この記事は前回の記事の続き。今回はmachine learningを使って、modelをtrainして、画像のcategoryを分類するものだ。これもdata campから学んだ物だから、興味あるかたはdata campをチェックしてください。ここからは英語にします。
Import Python Libraries
This time we are going to use scikit learn and PIL to handle the image processing and machine learning.
# used to change filepaths
import os
import matplotlib as mpl
import matplotlib.pyplot as plt
from IPython.display import display
%matplotlib inline
import pandas as pd
import numpy as np
from PIL import Image
from skimage.feature import hog
from skimage.color import rgb2grey
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# import train_test_split from sklearn's model selection module
from sklearn.model_selection import train_test_split
# import SVC from sklearn's svm module
from sklearn.svm import SVC
# import accuracy_score from sklearn's metrics module
from sklearn.metrics import roc_curve, auc, accuracy_score
Display image of each bee type
Now that we have all of our imports ready, it is time to look at some images. We will load our labels.csv file into a dataframe called labels, where the index is the image name (e.g. an index of 1036 refers to an image named 1036.jpg) and the genus column tells us the bee type. genus takes the value of either 0.0 (Apis or honey bee) or 1.0 (Bombus or bumble bee).
The function get_image converts an index value from the dataframe into a file path where the image is located, opens the image using the Image object in Pillow, and then returns the image as a numpy array.
We'll use this function to load the sixth Apis image and then the sixth Bombus image in the dataframe.
# load the labels using pandas
labels = pd.read_csv("datasets/labels.csv", index_col=0)
# show the first five rows of the dataframe using head
display(labels.head())
def get_image(row_id, root="datasets/"):
"""
Converts an image number into the file path where the image is located,
opens the image, and returns the image as a numpy array.
"""
filename = "{}.jpg".format(row_id)
file_path = os.path.join(root, filename)
img = Image.open(file_path)
return np.array(img)
# subset the dataframe to just Apis (genus is 0.0) get the value of the sixth item in the index
apis_row = labels[labels.genus == 0.0].index[5]
# show the corresponding image of an Apis
plt.imshow(get_image(apis_row))
plt.show()
# subset the dataframe to just Bombus (genus is 1.0) get the value of the sixth item in the index
bombus_row = labels[labels.genus == 1.0].index[5]
# show the corresponding image of a Bombus
plt.imshow(get_image(bombus_row))
plt.show()
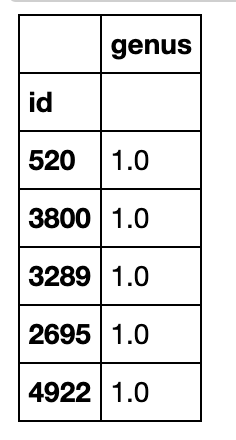
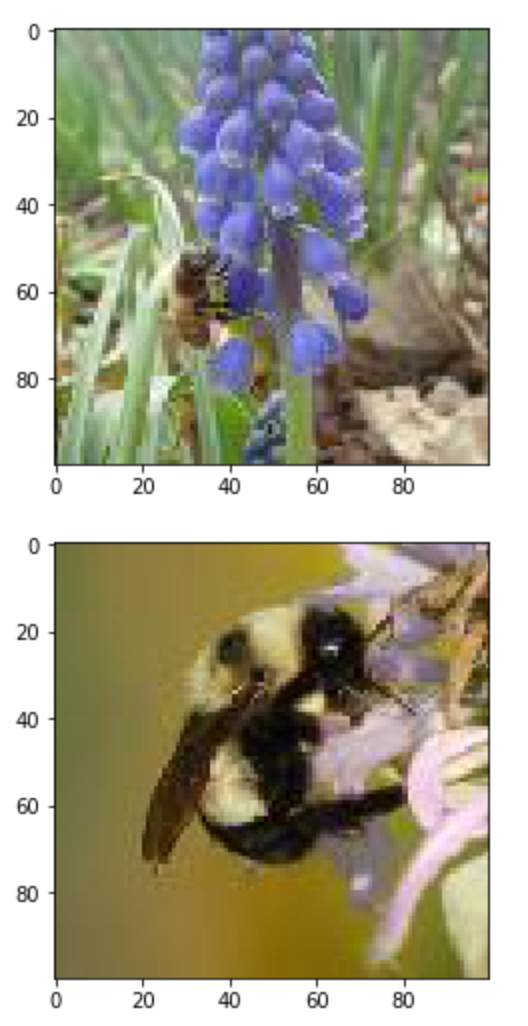
Image manipulation with rgb2grey
scikit-image has a number of image processing functions built into the library, for example, converting an image to greyscale. The rgb2grey function computes the luminance of an RGB image using the following formula Y = 0.2125 R + 0.7154 G + 0.0721 B.
Image data is represented as a matrix, where the depth is the number of channels. An RGB image has three channels (red, green, and blue) whereas the returned greyscale image has only one channel. Accordingly, the original color image has the dimensions 100x100x3 but after calling rgb2grey, the resulting greyscale image has only one channel, making the dimensions 100x100x1.
# load a bombus image using our get_image function and bombus_row from the previous cell
bombus = get_image(bombus_row)
# print the shape of the bombus image
print('Color bombus image has shape: ', ...)
# convert the bombus image to greyscale
grey_bombus = rgb2grey(bombus)
# show the greyscale image
plt.imshow(grey_bombus, cmap=mpl.cm.gray)
# greyscale bombus image only has one channel
print('Greyscale bombus image has shape: ', 1)

Histogram of oriented gradients
Now we need to turn these images into something that a machine learning algorithm can understand. Traditional computer vision techniques have relied on mathematical transforms to turn images into useful features. For example, you may want to detect edges of objects in an image, increase the contrast, or filter out particular colors.
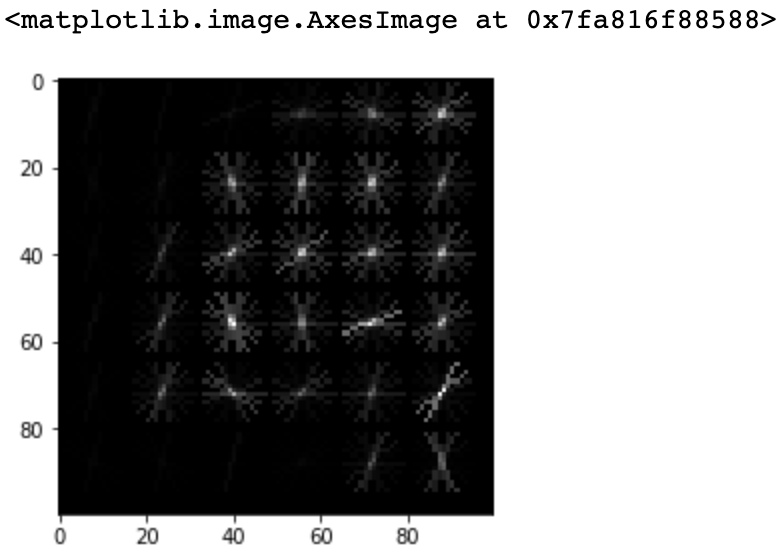
We've got a matrix of pixel values, but those don't contain enough interesting information on their own for most algorithms. We need to help the algorithms along by picking out some of the salient features for them using the histogram of oriented gradients (HOG) descriptor. The idea behind HOG is that an object's shape within an image can be inferred by its edges, and a way to identify edges is by looking at the direction of intensity gradients (i.e. changes in luminescence).
HOG

An image is divided in a grid fashion into cells, and for the pixels within each cell, a histogram of gradient directions is compiled. To improve invariance to highlights and shadows in an image, cells are block normalized, meaning an intensity value is calculated for a larger region of an image called a block and used to contrast normalize all cell-level histograms within each block. The HOG feature vector for the image is the concatenation of these cell-level histograms.
# run HOG using our greyscale bombus image
hog_features, hog_image = hog(grey_bombus,
visualize=True,
block_norm='L2-Hys',
pixels_per_cell=(16, 16))
# show our hog_image with a grey colormap
plt.imshow(hog_image, cmap=mpl.cm.gray)
Create image features and flatten into a single row
Algorithms require data to be in a format where rows correspond to images and columns correspond to features. This means that all the information for a given image needs to be contained in a single row.
We want to provide our model with the raw pixel values from our images as well as the HOG features we just calculated. To do this, we will write a function called create_features that combines these two sets of features by flattening the three-dimensional array into a one-dimensional (flat) array.
def create_features(img):
# flatten three channel color image
color_features = img.flatten()
# convert image to greyscale
grey_image = rgb2grey(img)
# get HOG features from greyscale image
hog_features = hog(grey_image, block_norm='L2-Hys', pixels_per_cell=(16, 16))
# combine color and hog features into a single array
flat_features = np.hstack([color_features, hog_features])
return flat_features
bombus_features = create_features(bombus)
# print shape of bombus_features
print(bombus_features.shape)
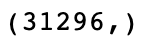
Loop over images to preprocess
Above we generated a flattened features array for the bombus image. Now it's time to loop over all of our images. We will create features for each image and then stack the flattened features arrays into a big matrix we can pass into our model.
In the create_feature_matrix function, we'll do the following:
- Load an image
- Generate a row of features using the create_features function above
- Stack the rows into a features matrix
In the resulting features matrix, rows correspond to images and columns to features.
def create_feature_matrix(label_dataframe):
features_list = []
for img_id in label_dataframe.index:
# load image
img = get_image(img_id)
# get features for image
image_features = create_features(img)
features_list.append(image_features)
# convert list of arrays into a matrix
feature_matrix = np.array(features_list)
return feature_matrix
# run create_feature_matrix on our dataframe of images
feature_matrix = create_feature_matrix(labels)
Scale feature matrix + PCA
Our features aren't quite done yet. Many machine learning methods are built to work best with data that has a mean of 0 and unit variance. Luckily, scikit-learn provides a simple way to rescale your data to work well using StandardScaler. They've got a more thorough explanation of why that is in the linked docs.
Remember also that we have over 31,000 features for each image and only 500 images total. To use an SVM, our model of choice, we also need to reduce the number of features we have using principal component analysis (PCA).
PCA is a way of linearly transforming the data such that most of the information in the data is contained within a smaller number of features called components. Below is a visual example from an image dataset containing handwritten numbers. The image on the left is the original image with 784 components. We can see that the image on the right (post PCA) captures the shape of the number quite effectively even with only 59 components.
Our features aren't quite done yet. Many machine learning methods are built to work best with data that has a mean of 0 and unit variance. Luckily, scikit-learn provides a simple way to rescale your data to work well using StandardScaler. They've got a more thorough explanation of why that is in the linked docs.
Remember also that we have over 31,000 features for each image and only 500 images total. To use an SVM, our model of choice, we also need to reduce the number of features we have using principal component analysis (PCA).
In our case, we will keep 500 components. This means our feature matrix will only have 500 columns rather than the original 31,296.
# get shape of feature matrix
print('Feature matrix shape is: ', feature_matrix.shape)
# define standard scaler
ss = StandardScaler()
# run this on our feature matrix
bees_stand = ss.fit_transform(feature_matrix)
pca = PCA(n_components=500)
# use fit_transform to run PCA on our standardized matrix
bees_pca = pca.fit_transform(bees_stand)
# look at new shape
print('PCA matrix shape is: ', bees_pca.shape)

Split into train and test sets
Now we need to convert our data into train and test sets. We'll use 70% of images as our training data and test our model on the remaining 30%. Scikit-learn's train_test_split function makes this easy.
X_train, X_test, y_train, y_test = train_test_split(bees_pca,
labels.genus.values,
test_size=.3,
random_state=1234123)
# look at the distrubution of labels in the train set
pd.Series(y_train).value_counts([0.0,1.0])

Train model
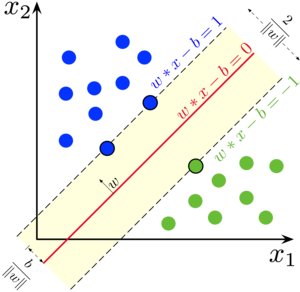
It's finally time to build our model! We'll use a support vector machine (SVM), a type of supervised machine learning model used for regression, classification, and outlier detection." An SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall."
Here's a visualization of the maximum margin separating two classes using an SVM classifier with a linear kernel.SVM
Since we have a classification task -- honey or bumble bee -- we will use the support vector classifier (SVC), a type of SVM. We imported this class at the top of the notebook.
SVM
# define support vector classifier
svm = SVC(kernel='linear', probability=True, random_state=42)
# fit model
svm.fit(X_train, y_train)

Score Model
Now we'll use our trained model to generate predictions for our test data. To see how well our model did, we'll calculate the accuracy by comparing our predicted labels for the test set with the true labels in the test set. Accuracy is the number of correct predictions divided by the total number of predictions. Scikit-learn's accuracy_score function will do math for us. Sometimes accuracy can be misleading, but since we have an equal number of honey and bumble bees, it is a useful metric for this problem.
# generate predictions
y_pred = svm.predict(X_test)
# calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print('Model accuracy is: ', accuracy)
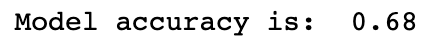
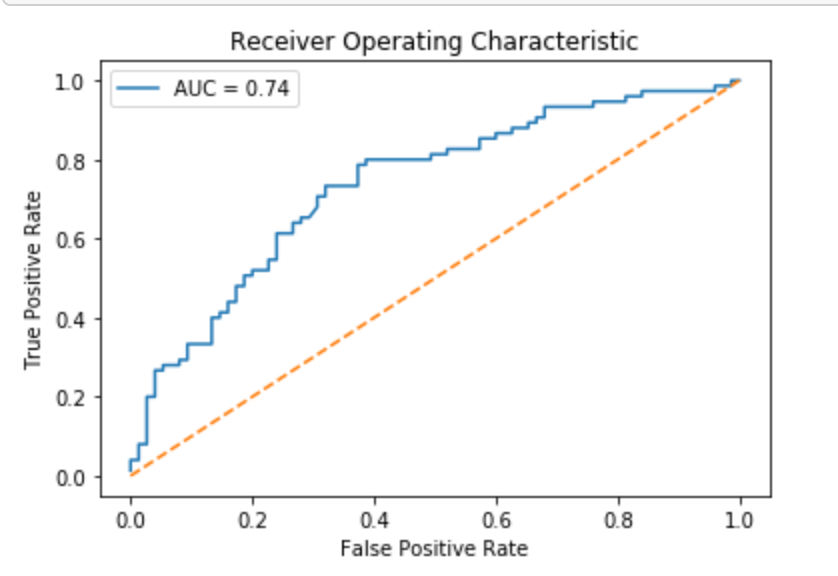
ROC curve + AUC
Above, we used svm.predict to predict either 0.0 or 1.0 for each image in X_test. Now, we'll use svm.predict_proba to get the probability that each class is the true label. For example, predict_proba returns [0.46195176, 0.53804824] for the first image, meaning there is a 46% chance the bee in the image is an Apis (0.0) and a 53% chance the bee in the image is a Bombus (1.0). Note that the two probabilities for each image always sum to 1.
Using the default settings, probabilities of 0.5 or above are assigned a class label of 1.0 and those below are assigned a 0.0. However, this threshold can be adjusted. The receiver operating characteristic curve (ROC curve) plots the false positive rate and true positive rate at different thresholds. ROC curves are judged visually by how close they are to the upper lefthand corner.
The area under the curve (AUC) is also calculated, where 1 means every predicted label was correct. Generally, the worst score for AUC is 0.5, which is the performance of a model that randomly guesses. See the scikit-learn documentation for more resources and examples on ROC curves and AUC.
# predict probabilities for X_test using predict_proba
probabilities = svm.predict_proba(X_test)
# select the probabilities for label 1.0
y_proba = probabilities[:,1]
# calculate false positive rate and true positive rate at different thresholds
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_proba, pos_label=1)
# calculate AUC
roc_auc = auc(false_positive_rate, true_positive_rate)
plt.title('Receiver Operating Characteristic')
# plot the false positive rate on the x axis and the true positive rate on the y axis
roc_plot = plt.plot(false_positive_rate,
true_positive_rate,
label='AUC = {:0.2f}'.format(roc_auc))
plt.legend(loc=0)
plt.plot([0,1], [0,1], ls='--')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate');