SAS ViyaはAIプラットフォームになります。Webブラウザ上で機械学習の設計、実行ができるStudioという環境も用意されていますが、開発者はプログラミングコードで開発することも可能です。プログラミング言語はJava/Python/R/SASが選べます。
機械学習を用いる際に専用のテーブル(casTable)を用いますが、今回はデータの分布を調べる方法を紹介します。
データを確認する
今回は organics.sas7bdat を用います。
organics = sess.upload('organics.sas7bdat')
データは以下のようになっています。
organics.casTable.head()
| CUSTID | GENDER | DOB | EDATE | AGE | AGEGRP1 | AGEGRP2 | TV_REG | NGROUP | NEIGHBORHOOD | LCDATE | ORGANICS | BILL | REGION | CLASS | ORGYN | AFFL | LTIME | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0000000140 | U | 1921-09-16 | 1998-02-23 | 76.0 | 60-80 | 70-80 | Wales & West | C | 16 | 1994-11-07 | 0.0 | 16000.00 | Midlands | Gold | 0.0 | 10.0 | 4.0 |
| 1 | 0000000620 | U | 1949-02-12 | 1998-02-23 | 49.0 | 40-60 | 40-50 | Wales & West | D | 35 | 1993-06-04 | 0.0 | 6000.00 | Midlands | Gold | 0.0 | 4.0 | 5.0 |
表示するデータを指定する
今回は年齢ごとにデータを確認します。
organics.casTable.percentile(inputs='AGE')
データが出力されます。
§ Percentile
| Variable | Pctl | Value | Converged | |
|---|---|---|---|---|
| 0 | AGE | 25.0 | 44.0 | 1.0 |
| 1 | AGE | 50.0 | 54.0 | 1.0 |
| 2 | AGE | 75.0 | 64.0 | 1.0 |
さらにデータをその分布に応じて分割します。
organics.casTable.percentile(inputs='AGE', values=list(range(5,95,5)))
そうするとデータが5%刻みで分割されたのが分かるでしょう。
§ Percentile
| Variable | Pctl | Value | Converged | |
|---|---|---|---|---|
| 0 | AGE | 5.0 | 32.0 | 1.0 |
| 1 | AGE | 10.0 | 36.0 | 1.0 |
| 17 | AGE | 90.0 | 72.0 | 1.0 |
さらにデータを性別でグルーピングします。元々の表では両性別が混在しています。
organics.casTable.groupby = ['GENDER']
result = organics.casTable.percentile(inputs='AGE', values=list(range(5,95,5)))
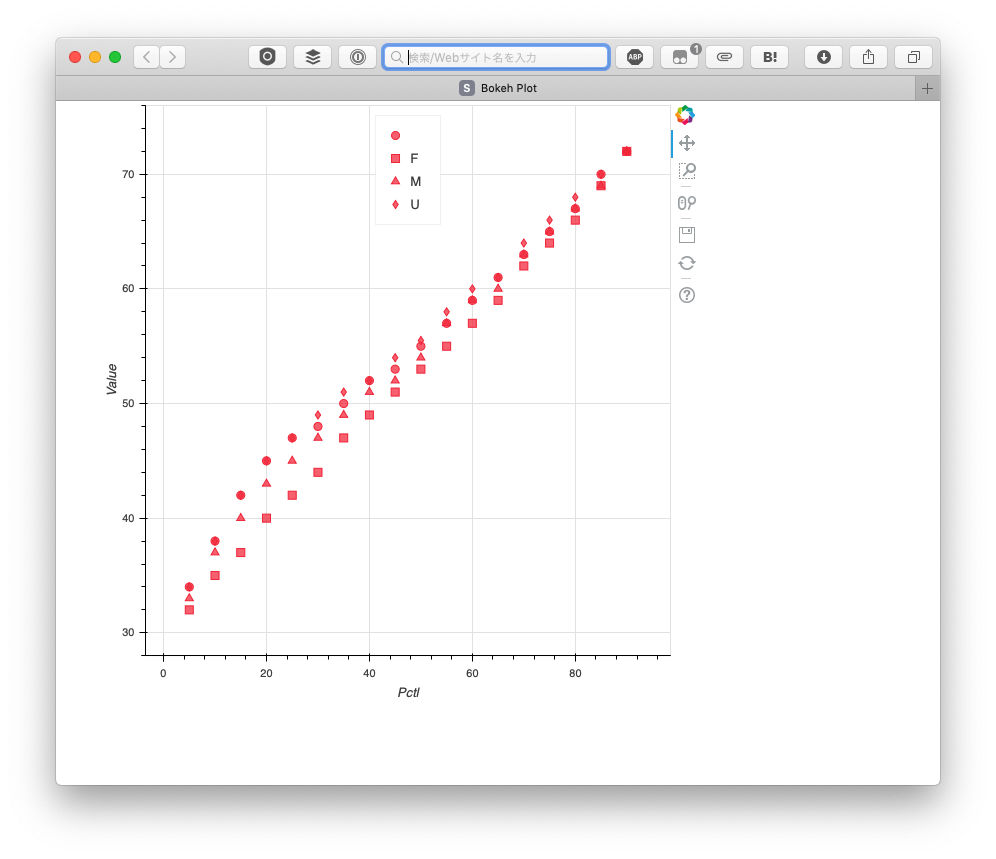
そしてそのデータをグラフ出力します。
df = result.concat_bygroups()['Percentile']
df.reset_index(level=0, inplace=True)
p = Scatter(df, x='Pctl', y='Value', legend='top_center', marker='GENDER')
output_file('scatter.html')
show(p)
そうすると性別ごと(UはUnknown)も含めてデータの分布が可視化されます。
Pythonを使うことでデータの傾向が可視化され、分析を行う前に全体像が把握できるようになります。ぜひPythonライブラリを使ってSAS Viyaの分析に役立ててください。