Increments × cyma (Ateam Inc.) Advent Calendar 2020 の19日目は、
Increments株式会社の @WakameSun が担当します!
はじめに
- 会議や講演の音声をそのまま文字に起こして、Qiita Teamへ記事投稿することろまで自動でできると嬉しいよねという話を上司と行っていました。
- 今回はその機能を実際に製品に実装するための調査も兼ねて、Azure Cognitive ServicesのSpeech to TextとQiita APIで作ってみることにしました。
- ソースコードの全容はGitHubにアップロードしています。
構成
今回はコマンドでpython main.py (音声ファイルのパス)で実行すると記事が投稿されるようにするところまでをゴールとします。
アクセストークンなどの設定は.envに書いて、settings.pyを読み込むことで利用できるようにしました(主旨から外れるのでソースコード参照)。
まずSpeech to Textで音声ファイルから文字起こしをした後、それを記事の本文としてQiita Teamに投稿します。
各種設定
Azure側の設定
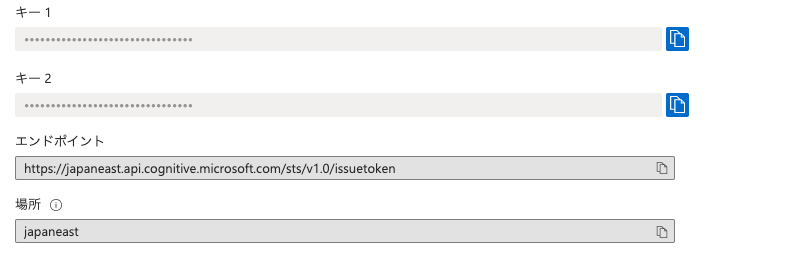
Azureのアカウントを作成後、Azure Cognitive ServicesのSpeech to Textで書き起こしをしてみよう - Qiitaを参考にプロジェクトを作りましょう。その後、プロジェクトの「キーとエンドポイント」の画面から、キー1の値を.envのSUBSCRIPTIONに、場所の値を.envのREGIONにコピペしましょう。
Qiita APIの設定
- https://qiita.com/settings/tokens/new もしくは https://my.qiita.com/settings/team_applications から個人用アクセストークンを作成します。(前者はQiita、後者はAPIを利用するQiita Teamのチームへのログインが必要です。)
- スコープはwrite_qiita_teamに必ずチェックを入れるようにしてください。
- SSOを導入しているチームはチーム別アクセストークンから作成する必要があります。また、個人用アクセストークンを利用する場合オーナーに設定を変えてもらう必要がある可能性があります。
- ※(詳細はAPIを利用するためのチーム別アクセストークンの設定参照)
- 作成したアクセストークンのトークンは.envのACCESS_TOKENにコピペしてください。
- ※下の画像の黒塗りした部分がトークンです。
- 最後に利用するチームのドメイン名を.envのTEAM_DOMAINに記入しましょう。
ソースコードに関して
この時点でもう基本的な設定は完了しているので、コマンドラインでpython main.py (音声ファイルのパス)を実行すればQiita Teamへ記事を投稿できるはずです。
あとはQiita APIのドキュメントを参考にグループ名やタグの値を変更すればカスタマイズができるため、それで十分という方はここでブラウザバックしていただいても大丈夫です。
Qiitaへの投稿
以下Qiita Teamに投稿する部分のコードを抜粋しています。まずはmain.py。
import sys
import text_to_audio
import qiita_team
if __name__ == '__main__':
audio_file_path = sys.argv[1]
article_body = text_to_audio.get_text(audio_file_path)
qiita_team.post_qiita_team(audio_file_path, article_body)
- コマンドラインから実行するのはmain.pyですが、音声ファイルから文字起こしを行う部分はtext-to-audio.pyのgetText関数、起こした文字を記事として投稿する部分はqiita_team.pyのqiita_team.post_qiita_team関数で定義しています。
次に文字起こしを行うtext-to-audio.py。
音声ファイルからの文字起こし
import azure.cognitiveservices.speech as speechsdk
import time
import re
import settings
# Setting for speech to text
SUBSCRIPTION = settings.SUBSCRIPTION
REGION = settings.REGION
def get_text(filepath):
speech_config = speechsdk.SpeechConfig(subscription=SUBSCRIPTION, region=REGION)
speech_config.speech_recognition_language = 'ja-JP'
audio_input = speechsdk.AudioConfig(filename=filepath)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input)
done = False
text = ''
def stop_cb(evt):
print('CLOSING on {}'.format(evt))
speech_recognizer.stop_continuous_recognition()
nonlocal done
done = True
def split(evt):
st = re.search(r'\".+?\"',str(evt))
new_text = st.group(0).strip('"')
nonlocal text
text = text + '\n' + new_text
speech_recognizer.recognized.connect(split)
speech_recognizer.session_stopped.connect(stop_cb)
speech_recognizer.canceled.connect(stop_cb)
speech_recognizer.start_continuous_recognition()
while not done:
time.sleep(.5)
speech_recognizer.stop_continuous_recognition()
return text
- Microsoft公式の音声変換の概要とAzure Cognitive Service Speech to Text API を調査し、Google Cloud Speech-to-Text APIと比較していくを参考に作成しました。
- 今回はテキストをコマンドラインに出力するのではなく、一つの文字列として返す必要があるので、ブロックごとに作成された文字列同士を結合したものを返すようにしています。
最後にqiita_team.py。
import requests
import settings
# Setting for Qiita Team
ACCESS_TOKEN = settings.ACCESS_TOKEN
TEAM_DOMAIN = settings.TEAM_DOMAIN
GROUP_NAME = settings.GROUP_NAME
COEDITING = settings.COEDITING
def post_qiita_team(filepath, body):
url = 'https://' + TEAM_DOMAIN + '.qiita.com/api/v2/items/'
body = body
params = {
'body': body,
'coediting': COEDITING,
'tags': [
{'name': '音声認識'},
{'name': 'QiitaAPI'}
],
'group_url_name': GROUP_NAME,
'title': filepath.split('/')[-1].split('.')[0],
}
headers = {'Authorization': 'Bearer {}'.format(ACCESS_TOKEN)}
requests.post(url, headers=headers, json=params)
-
requestsを使って実装しています。
-
文字起こしした文字列を引数のbodyとして受け取って記事の本文に、タイトルはファイル名から識別子を抜いたものになっています。
-
ちなみにurlを
https://qiita.com/api/v2/items/にするとQiitaに投稿することができます(ただしwrite_qiitaにスコープを持ったアクセストークンが必要)。
実行例
今回は https://hinanogimaya.com/6648/ の新型コロナウイルス影響による臨時休業時の留守番電話のアナウンス音声をサンプルとして記事を作成してみました。(日本語の著作権フリーの音声サンプルがとても少なくてびっくりしました・・・)
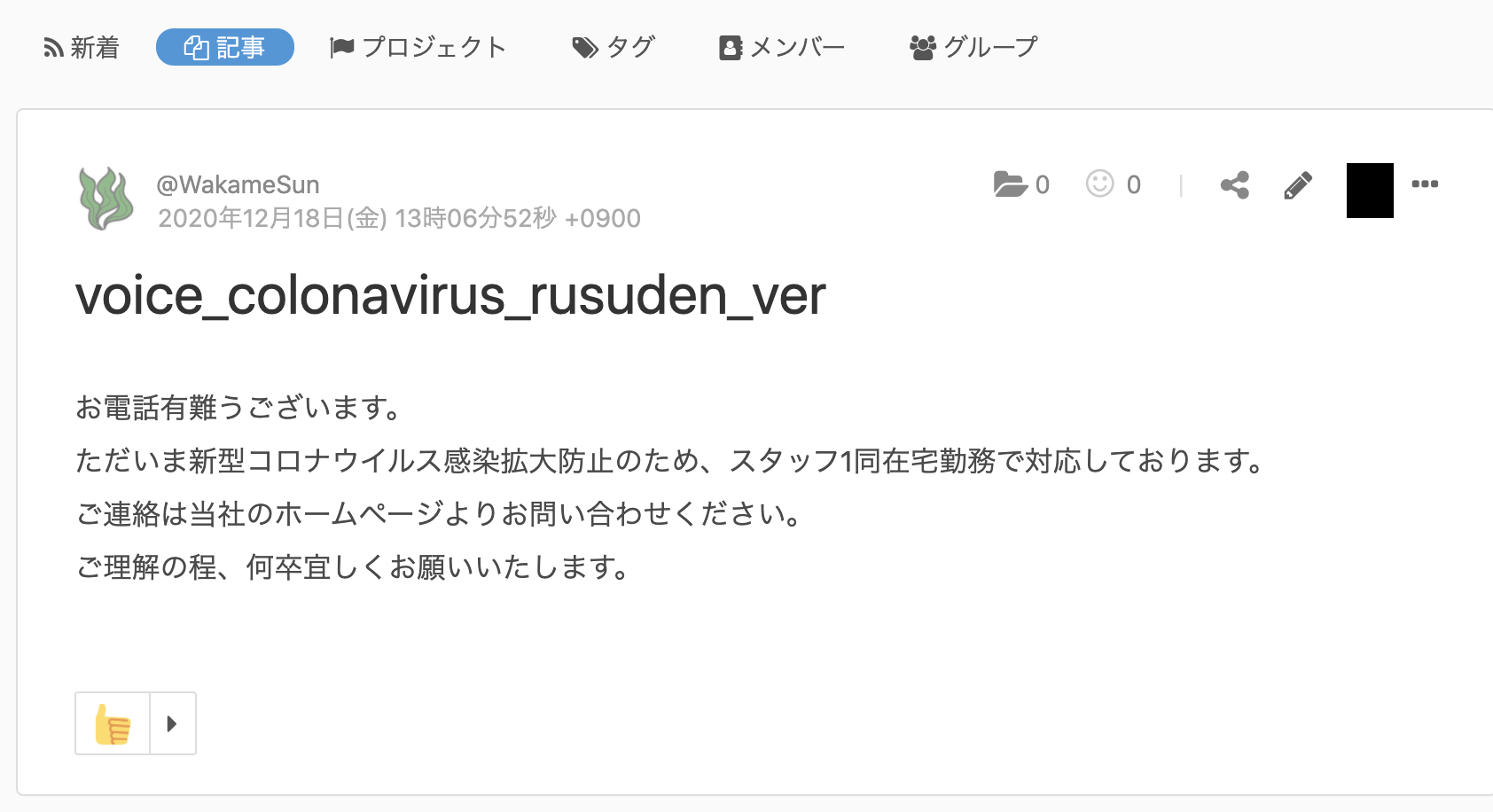
実際に上記の画像のように作成されているのを確認することができました。
精度としては正解文書が
お電話ありがとうございます。
ただいま新型コロナウイルス感染拡大防止のため、スタッフ一同在宅勤務で対応しております。
ご連絡は当社のホームページよりお問い合わせください。
ご理解のほど、何卒よろしくお願いいたします。
であるのに対し作成された文章は
お電話有難うございます。
ただいま新型コロナウイルス感染拡大防止のため、スタッフ1同在宅勤務で対応しております。
ご連絡は当社のホームページよりお問い合わせください。
ご理解の程、何卒宜しくお願いいたします。
となり、一同が1同になっていること以外はほぼ完璧な文字起こしをしてくれました。
発話しているのがプロの声優なので、比較的認識はしやすいだろうという推測はありますが、普通の音声でも最低限の手直しを人が行うだけで楽に文字起こしが行えるんじゃないかなと思います。
作成してみて
Azureは今回初めて登録して使ってみたのですが、公式のドキュメントがとても親切だったのでうまく誘導に乗って作成できたと思います。登録してから簡単なコードが動くまで1時間もかかっていないと思います。
かなり精度はよさそうなので実際にプロダクトに組み込んでも面白そうです。
最後に
Increments × cyma (Ateam Inc.) Advent Calendar 2020 の20日目は @ihsiek がお送りします!