ICCV2019でBest Paperの*"SinGAN: Learning a Generative Model from a Single Natural Image"*が色々なタスクに応用できそうで、面白かったのでまとめてみた。
論文はSinGANを参照。
Abstract
One-shot learningをGANで実施。つまり、一枚の画像で学習し学習した特徴を元に画像生成や画像変換を行う。所感ではOne-shot learningで一つのタスクではなく複数のタスクに応用できるのは今後の発展がかなり期待できると感じでます。
論文中では以下のタスクに応用。結果が全部良好で印象がよかった。
・Image Generation
・High Resolution
・Super Resolution
・paint to image
・Editing
・Harmonization
・Animation

Background
Few-shot learningはmeta learningを用いた手法が多く提案されている。
meta learning分かりやすい記事はこちら
特にOne-shotでのGANベースの従来研究ではテクスチャを保存することが限界だった。
下図は従来のGANベースで一枚のみの画像で学習を行った場合のImage generation結果。
ご覧の通り、PSGAN等では画像のなんとなくのテクスチャの雰囲気は生成できているが、シーンなどは特徴として出力できない。しかしSinGANではより詳しい特徴まで再現できている!
じゃあどうやって実現してるのって話になる。

Method
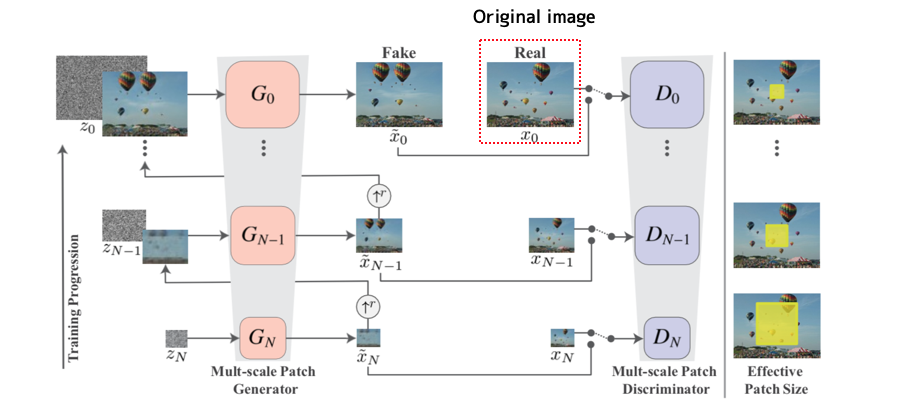
提案されたアーキテクチャは上図。簡単に構造を説明すると...
・Pyramid型の複数Generator及びDiscriminator。
・学習で用意する画像は上図のOriginal imageの部分。
・一番小さくdown samplingした画像から、解像度を上げていく。
・最初の入力はNoiseで次からはNoiseと下位層で出力された画像をAttention的に合わせる。
・DiscriminatorはPatchGANベースで、Patch毎にRealかfakeか判別している。
ここが工夫点で、PatchGANのReceptive fieldを各解像度で設けることで、様々な受容野で特徴抽出が可能。それに加え、Multi-scaleでGenerator-Discriminatorを応用しているので、精巧な特徴抽出はできそう。
筆者曰く、様々な解像度で特徴を捉えることが非常に重要だそうで、そんなことは知っているが本当にそれだけでこんなに上手くいったのかというのが正直な所感。
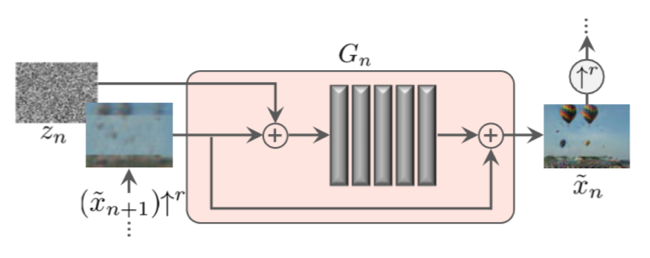
Generatorの構造も5層の33FCN構造で
33Convolution BatchNormalization Leaky ReLUを繰り返すだけ。
解像度がアップした際はNoiseと下位層で生成した特徴(生成画像)をResidual的に加算。
損失関数もいたって単純。
各解像度でGANおなじみのAdversarial lossを算出するのにReconstruction lossを追加するだけ。
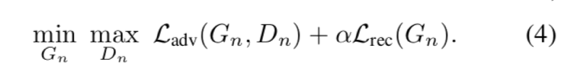
右項のReconstruction lossは生成した画像とその解像度での正解画像をL2ノルムで算出している。詳しい式は論文からどうぞ。
結果
結果が大量にあるので、個人的に面白かった結果を記載します。
Super Resolution
画像を拡大した際の画像のいわゆるボケを軽減するためのsuper resolution。
従来のGANベースだと、下図のSRGANが有名。SRGANはsuper resolutionに特化しており、なおかつ複数枚の画像で低解像→高解像の画像変換を行うように学習されている。
しかしSinGANは1枚の学習画像のみでかなり高精度に...すごい。

Change number of the scale
Pyramid状の構造で提案手法において、Pyramidをいわば何段積めばいいの?って話
2 scalesは2段ですよという意味。
この結果の面白いことは従来の手法との比較が段階的に確認できる点。
小さいスケール数では図のテクスチャ情報のみが保存されており、スケール数が増加するに従い、図の詳細な形状情報などが生成されている。
SinGANの構造の重要性が見えた気がする、

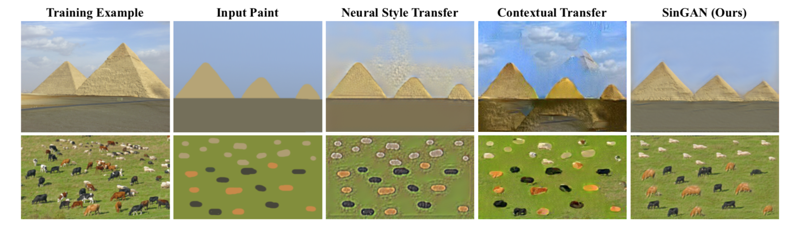
Paint to image
何度も言っているが、これまでのOne-shotでの画像変換は図のテクスチャ情報のみを扱う。
下図はそれを色濃く示した結果。
特に牧場に牛などがいる絵を再現するのは従来の研究では難しかったが、SinGANはテクスチャ以外の情報も取り入れている。
Conclusion
SinGANは様々なタスクに応用可能でネットワーク構造もシンプルなので発展が今後期待できそう。
githubもPytorchで実装されたものを筆者が公開しており簡単に実験可能だった。
次回は実装編でも書いてみようかな。