昨年の8月に「ChatGPTでクイズ問題の難易度を推定してみる」という記事を書いた。
この記事ではChatGPTのモデルとしてGPT-3.5を使っていたので、GPT-4oだとどうなるかを試してみる。
openaiライブラリのバージョンを上げたので少し記法を変える必要があったが、基本的にやることは同じで、モデルとして"gpt-3.5-turbo"を指定していたところを"gpt-4o-2024-05-13"に変更してやってみた。
前回は世界の高い山に関する問題をいくつか作ってやってみたが、今回はせっかくなので実際に大会の問題を使ってみることにした。今回はabc the 17thの筆記クイズの問題100問を使用した(問題はBOOTHで購入できる)。
結果は以下の通り:
| # | mean | sigma |
|---|---|---|
| 1 | 29.3 | 11.8 |
| 2 | 75.5 | 10.5 |
| 3 | 90.4 | 2.6 |
| 4 | 29.9 | 8.1 |
| 5 | 45.5 | 16.8 |
| 6 | 21.2 | 5.9 |
| 7 | 17.6 | 3.1 |
| 8 | 23.0 | 5.1 |
| 9 | 35.2 | 10.9 |
| 10 | 13.2 | 1.0 |
| 11 | 39.4 | 13.1 |
| 12 | 30.2 | 10.2 |
| 13 | 30.1 | 8.2 |
| 14 | 19.5 | 3.3 |
| 15 | 12.9 | 0.9 |
| 16 | 86.1 | 2.6 |
| 17 | 14.6 | 1.4 |
| 18 | 72.8 | 11.0 |
| 19 | 19.0 | 3.6 |
| 20 | 19.1 | 4.8 |
| 21 | 42.6 | 14.8 |
| 22 | 20.1 | 4.5 |
| 23 | 20.4 | 4.0 |
| 24 | 83.9 | 2.6 |
| 25 | 39.2 | 14.9 |
| 26 | 16.9 | 2.5 |
| 27 | 30.0 | 10.3 |
| 28 | 31.5 | 9.8 |
| 29 | 14.3 | 2.2 |
| 30 | 18.5 | 2.7 |
| 31 | 24.6 | 6.1 |
| 32 | 17.1 | 2.6 |
| 33 | 15.7 | 2.0 |
| 34 | 16.0 | 2.4 |
| 35 | 15.4 | 1.6 |
| 36 | 12.1 | 0.8 |
| 37 | 13.1 | 0.9 |
| 38 | 80.8 | 5.3 |
| 39 | 19.0 | 3.2 |
| 40 | 56.5 | 16.4 |
| 41 | 84.2 | 4.1 |
| 42 | 21.5 | 5.7 |
| 43 | 26.7 | 7.5 |
| 44 | 50.4 | 16.1 |
| 45 | 26.3 | 8.6 |
| 46 | 23.6 | 7.7 |
| 47 | 14.9 | 1.7 |
| 48 | 30.2 | 11.7 |
| 49 | 27.9 | 7.9 |
| 50 | 34.5 | 11.9 |
| 51 | 23.4 | 6.2 |
| 52 | 16.3 | 1.6 |
| 53 | 18.9 | 3.0 |
| 54 | 67.5 | 12.1 |
| 55 | 11.0 | 0.8 |
| 56 | 36.0 | 11.2 |
| 57 | 14.3 | 1.3 |
| 58 | 22.7 | 6.0 |
| 59 | 12.2 | 0.7 |
| 60 | 56.8 | 16.6 |
| 61 | 15.8 | 2.4 |
| 62 | 24.8 | 6.4 |
| 63 | 13.1 | 0.9 |
| 64 | 10.0 | 0.6 |
| 65 | 14.9 | 1.6 |
| 66 | 13.5 | 1.0 |
| 67 | 20.1 | 4.0 |
| 68 | 16.1 | 1.6 |
| 69 | 51.7 | 16.0 |
| 70 | 12.0 | 1.0 |
| 71 | 23.3 | 7.0 |
| 72 | 21.8 | 5.7 |
| 73 | 14.5 | 1.5 |
| 74 | 21.3 | 5.8 |
| 75 | 13.3 | 1.0 |
| 76 | 13.6 | 1.2 |
| 77 | 29.5 | 7.7 |
| 78 | 13.9 | 1.0 |
| 79 | 15.2 | 1.4 |
| 80 | 13.9 | 1.4 |
| 81 | 14.2 | 1.4 |
| 82 | 16.2 | 2.7 |
| 83 | 13.4 | 1.5 |
| 84 | 11.2 | 1.0 |
| 85 | 20.1 | 3.9 |
| 86 | 13.9 | 1.6 |
| 87 | 18.3 | 3.0 |
| 88 | 36.5 | 12.4 |
| 89 | 15.3 | 2.3 |
| 90 | 15.0 | 1.7 |
| 91 | 12.0 | 0.9 |
| 92 | 13.5 | 1.1 |
| 93 | 66.6 | 15.8 |
| 94 | 13.9 | 1.0 |
| 95 | 13.9 | 1.0 |
| 96 | 21.3 | 5.6 |
| 97 | 19.2 | 3.4 |
| 98 | 23.0 | 6.2 |
| 99 | 11.7 | 0.9 |
| 100 | 18.3 | 3.3 |
プロットすると下図のようになる:
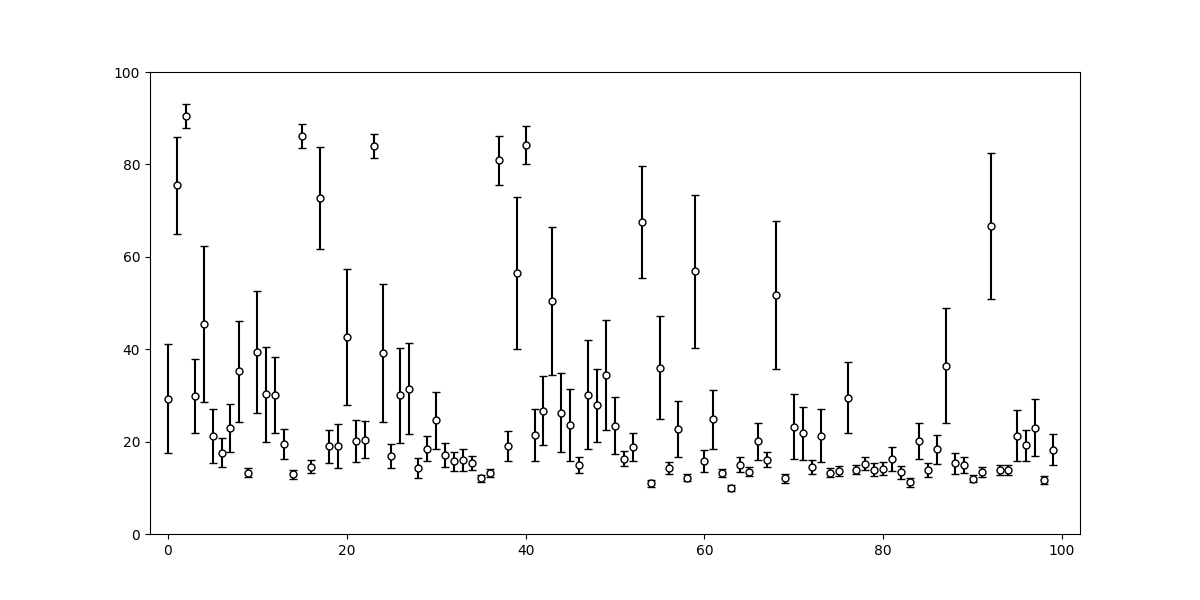
問題番号順で難易度が高くなっていくようになっているわけではないので、推定された難易度順にソートすると
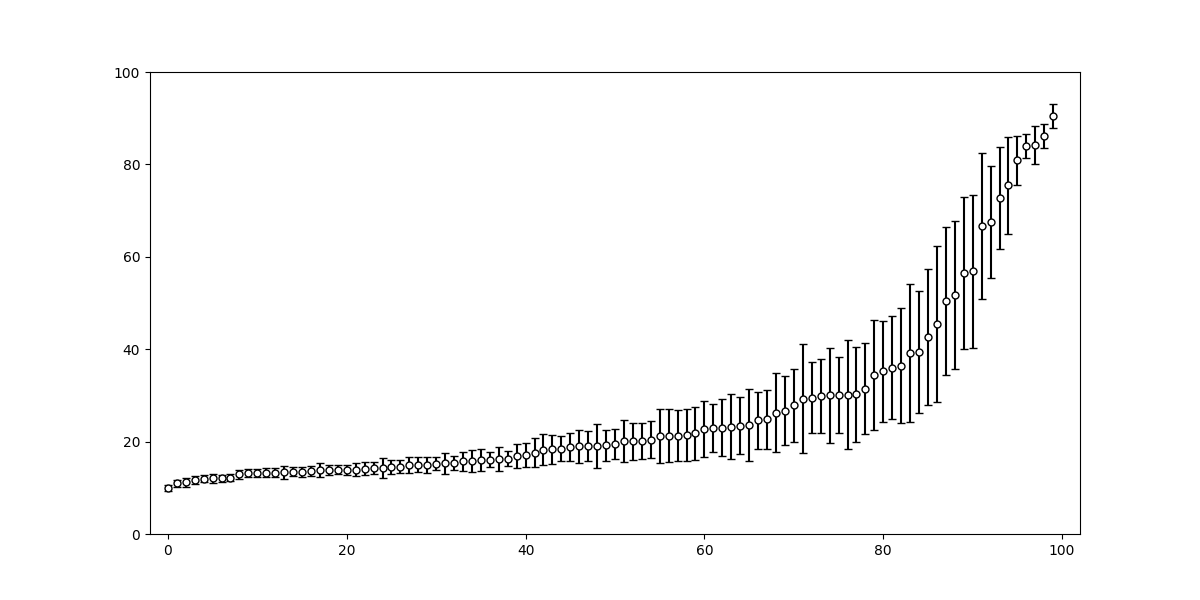
基本的には10〜30%くらいのものが多そう。ヒストグラムを書いてみると下図のようになる:
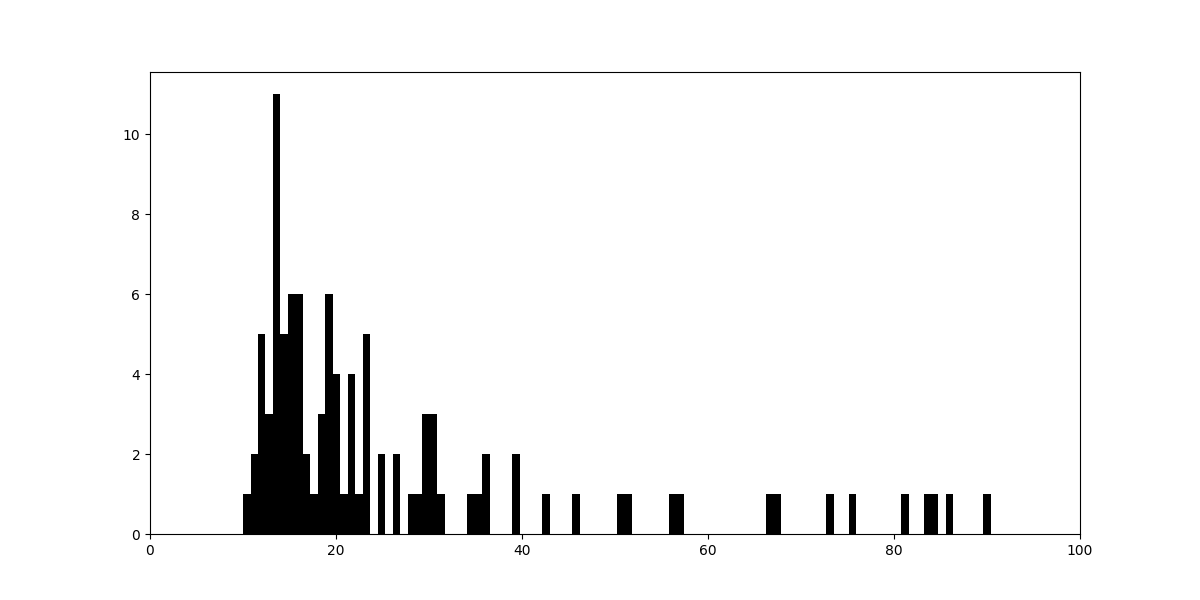
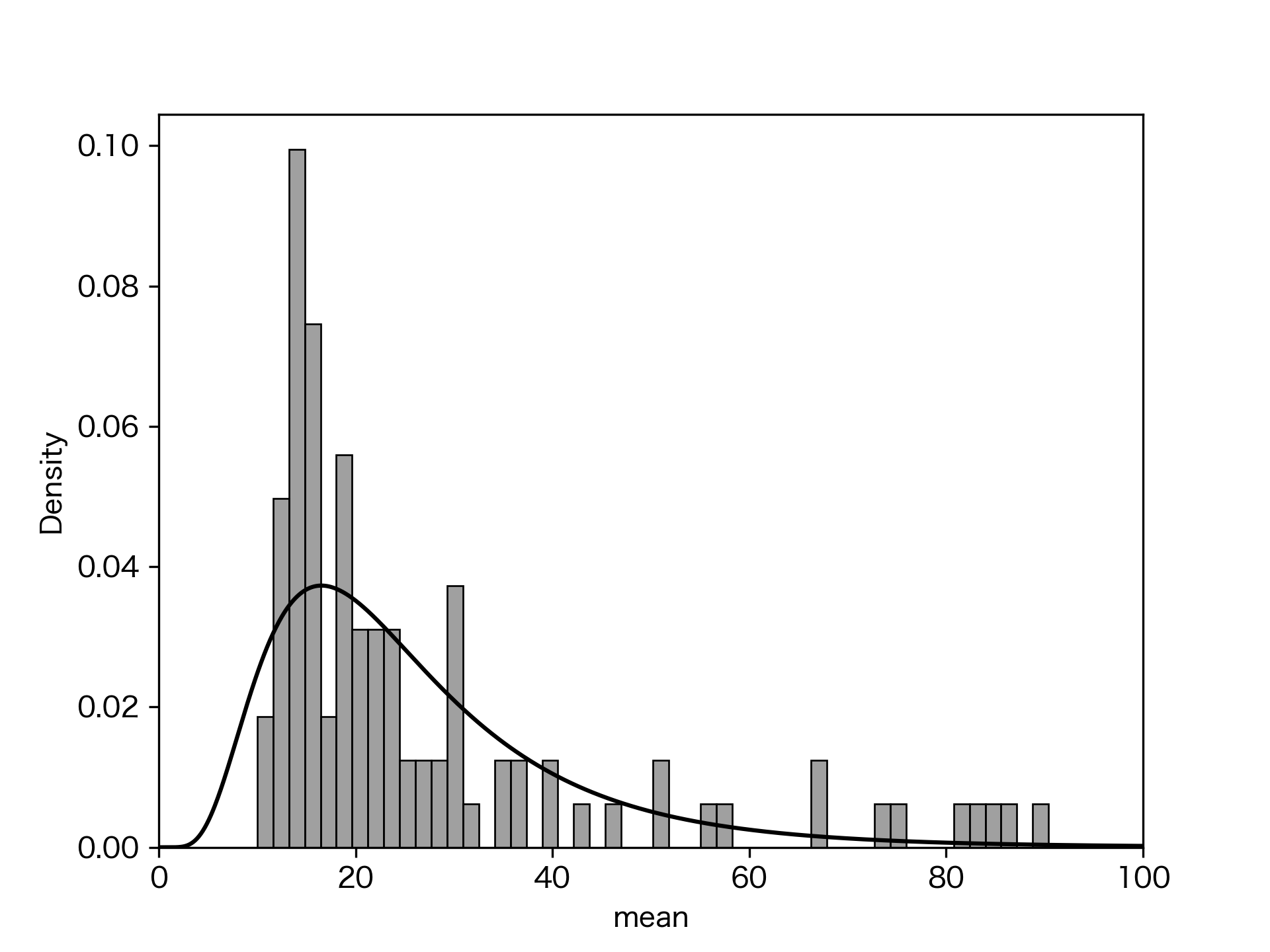
何となく、対数正規分布のように見えるのでフィッティングしてみる。scipy.statsのlognormを使ってフィットしたものをヒストグラムに重ねると下図のようになった:
横軸を対数にしたものをseabornのhistplotで書いてみるとこんな感じ:
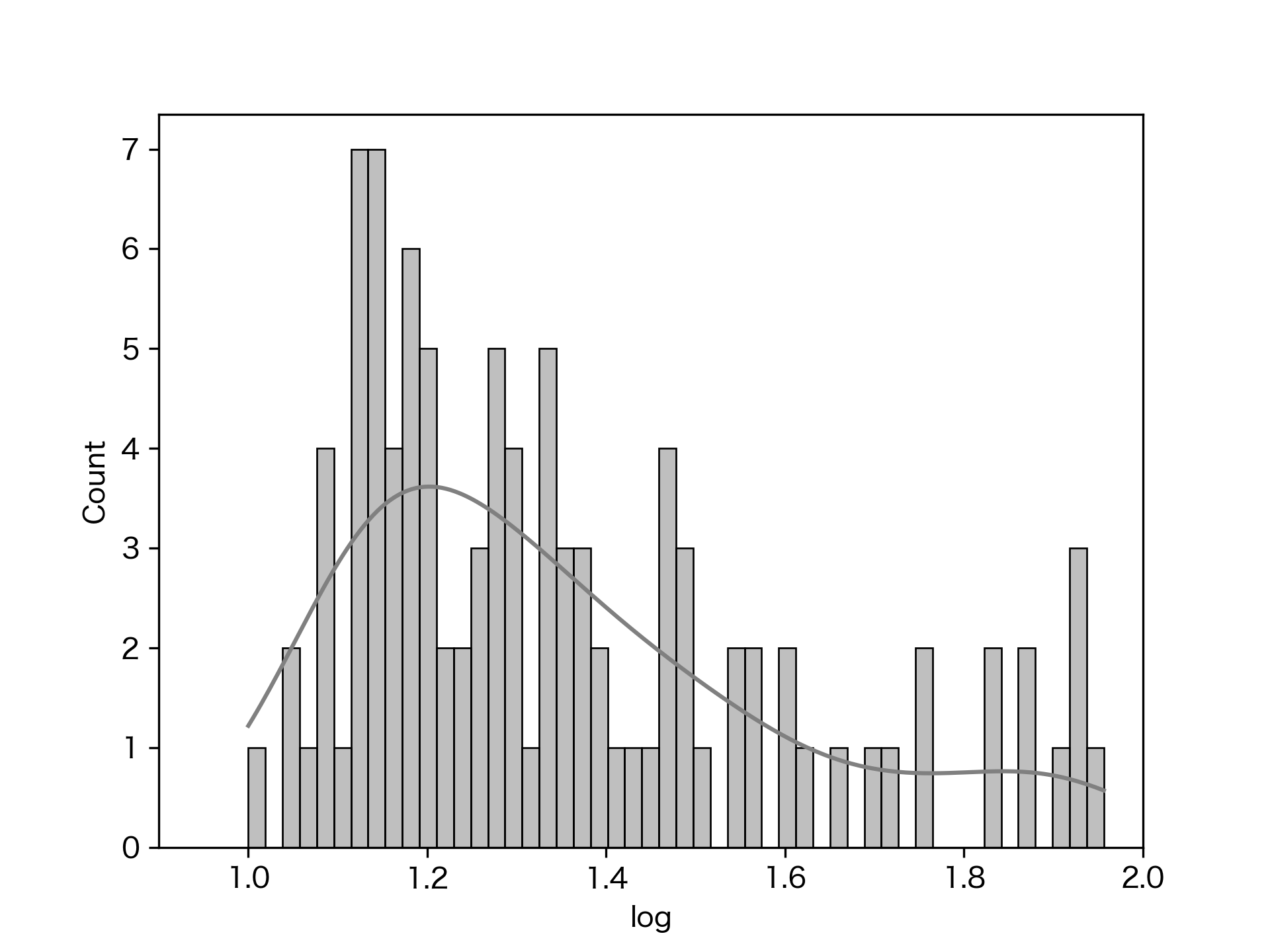
右側の裾野が長く、左側がカットアウトされているような感じに見えるので、あんまりはっきりと正規分布という風でもなさそう。
kstestでKolmogorov-Smirnov検定をしてみると、p値が0.074となる。有意水準0.05としたら、この分布が対数正規分布から外れている、とは言えない範囲だが、それほど綺麗に当てはまっているというわけでもなさそう。
QQプロットを描いてみると下図のようになる:
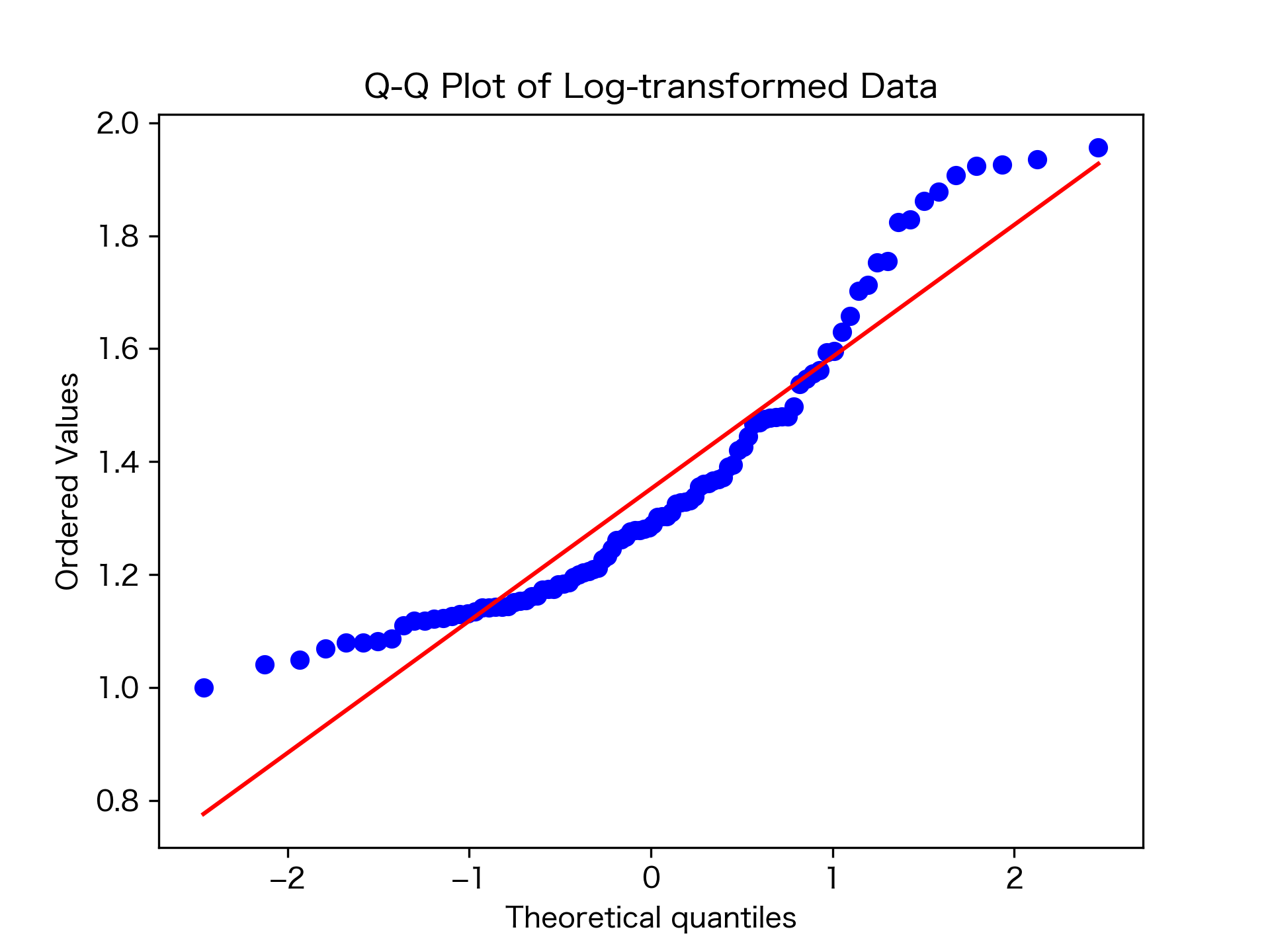
中央付近は対角線に近いところにあるが、両端が外れた位置にあって、完全にモデルに適合しているとは言いがたいように見える。
分布の山にあたる予想正答率は11.2%となる。abcは"基本問題"を謳っているが、競技クイズ界隈で"基本問題"といっても日本人一般の正解率では低め、ということになるだろうか。
一方で、今回の難易度推定では予想正答率の平均が10%を下回るものは1つも出ていない。これはabcの"基本問題"たる性質を表しているのか、それともChatGPTの回答の限界なのか。個別のChatGPTの回答には10を下回る値を出しているものはあるので、必ずしも10未満が出せないというわけではなさそうだが、結構多くの回答で10の倍数のキリの良い数字を出しているのが気になるところ。
予想正答率の平均が80を超える問題は「チェッカーフラッグ」「リンク」「(y)切片」「『キングダム』」「ディープラーニング」の5問だった。「チェッカーフラッグ」の問題は「市松模様」というのが問題文中に入っているから正答率が上がりそうだし、他もまあ一般知名度が高そうな雰囲気はある。
予想正答率の平均が12以下なものをみると「滝線都市」「ウィケット」「(シルヴィ・)バルタン」「荻原守衛」の4問。これらは各分野に触れていないと知らない可能性が高く、一般知名度で見ると低くなると言っても違和感はなさそう。
ちなみに、今回は金額としては合計で\$7くらいかかったらしい。大会1回に1000問使うとしたら、10倍で\$70といったところなので、まあそこそこの大会なら出せなくもない範囲だろうか。もっと安く済むならもっと大量のデータで色々試してみたいところだったが、ちょっと今回はこの程度で終わらせておくことにする。