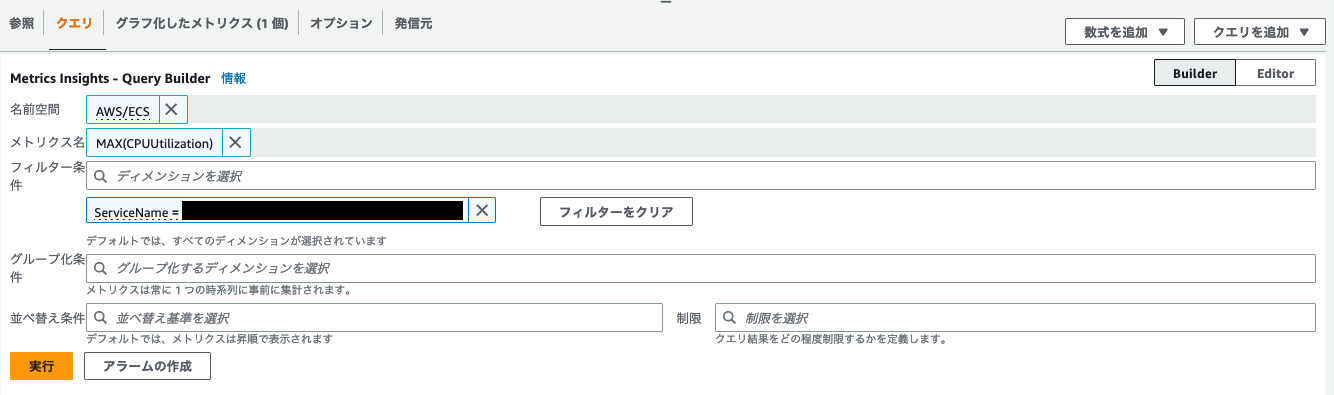
入力はGUIベースのBuilderという機能を用いましたが、左側にあるEditorボタンを押すことでSQLライクなクエリ言語でメトリクスを設定することができます。
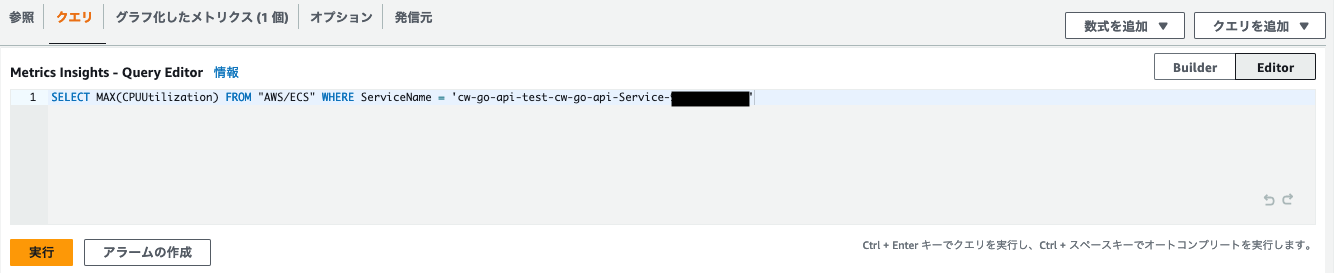
SELECT MAX(CPUUtilization) FROM "AWS/ECS" WHERE ServiceName = 'cw-go-api-test-cw-go-api-Service-xxxxxxx'
(3)CPU負荷を一時的に急上昇させる
URLは以下からコピーしてください。
EC2 > ロードバランサー > 今回新規で作成したロードバランサーのDNS name > コピー
curl http://${新規で作成したDNSから取得}.ap-northeast-1.elb.amazonaws.com/loadCpu
{"message":"Increased CPU load"}
本APIに紐づく処理は非常に負荷のかかる処理になるため、実行回数は必ず1回のみにしてください。
このAPIは以下のような処理でリクエストが発生した場合に一定期間無限ループ処理を走らせてCPU負荷を上昇させます。
func loadCPUHandler(w http.ResponseWriter, r *http.Request) {
done := make(chan int)
go func() {
// 無限ループ作成
for {
select {
// doneチャネルからメッセージが送られてきたとき(またはチャネルが閉じられたとき)無限ループを抜ける
case <-done:
return
// 何もせず次のループへ進む
default:
}
}
}()
// 10秒後にチャネルを閉じる
time.AfterFunc(10*time.Second, func() {
close(done)
})
response := Response{
Message: "Increased CPU load",
}
if err := json.NewEncoder(w).Encode(response); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
}
}
// 省略
func main() {
// 省略
http.HandleFunc("/loadCpu", loadCPUHandler)
// 省略
}
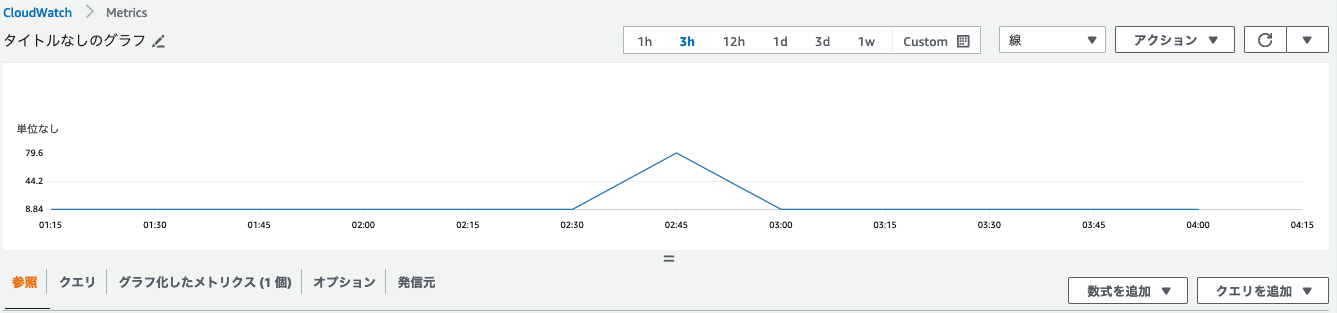
(4)メトリクス確認
特定の期間でCPU負荷が上昇したことが確認できます。
例3:リクエスト成功率/可用性計測
ここでは、Metric Mathという機能を使って、ロードバランサーに対して発生したリクエストのうち、ステータスが200だった割合を計測してみます。
このMetric Mathという機能は、CloudWatchのメトリクスに数式を使⽤して、新しいメトリクスを作成することができます。METRICS関数、基本的な算術関数をはじめとした関数をサポートしており、メトリクスに[Id]フィールドを設定し、関数で利⽤できます。
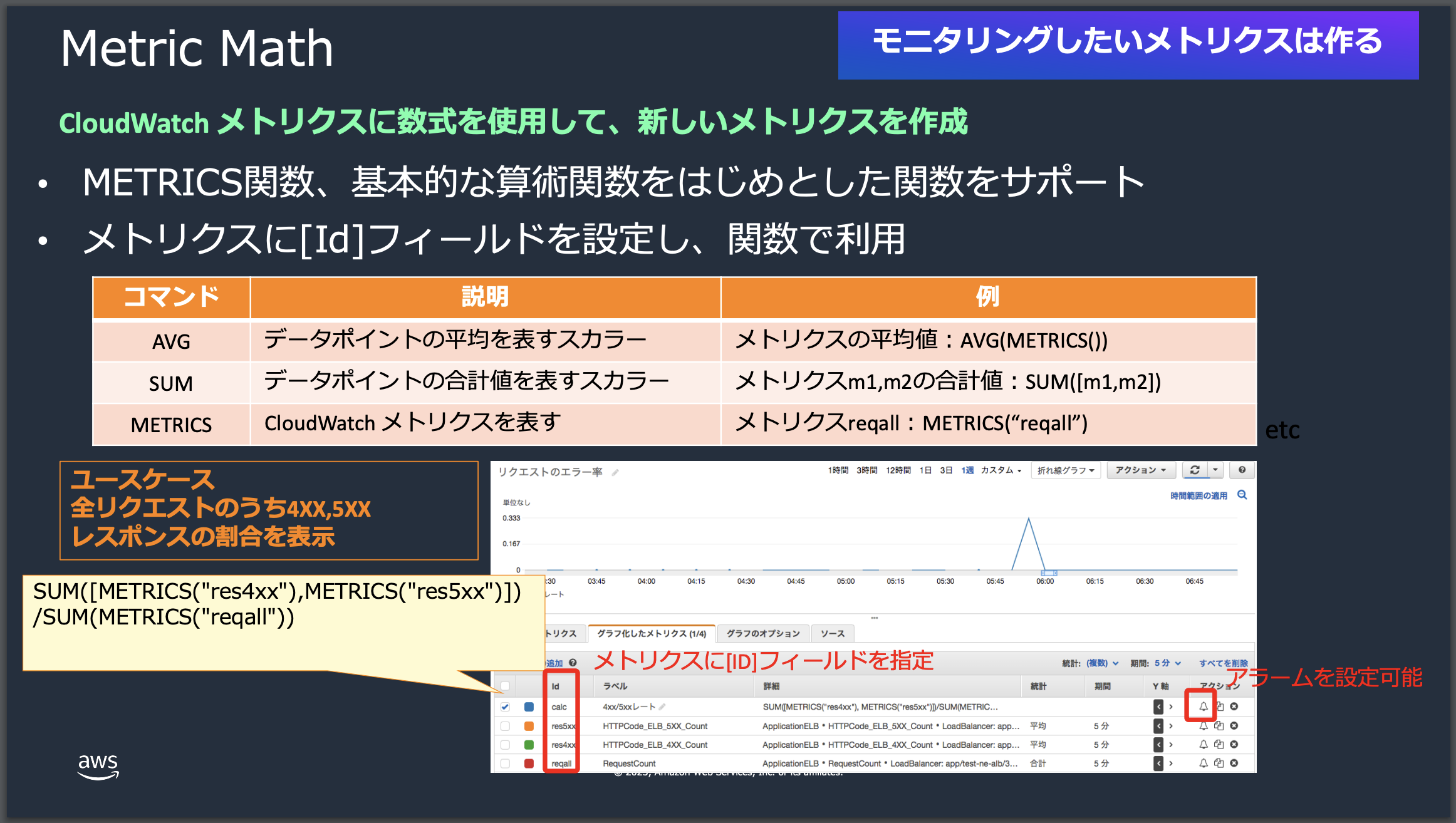
利用するメトリクスはこちらになります。
| 項目 | 内容 |
|---|---|
| RequestCount | 選択したロードバランサーに対してクライアントが発行したリクエストの数 |
| HTTPCode_Target_2XX_Count | ターゲットグループから各HTTP応答コードの数 |
(1)対象となるメトリクス名前空間の選択
マネジメントコンソール > CloudWatch > メトリクス > すべてのメトリクス > ApplicationELB > AppELB 別メトリクス
(2)ロードバランサーのDNS名を取得
ここで一旦別タブを開き、EC2 > Load balancers > 今回新規で作成したロードバランサーのnameをコピーしてください。
(3)メトリクス選択
(2)でコピーしたロードバランサーのnameを検索窓に入力 > RequestCount, HTTPCode_Target_2XX_Countの2つをチェックボックスで選択

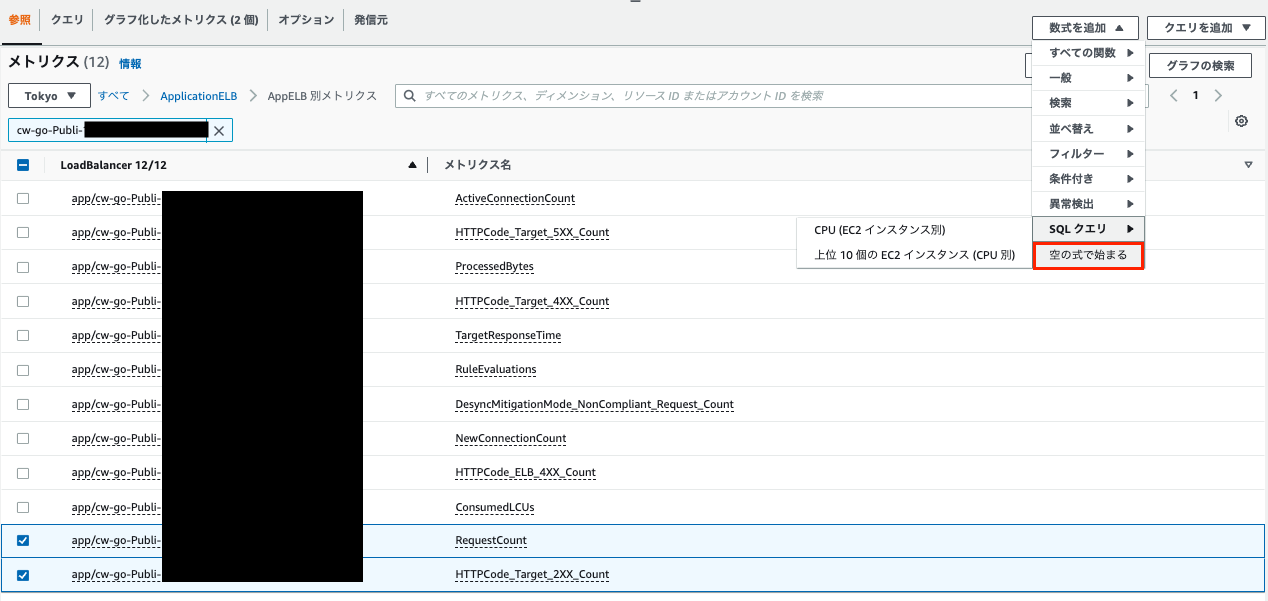
(4)Metric Mathの作成
画像のように左側にある数式を追加 > 空の式をで始まるを選択します
すると"グラフ化したメトリクス"にメトリクスが追加されるため以下のような計算式を入力します。期間は1分を選択してください。
SUM(METRICS("m2")) /SUM(METRICS("m1"))
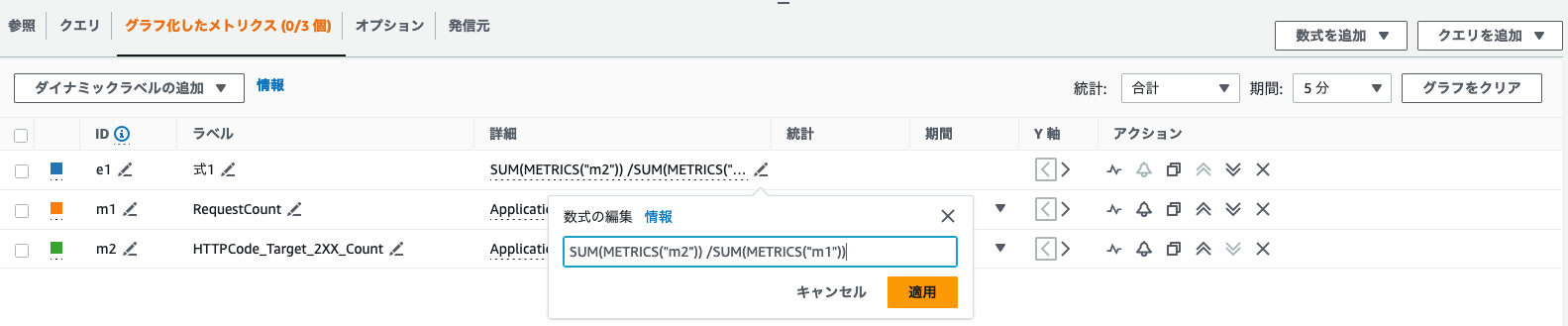
| id | 内容 |
|---|---|
| e1 | Metric Mathが反映 |
| m1 | RequestCount |
| m2 | HTTPCode_Target_2XX_Count |
(5)エラー出力
以下のスクリプトをAPIで叩きます。URLはEC2 > ロードバランサー > 今回新規で作成したロードバランサーのDNS nameをコピーしてください。
# ランダムでエラーを返却
$ for i in {1..10}; do curl -sS http://${新規で作成したDNSから取得}.ap-northeast-1.elb.amazonaws.com/error; sleep 1; done
# 正常ステータスを返却
$ for i in {1..40}; do curl -sS http://${新規で作成したDNSから取得}.ap-northeast-1.elb.amazonaws.com/health; sleep 1; done
上記のうちエラー出力のAPIは以下のようにリクエスト毎にエラーステータスをランダムに出力します。
func errorHandler(w http.ResponseWriter, r *http.Request) {
errors := []int{
http.StatusBadRequest,
http.StatusUnauthorized,
http.StatusForbidden,
http.StatusNotFound,
http.StatusInternalServerError,
http.StatusBadGateway,
http.StatusServiceUnavailable,
http.StatusGatewayTimeout,
}
// Set log flags to 0 to disable date and time prefix
log.SetFlags(0)
// 任意のステータスエラーをランダム生成
rand.Seed(time.Now().UnixNano())
errorIndex := rand.Intn(len(errors))
w.WriteHeader(errors[errorIndex])
response := Response{
Message: http.StatusText(errors[errorIndex]),
}
// ログ出力をjson形式に変換する
logData := map[string]interface{}{
"timestamp": time.Now().Format(time.RFC3339),
"status_code": errors[errorIndex],
"message": response.Message,
}
logJSON, err := json.Marshal(logData)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
log.Println(string(logJSON))
if err := json.NewEncoder(w).Encode(response); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
}
}
// 省略
func main() {
// 省略
http.HandleFunc("/health", healthHandler)
http.HandleFunc("/error", errorHandler)
// 省略
}
(6)メトリクスを確認
エラーレスポンス => 正常レスポンスの順番で当該APIを叩いているため徐々にリクエスト成功率が上昇していることが確認できます。
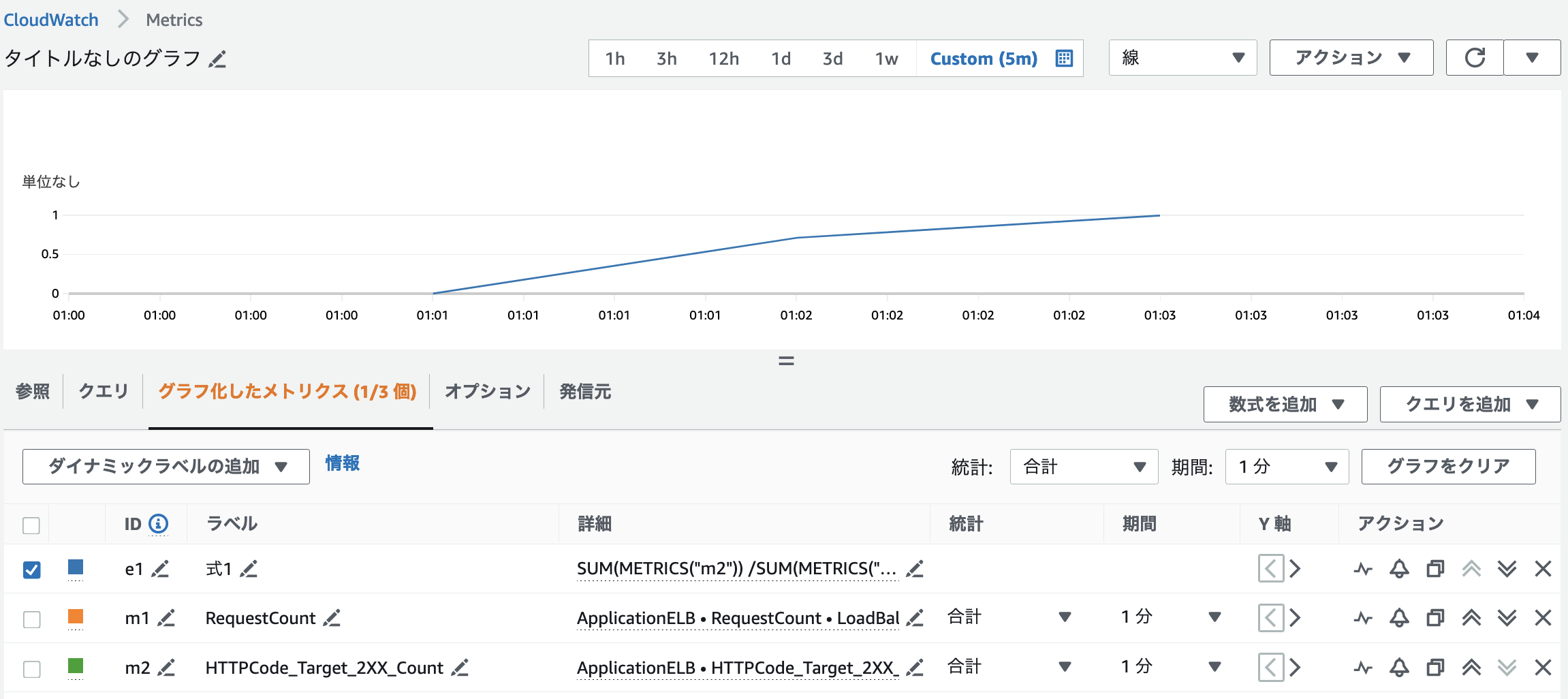
例4:SLOアラートの設定
ここでは上記で説明した例1:レイテンシ計測で説明したメトリクスを使ってアラートを作成します。上述の通り、ドメインや組織によってSLOも異なります。また、今回設定したメトリクスもSLOとして正しいわけでもありません。
ここでのSLOの定義
1分間にわたって99%以上のリクエストのレスポンス時間が500msを超えた場合、SLO違反が発生したと判断
(1)Cloud Watch Aramの作成
アクション欄にある🛎マークを押すことでCloudWatch Aramを作成することができます。

以下の画像を参考に設定します。
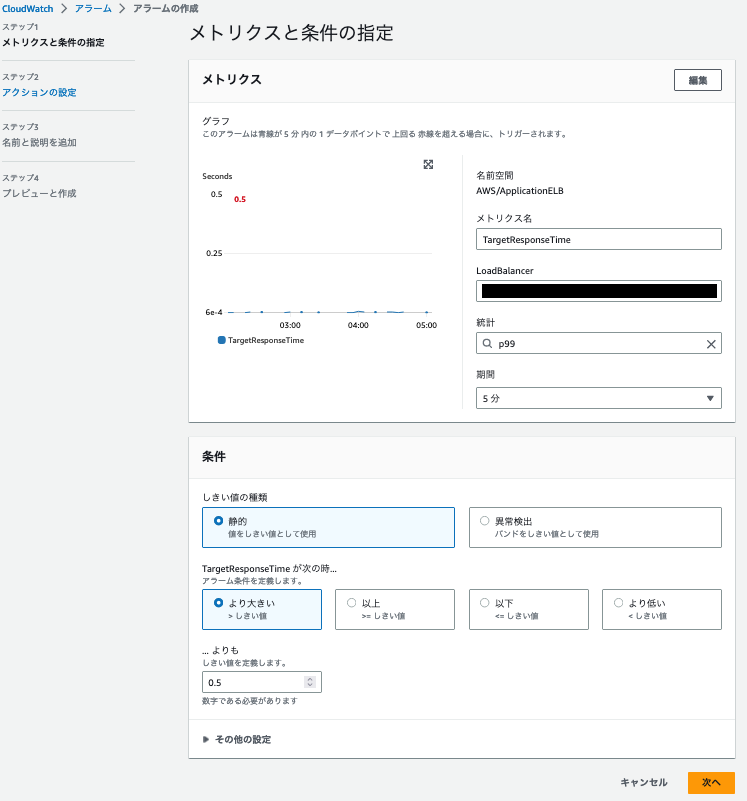
新しいトピックの作成 > 通知を受け取る E メールエンドポイント > 任意のメールアドレスを入力
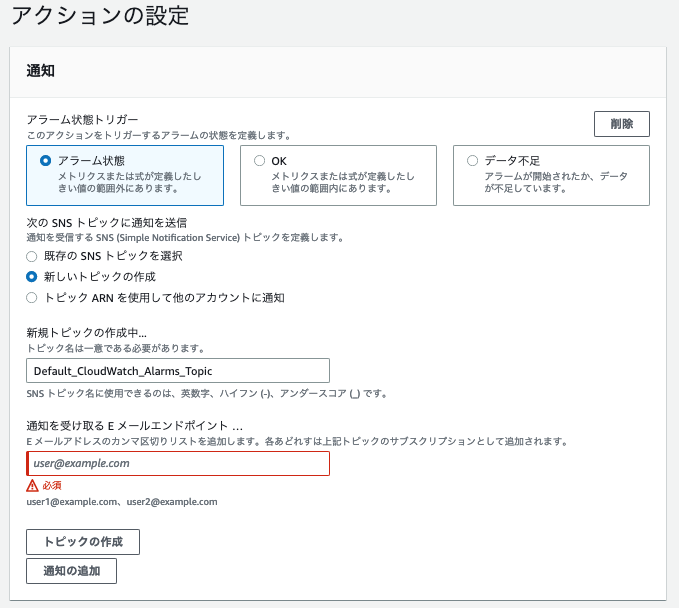
新規にトピックを作成すると確認メールが送付されるので承認してください。

アラームの名前は任意のもので構いません。
(2)ロードバランサーのDNS名を取得
URLは以下からコピーしてください。
EC2 > ロードバランサー > 今回新規で作成したロードバランサーのDNS name > コピー
(3)遅延を発生させる
for i in {1..10}; do curl -sS http://.ap-northeast-1.elb.amazonaws.com/delayedResponse; sleep 1; done
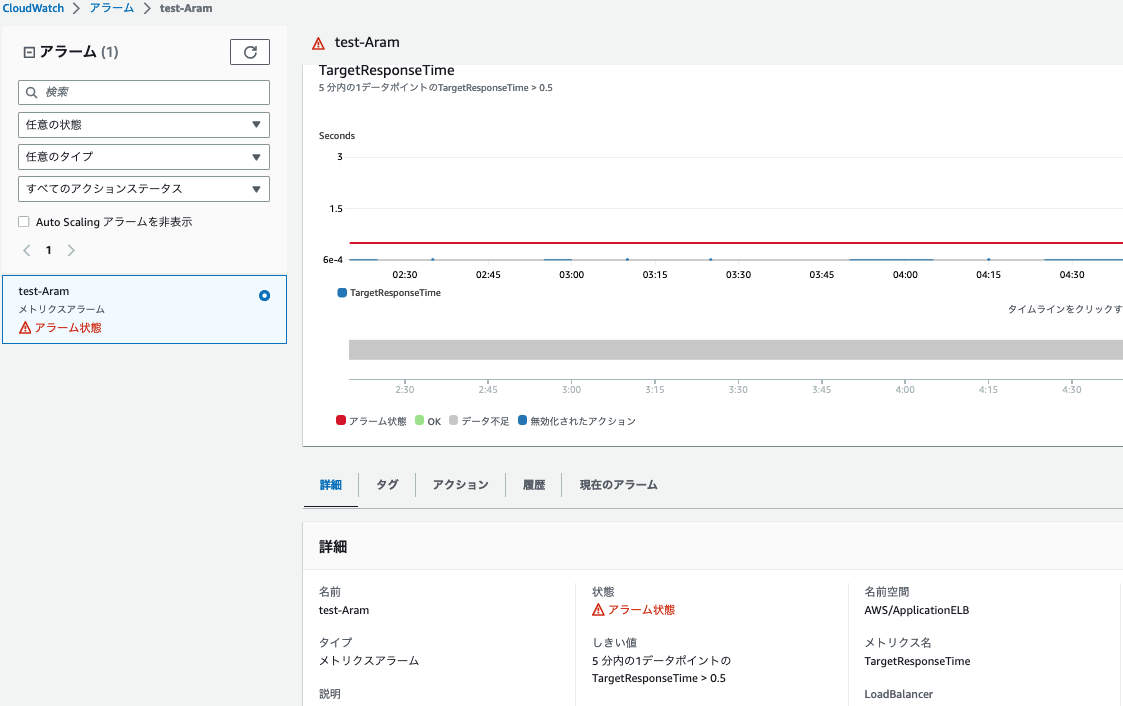
(4)アラート確認
以下のようにアラート常態となり、アラートメールが届くことが確認できます。

例5: Container Insightを用いた統合管理

Container InsightはECSやFargateやEKSのメトリクスやログを、CloudWatchで取得〜可視化~分析するための統合的な機能です。各種メトリクスを設定することは上記の手順の通り比較的工数がかかりますが、本機能を利用することでワンタッチで利用することができるため非常に便利です。
(1)Container Insightを有効化する
本アプリケーションでは、Copilotの設定ファイルに記述することですぐに利用することができます。
# The manifest for the "test" environment.
# Read the full specification for the "Environment" type at:
# https://aws.github.io/copilot-cli/docs/manifest/environment/
# Your environment name will be used in naming your resources like VPC, cluster, etc.
name: test
type: Environment
# Import your own VPC and subnets or configure how they should be created.
# network:
# vpc:
# id:
# Configure the load balancers in your environment, once created.
# http:
# public:
# private:
# Configure observability for your environment resources.
observability:
container_insights: true # ここをtrueに設定します!!
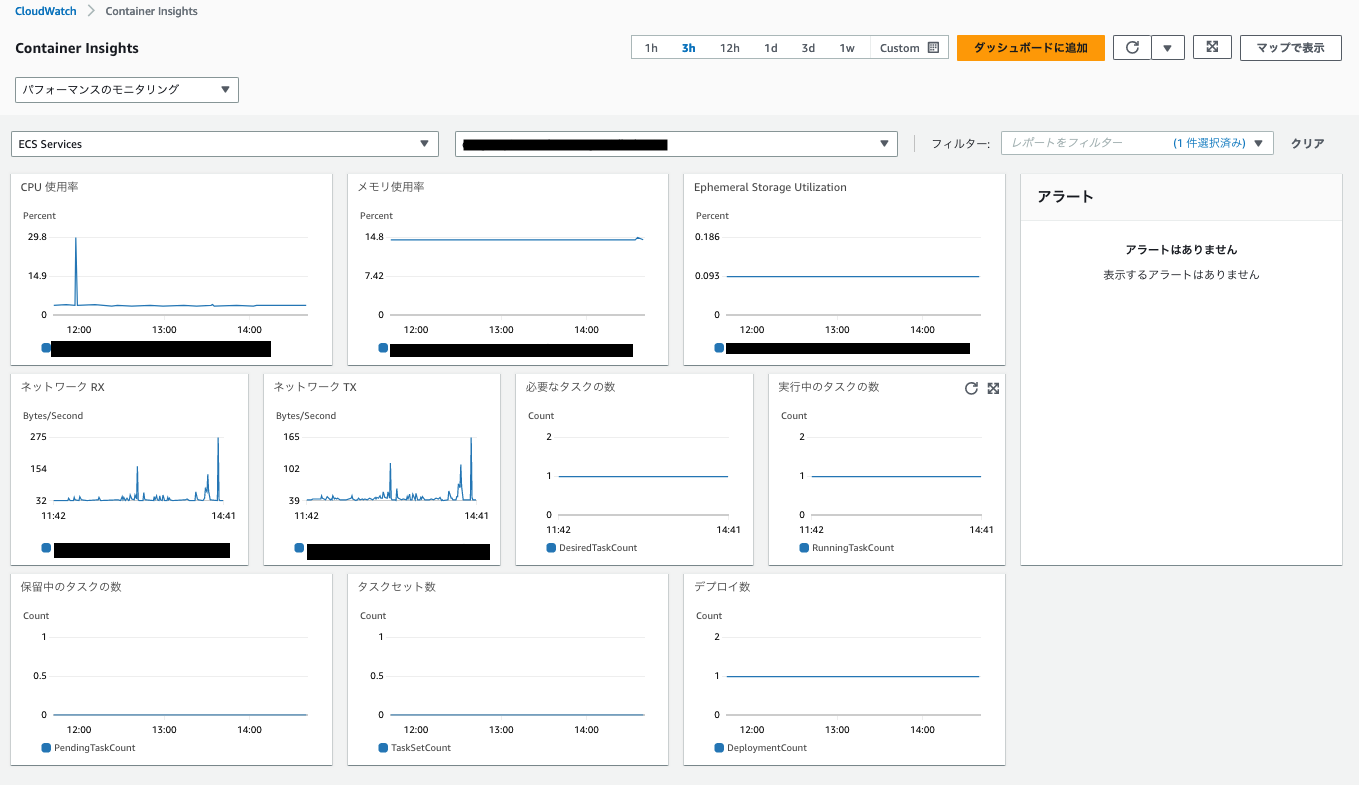
(2)ダッシュボードを確認
CloudWatch > Container Insights > ECS Service
以下のような図の通り必要な指標が一通り揃っているので非常に便利です。
CloudWatch logs編
次は、CloudWatch logsの関連機能を手を動かしながら確認していきます。引き続き上記で環境構築したサンプルアプリを用いて確認していきます。
例1:特定の文字列"Error"が含まれているログのみを抽出
ここではCloudWatch Logs Insightsという機能を用いて抽出してみます。

本機能は、CloudWatch Logsに保存されているログデータを分析するための対話型のクエリ機能です。ユーザーは標準SQLに似たクエリ言語を使用してカスタムクエリを作成し、ログデータを分析して視覚的なグラフや表を生成します。これにより、迅速なトラブルシューティングと効果的な監視が可能となります。
ユースケースとしては、エラーログの中の特定の文字列のみを抽出して分析したいケースなどです。
(1)エラー出力
本ハンズオンで利用しているアプリケーションはCopilot経由でECS上にデプロイしています。ECSではエラー標準出力先がデフォルトでCloudWatchとなっているため、アプリケーション側で特に指定がない場合、当該リソースにログが転送されます。
上記で既に利用した/errorにリクエストを再度投げてみます。
# ランダムでエラーを返却
$ for i in {1..100}; do curl -sS http://${新規で作成したDNSから取得}.ap-northeast-1.elb.amazonaws.com/error; sleep 1; done
(2)ログ確認
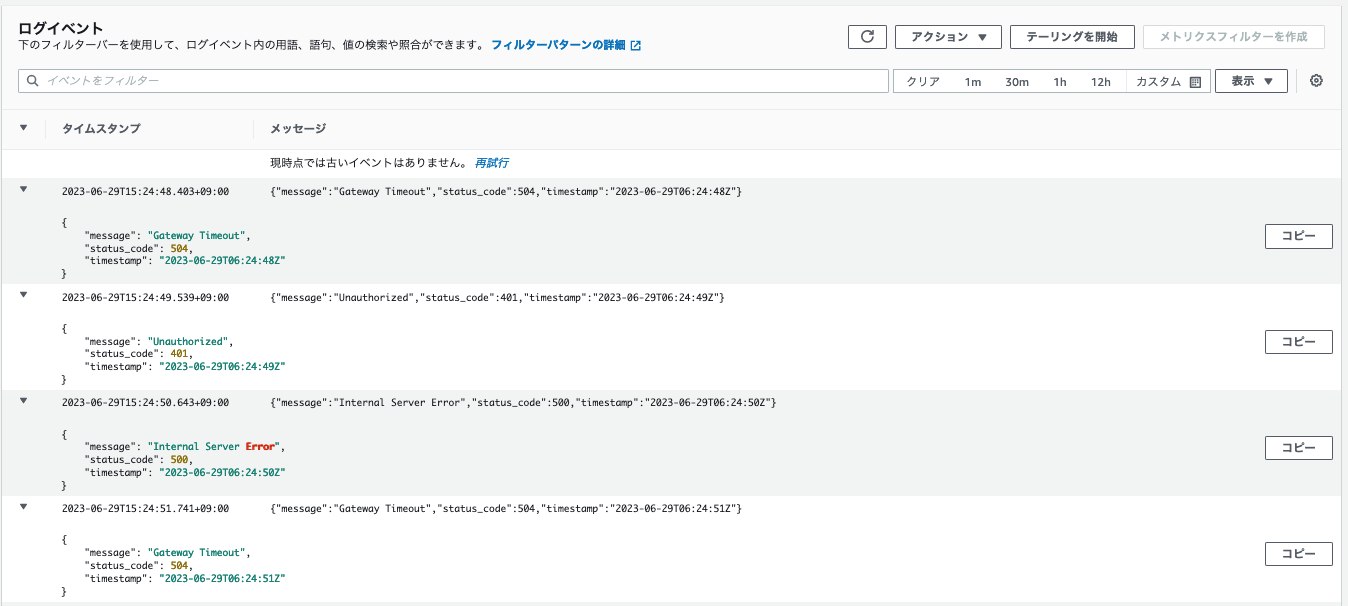
CloudWatch > ロググループ > /copilot/app-test-cw-go-api
以下のようにログが出力されていることが確認できます。
(3)モニタリング対象のロググループを選択
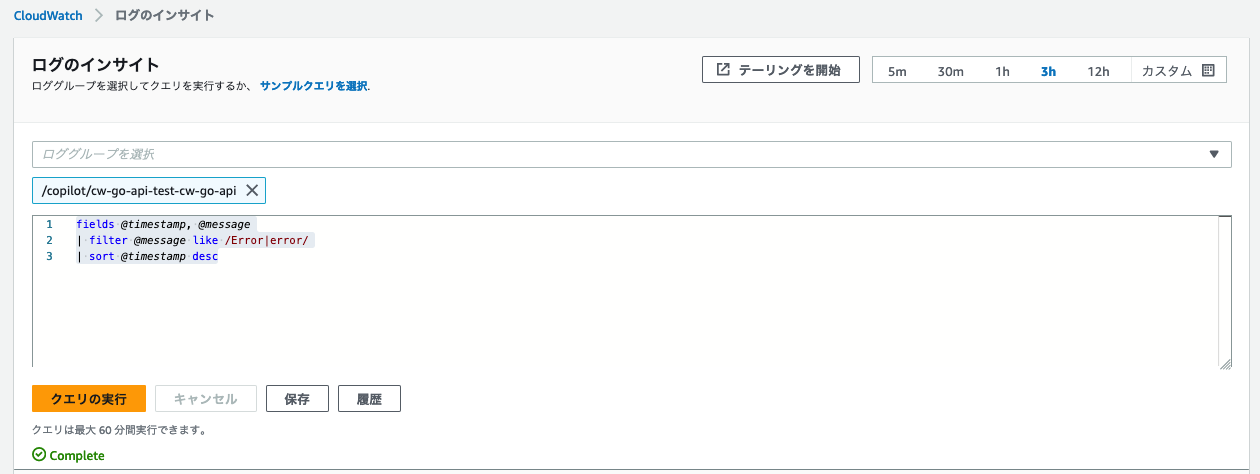
CloudWatch > ログのインサイト > ロググループを選択 > /copilot/app-test-cw-go-api
(4)クエリ作成
以下のクエリを入力 > 実行
fields @timestamp, @message
| filter @message like /Error|error/
| sort @timestamp desc
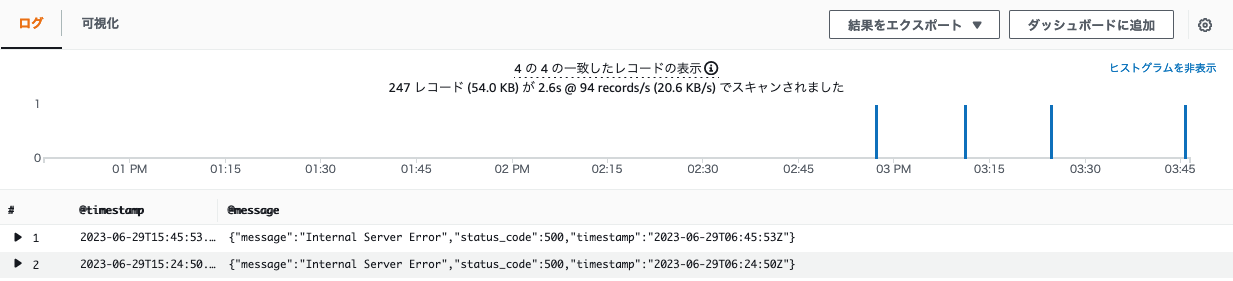
(5)結果の確認
以下のようにロググループの中のログイベント内に特定の文字列が含まれているレコードのみ抽出できています。
例2:ログをメトリクス化して特定の文字列が含まれているかをカウント
ここではCloudWatch Logs メトリクスフィルターという機能を用いて抽出してみます。
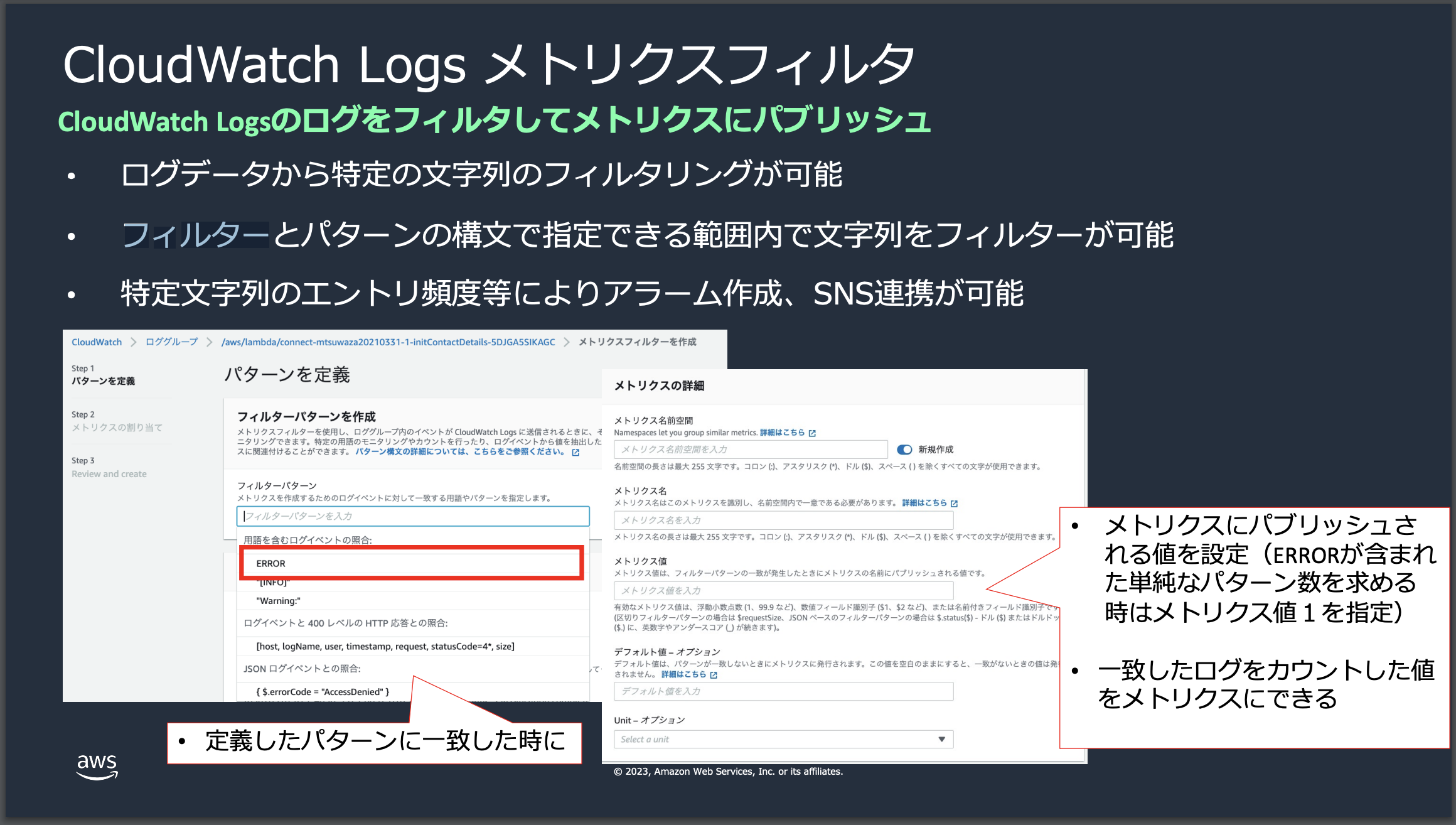
本機能は、ログデータ内のパターンを検索し、その情報をメトリクスとして抽出します。CloudWatchアラームと連携させることで、異常を検知した際に通知や自動的なアクションを行うことが可能です。
ユースケースとしては、特定の文字列(ex.Error)が含まれていた場合にカウントするカスタムメトリクスを作成 => 上記メトリクスを使ったアラートを作成 => 通知するといったような、ログの中身をベースにアラートやイベントを発生させるケースです。
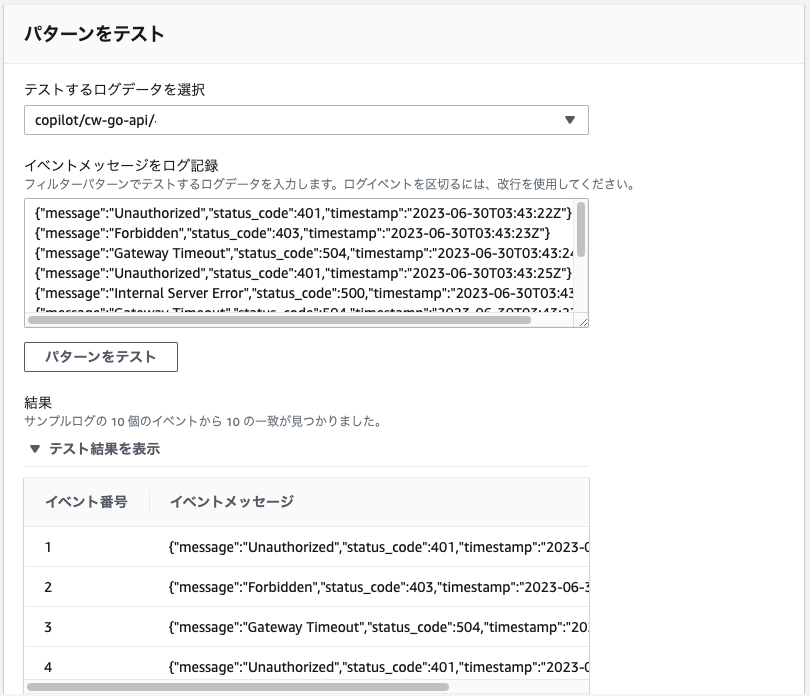
(1)ログのパターンをもとにカウントするメトリクスフィルターを作成
Cloud watch > ロググループ > /copilot/app-test-cw-go-api > メトリクスフィルターを作成
| 項目 | 値 |
|---|---|
| フィルターパターン | Error |
| テストするログデータを選択 | 上記で/errorが!出力されたロググループ |
パターンをテストで該当するログデータが表示されることも確認できます。
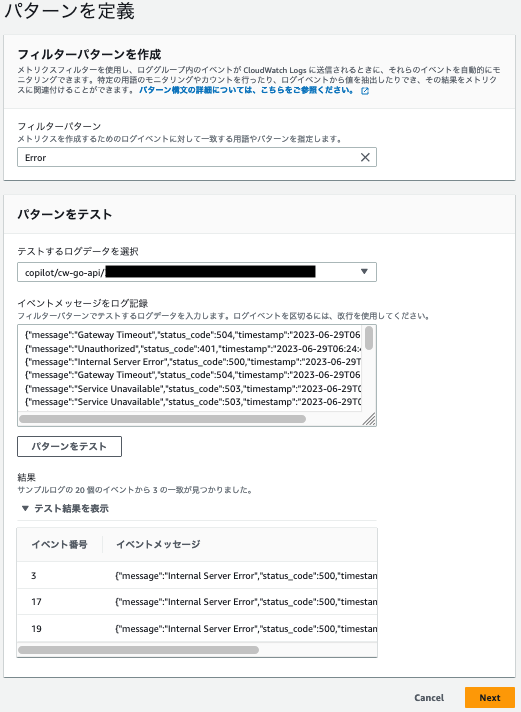
| 項目 | 値 |
|---|---|
| フィルター名 | error-count |
| メトリクス名前空間 | 任意の名前空間を指定してください |
| メトリクス名 | error-count |
| メトリクス値 | 1 |
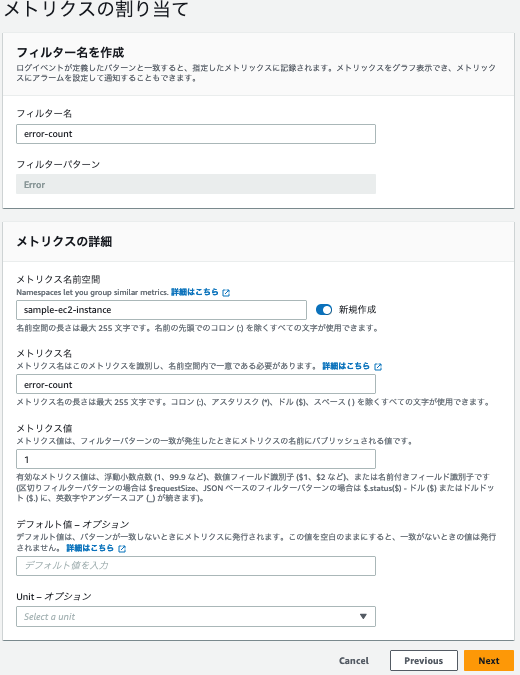
(2)エラーを出力
以下のスクリプトをAPIで叩きます。
URLはEC2 > ロードバランサー > 今回新規で作成したロードバランサーのDNS nameをコピーしてください。
# ランダムでエラーを返却
$ for i in {1..100}; do curl -sS http://${新規で作成したDNSから取得}.ap-northeast-1.elb.amazonaws.com/error; sleep 1; done
(3)Cloud Watch Metricsから確認
CloudWatch > すべてのメトリクス > 参照 > 上記で指定した任意の名前空間 > ディメンジョンなしのメトリクス > error-count
メトリクスが計測されるまで、少し時間がかかるのでご注意ください。
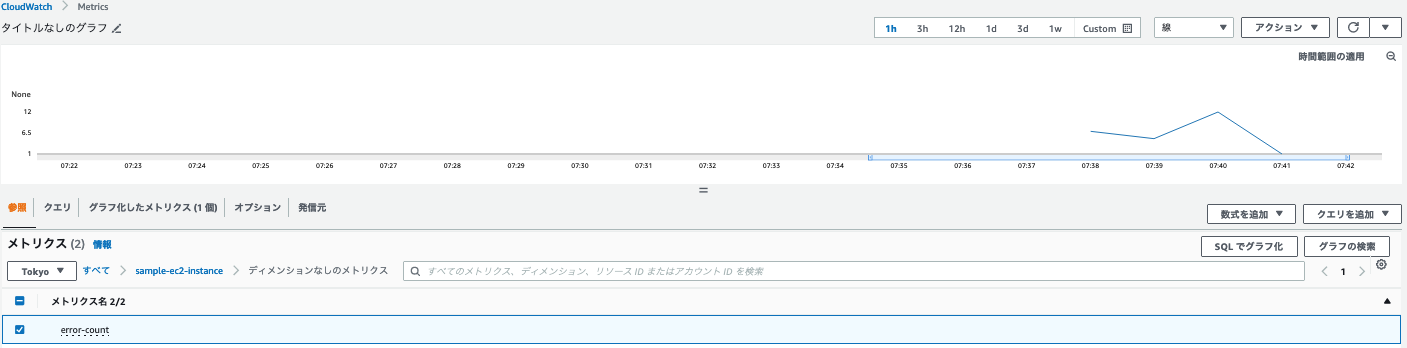
ここまでくれば、あとは既存のメトリクスと組み合わせたり、アラートを発生させることも可能ですね。
※アラート作成とメール通知に関しては重複する内容になるため割愛します。
例3:Kinesis Data Firehose/S3/Amazon Athenaを使ったログ転送と分析
CloudWatch logsは便利なのですがログ保管はコストパフォーマンスがあまり良くありません。そこで、ログデータを他のAWS 上のデータウェアハウスに転送する事がよくあります。また、転送先で大量のログデータを分析するための基盤を設定することも重要です。
ここでは以下のリソースを用いてログ転送とログ分析基盤を構築します。
| リソース名 | 内容 |
|---|---|
| Kinesis Data Firehose | リアルタイムで大量のデータを収集し、S3, Redshift, Elasticsearchなどに簡単にロードできるストリーミングデータ配信ツールです |
| S3 | ストレージサービス。ここではCloud Watchから転送されたログを格納します。 |
| Amazon Athena | S3上の大量のデータに対してSQLを使用して分析を行うことができます。サーバーレスで、設定や管理が不要で、実行したクエリのみに課金されます。 |
| Cloud Watch subscription filter | AWS CloudWatch Logsからリアルタイムでログデータをフィルタリングし、指定したAWSサービス(例:Lambda, Kinesis)に転送する機能です。 |
また本ハンズオンでは、CloudWatch Log サブスクリプションフィルタという、外部にリアルタイムでログ転送ができる機能を使っていきます。

(1)事前準備
以下のリソースは説明が冗長になるためcloudformationを使って作成してしまいます。
| リソース名 | リソース | 目的 |
|---|---|---|
| KinesisDataBucket | s3 | Kinesis Data Firehoseの配信ストリーム送信先 |
| AthenaQueryBucket | s3 | Amazon Athenaで実行したクエリ結果を保管する先 |
| LogsRole | IAM | CWLがFirehoseにログデータを渡すために必要になるAssumeRole権限 |
以下、スクリプトを実行してスタックを作成します。
$ pwd
/Users/hogehoge/cw-go-api
# スタック作成
$ aws cloudformation create-stack \
--stack-name s3-iam \
--template-body file://cw-sbf.yml \
--capabilities CAPABILITY_IAM
マネジメントコンソールの画面でステータスがCREATE_COMPLETEという表示になっていれば完成です。
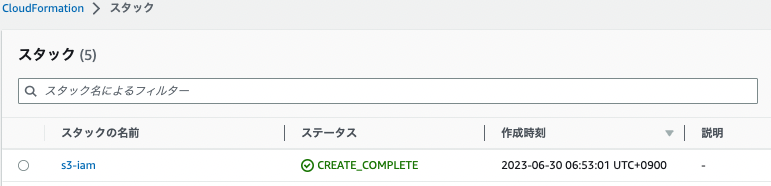
(2)Kinesis Data Firehoseを作成
マネジメントコンソール > Amazon Kinesis > Data Firehose > 配信ストリームを作成
少し設定画面が多いですが画像を参考に入力してください。
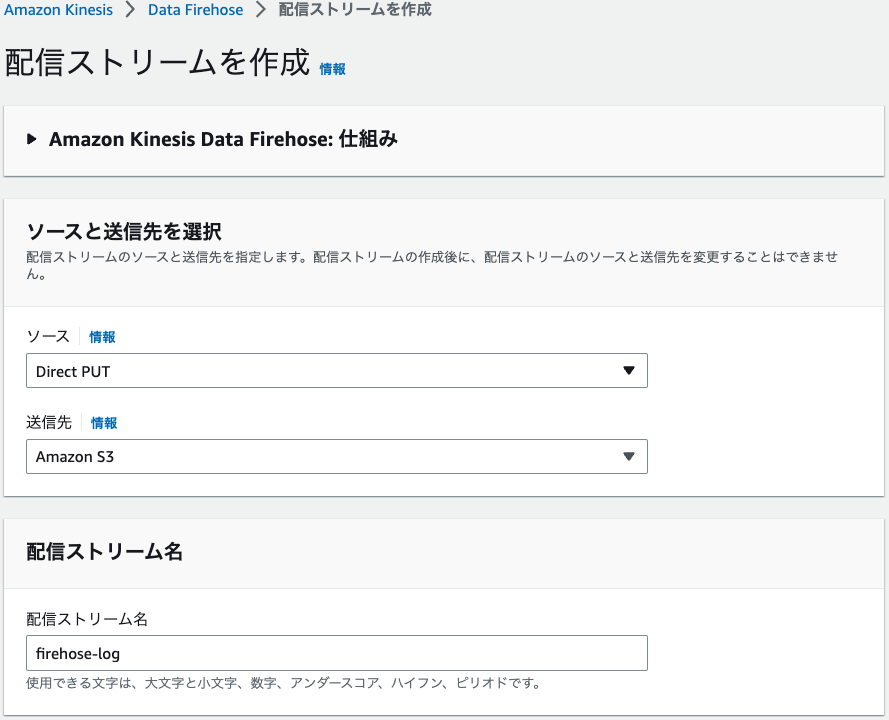
デフォルトのままだとClod Watch サブスクリプションフィルタから転送されたログでは、Amazon Atena側でデータ形式の問題で分析できません。そのため、一旦、Lamda側でデータ変換を行います。
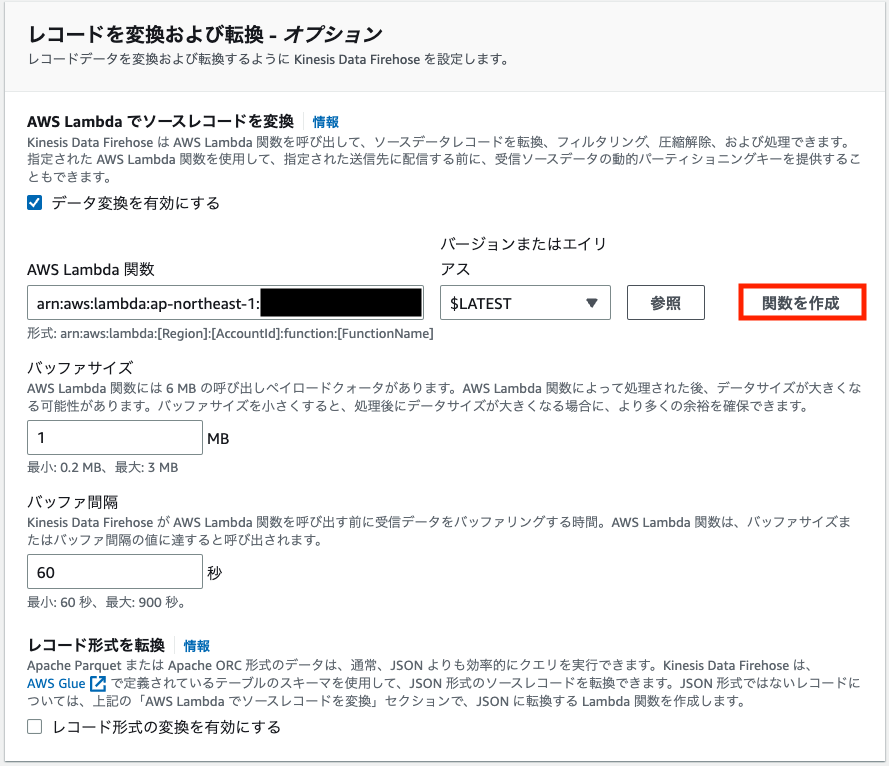
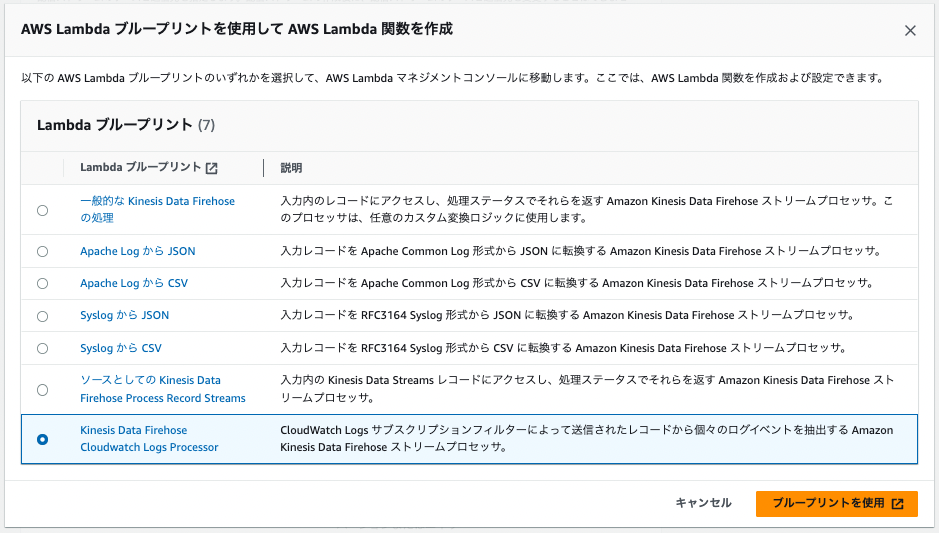
関数名 > streamProcessorと入力 > 関数の作成 > 以下の画像のように成功バーが表示されれば完成です
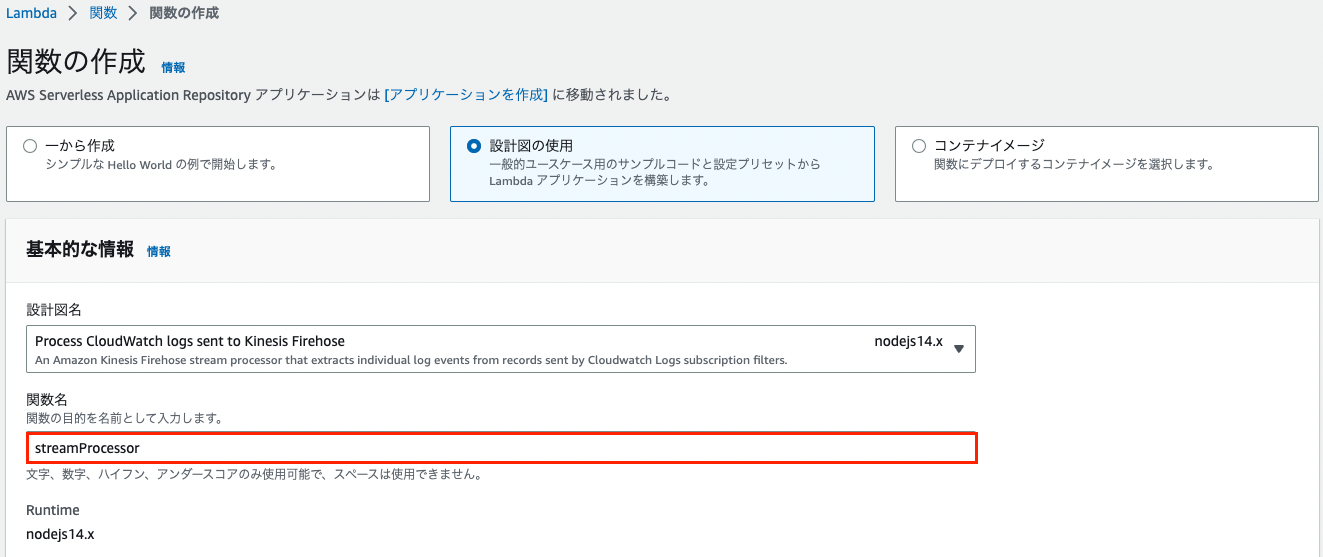

Lamdaがデータ変換を完了する前にタイムアウトが発生しないようにするために、上記で作成したLamdaの以下の項目を画像の通り1分に修正します。
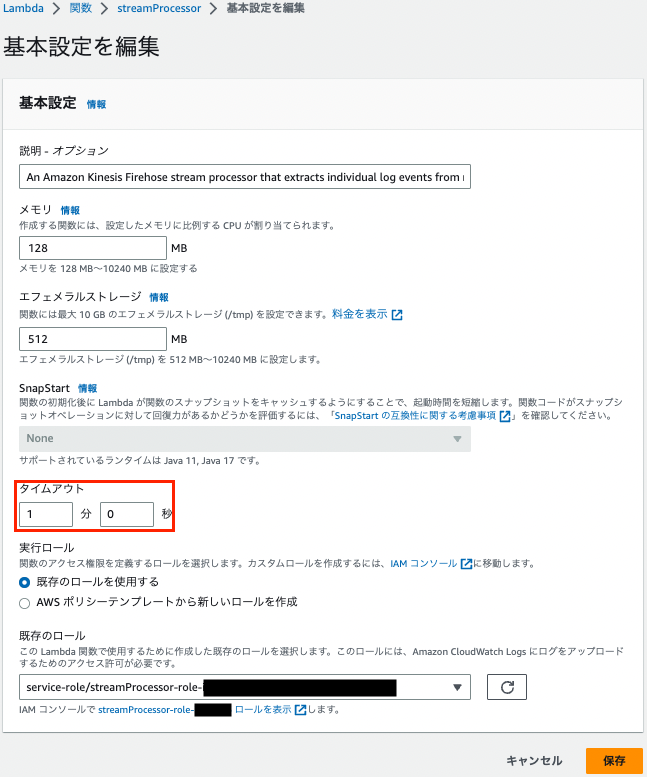
s3バケット > kinesis-data-bucket-sample > 選択
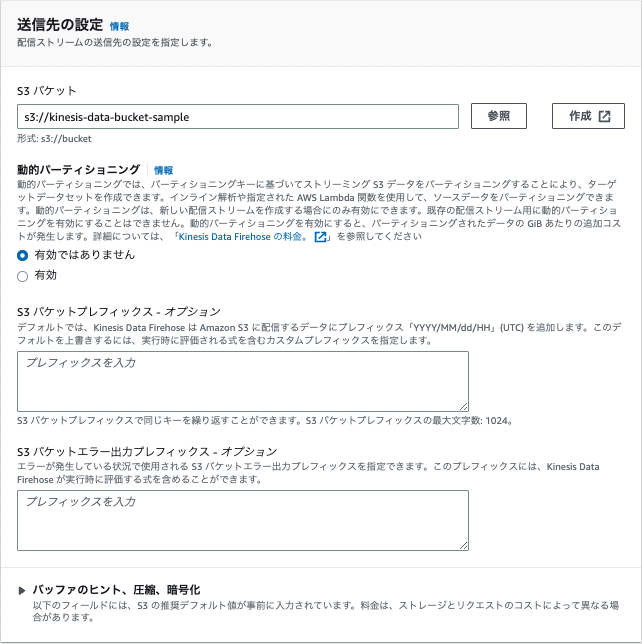
以後はデフォルトの設定で問題ありません。配信ストリームを作成を選択して完了です。
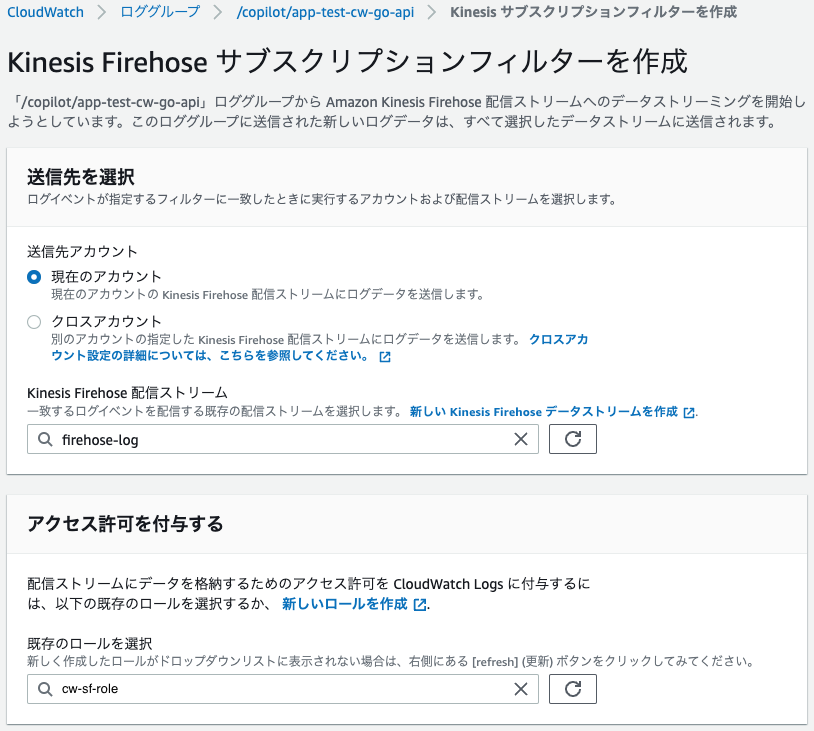
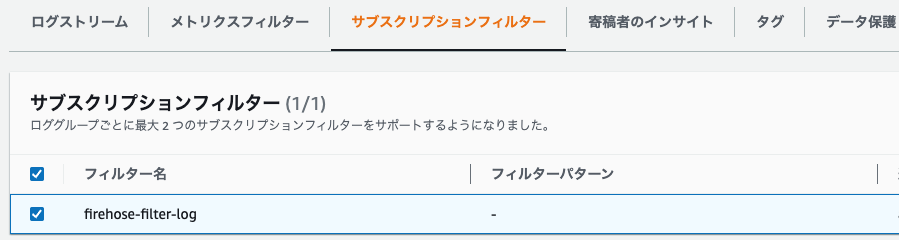
(2)Cloud Watch サブスクリプションフィルターの設定
マネジメントコンソール > ロググループ > /copilot/app-test-cw-go-api > サブスクリプションフィルター > Kinesis Firehose サブスクリプションフィルターを作成 > 以下の項目を入力 > ストリーミングを開始
| 項目 | 値 |
|---|---|
| 送信先アカウント | 現在のアカウント |
| Kinesis Firehose 配信ストリーム | firehose-log |
| 既存のロールを選択 | cw-sf-role |
| ログの形式 | json |
| サブスクリプションフィルター名 | firehose-filter-log |
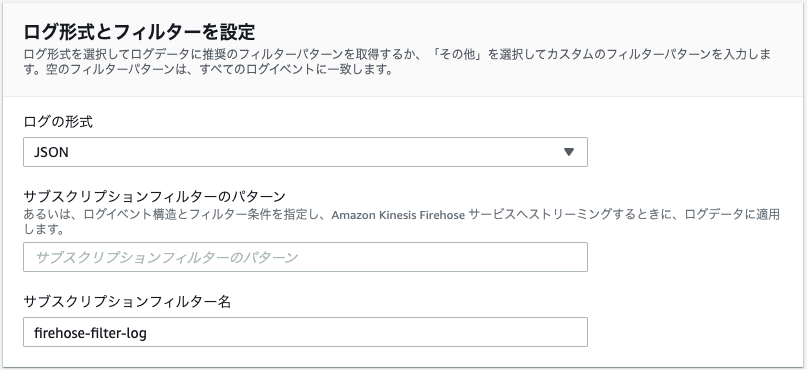
(3)S3にログ転送されることを確認
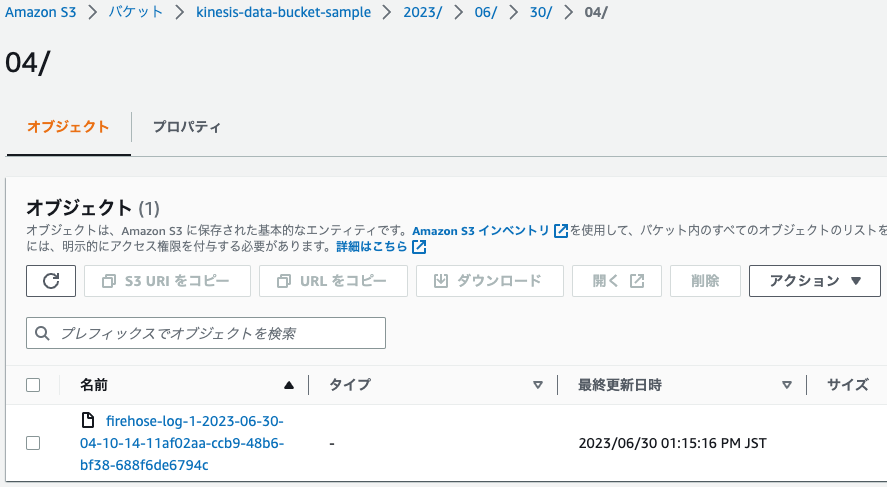
ここで一旦動作確認をしておきます。
# ランダムでエラーを返却
$ for i in {1..100}; do curl -sS http://${新規で作成したDNSから取得}.ap-northeast-1.elb.amazonaws.com/error; sleep 1; done
マネジメントコンソール > S3 > バケット > kinesis-data-bucket-sample > 以下の画像のような階層で格納されます
画面に反映されるまで5分程度かかるので少し待ちます。
(4)Amazon Atena
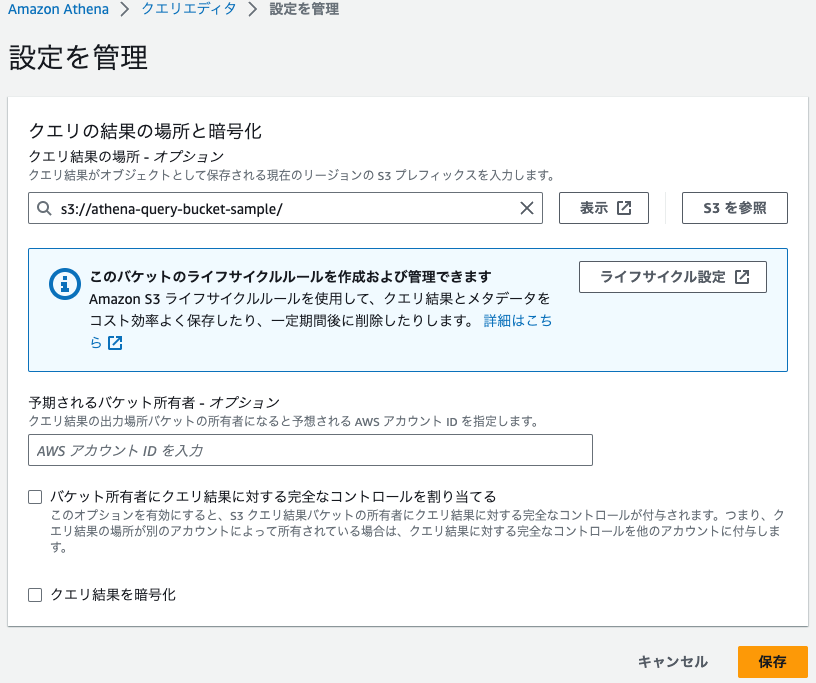
マネジメントコンソール > Amazon Athena > データをクエリする > クエリエディタを起動

設定を管理 > クエリの結果の場所と暗号化 > S3を参照 > 以下を入力
| 項目 | 値 |
|---|---|
| クエリ結果の場所 | athena-query-bucket-sample |
| 項目 | 値 |
|---|---|
| データソース | AwsDataCatalog |
| データベース | default |
テーブルとビュー > データソースからテーブルを作成 > s3バケットデータ
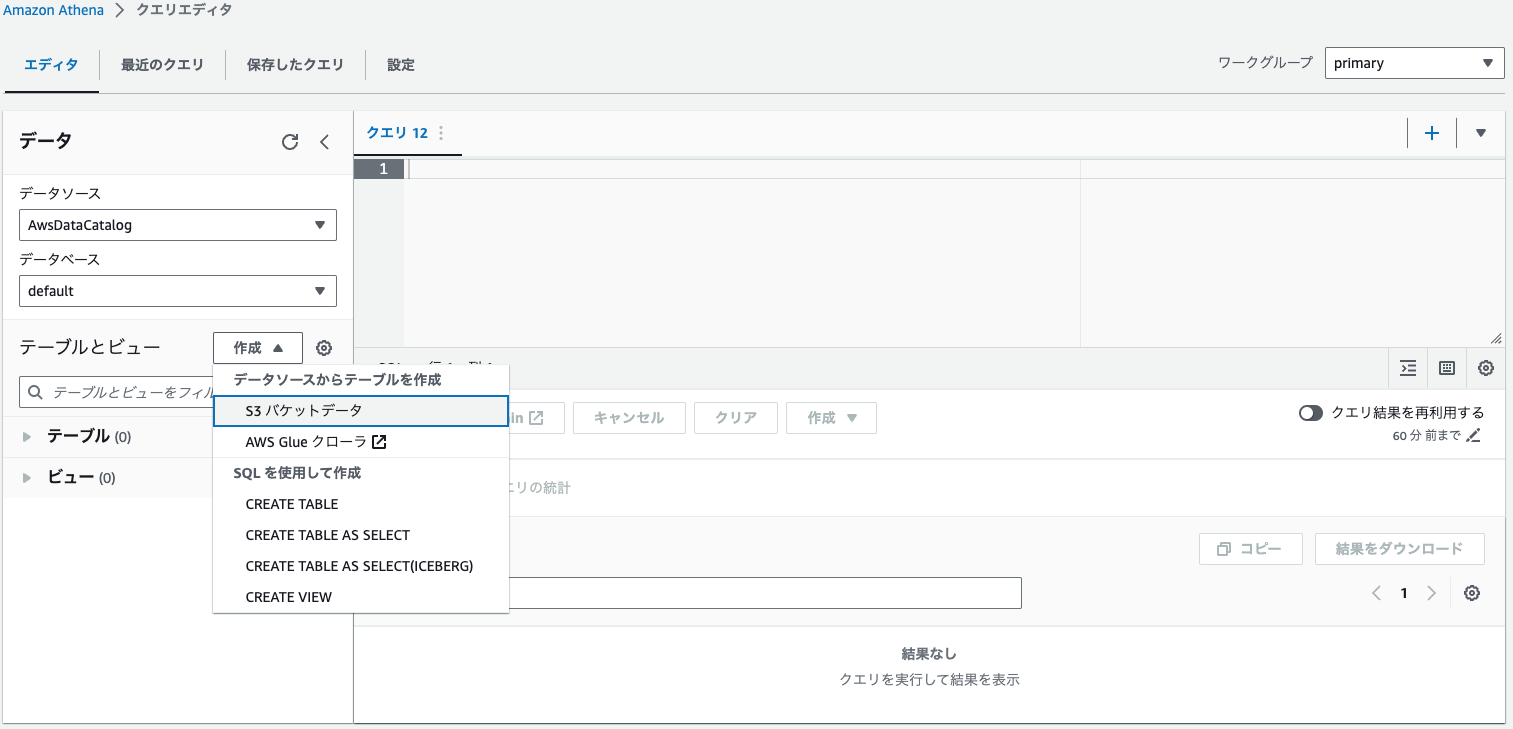
| 項目 | 値 |
|---|---|
| テーブル名 | cw_go_api_table |
| データベース設定 | 既存のデータベースを選択 > default |
| 入力データセットの場所 | kinesis-data-bucket-sample |
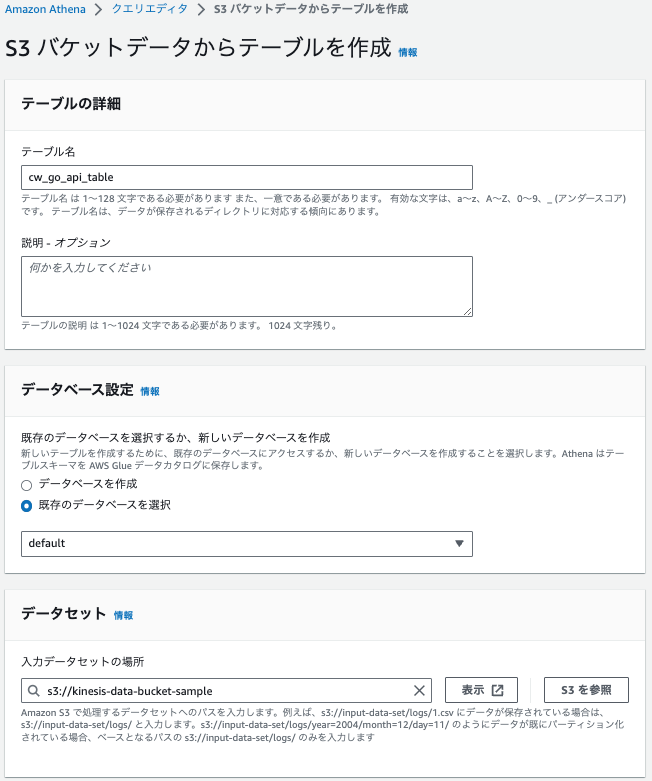
| 項目 | 値 |
|---|---|
| ファイル形式 | JSON |
※上記を設定すると自動的にデフォルト設定が反映されます。特に修正不要です。
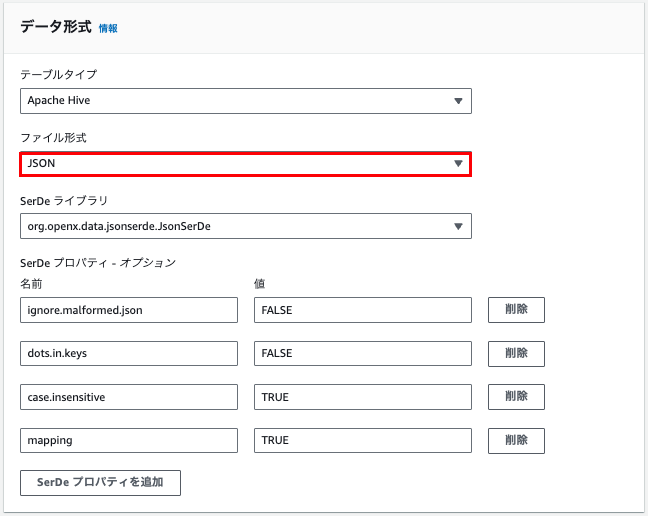
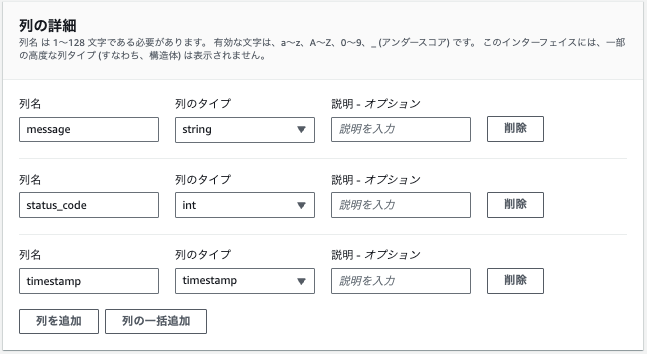
上記で設定すると以下のようなクエリがエディタ上に反映されます。
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`cw_go_api_table` (
`message` string,
`status_code` int,
`timestamp` timestamp
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'ignore.malformed.json' = 'FALSE',
'dots.in.keys' = 'FALSE',
'case.insensitive' = 'TRUE',
'mapping' = 'TRUE'
)
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://kinesis-data-bucket-sample/'
TBLPROPERTIES ('classification' = 'json');
手動設定しましたが、このようにクエリだけでも同様な処理を記述することができます。
(5)クエリ結果
新しいタブを開き以下のクエリを入力します。
select * from cw_go_api_table
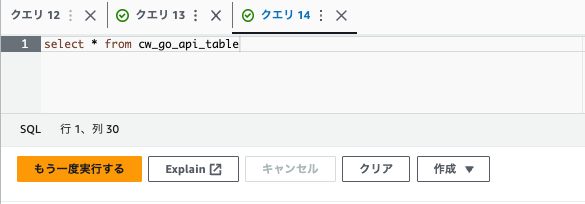
S3に格納されているログが取得できます。
Cloud Watch Agent編
ここからは以下のサンプルアプリを使って進めます。初期設定が完了していない方は、以下のリポジトリのREADME.mdを参考にしながら設定をお願いします。
例1:EC2上で稼働しているNginxのメトリクスとログを個別に作成してモニタリングする
(1)Cloud Watch Agentの設定ファイル確認
README.mdの中で以下のコマンドを実行したかと思います。こちらのコマンドはSystems ParameterにCloud Watch Agentの設定ファイルを格納しております。
$ aws ssm put-parameter --name "/config/cw-agent" --type "String" --value "$(cat cw-agent.json)"
この設定ファイル内で、メトリクスの名前空間/メトリクス名/ディメンション、ログに関してはロググループ/ログストリームを指定しています。
{
"agent": {
"run_as_user": "cwagent"
},
"metrics": {
"aggregation_dimensions": [
[
"InstanceId"
]
],
"append_dimensions": {
"InstanceId": "${aws:InstanceId}"
},
"namespace": "ec2-instance",
"metrics_collected": {
"mem": {
"measurement": [
"mem_used_percent"
],
"metrics_collection_interval": 60
}
}
},
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/nginx/access.log",
"log_group_name": "/web/nginx_access_log",
"log_stream_name": "{instance_id}",
"timestamp_format": "%d/%b/%Y:%H:%M:%S %z",
"timezone": "Local"
}
]
}
}
}
}
(2)Cloud Watch Agentのインストール
(1)で設定ファイルをSystems ManagerのParameter Storeに格納できました。そこで、次はEC2内にCloud Watch Agentをインストールしていきます。
まずはじめに、EC2のIPアドレスをコピーしておきます。
マネージメントコンソール > EC2 > 該当のEC2インスタンスを選択 > Elastic IPアドレス > コピー
以下のコマンドを実行します。
# EC2インスタンスにSSHで接続します。'access-key.pem'は秘密鍵ファイルで、ec2-userはデフォルトのユーザー名です。
$ ssh -i ~/.ssh/access-key.pem ec2-user@<上記でコピーしたIPアドレス>
# Amazon CloudWatch Agentをインストールします。
$ sudo yum install -y amazon-cloudwatch-agent
# Amazon CloudWatch Agentの設定をAWS Systems Manager Parameter Storeから取得し、エージェントを開始します。
# -a fetch-config: 設定を取得する
# -m ec2: EC2インスタンス上で動作していることを指定
# -c ssm:/config/cw-agent: Parameter Storeのパスを指定して設定を取得
# -s: エージェントを開始
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c ssm:/config/cw-agent -s
(3)該当EC2にリクエストをする
# ランダムでエラーを返却
$ for i in {1..10}; do curl -sS http://${上記で取得したIPアドレス}; sleep 1; done
(4)Cloud Watch上で結果を確認
CloudWatch > Metrics > すべて > ec2-instance > InstanceId >
ec2-dev-ec2-bastion
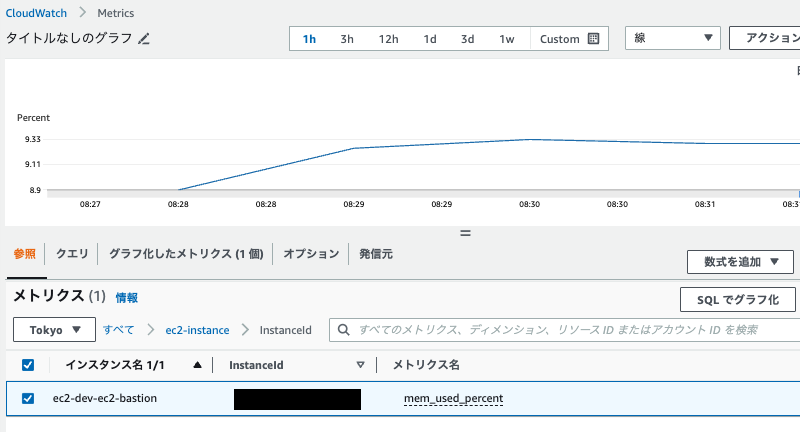 メトリクスが出力されていることが確認できます。続いてログも確認してみます。
メトリクスが出力されていることが確認できます。続いてログも確認してみます。
CloudWatch > ロググループ > /web/nginx_access_log > ログストリーム
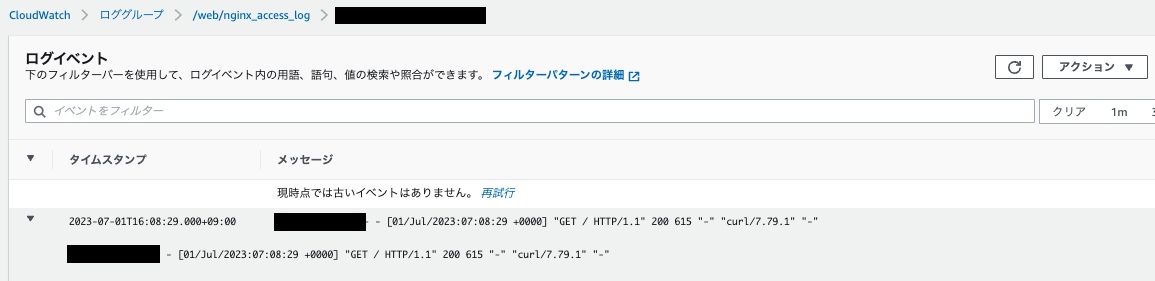 ログが出力されていることが確認できます。
ログが出力されていることが確認できます。
リソースの削除
今回のハンズオンで利用した各種リソースを削除していきます。放置したままだと料金が発生するため個人アカウント等で利用している方はご対応ください。
削除方法は各リポジトリのREADME.meをご確認ください。
参考にした資料
本記事は以下の"AWS BlackBelt 2023 Amazon CloudWatchの概要と基本"をメインに参考にさせて頂きました。その他にも、非常に勉強になった書物がいくつかあるのでこの場を借りてご紹介させていただきます。