SAS Viya(サス・ヴァイヤ)はオープンなAIプラットフォームです。クラウドやオンプレミスで設置可能です。
今回はデモ版でデータ分析を試してみました。有名なタイタニック生存者のデータ、titanic_train.csvを使っています。
SAS Viyaの登録
時々英語になったり、ステップが多かったりしますが、登録作業自体は簡単です。
データの入手
データは parallel_ml_tutorial/titanic_train.csv at master · ogrisel/parallel_ml_tutorial などから入手します。
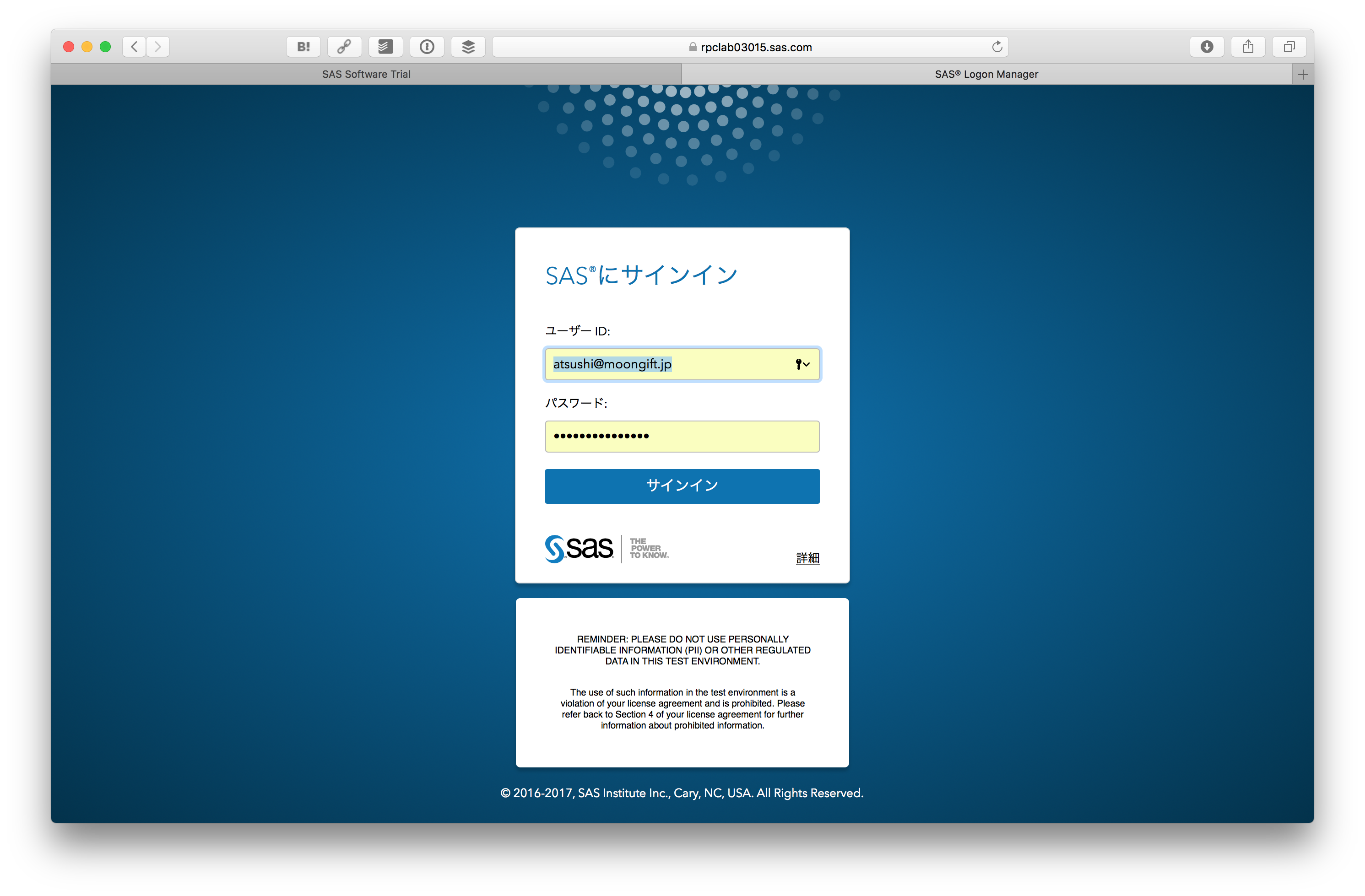
ダッシュボードにログイン
SAS Viyaにログインします。ユーザIDはメールアドレスを使います。
ログインすると表示される画面です。まずデータの管理を実行します。
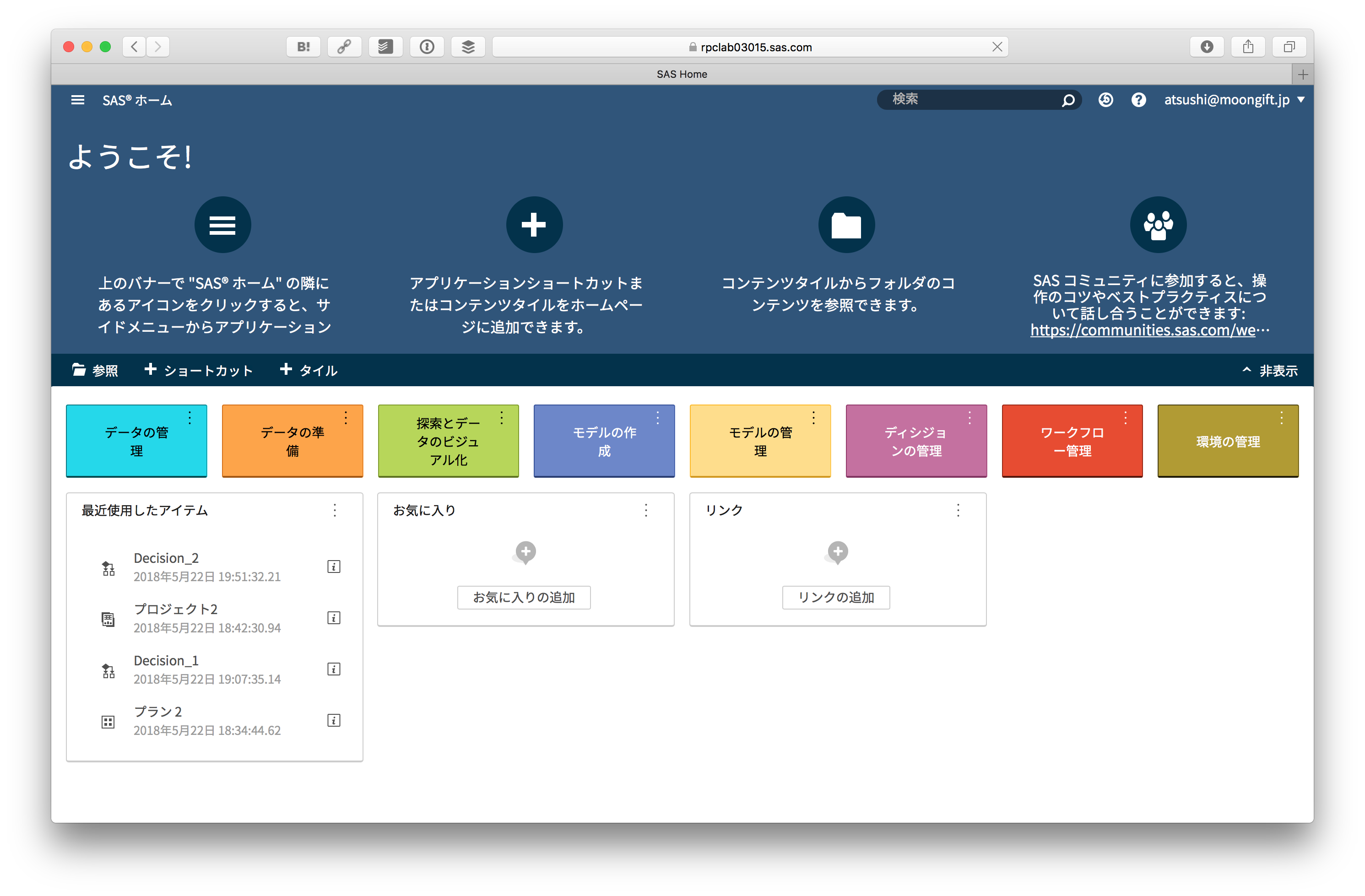
データの管理
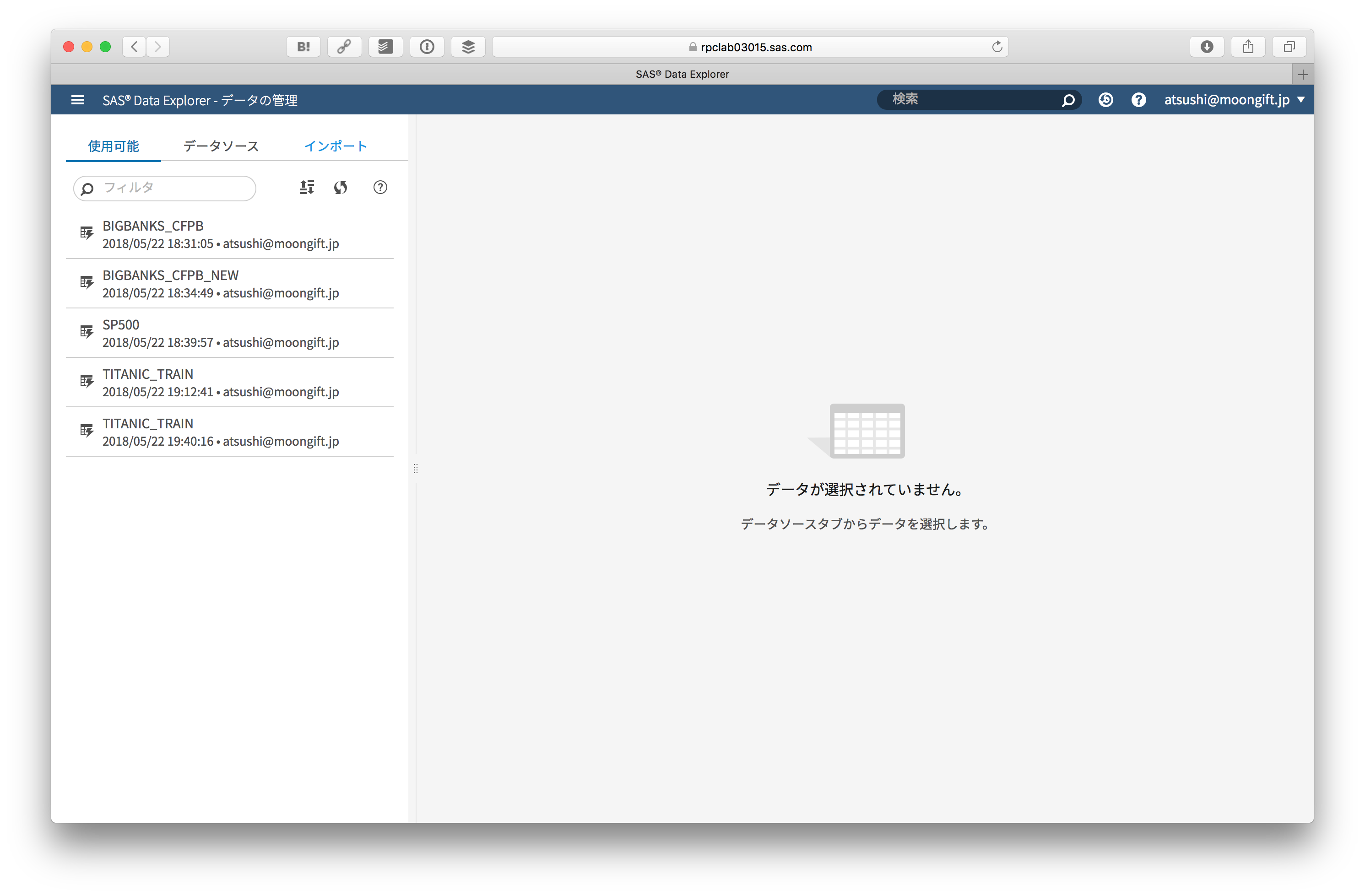
使用可能なソースは最初は何もありません。
インポートを選んで、先ほどダウンロードしたCSVファイルを選択します。
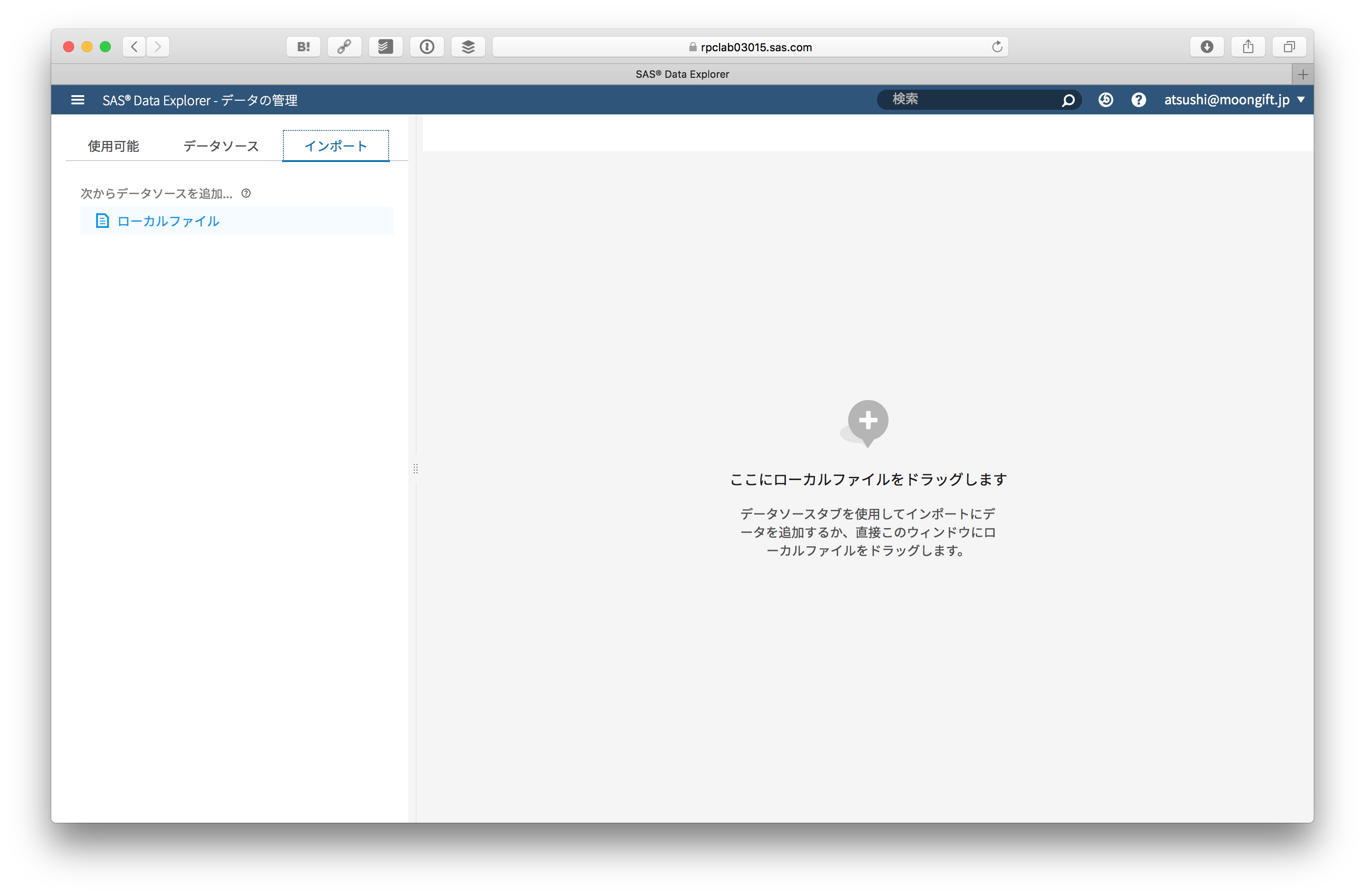
テーブル名に .csv といった拡張子が入っているとインポートに失敗するので注意してください。
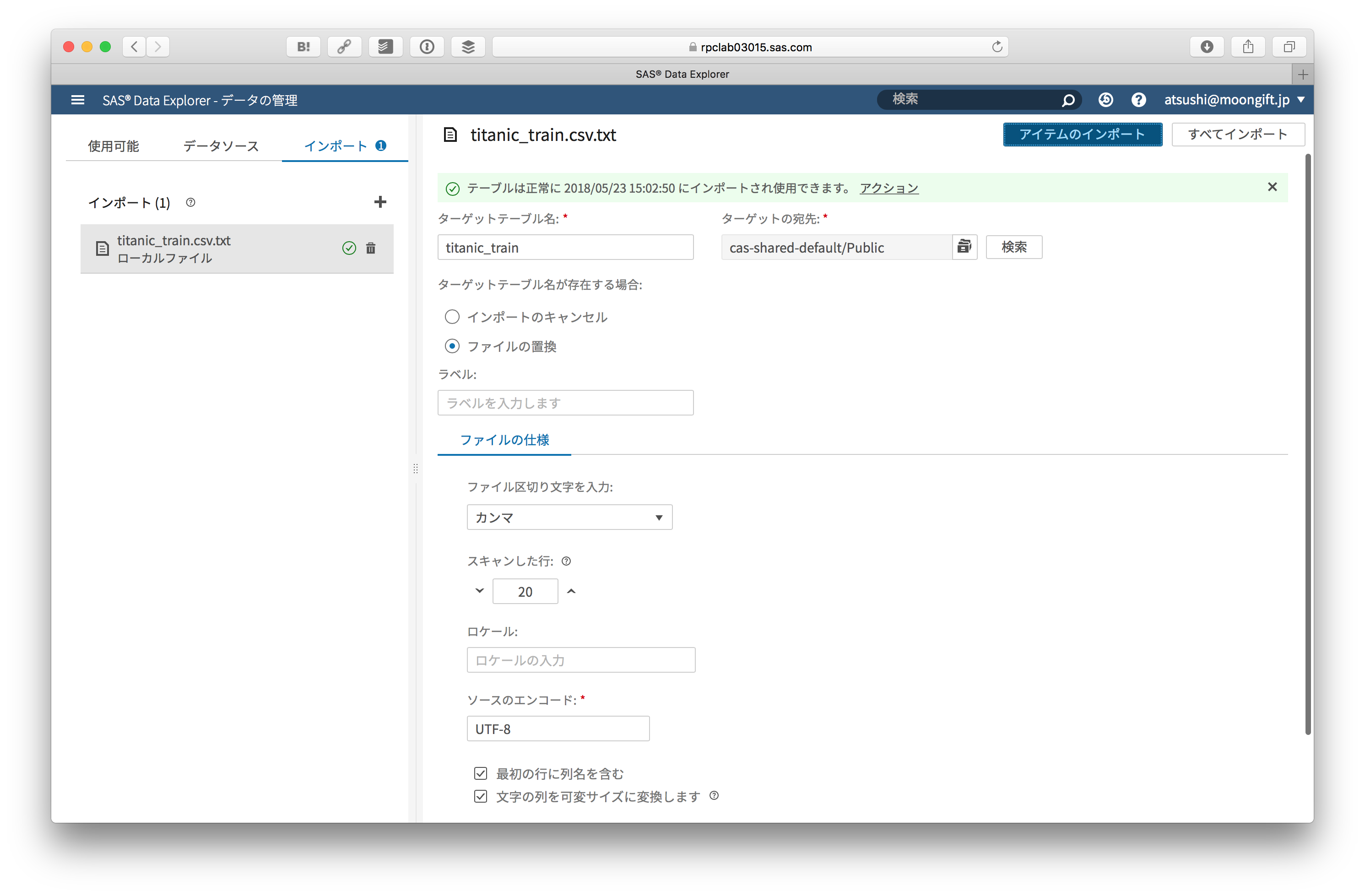
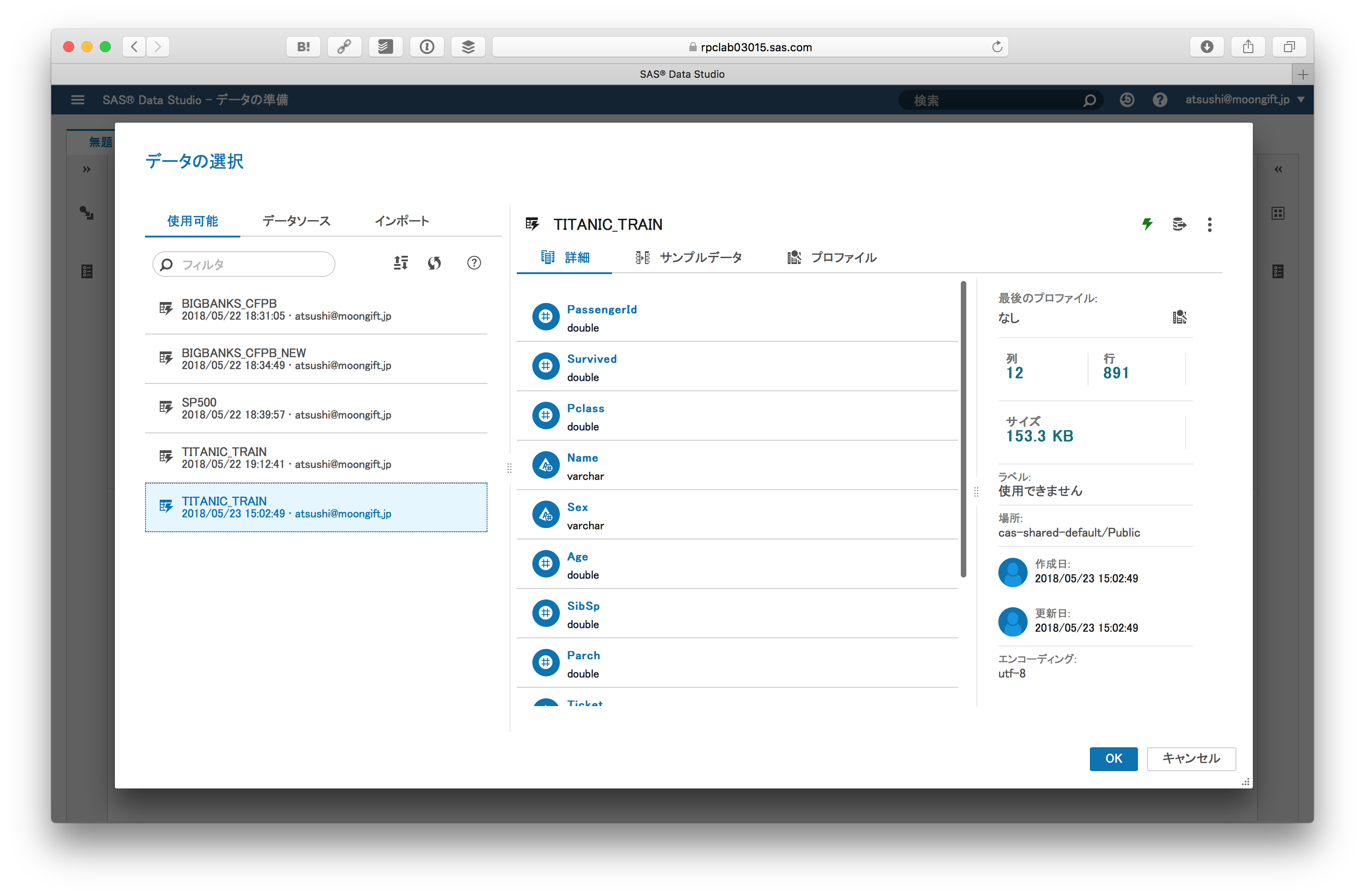
インポートされると列データやプレビューができます。
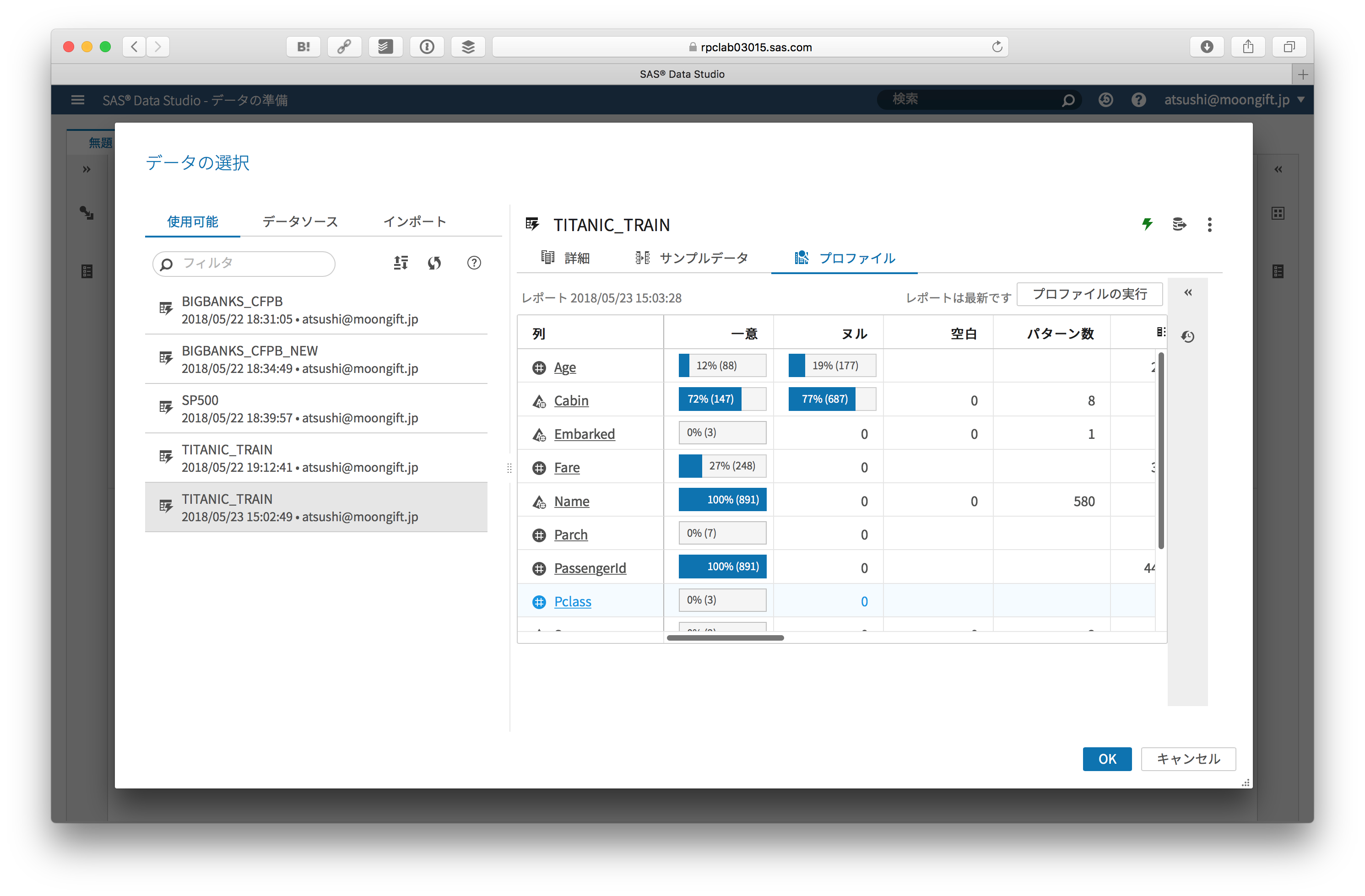
プロファイルを使って簡易的に分析もできます。
データの準備
データの準備ではカラム名を変えたり、データの修正を行います。欠損値などがあれば適用したりするのに使います。
探索とデータのビジュアル化
簡易的なグラフやデータ表示を行います。
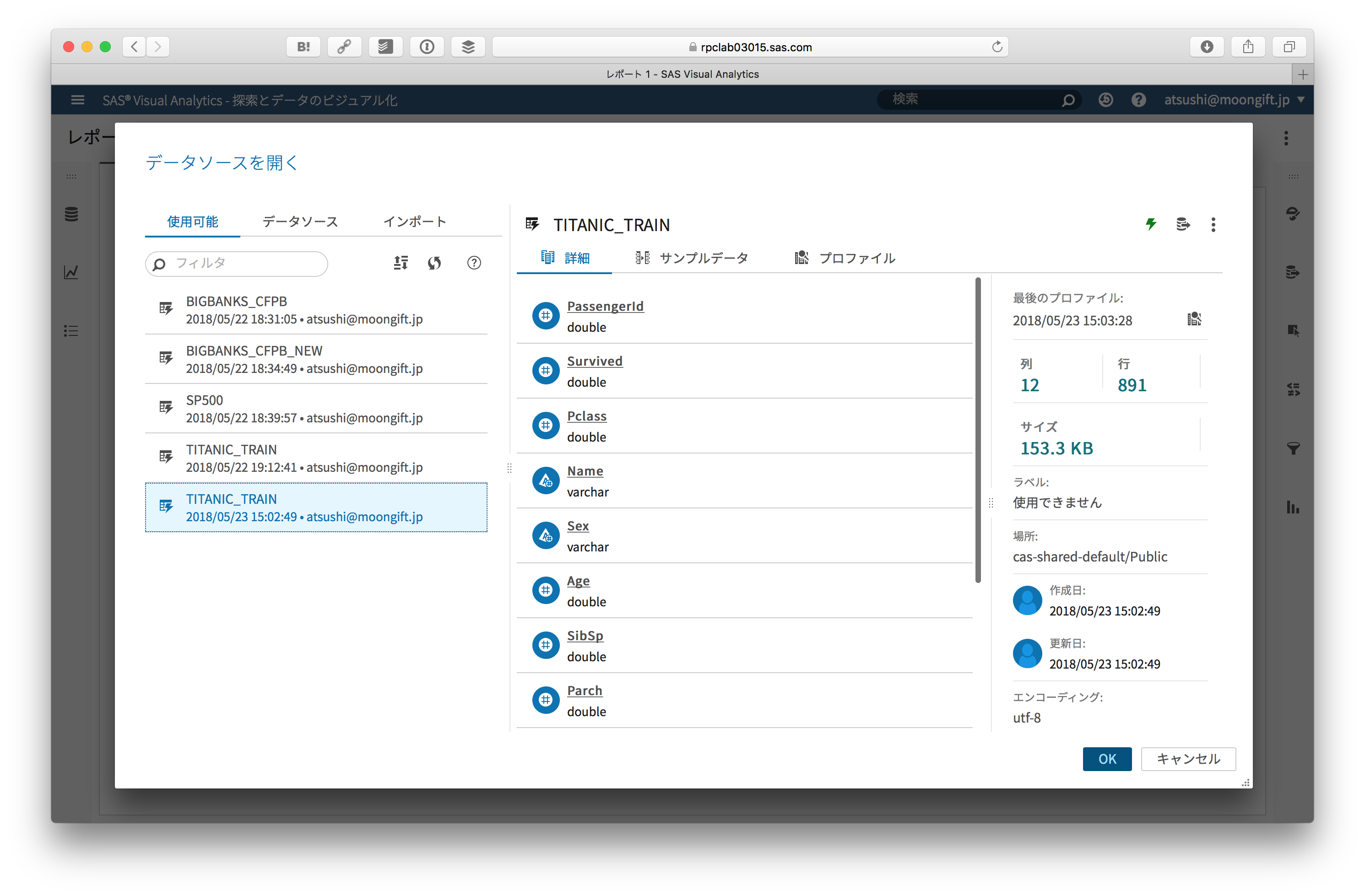
データは先ほど取り込んだものを使います。
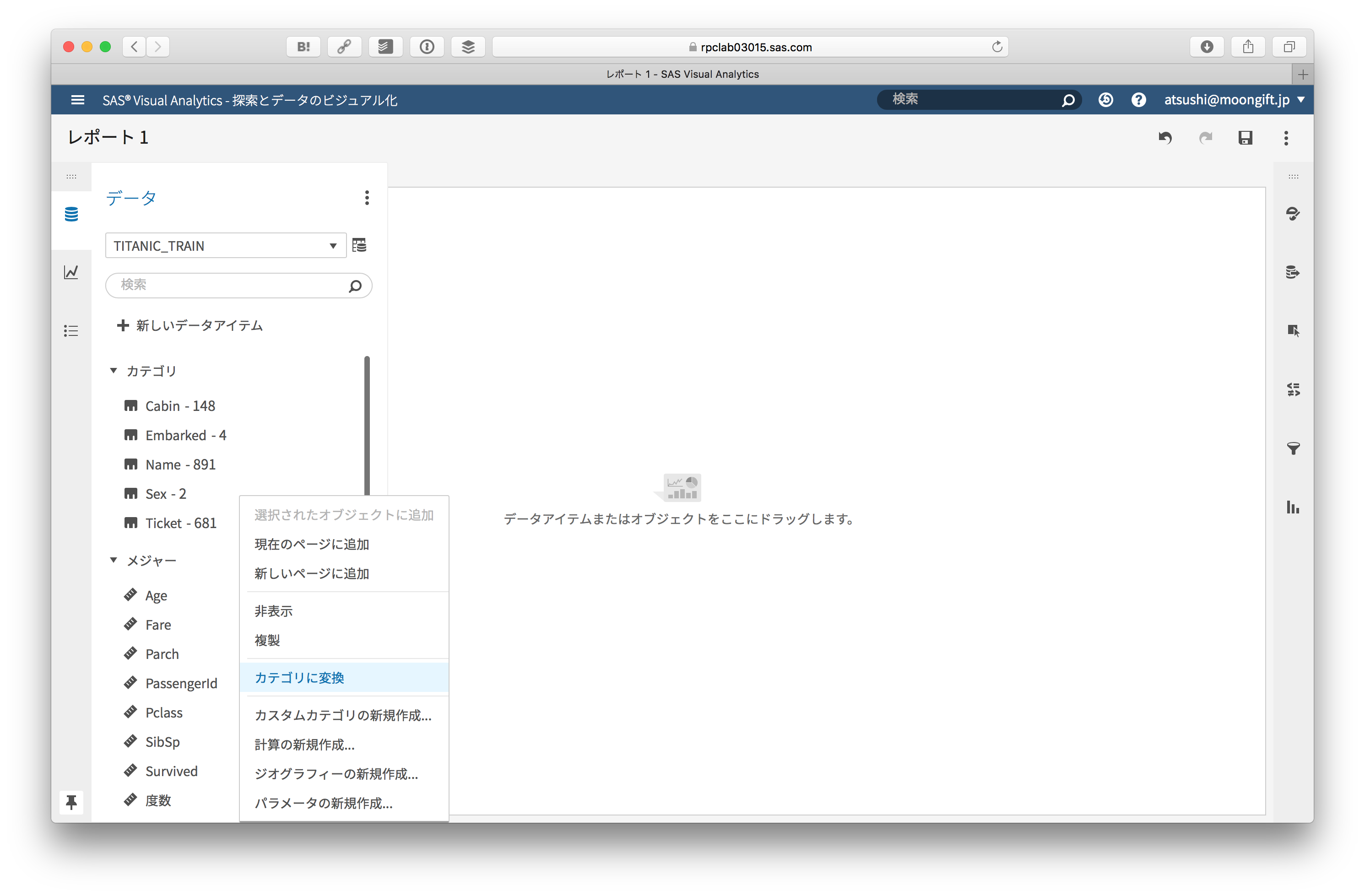
データによって自動的に集計行とラベル行に指定されていますので、必要に応じて変更します。
例えば性別別に生存者の数を見たりできます。
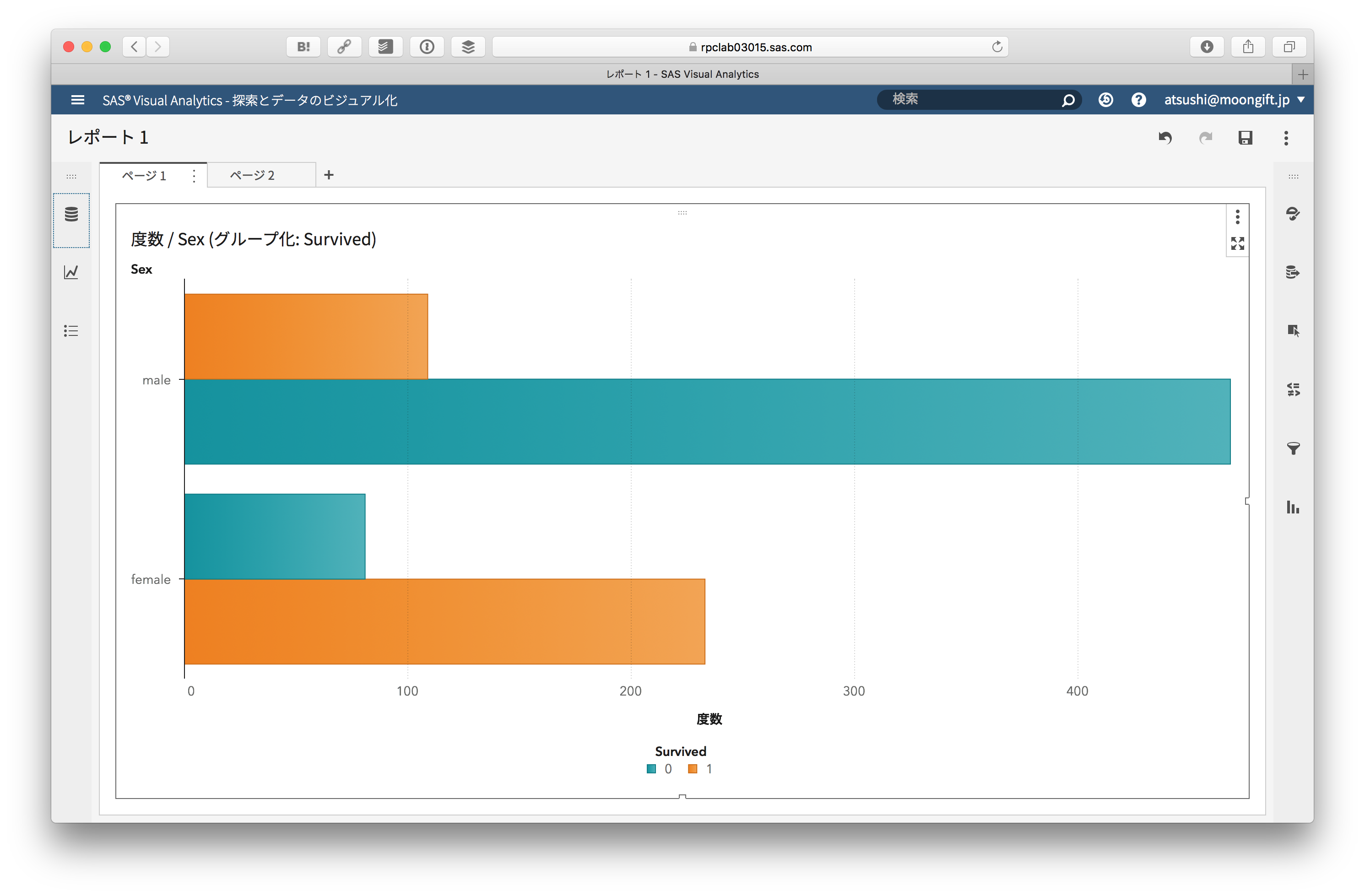
モデルの作成
テキスト分析やデータマイニング、機械学習を行う機能です。
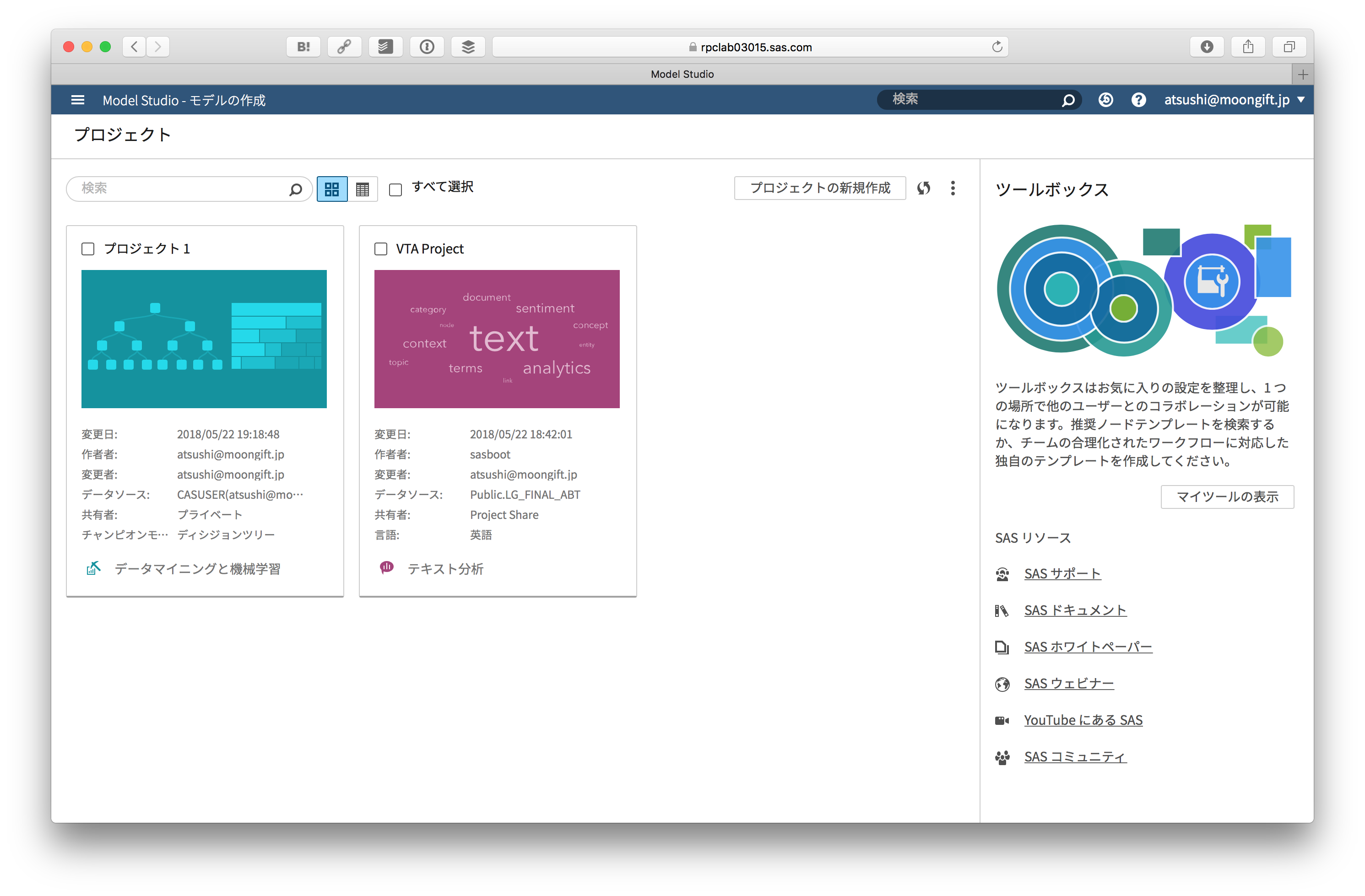
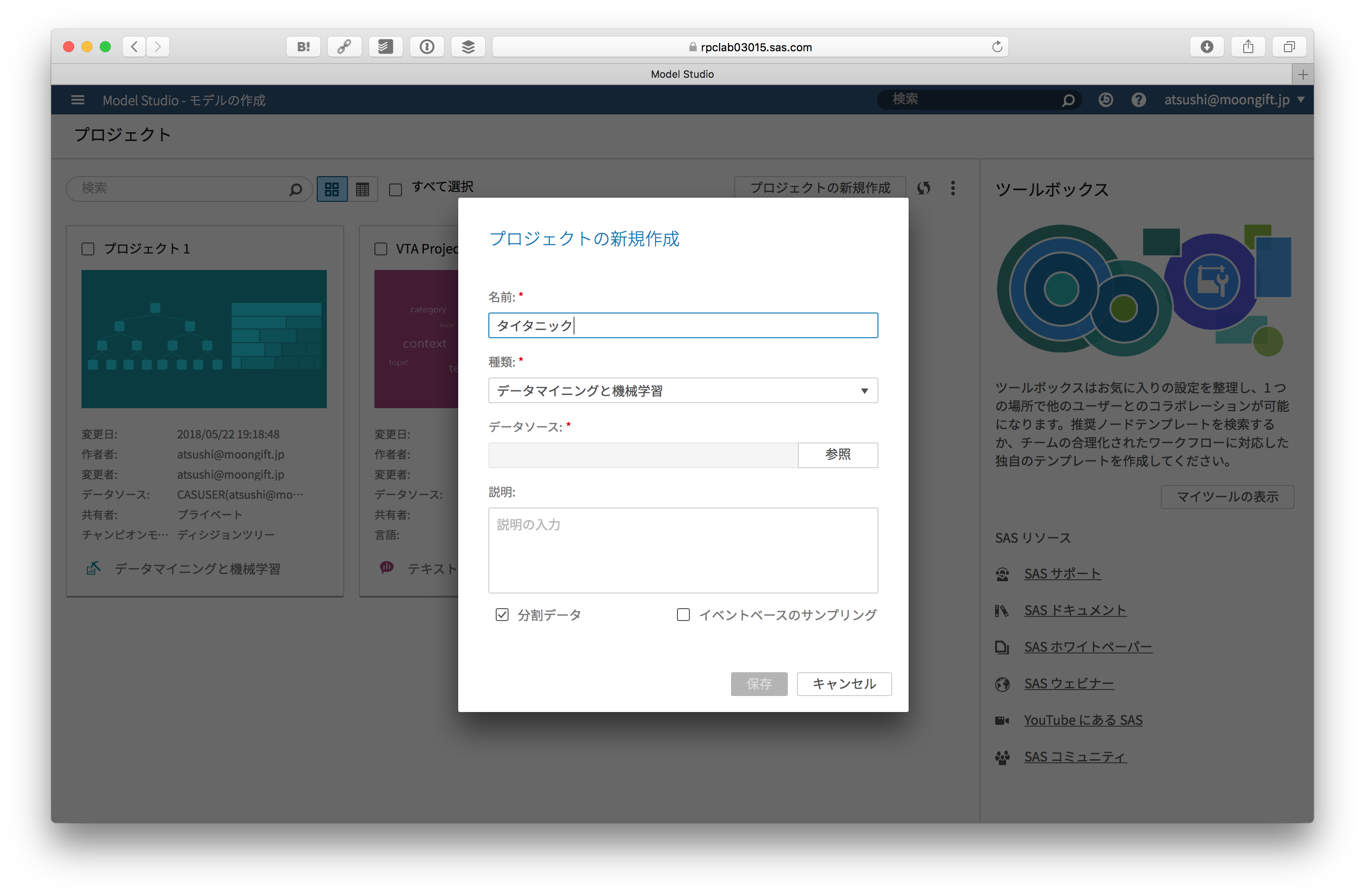
新しいモデルを作成します。データソースはもちろん先ほどインポートしたものを指定します。
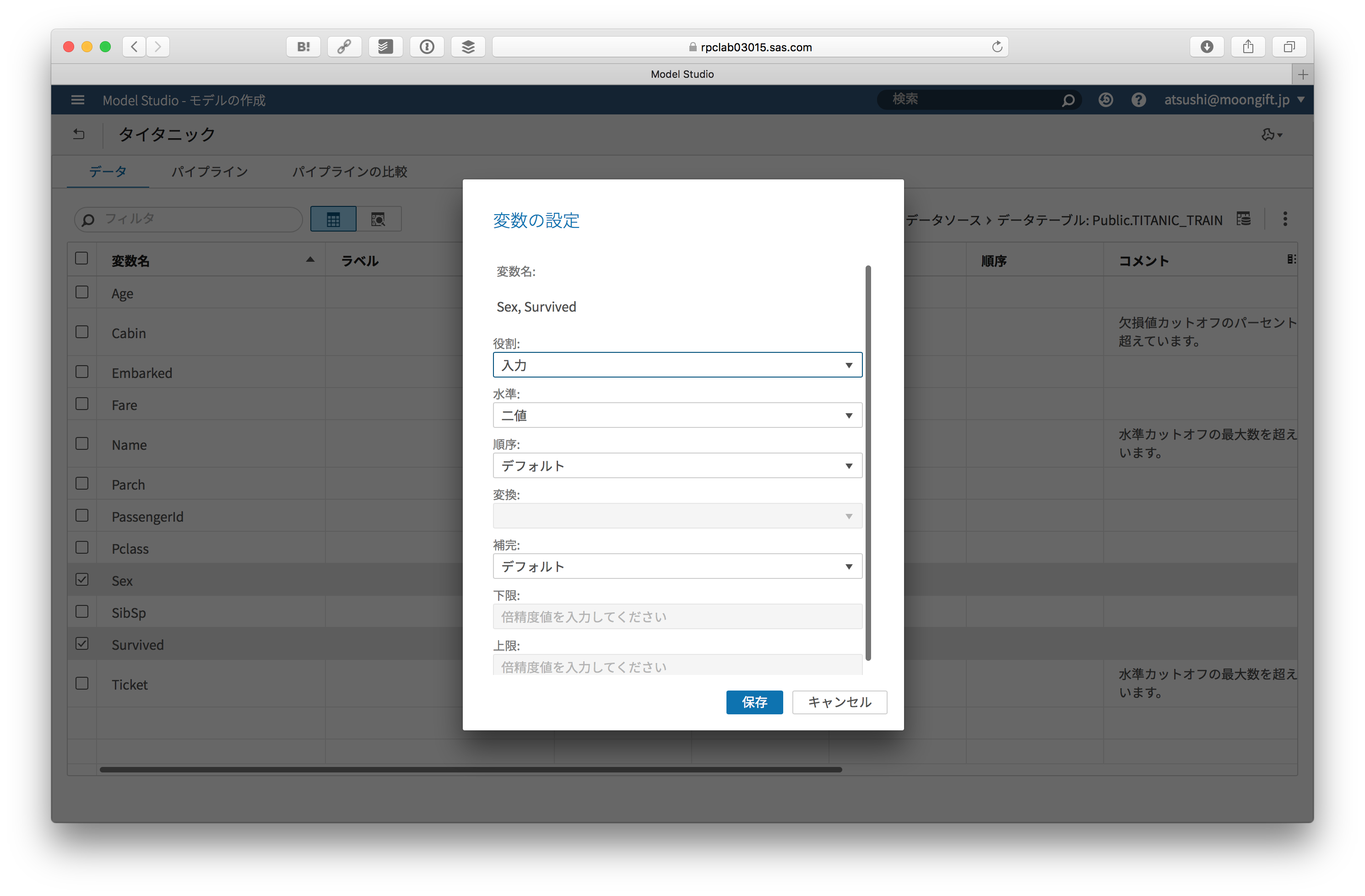
そして変数やターゲット変数を指定します。
パイプラインを使って、ビジュアル的にデータマイニングの設定ができます。
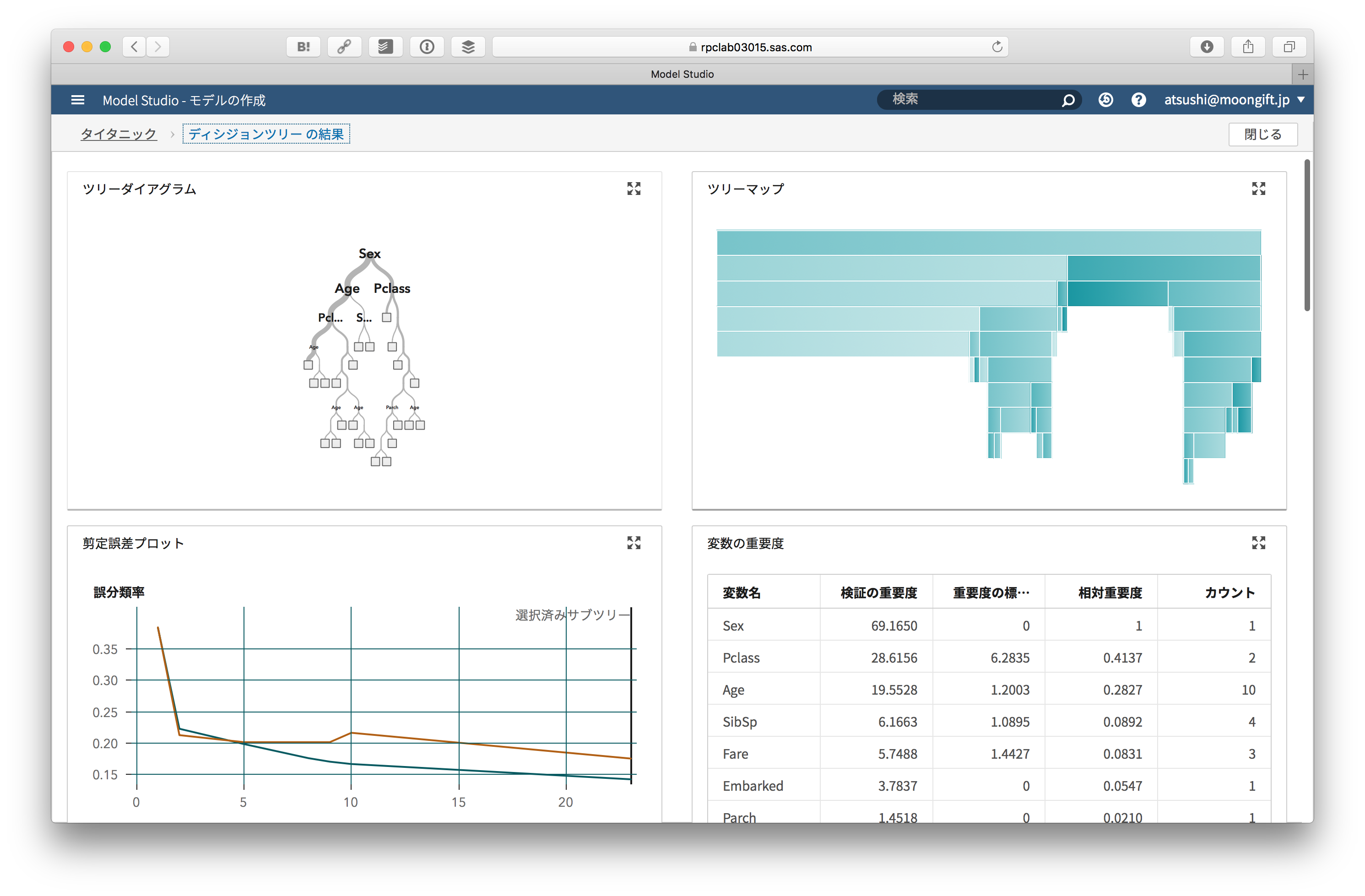
ディシジョンツリーやツリーマップ、剪定誤差などを確認できます。
SAS Viyaは操作をビジュアルでできるので、開発者でなくとも使えるAIプラットフォームです。開発者向けにはREST APIも公開されていますので、それを使ってより深く掘り下げることもできます。
無償体験版も用意されていますので、ぜひ試してみてください!