概要
時代の流れもあり、自分もどっかでAmazonRekognition触ってみたい、という欲求があったので、触ってみました。題材は少年時代の思い出「遊戯王」。我ながらちょうどよいテーマで思いついたものだなと思います。
つくったもの
- LINEに画像を投げると、それが遊戯王カードの画像かどうかを学習モデルが回答してくれるBOT(以下、期間限定公開中)
構成環境
- フロントはLINE公式アカウント
- リクエストの受付はAPI Gateway → Lambda
- 画像保存はS3
- 画像判定の学習モデルはAmazonRekognition
という構成でやっとります(きれいな図で表現したかった)。
実装した流れ
-
LINEアカウント上で画像をアップロード
- ユーザーがLINEボットに画像を送信
-
画像をS3にアップロード
- 受信した画像をAWS S3バケットに保存
-
S3に画像がアップロードされたらLambdaをトリガー
- S3のイベント通知機能で、画像アップロード時にLambda関数を起動
-
Lambdaで画像を解析
- 画像が遊戯王カードかどうかを判定し、画像内の文字列を読み取る
-
結果をLINEアカウントに返信
- 判定結果をユーザーに返信
実装の各詳細
1. LINEアカウントの設定
a. LINE Developersコンソールでチャネル作成
- LINE Developersにアクセスし、アカウントを作成またはログイン
- 新しいMessaging APIチャネルを作成
- チャンネル名、説明、アイコンなどを設定
- チャンネルアクセストークンをメモ
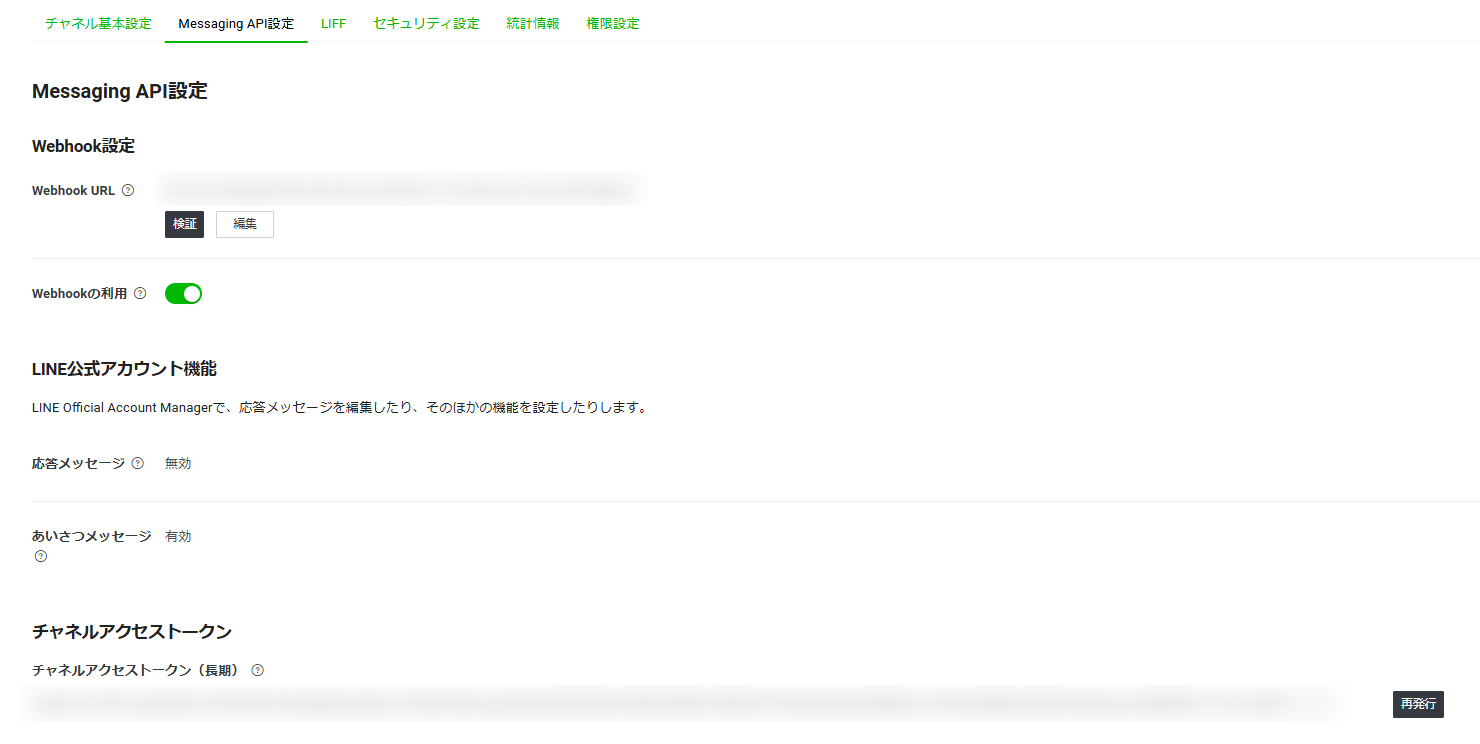
b. Webhookの設定
- Messaging API設定で、Webhook送信を「利用する」に設定
- Webhook URLを後ほど設定(API Gatewayのエンドポイントが必要)
2. AWS LambdaでWebhookエンドポイントを作成
a. Lambda関数の作成(Webhook受信)
AWS Lambdaで新しい関数を作成
- 関数名:
LineWebhookHandler - ランタイム:Python 3.8、Node.jsなどから選択
- LINEからのWebhookイベントを受信し、画像メッセージの場合は画像データを取得し、一時的に保存
- LINEユーザーの
userIdを取得し、S3にアップロード時のメタデータとして保存する
i. LineWebhookHandler
import os
import json
import boto3
import urllib.request
from botocore.exceptions import ClientError
# LINE Messaging API
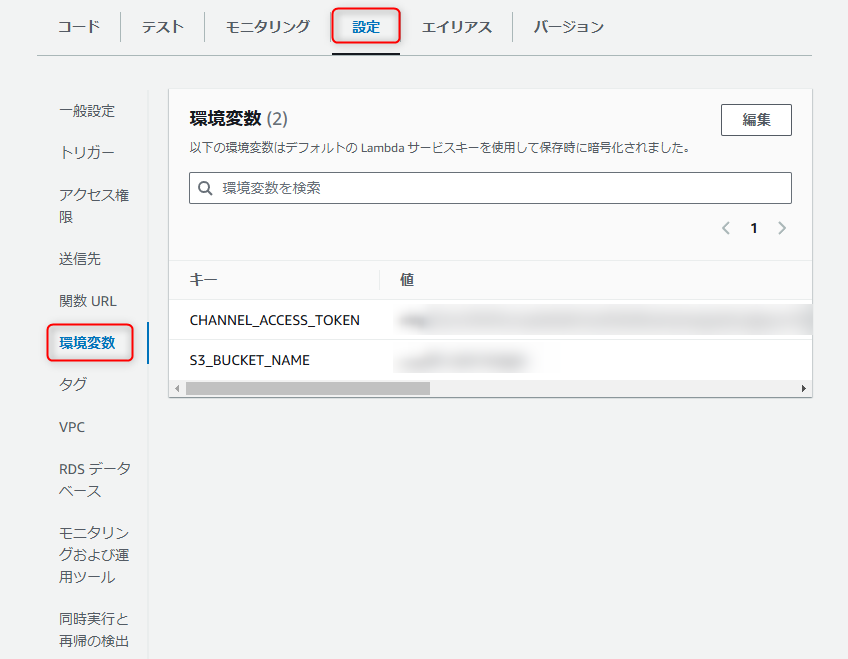
LINE_CHANNEL_ACCESS_TOKEN = os.environ.get('CHANNEL_ACCESS_TOKEN', '')
# S3 Bucket Name
S3_BUCKET_NAME = os.environ.get('S3_BUCKET_NAME', '')
# Initialize S3 client
s3_client = boto3.client('s3')
def lambda_handler(event, context):
print("Event:", event)
# 環境変数の確認
if not LINE_CHANNEL_ACCESS_TOKEN:
print("Error: LINE_CHANNEL_ACCESS_TOKEN is not set")
return {
'statusCode': 500,
'body': json.dumps({'message': 'Server configuration error'})
}
if not S3_BUCKET_NAME:
print("Error: S3_BUCKET_NAME is not set")
return {
'statusCode': 500,
'body': json.dumps({'message': 'Server configuration error'})
}
# イベントデータの取得(API Gateway経由の場合)
if 'body' in event:
event_body = json.loads(event['body'])
else:
event_body = event
# イベントの存在確認
if 'events' not in event_body or len(event_body['events']) == 0:
print("No events to process")
return {
'statusCode': 200,
'body': json.dumps({'message': 'No events to process'})
}
# 各イベントを処理
for event_data in event_body['events']:
if event_data.get('type') == 'message' and event_data.get('message', {}).get('type') == 'image':
user_id = event_data['source'].get('userId', 'UnknownUser')
message_id = event_data['message'].get('id', 'UnknownMessageId')
print(f"Processing image message from user: {user_id}, message_id: {message_id}")
# LINEから画像データを取得
image_content = get_image_content(message_id)
if image_content:
file_name = f"{message_id}.jpg"
# S3に画像をアップロード(ユーザーIDをメタデータとして保存)
upload_success = upload_image_to_s3(image_content, file_name, user_id)
if upload_success:
print(f"Image successfully uploaded to S3: {file_name}")
else:
print("Failed to upload image to S3")
else:
print("Failed to retrieve image content from LINE")
else:
print("Event is not an image message")
return {
'statusCode': 200,
'body': json.dumps({'message': 'Processing completed'})
}
def get_image_content(message_id):
try:
url = f"https://api-data.line.me/v2/bot/message/{message_id}/content"
req = urllib.request.Request(url)
req.add_header('Authorization', f'Bearer {LINE_CHANNEL_ACCESS_TOKEN}')
with urllib.request.urlopen(req) as response:
content = response.read()
return content
except Exception as e:
print(f"Error getting image content: {e}")
return None
def upload_image_to_s3(image_content, file_name, user_id):
if not S3_BUCKET_NAME:
print("Error: S3_BUCKET_NAME is not set")
return False
try:
s3_client.put_object(
Bucket=S3_BUCKET_NAME,
Key=file_name,
Body=image_content,
ContentType='image/jpeg',
Metadata={'userId': user_id}
)
return True
except ClientError as e:
print(f"Error uploading image to S3: {e}")
return False
ⅱ. Lambda関数の環境変数
スクリプト内で使用する環境変数も指定必要。
b. API Gatewayの設定
- AWSマネジメントコンソールでAPI Gatewayサービスを開き、新しいREST APIを作成
- API名を入力(例:「LineWebhookAPI」)
- リソースとメソッドを設定
- リソースパス:
/callback - メソッド:
POST
- リソースパス:
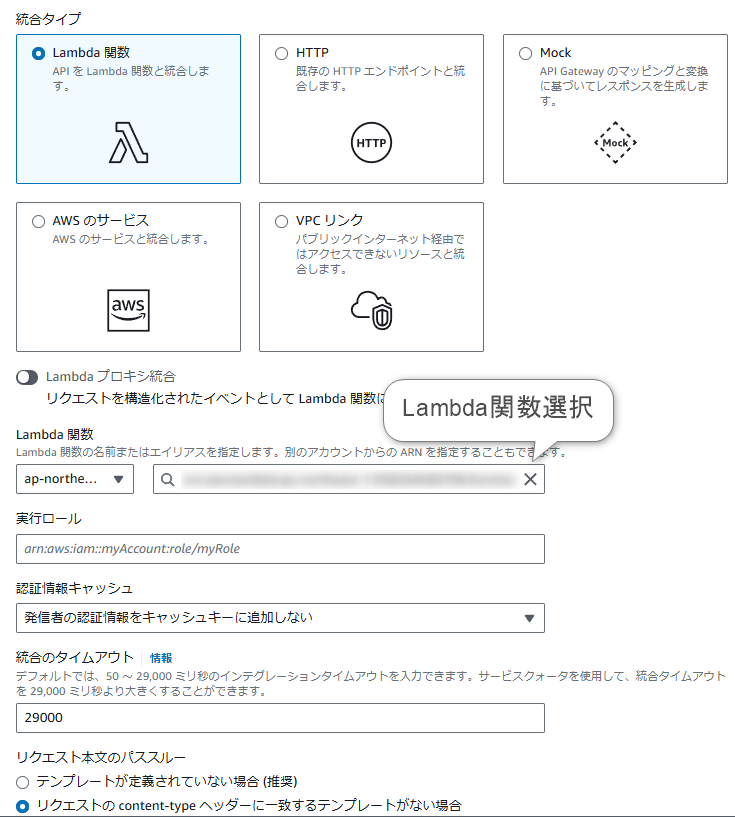
c. API GatewayとLambdaの統合
- API Gatewayのメソッド統合タイプを「Lambda関数」に設定し、
LineWebhookHandlerを指定 - デプロイしてAPIのエンドポイントURLを取得
d. LINE DevelopersコンソールでWebhook URLを設定
- API GatewayのエンドポイントURLをWebhook URLに設定(例:
https://{api-id}.execute-api.{region}.amazonaws.com/prod/callback)
ⅲ. IAM権限の設定内容
S3へのオブジェクト設置を可能にするため、Lambda関数に権限ロールを作成して設定。
ここから

ここで作成
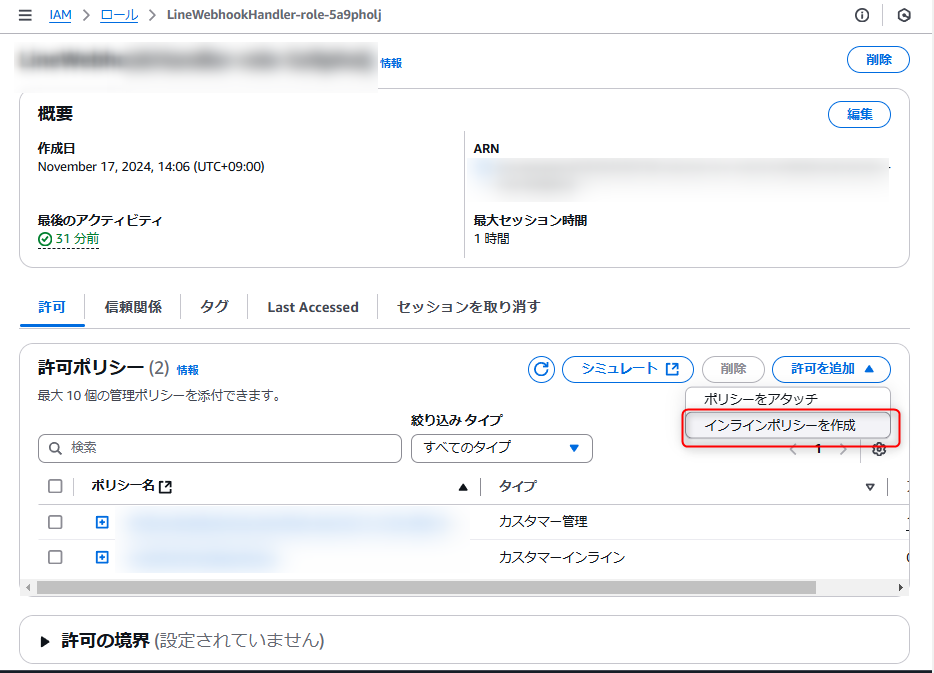
JSONで作成するので記載は以下。
(バケット名は次で作成するものを設置)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::(バケット名記載)/*"
}
]
}
3. 画像をS3にアップロード
ここまででうまくいけばLINEアカウントで画像送信→S3にアップロードできるようになる。
a. S3バケットの作成
- AWS S3で新しいバケットを作成
- バケット名:
yugioh-card-images(ユニークな名前を付ける必要あり) - アクセス許可やバージョニングを必要に応じて設定(基本デフォルトでOK)
- バケット名:
b. S3のバケットポリシーでLambda関数からのアクセスを許可
- 以下から設定を変更

- 設定内容
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "(Lambda関数に設定されたIAMロールのARNを記載)"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::(S3のバケット名)/*"
}
]
}
c. Lambda関数で画像をS3に保存
-
LineWebhookHandler関数内で受信した画像データをS3バケットにアップロード - AWS SDKを使用して
PutObject操作を実行 - 画像ファイル名には一意のキー(例:タイムスタンプやUUID)を使用
4. S3でイベント通知を設定
a. S3イベントの設定
- S3バケットのプロパティでイベント通知を設定
- イベントタイプ:
PUT(オブジェクトの作成) - プレフィックス/サフィックスを必要に応じて設定(例:特定のフォルダのみ監視)
- 送信先:Lambda関数を選択
- Lambda関数:
ImageProcessingFunction(次のステップで作成)
- イベントタイプ:
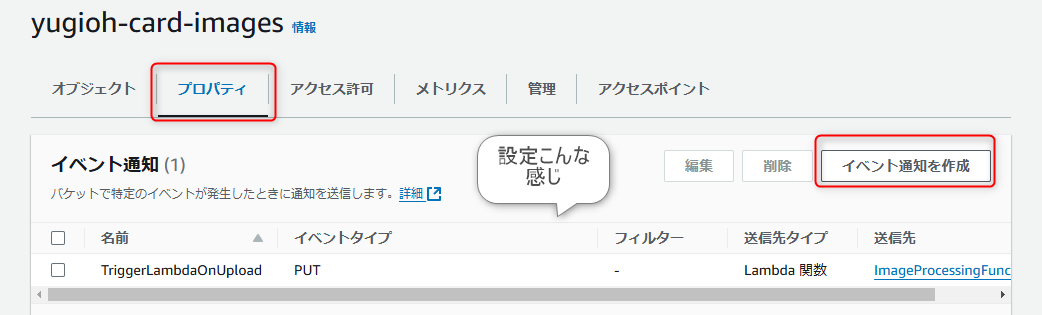
5. 画像を処理するLambda関数
a. Lambda関数の作成(画像解析)
- 新しいLambda関数を作成
- 関数名:
ImageProcessingFunction - ランタイム:Python 3.8、Node.jsなど
- 関数名:
i. ImageProcessingFunction
※実際は、以下に加えてrequestsをimport用に取得したzipファイルをアップロードしています。
import boto3
import json
import os
import requests
# Initialize AWS clients
s3_client = boto3.client('s3')
rekognition_client = boto3.client('rekognition')
textract_client = boto3.client('textract')
# LINE Messaging API
LINE_CHANNEL_ACCESS_TOKEN = os.environ.get('CHANNEL_ACCESS_TOKEN', '')
def lambda_handler(event, context):
print("Event:", event)
# 環境変数の確認
if not LINE_CHANNEL_ACCESS_TOKEN:
print("Error: LINE_CHANNEL_ACCESS_TOKEN is not set")
return {
"statusCode": 500,
"body": "CHANNEL_ACCESS_TOKEN is not set"
}
# イベントの構造を確認
if "Records" not in event:
print("Error: 'Records' key is missing in the event object")
return {
"statusCode": 400,
"body": "Invalid event format: 'Records' key is missing"
}
# S3イベント情報を処理
for record in event['Records']:
try:
bucket_name = record['s3']['bucket']['name']
object_key = record['s3']['object']['key']
print(f"Processing file {object_key} from bucket {bucket_name}")
# S3から画像を取得
image_content, user_id = get_image_from_s3(bucket_name, object_key)
if image_content and user_id:
# 画像が遊戯王カードか判定
is_yugioh_card = analyze_with_rekognition(image_content)
# 画像内の文字列を抽出
extracted_text = extract_text_from_image(image_content)
# ユーザーに結果を送信
send_message_to_user(user_id, is_yugioh_card, extracted_text)
else:
print("Failed to retrieve image content or user ID from S3")
except KeyError as e:
print(f"Error processing record: {e}")
return {
"statusCode": 400,
"body": f"Invalid record format: {e}"
}
return {
"statusCode": 200,
"body": "Processing completed"
}
def get_image_from_s3(bucket, key):
try:
response = s3_client.get_object(Bucket=bucket, Key=key)
image_content = response['Body'].read()
user_id = response['Metadata'].get('userid', '')
return image_content, user_id
except Exception as e:
print(f"Error getting object from S3: {e}")
return None, None
def analyze_with_rekognition(image_content):
try:
print("Starting Rekognition analysis...")
response = rekognition_client.detect_custom_labels(
ProjectVersionArn=os.environ['REKOGNITION_MODEL_ARN'],
Image={'Bytes': image_content}
)
print("Rekognition response:", response)
labels = response['CustomLabels']
for label in labels:
if label['Name'] == 'YugiohCard' and label['Confidence'] > 80:
return True
return False
except Exception as e:
print(f"Error analyzing with Rekognition: {e}")
return False
def extract_text_from_image(image_content):
try:
response = textract_client.detect_document_text(
Document={'Bytes': image_content}
)
text = ''
for block in response['Blocks']:
if block['BlockType'] == 'LINE':
text += block['Text'] + '\n'
return text
except Exception as e:
print(f"Error extracting text: {e}")
return ''
def send_message_to_user(user_id, is_yugioh_card, extracted_text):
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {LINE_CHANNEL_ACCESS_TOKEN}'
}
if is_yugioh_card:
# message_text = 'これは遊戯王カードです。\n\n検出されたテキスト:\n' + extracted_text
message_text = 'これは遊戯王カードです。'
else:
message_text = 'これは遊戯王カードではありません。'
data = {
'to': user_id,
'messages': [
{
'type': 'text',
'text': message_text
}
]
}
try:
response = requests.post(
'https://api.line.me/v2/bot/message/push',
headers=headers,
data=json.dumps(data)
)
if response.status_code != 200:
print(f"Failed to send message: {response.text}")
else:
print("Message sent successfully")
except Exception as e:
print(f"Error sending message: {e}")
def check_rekognition_model_status():
try:
response = rekognition_client.describe_project_versions(
ProjectArn=os.environ['REKOGNITION_PROJECT_ARN']
)
for version in response['ProjectVersionDescriptions']:
if version['Status'] == 'RUNNING':
return True
return False
except Exception as e:
print(f"Error checking Rekognition model status: {e}")
return False
def test_textract_connection():
try:
response = textract_client.get_document_text_detection(
JobId='dummy-job-id' # 無効なJobIdを指定しても接続確認に利用可能
)
print("Textract connection successful:", response)
except Exception as e:
print(f"Textract connection test failed: {e}")
ⅱ. 環境変数を設定
- Lambda関数内で利用している「REKOGNITION_PROJECT_ARN」を環境変数として設定
- Lambda関数内で利用している「LINE_CHANNEL_ACCESS_TOKEN」を環境変数として設定※後述取得
ⅲ. IAMロールに権限設定
- 必要な権限を設定
- IAMロールにS3やRekognition、Textractへのアクセス許可を付与(設定方法は先のLambda関数と一緒)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::(画像参照のバケット名)/*"
},
{
"Effect": "Allow",
"Action": "rekognition:DetectCustomLabels",
"Resource": "(RekognitionのモデルのARN ※後述)"
},
{
"Effect": "Allow",
"Action": "textract:DetectDocumentText",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "ssm:GetParameter",
"Resource": "(SSM登録してあるLINEのチャンネルアクセストークンのARN)"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
6. 画像が遊戯王カードかどうかを判定
a. 学習用データを登録するS3バケットを作成
ⅰ. バケットを作成し、バケットポリシーを設定
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AWSRekognitionS3AclBucketRead20191011",
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com"
},
"Action": [
"s3:GetBucketAcl",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::(データセット用のバケット名)"
},
{
"Sid": "AWSRekognitionS3GetBucket20191011",
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:GetObjectAcl",
"s3:GetObjectVersion",
"s3:GetObjectTagging"
],
"Resource": "arn:aws:s3:::(データセット用のバケット名)/*"
},
{
"Sid": "AWSRekognitionS3ACLBucketWrite20191011",
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::(データセット用のバケット名)"
},
{
"Sid": "AWSRekognitionS3PutObject20191011",
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::(データセット用のバケット名)/*",
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control"
}
}
}
]
}
ⅱ. トレーニング用・テスト用の画像を登録するディレクトリを配下に作成。
-
train/
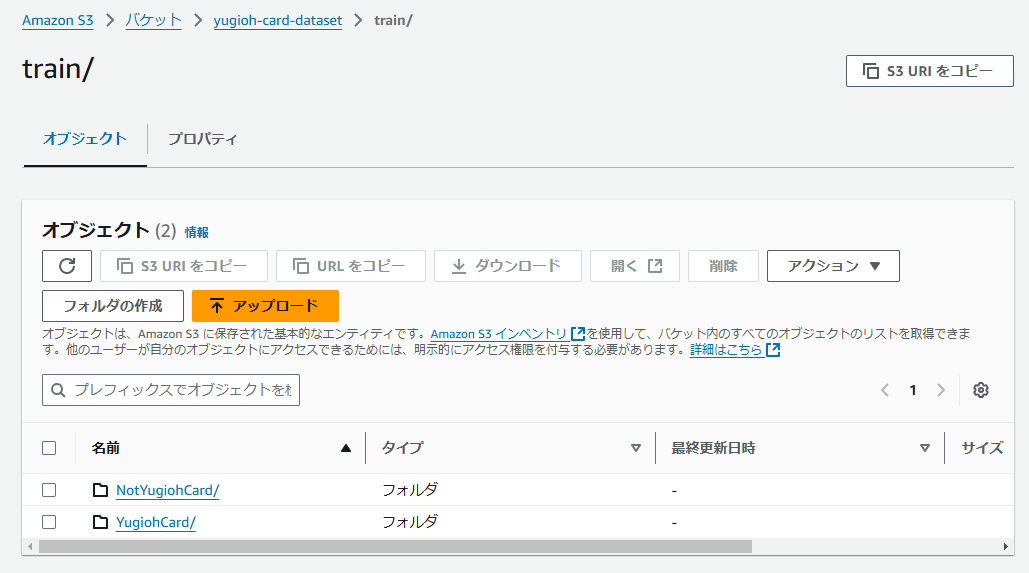
-
test

ⅲ. トレーニング用・テスト用にそれぞれ8:2ぐらいの比率でサンプルファイルをアップロードする
b. Amazon Rekognitionカスタムラベルの設定
- Amazon Rekognition Custom Labelsを使用して遊戯王カードのモデルを作成
- 遊戯王カードの画像と、それ以外のカードや画像を用意してトレーニングデータセットを作成
- モデルをトレーニングし、デプロイ
- プロジェクト作成
こっから入って基本流れに沿う感じで行けます。
途中ある「自動ラベル付け」にチェックを入れてやるとスムーズ。

c. Lambda関数でモデルを呼び出す
- Rekognitionの
DetectCustomLabelsAPIを使用して、画像が遊戯王カードかどうかを判定 - 信頼度(Confidence)をチェックし、閾値を超える場合は「遊戯王カード」と判断
7. 送信して動作確認!
うまくいけばこんな感じに動作確認できる…はず!!!
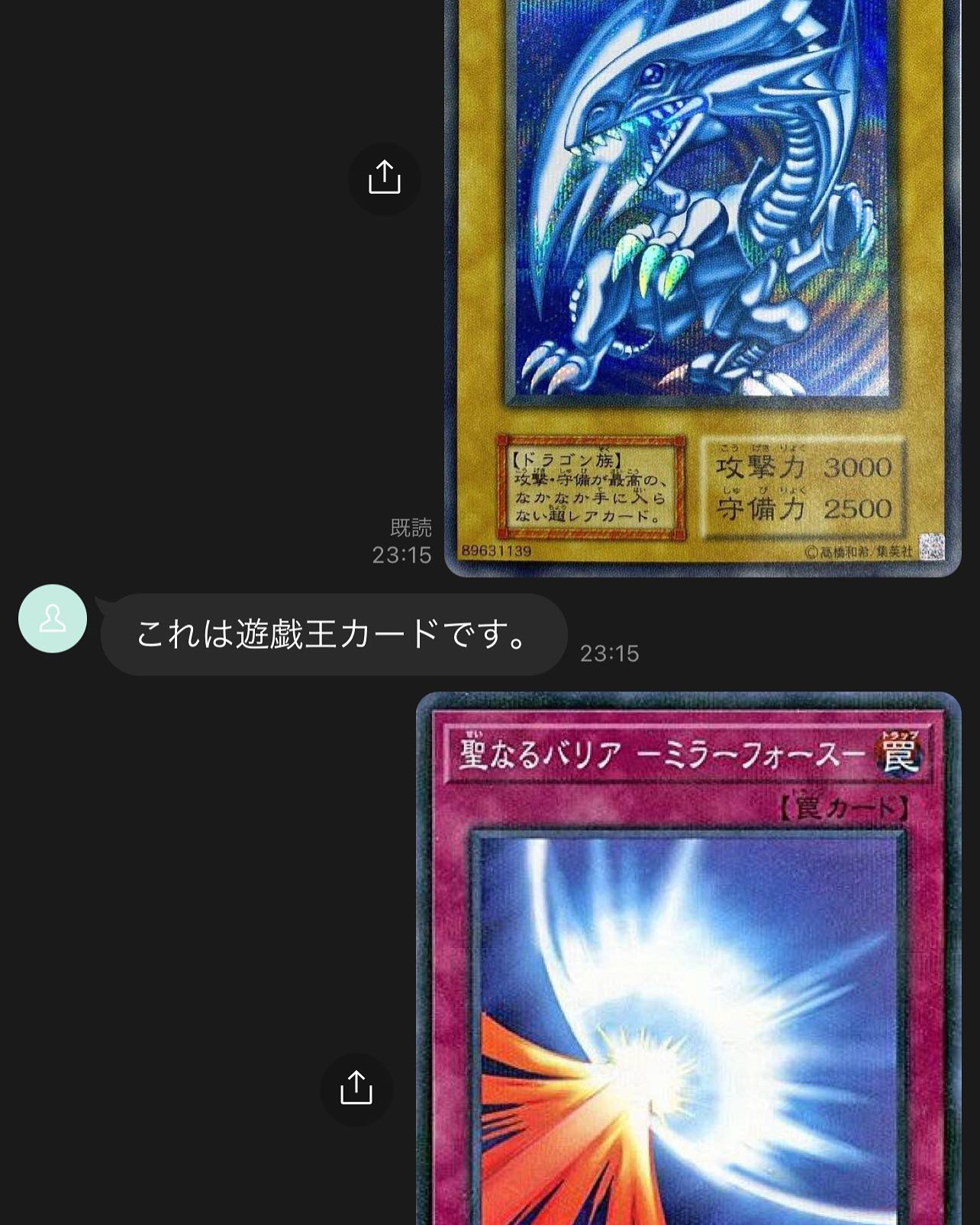
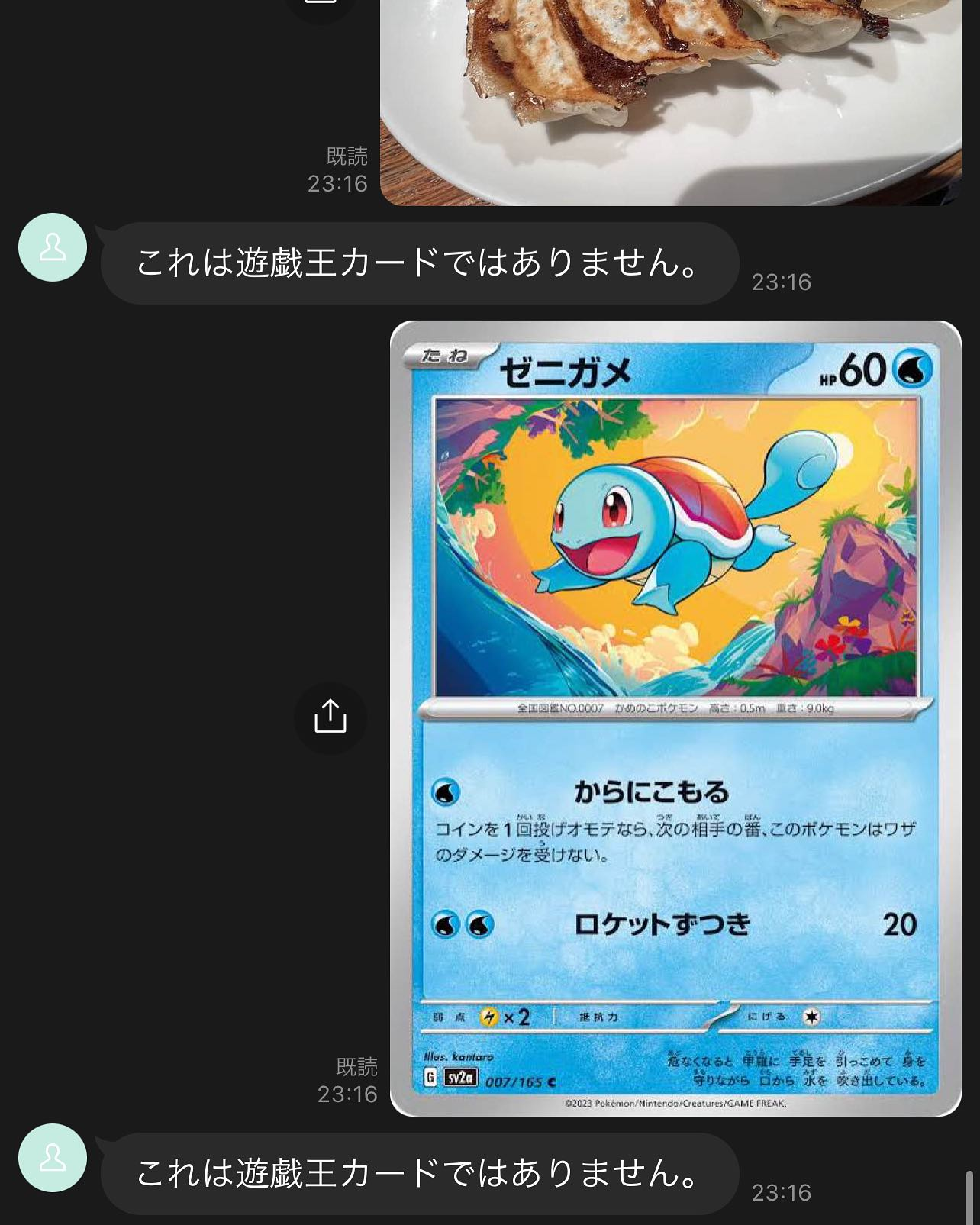
振り返り
KPT
-
Keep(よかった):
- 実際に5時間くらいで動くものにたどり着けたこと
- ChatGPTに相談したとはいえ、相談がまあまあ上手にうまくできた(骨子を質問→枝葉を質問、に砕いていく)
- Lambdaのログを確認しながらスクリプトや接続の動作確認ができたことは効率よかった
-
Problem(改善したいこと):
- 試行錯誤の跡を振り返りながらまとめたので、手樹が前後してしまいました。ごめんなさい
- あと同じ理由でおそらく上記では実現しない恐れがありますが、その点もご配慮ください(ご指摘あれば直します)
-
Try(次に挑戦すること):
- 次というか、ユーザー情報を保存したりだとか、チャット情報を保存したりとかはやりたい
- 学習モデルをもう少しちゃんとした量のデータセットで作り直したい
- IAM周りはGPT相談でなく、自分で設定しながらやりたい
- Lambda記載のfunctionはリファクタリングしたい
ただの感想
- AWS周りでやはり詰まったり不安に見舞われるのはIAM周りなので、そこを繰り返しやって克服すると幅が広がる気がする
- 1週間後に設定した学習モデルを終了し忘れないように気を付けないとコストがかさむ
- 次はメンバーに自信をつけられるハンズオン形式でやらせよう
- 学生さんとも勉強会的にやってみたい
おわり
フリーに自己責任でできる日曜大工もよいものです。
後日談
Qiitaのアドベントカレンダー用に、後日談で本当にあった怖い話を追記。
サンプルで作成したLINEアカウントを、意気揚々と翌日知り合いにひけらかしていました。
そういえば、Recognitionていったい費用いくらなんだ?と思い至り、CostExplorerを開き愕然。
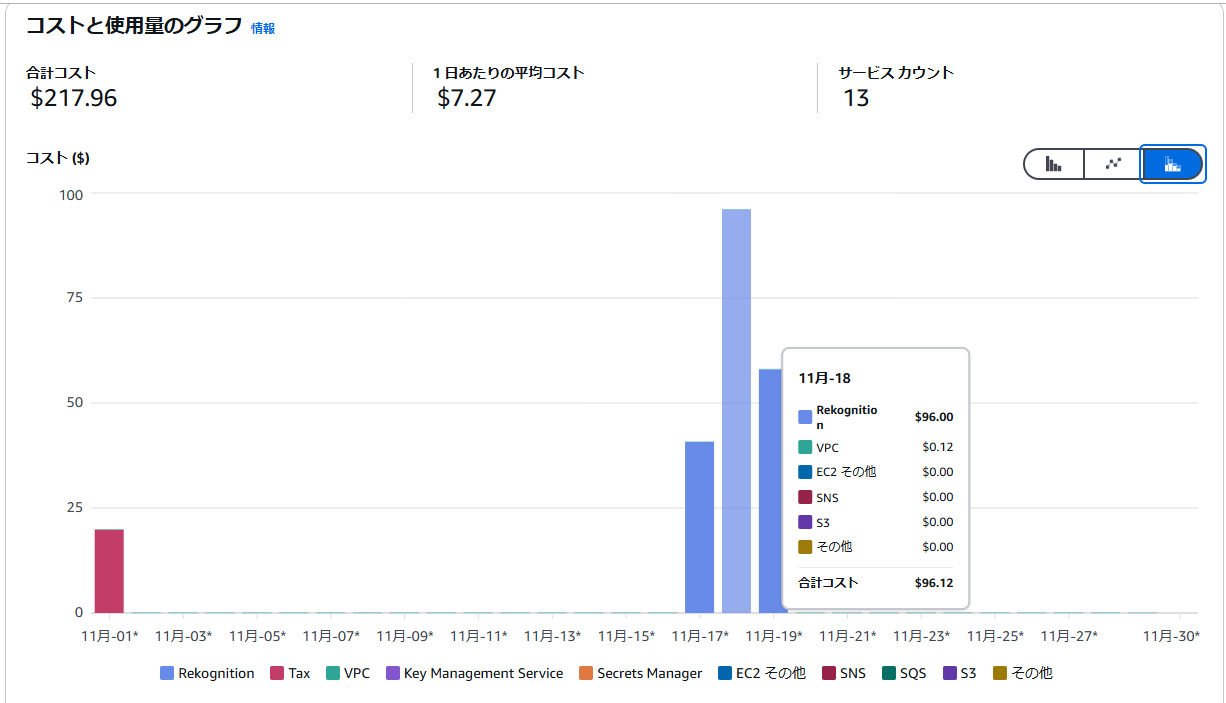
「1日96ドル(約1.4万円)!!!???(1日半動かし続けていたので合計200ドル(約3万円))」
大慌てで停止しました。動作しなくてもモデルが稼働しているだけでそれなりの費用が発生するRecognition…。大変面白いのですが、皆さんも遊ぶときはくれぐれもご注意ください。