コーディング規約 JSP
1 本書について
1.1 目的
本規約は、JSPのコーディングを行う際に参照する規約や推奨事項を示したものである。本規約を参照することで、JSPを用いたソースコードの品質水準を一定以上に維持し、保守性の高いソフトウェアを作成することを目的とする。
1.2 実行環境
| 項目 | 前提条件 |
|---|---|
| efw | 3.0以上 |
| サポートブラウザ | ・IE 10以上、IE Edge推奨 |
| ・Firefox 最新 | |
| ・Google Chrome 最新 | |
| ・Safari 未確認 | |
| ・Android 未確認 |
2 フォーマットに関する基準
2.1 【必須】文字コードについて
2.1.1 文字コードはUTF-8(BOMなし)とする
プログラムの文字コードは、UTF-8でBOMなしとすること。
2.2 【必須】コメントの記述形式に関する基準について
2.2.1 HTMLのコメント基準
HTMLのコメント記述は、<!-- -->を使用すること。
例:
<!-- 検索条件を入力するエリア -->
<TD>検索条件①</TD>
<TD><INPUT TYPE="TEXT" ID="txt_searchCon1" STYLE="IME-MODE: DISABLED" MAXLENGTH=20></TD>
<TD>検索条件①</TD>
<TD><INPUT TYPE="TEXT" ID="txt_searchCon2" STYLE="IME-MODE: DISABLED" MAXLENGTH=20></TD>
2.2.2 JavaScriptのコメント基準
可読性を向上させるため、必要に応じてJavaScriptの説明をコメントとして記述すること。
下記にコメントの基準と記述例を示す
| No | コメント |
|---|---|
| 1 | (/* */)形式のブロックコメント |
| 2 | ({//)形式の1行コメント |
例:
/**
複数行コメント(ブロックコメント)です。
…
**/
function init() {
// 1行コメントです。
$('#txt_userName').focus();
・・・
}
2.3 【推奨】大文字と小文字について
2.3.1 HTMLは可能な限り大文字で記述する
一部の属性値(例:パスを記載する属性値)以外、大文字で記述する。
例:
<HEAD>
<TITLE>パスワード変更</TITLE>
<META CONTENT="TEXT/HTML;CHARSET=UTF-8" HTTP-EQUIV="CONTENT-TYPE">
<LINK REL=STYLESHEET TYPE=TEXT/CSS HREF="css/style.css">
・・・
</HEAD>
Eclipseでソースを大文字に変換する操作手順:
- HTMLソースを選択し右クリックでメニューを表示する。
- そのメニューの【変換】を選択し、サブメニューで【大文字に変換】を選択する。
※ショートカットキー:Ctrl + Alt + U
例外:
efwタグは上記規約を適用しない
<BODY ONLOAD="Efw('T02_search')">
<efw:Part path="T03.jsp" />
<efw:Part path="T04.jsp" />
<DIV>
<efw:Part path="head.jsp" title="親代理店一覧" />
・・・
</BODY>
3 命名規約
3.1 【推奨】ファイル名
3.1.1 共通ファイルの命名基準
使用目的を示し、英数字の名前とする。
例:
| 共通ファイル | 説明 |
|---|---|
| head.jsp | システムヘッダ部の情報を記述する |
| error.jsp | システムエラー時に表示する画面とメッセージ内容を記述する |
| paging.jsp | 画面のページング処理を記述する |
3.1.2 業務関連ファイルの命名基準
システムのコード体系に従い、命名する。
例:
業務内容に基づいて以下分類を行い、各分類名称の略語と連番にして連結する
| 分類 | 分類名称の略語 | 連番(2桁) | サンプル |
|---|---|---|---|
| ログイン関連 | LG | 01、02・・・ | LG01.jsp、LG02.jsp |
| システム関連 | SM | 同上 | SM01.jsp、SM02.jsp |
| トランザクション関連 | TS | 同上 | TS01.jsp、TS02.jsp |
| マスタ関連 | MT | 同上 | MT01.jsp、MT02.jsp |
3.2 【推奨】JavaScript関数の命名について
※JSPにおいてJavaScript関数はできるかぎり記述しない
3.2.1 業務関連関数の命名基準
- 動詞または動詞+名詞となるように命名する
- ローワーキャメルケース(lower camel case)を使う
単語の先頭を大文字にしてつなげる
最初の文字を小文字にする
例:
| 違反サンプル | 修正サンプル |
|---|---|
| userRowSelect | selectUserRow |
3.2.2 html イベントハンドラより呼出し関数の命名基準
イベントハンドラ名に要素のID名あるいはClass名をつける
例:
| イベントハンドラ | サンプル |
|---|---|
| ONLOAD | body_onLoad |
| ONCLICK | btn_add_onClick |
| ONDBLCLICK | btn_del_dblClick |
3.3 【推奨】ローカル変数の命名について
3.3.1 タグID
コントロール種類に基づいて分類し、各分類の略語を先頭につける。
| No. | HTML要素 | タイプ属性 | 接頭文字 |
|---|---|---|---|
| 1 | INPUT | text | txt_ |
| 2 | password | pw_ | |
| 3 | checkbox | chk_ | |
| 4 | radio | radio_ | |
| 5 | button | btn_ | |
| 6 | file | file_ | |
| 7 | hidden | hid_ | |
| 8 | TEXTAREA | - | txta_ |
| 9 | SELECT | - | sel_ |
例:
<TD>検索条件①</TD>
<TD><INPUT TYPE="TEXT" ID="txt_searchCon1" STYLE="IME-MODE: DISABLED" MAXLENGTH=20></TD>
<TD>検索条件①</TD>
<TD><INPUT TYPE="TEXT" ID="txt_searchCon2" STYLE="IME-MODE: DISABLED" MAXLENGTH=20></TD>
3.3.2 HTMLのCLASS
- デザイン関連のCLASSについては、制限しない
- 業務関連のCLASSについては、HTMLのID命名規則に従う
※ダイアログ画面用のID(DIVタグ内で)を定義する場合、ダイアログ画面の要素についてCLASSで定義すること。
例:
<!--ダイアログ画面はIDで定義-->
<DIV CLASS="DIALOG" ID="S02" STYLE="DISPLAY:NONE">
<TABLE STYLE="WIDTH:100%">
<COLGROUP>
<COL WIDTH=100PX>
<COL>
</COLGROUP>
<!--ダイアログ画面の要素はCLASSで定義-->
<TR><TD>ユーザID</TD><TD><INPUT CLASS="txt_userId" TYPE="TEXT" ・・・></TD></TR>
<TR><TD>ユーザ名</TD><TD><INPUT CLASS="txt_userName" TYPE="TEXT" ・・・></TD></TR>
<TR><TD>メールアドレス</TD><TD><INPUT CLASS="txt_eMail" TYPE="TEXT" ・・・>
</TABLE>
<DIV STYLE="TEXT-ALIGN:CENTER">
<BUTTON ONCLICK="Efw('S02_save')">保存</BUTTON>
<BUTTON ONCLICK="Efw('S01_search');S02.dialog('close');">閉じる</BUTTON>
</DIV>
</DIV>
3.3.3 JavaScriptの変数
変数名はハンガリアン記法(Hungarian notation)を使う
変数名の先頭に小文字でデータ種類を示す接頭文字を付ける
| データの種類 | 接頭文字 | 使用例 |
|---|---|---|
| String 型 | str | var strFileName = ""; |
| Number 型 | num | var numHeight = 0; |
| Boolean 型 | bln | var blnDutyFlag = true; |
| Array 型 | arr | var arrAnimals = ['dog', 'cat']; |
例外:
配列の中身を逐次処理するループカウンタ変数は、i,j,keyなどを使用する。
3.4 URLパラメータについて
3.4.1 【必須】標準的なパラメータのみ使用する
標準的なパラメータ:クエッションマーク (?) の後にある変数値がイコール (=) で示す
3.4.2 【推奨】パラメータの命名について
小文字で記述する。
3.4.3 【必須】パラメータの値について
コード類のみ使用可とする。
※名称類を引き渡すと、エンコードの問題があるので、名称類を使用不可とする。
コーディング規約 Event JS
1 本書について
1.1 目的
本書は、efwにおいて、「event」フォルダー配下のJavaScriptのコーディングを行う際に参照する規約や推奨事項を示したものである。本書を参照することで、JavaScriptを用いたソースコードの品質水準を一定以上に維持し、保守性の高いソフトウェアを作成することを目的とする。
2 フォーマットに関する基準
2.1 【必須】文字コードについて
2.1.1 文字コードはUTF-8(BOMなし)とする
プログラムの文字コードは、UTF-8でBOMなしとすること。
2.2 【推奨】フォーマット
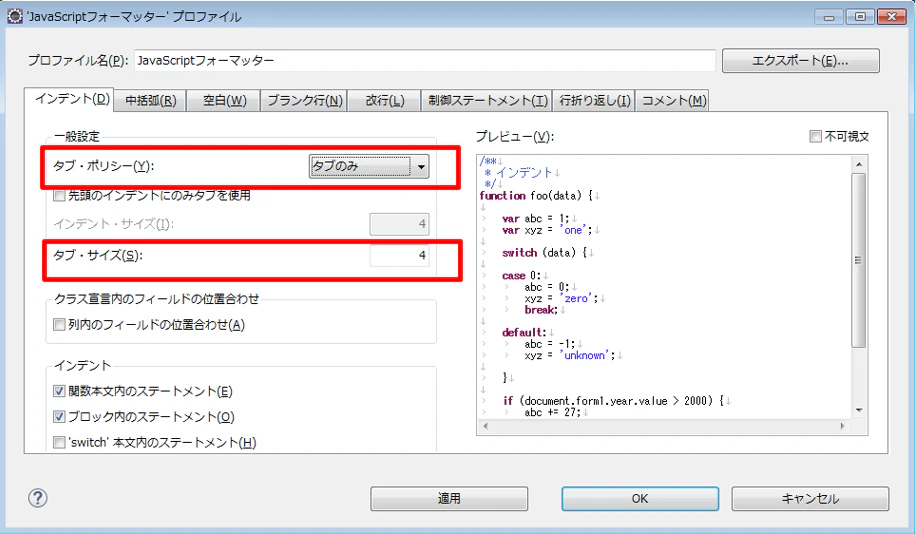
2.2.1 インデント基準
eclipseのデフォルト設定を流用する。
インデントに利用する文字 → タグ
インデント・サイズ → 4文字
eclipseのインデント設定変更手順
フォーマッターがカスタマイズされて、上記基準に合わない場合、eclipseでインデントの設定変更が可能です。
① ウィンドウ -> 設定 -> JavaScript -> コードスタイル -> フォーマッター
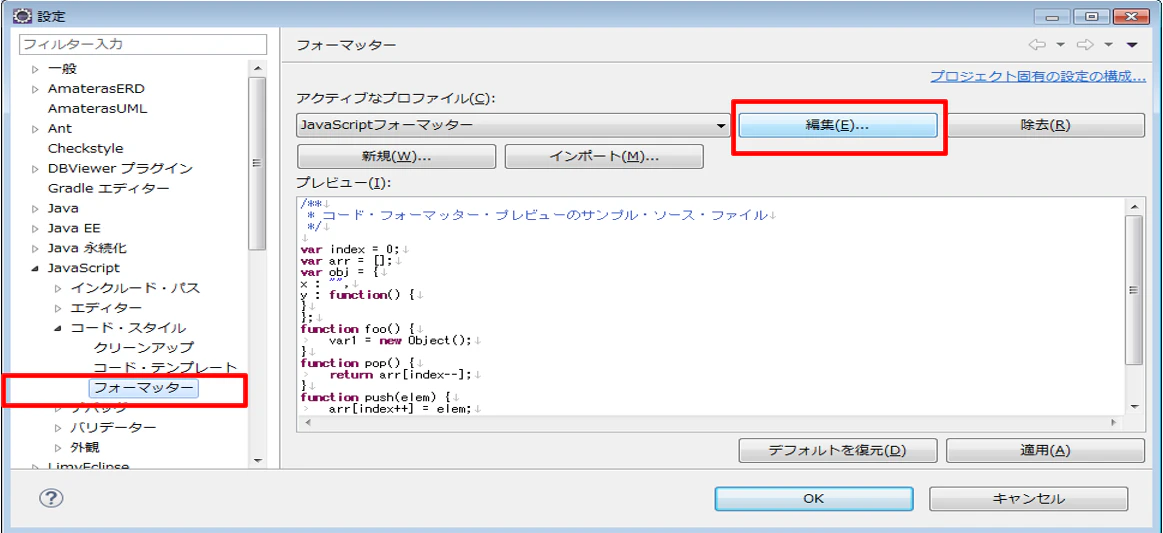
② 上記画面の編集ボタン押下よりアクティブなプロファイルの編集画面が表示される
2.2.2 改行基準
基本:
①文が長く、120文字の制限を超えてしまう場合適切に改行を行う。
②読みやすい形式で改行を行う。
下記の場合、改行基準を定める。
① Params Formatの場合
引数ごとに改行を行う。
例:
K01_search.paramsForma{
"#txt_name":null, //コメント
"#txt_address":null, //コメント
"#txt_age":null //コメント
};
② DB操作関数呼出しの場合
引数ごとに改行を行う。
例:
var rsM_USER = db.select(
"T02", //コメント
"selM_USER", //コメント
{...} //コメント
);
③ Recordのmap関数を使用する場合
引数ごとに改行を行う。
例:
var arrM_USER = rsM_USER.map({
"strA":"data1", //コメント
"strB":["data2","#,##0"], //コメント
"strC":["data3","yyyy/MM/dd"] //コメント
}).getArray();
④ メソッドチェーンの場合
メソッドの前で行を行う。
例:
return (new Result())
.runat("#sel_county1") //コメント
.append("<option value='{strCounty}'>{strCounty}</option>") //コメント
.withdata(data) //コメント
.runat("#sel_county2") //コメント
.append("<option value='{strCounty}'>{strCounty}</option>") //コメント
.withdata(data); //コメント
⑤ 式が長い場合
演算子の直後で改行を行う
例:
.append("<tr>" +
"<td title='{strA}'>{strA}</td>" + //コメント
"<td title='{strB}'>{strB}</td>" + //コメント
"<td title='{strC}'>{strC}</td>" + //コメント
"<td title='{strD}'>{strD}</td>" + //コメント
"<td title='{strE}'>{strE}</td>" + //コメント
"</tr>")
2.3 【推奨】Eclipseのデフォルトフォーマッタを適用しないこと
Eclipseのデフォルトフォーマッタの適用によりソースの可読性が落ちる恐れがあるため、Eclipseのデフォルトフォーマッタを適用しない。
例:
Eclipseのフォーマッタの適用前
.append("<tr>" +
"<td title='{strA}'>{strA}</td>" + //コメント
"<td title='{strB}'>{strB}</td>" + //コメント
"<td title='{strC}'>{strC}</td>" + //コメント
"<td title='{strD}'>{strD}</td>" + //コメント
"<td title='{strE}'>{strE}</td>" + //コメント
"</tr>")
Eclipseのフォーマッタの適用後
.append(
"<tr>" + "<td title='{strA}'>{strA}</td>" + "<td title='{strB}'>{strB}</td>" + "<td title='{strC}'>{strC}</td>" + "<td title='{strD}'>{strD}</td>" + "</tr>"
)
2.4 【必須】コメントの記述形式
目的別にコメント記号を使い分ける。
定義したオブジェクトのAPI仕様を記述するコメントと、それ以外の可読性向上を目的としたインラインコメントで、コメント記号を使い分けること。それぞれ利用するコメント記号は、下記記述例の通りとする。
2.4.1 API仕様を記述するコメント
/**
* 桁数をチェックする
* @param {number} 最大桁数
* @param {number} 最小桁数
* @return {boolean} チェック結果
*/
2.4.2 インラインコメント
・複雑なロジックを理解するためのヒントを記述
・以下ソースの箇所はインラインコメントの記述を推奨する
① Params Format
各パラメータの説明 例: 2.2.2 ① を参照
② DB操作関数呼出し
各パラメータの説明 例: 2.2.2 ② を参照
③ Recordのmap関数
各パラメータの説明 例: 2.2.2 ③ を参照
④ メソッドチェーン
各メソッドの説明 例: 2.2.2 ④ を参照
2.5 【必須】セミコロンの基準について
2.5.1 文末のセミコロンは省略しない
文末のセミコロン「;」は、JavaScriptの言語仕様としては省略可能であるが、可読性を高めるため、
そしてミニファイ実施後のスクリプトが実行時にエラーとなる可能性があるため、必須とする。
禁止する例:
var strHoge = ""
守るべき例:
var strHoge = "";
2.6 【必須】記法
2.6.1 オブジェクトの定義
オブジェクトの生成は、オブジェクトリテラルによる生成する。
例:
var objCustomer = {
"strName" : "taro", //コメント
"numAge" : 22, //コメント
"check" : function(numMaxDigit, numMinDigit){ //コメント
//...
}
};
2.6.2 配列の定義
配列は配列リテラルを使って配列を宣言する。(new演算子によるオブジェクトの生成は行わない。)
禁止する例:
var arrAnimals = new Array('dog', 'cat');
守るべき例:
var arrAnimals = {'dog', 'cat'};
3 ファイルの粒度
3.1 【必須】画面のイベント毎にjsファイルを作成する。
複雑な処理、共通的な処理の場合、業務に合わせてファイルを分割する。
※1jsファイルの行数を1000行位とする。
3.2 【推奨】業務処理毎にjsファイルを作成する。
4 命名規約
4.1 イベントID
4.1.1 【必須】画面のイベント毎に作成したjsファイルの場合
イベントID : 「画面ID + "_" + イベント名」
イベント名について:
① 動詞または動詞+名詞となるように命名する
② ローワーキャメルケース(lower camel case)を使う
例:
ログイン画面(LG01)のクリアボタン押下時→ "LG01_clear"
4.1.2 【推奨】業務処理毎に作成したjsファイルの場合
イベントID : 「業務ID」
4.1.3 【推奨】サブフォルダーについて
必要に応じて(大規模開発等)、「event」フォルダーの配下にサブフォルダーを作成することは可能です。
サブフォルダーを作成する場合、イベントIDの中にパスを含む必要がある。
例:
「LG」サブフォルダーを作成した場合、
ログイン画面(LG01)のクリアボタン押下時 → "LG/LG01_clear"
4.2 【必須】ファイル名
「イベントID + ".js"」とする。
※イベントIDの中にパスが含まれている場合、サブフォルダーを作成して、ファイル名からパスを除く。
例:
LG01_clear.js
4.3 【推奨】関数
① 動詞または動詞+名詞となるように命名する
② ローワーキャメルケース(lower camel case)を使う
・単語の先頭を大文字にしてつなげる
・最初の文字を小文字にする
例:
行編集ボタンのクリックイベント → editRow
4.4 パラメータ
4.4.1 【必須】セレクター
JSPの画面要素の名前にあわせる。
4.4.2 【推奨】マニュアルパラメータ
小文字で記述する。
例:
JSファイル
T01_maintain.paramsFormat = {
// 名前
"#txt_name":null,
// 住所
"#txt_address":null,
// 年齢
"#txt_age":null,
// 処理モード
"mode":null
};
※上記のJSファイルの paramsFormat 内に定義されているセレクターは、"#txt_name"、"#txt_address"、"#txt_age" です。"mode"はマニュアルパラメータです。
JSファイル
// 完了解除
function edit(){
var strMode = "edit";
Efw("T01_maintain",
{
"mode":strMode
}
);
}
…
<TD>名前</TD>
<TD><INPUT TYPE="TEXT" ID="txt_name" …></TD>
<TD>住所</TD>
<TD><INPUT TYPE="TEXT" ID="txt_address" …></TD>
<TD>年齢</TD>
<TD><INPUT TYPE="TEXT" ID="txt_age" …></TD>
※上記のJSファイルの paramsFormat 内に定義されているセレクターは、JSPファイルのHTML要素と対応しています。
具体的には、paramsFormat 内の "#txt_name"、"#txt_address"、"#txt_age" は、それぞれJSPファイル内の 、、 の要素に対応しています。
"mode"はJSPファイル内の"mode"マニュアルパラメータに対応しています。
これらのセレクターは、 Efwフレームワーク (おそらく独自のJavaScriptフレームワーク) を介して、JSPファイルのフォーム要素の値を取得し、JSファイルの paramsFormat に定義された変数に格納するため使用されます。
4.5 【推奨】ローカル変数
4.5.1 ハンガリアン記法(Hungarian notation)を使う
変数名の先頭に小文字でデータ種類を示す接頭文字を付ける
| データの種類 | 接頭文字 | 使用例 |
|---|---|---|
| String 型 | str | var strFileName = ""; |
| Number 型 | num | var numHeight = 0; |
| Boolean 型 | bln | var blnDutyFlag = true; |
| Array 型 | arr | var arrAnimals = ['dog', 'cat']; |
| Object 型 | obj | var objCustomer = {}; |
| RecordSet (DB検索結果など) | rs | var rs診断テーブル = db.select("TO2", "sel診断テーブル", {}); |
| RecordSet(Array) | arr | var arr診断テーブル = db.select("TO2", "sel診断テーブル", {}).getArray(); |
| RecordSet(row) | data | var data診断テーブル = db.select("TO2", "sel診断テーブル", {}).getSingle(); |
| Parameter | param | var paramFileName = ""; |
| Result (返却する結果) | rst | var rstSearch = new Result(); |
例外:
配列の中身を逐次処理するループカウンタ変数は、i,j,kなどを使用する。
4.5.2 DB操作に関連する変数
DBのテーブルの名前、項目の名前を使用して命名する。
※DBのテーブルの名前、項目の名前は日本語で命名されている場合、変数名の中で日本語も使用可能
例:
DBのテーブルの名前を使用して命名する例
var rs診断テーブル = db.select(
"T02",
"sel診断テーブル",
{}
);
DBの項目の名前を使用して命名する例
var strKijunnDate =
db.select(
"T01",
"selKijunnDate",
{}
).getSingle();
4.5.3 画面から渡されたパラメータを使用して何らかの処理を行う場合に定義するローカル変数について
画面の要素の名前を使用して命名する。
例:
var strFreeWord = params["#txt_freeWord"]
コーディング規約 外だしSQL
1 本書について
1.1 目的
本書は、efwにおいて、「sql」フォルダー配下のXMLファイルに外だしSQLのコーディングを行う際に
性能、保守性等に留意した記述を行うための基準集である。
2 フォーマットに関する基準
2.1 【必須】文字コードについて
2.1.1 文字コードはUTF-8(BOMなし)とする
プログラムの文字コードは、UTF-8でBOMなしとすること。
2.2 【推奨】SQLフォーマット
2.2.1 大文字/小文字について
SQL文中のキーワード(予約語)、関数は大文字で、DBオブジェクト等の名前は小文字で記述する。
① SELECT、ORDER BY等のキーワード(予約語)は大文字で記述する。
② テーブル名、列名等の名前は小文字で記述する。
2.2.2 改行/インデント基準
(1) インデント文字/文字サイズ
| No | 項目 | 基準 |
|---|---|---|
| 1 | 行の最大幅 | 120文字 |
| 2 | インデント文字 | タブ |
| 3 | インデントのサイズ | 4文字 |
(2) DML文の改行/インデント基準
DML文(SELECT/INSERT/UPDATE/DELETE)の改行/インデントの基準を下記に示す。
| No | 項目 | 改行 | インデント |
|---|---|---|---|
| 1 |
SELECT/INSERT INTO table / UPDATE table / DELETE FROM table 句の後 |
○ | ○ |
| 2 |
SELECT/INSERT INTO/UPDATE 文のカラム名の後 |
○ | × |
| 3 |
FROM 句の前後 |
○ | ○ |
| 4 |
WHERE 句の前後 |
○ | ○ |
| 5 |
GROUP BY 句の前後 |
○ | ○ |
| 6 |
HAVING 句の前後 |
○ | ○ |
| 7 |
ORDER BY 句の前後 |
○ | ○ |
| 8 |
INSERT 文内の VALUES 句の前後 |
○ | ○ |
| 9 |
UPDATE 文内の SET 句の前後 |
○ | ○ |
| 10 |
FROM 句内の JOIN 句 (LEFT JOIN, OUTER JOIN 含む) の前 |
○ | × |
| 11 |
JOIN 句内の ON の前 |
○ | × |
| 12 |
CASE 式の WHEN の前※ただし、 THEN と ELSE の2択の場合は改行しない |
○ | ○ |
| 13 |
CASE 式の THEN の前後 |
× | × |
| 14 |
CASE 式の ELSE の前※ただし、 THEN と ELSE の2択の場合は改行しない |
○ | ○ |
| 15 |
CASE 式の END の前※ただし、 THEN と ELSE の2択の場合は改行しない |
○ | × |
| 16 | 条件式の論理演算子 (AND/OR) の前※ただし、「 0 < item_a AND item_a < 200」のような2つの条件式をセットで1行とした方が意味を把握しやすい条件文は、論理演算子前の改行の対象外とする |
○ | × |
例:
SELECT
a.column1,
a.column2,
b.column3
FROM
tablea a,
JOIN tableb b
ON a.id = b.id
WHERE
a.prime_flg = '1'
AND a.del_flg = '0'
case式の例①
SELECT
dept_name,
office,
CASE result
WHEN 'a' THEN 'green'
WHEN 'b' THEN 'yellow'
WHEN 'c' THEN 'red'
ELSE 'gray'
END
FROM
dept_performance
WHERE
year = '2016'
case式の例②(thenとelseの2択の場合は改行しない)
SELECT
dept_name,
CASE dept_kind WHEN 'j' THEN '日本' ELSE '海外' END,
SUM(CASE WHEN sex = 'm' THEN 1 ELSE 0 END),
SUM(CASE WHEN sex = 'f' THEN 1 ELSE 0 END)
FROM
employee
GROUP BY
dept_name,
dept_kind
2.3 【必須】コメントの記述形式
可読性を向上させるため、必要に応じてSQLの説明をコメントとして記述すること。
下記にコメントの基準と記述例を示す
| No | コメント |
|---|---|
| 1 | (/** **/)形式のブロックコメント |
| 2 | (//)形式の1行コメント |
| 3 | ()形式の1行コメント |
例:
<sql id="selPurchase">
/**
複数行コメント(ブロックコメント)です。
…
**/
SELECT
p.dcnt,
g.sname,
s.scnt
FROM
purchase p
//1行コメントです。
INNER JOIN goods g
ON p.dno = g.dno
LEFT OUTER JOIN stock s
ON g.dno = s.dno
WHERE
<!-- 1行コメントです。 -->
p.tcode = 'a';
</sql>
3 ファイルの粒度
【推奨】システムの規模、業務内容により、画面毎又は業務毎又はテーブル毎に「XML」ファイルを作成する。
4 命名規約
4.1 【推奨】ファイル名
ファイルの粒度より、以下の命名基準とする。
| No | ファイルの粒度 | ファイル名 |
|---|---|---|
| 1 | 画面毎 | 「画面ID + ".xml"」 |
| 2 | 業務毎 | 「業務ID + ".xml"」 |
| 3 | テーブル毎 | 「テーブル物理名」 + ".xml" |
4.2 【推奨】ファイル名
①動詞または動詞+名詞となるように命名する
②ローワーキャメルケース (lower camel case)を使う
・単語の先頭を大文字にしてつなげる
・最初の文字を小文字にする
例:
ユーザ情報を検索するSQL文 → "selectUserInfo"
4.3 【推奨】パラメータ
パラメータ名は、関連項目名と同じにする。
例:
INSERT INTO table_1 (
field1,
field2
) VALUES (
:field1, -- パラメータ
:field2 -- パラメータ
)
5 SQLコーディング内容に関する基準
5.1 SQL文の表記に関する基準
5.1.1 【必須】 SELECT句では「*」を使用せず、列名を明記する
SELECT句にて「*」を使用するとメンテナンス性に欠ける文になる。また、解析処理の実行やI/O増加によりパフォーマンス低下にもつながる。
SELECT句には(すべての列を取得する場合でも)列名を記述すること。
5.1.2 【必須】 insert句でinto後の列名を省略せずに記入する
insert文にて列名を記述しないと、values句の値をどの列に挿入しているかについてを文の記述からだけでは把握できず、メンテナンス性に欠ける文になる。
5.1.3 【必須】order byには列番号ではなく列名を指定する
order by句でのソートキーに列番号を指定することもできる。しかし、ソートキーを列番号で指定した場合、SELECT句で指定する列に追加や削除があった際、さらに、列番号では一目でソートキーが把握できないため、ソートキーには列名を指定すること。
5.1.4 【必須】複数の表を利用する場合、すべての表に表別名を定義し、列を修飾する
複数の表を利用する複雑なクエリにおいて、列を表名や表別名で修飾しないと、列が属する表の把握が困難である。
また、表別名を用いずに表名で列を修飾した場合、「表名.列名」の記述で文が長くなり、列名が目立たない可読性の低いクエリとなってしまうことが多い。
5.1.5 【必須】表別名は表に関連性のある短い名前とする
(1) 概要
表別名(エイリアス)はSQL文の読みやすさに影響する。
SQL文の可読性を上げるため、表別名には“a”, “b”, “c”など意味のない名前ではなく、表名の頭文字や、表名の省略形など、表に関連性のある短い名前を付けること。
(2) 記述例
悪い例:
SELECT
a.scnt,
b.sname,
c.zcnt
FROM
purchase a
INNER JOIN goods b
ON a.dno = b.dno
LEFT OUTER JOIN stock c
ON b.dno = c.dno
WHERE
a.tcode = 'a';
表別名に“a”, “b”, “c”など意味のない名前をつけた場合、“a”, “b”, “c”がそれぞれどのテーブルを示しているのか分かりずらい。
良い例:
SELECT
p.scnt,
g.sname,
s.zcnt
FROM
purchase p
INNER JOIN goods g
ON p.dno = g.dno
LEFT OUTER JOIN stock s
ON g.dno = s.dno
WHERE
p.tcode = 'a';
表別名を表名の頭文字(PURCHASE→P、GOODS→G、STOCK→S)としていることで、どのテーブルを指しているのか分かりやすい。
5.2 FROM句に関する基準
5.2.1 【必須】暗黙のソートを伴う集合演算(ALLなしのUNION等)は原則使用しない
UNION等の集合演算子は暗黙的にソート・重複排除を行うため、性能が劣化する恐れがある。
原則はUNION ALLを使用し、UNION等は確実に重複があり、業務上やむをえない場合にのみ使用すること。
5.2.2 【必須】外部結合はWHERE句でなくOUTER JOINで結合する
(1)概要
外部結合は、WHERE句ではなくLEFT OUTER JOIN~ONを使用して記述する。
一部のDBMSでは、外部結合演算子「(+)」をWHERE句に記述する形式での外部結合をサポートしている。
しかし、外部結合演算子「(+)」を用いた外部結合は、DBMSに依存した記述形式である。
メンテナンス性・移植性の面から、外部結合はLEFT OUTER JOINで記述すること。
(2)記述例
悪い例:
DBMSに依存した形式で記述した外部結合の例
SELECT
p.scnt,
g.sname,
s.zcnt
FROM
purchase p,
goods g,
stock s
WHERE
p.tcode = 'a';
AND p.dno = g.dno
and g.dno(+) = s.dno
良い例:
DBMSに依存しないOUTER JOIN句による外部結合の例
SELECT
p.scnt,
g.sname,
s.zcnt
FROM
purchase p
INNER JOIN goods g
ON p.dno = g.dno
LEFT OUTER JOIN stock s
ON g.dno = s.dno
WHERE
p.tcode = 'a';
外部結合にはOUTER JOINを使用するとDBMS依存の記述がなくなる。
また、JOINを使用することで検索条件、結合条件が明確に分かれる。
5.2.3 【必須】外結合と内結合の混在SQLでは内結合をINNER JOINで記述する
(1) 概要
外結合と内結合を混在する場合には、内結合はINNER JOIN構文で記述する。
さらに、探索条件にて最も絞り込める表をFROM句の最初に指定すること。
ROM句にカンマで区切り表を書き並べて結合するものとLEFT OUTER JOINを混在して指定した場合、LEFT OUTER JOINが先に処理される。
探索条件にて絞り込む表がLEFT OUTER JOINの外表以外であった場合でもLEFT OUTER JOINの外表を最初に検索するため、
表が絞り込めていない状態でLEFT OUTER JOINを行い処理が遅くなる。
内結合をINNER JOIN構文にて記述し探索条件にて絞り込む表をFROM句の最初に指定することで、
絞り込んだ表を最初に検索し、少ない行数で結合処理を行うため高速に処理できる。
なお、INNER JOIN構文、LEFT OUTER JOIN構文では、FROM句の指定順に結合する。
(2) 記述例
悪い例:
FROM句にカンマ区切りとJOINでの結合が混在した例
SELECT
p.scnt,
g.sname,
s.zcnt
FROM
purchase p,
goods g
LEFT OUTER JOIN stock s
ON g.dno = s.dno
WHERE
p.dno = g.dno
AND p.tcode = 'a';
FROM句にカンマ区切りとJOINでの結合が混在した場合、カンマよりJOINが先に処理される。
括弧を利用して処理の優先順位を明示することは可能だが、可読性向上のため、カンマによる結合とJOINによる結合の混在は避ける。
上記の例では、goodsとstockの全件を外部結合後に、puchaseとの内部結合が行われるため、探索条件のp.tcode = 'a'があっても処理が遅くなる。
なお、表aと表bを内部結合後に表cを外部結合した場合と、表aに表bと表cの外部結合結果を内部結合した場合は結果が異なることにも注意し、
内部結合、外部結合の順番を考慮すること。
良い例:
FROM句の結合をJOINの利用に統一した例
SELECT
p.scnt,
g.sname,
s.zcnt
FROM
purchase p
INNER JOIN goods g
ON p.dno = g.dno
LEFT OUTER JOIN stock s
ON g.dno = s.dno
WHERE
p.tcode = 'a';
カンマ区切りの内部結合をINNER JOINによる内部結合に変更し、purchaseとgoodsの内部結合が先に行われるようにしている。
puchase表のtcodeによる絞り込み条件があるため、効率的に結合が行われる。
5.2.4 【推奨】FROM句の副問合せはなるべく用いない
(1) 概要
FROM句の副問合せを指定すると、内部導出表を作成することが多くなる。
内部導出表は、FROM句の副問合せ結果で作成する作業表であるため、作業表へのI/Oによって、性能が悪くなる。
また、内部導出表を作成すると、外側問合せに指定した探索条件は、FROM句の副問合せ結果で作成する作業表の作成後に評価するため、
インデックスが用いられず性能が悪くなる。
FROM句の副問合わせはなるべく利用しないこと。
(2) 記述例
悪い例:
SELECT
st.sname
FROM
(
SELECT
p.dno,
p.tcode
FROM
purchase p
WHERE
p.tcode = 'a'
) pt,
(
SELECT
s.dno,
s.sname
FROM
stock s
) st
WHERE
pt.dno = st.dno
FROM句の副問合わせで内部導出表が作成される。
内部導出表に対して探索条件を記述しても検索にインデックスが用いられず効率が悪い。
良い例:
FROM句での副問い合わせを排除した例
SELECT
s.sname
FROM
purchase p,
stock s
WHERE
p.dno = s.dno
and p.tcode ='a';
内部導出表を作らない副問合わせのない検索では、purchase表、stock表のインデックスが利用される。
5.3 WHERE句に関するの基準
5.3.1 【必須】探索条件はインデックスの効果を考慮して指定する
(1) 概要
探索条件(WHERE句)に指定する列や“AND”,“OR”の指定の記述によって、指定項目が同じ場合でもインデックスの効果が低い場合がある。
インデックスを最大限利用できるよう条件指定を行うこと。
特に、複合インデックスでインデックス構成列の前方の列を指定しないとインデックスが利用されないため、
インデックス構成列の先頭から該当する項目までを探索条件に含める探索条件とできないかを検討すること。
(2) 記述例
複合インデックスに対する探索条件の指定とインデックスの効果を示した記述例は下記のとおり。
なお、前提として複合インデックスAを項目A、B、Cの順で定義しているものとする。
① 全てand条件の場合の例(インデックスの先頭項目なし)
WHERE
項目B = 値B
AND 項目D = 値D
AND 項目C = 値C
探索条件にインデックスの先頭項目「項目A」が含まれていないためインデックスが利用されない。
② 全てand条件の場合(インデックス定義の第1項目、第3項目あり)
WHERE
項目A = 値A
AND 項目D = 値D
AND 項目C = 値C
インデックス定義の先頭項目「項目A」の検索にインデックスが利用される。
インデックスの第2項目が条件に含まれていないため、「項目C」の検索にインデックスは利用されない。
③ 全てand条件の場合の例(項目の順番が入れ替わる場合)
WHERE
項目A = 値A
AND 項目B = 値B
AND 項目C = 値C
WHERE
項目B = 値B
AND 項目C = 値C
AND 項目A = 値A
WHERE
項目C = 値C
AND 項目B = 値B
AND 項目A = 値A
“and”で繋がれた探索条件は、指定順序がインデックスの定義順と異なっていても、適切なインデックスが利用される。
上記の例では、項目A、B、C の指定順番に関係なく、すべてインデックスが有効となる。
④ and条件とor条件の場合の例1
WHERE
(項目A = 値A)
OR (
項目A = 値A
AND 項目B = 値B)
“or”の両辺に項目Aがあるので、インデックスは有効になる。
左辺では、インデックスの先頭項目「項目A」が利用され、右辺ではインデックスの先頭および次の「項目A」「項目B」が利用される。
(インデックス検索をorの両辺で2回行う)
⑤ and条件とor条件の場合の例2
WHERE
(
項目A = 値A
AND 項目B = 値B)
OR (項目C = 値C)
「項目C」が”or”の右辺で独立している。「項目C」はインデックスの先頭ではないため、右辺の検索にインデックスは利用されない。
左辺に関しては「項目A」および「項目B」のインデックスが利用される。
5.3.2 【必須】結合条件や検索条件で、左辺と右辺のデータ型を一致させる
(1) 概要
結合条件、検索条件で比較する列や定数のデータ型が異なると、暗黙の型変換でデータ型を統一した後、比較が行われる。
この場合、インデックスは使用されないため、アクセス・パスが悪化し、性能が劣化する可能性が高くなる。
明示的にデータ型を変換した場合でもインデックスが使用されなくなるため比較する値はデータ型を必ず一致させておく必要がある。
なお、アプリケーションからSQLを発行する際、ドライバ(JDBC、ADO.NET等)の設定によってはAPからDBに値を受け渡す際にデータ型変わる可能性があるので、注意すること。
(2) 記述例
悪い例:
SELECT
g.goods_name,
g.price
FROM
goods g
WHERE
g.price = '10000'
goods表のprice列(数値型)に対する条件式の右辺が文字列で指定されている。
左辺と右辺でデータ型が異なるため、price列にインデックスが定義されていても利用されない可能性がある。
良い例:
SELECT
g.goods_name,
g.price
FROM
goods g
WHERE
g.price = 10000
goods表のprice列(数値型)に対する条件式の両辺のデータ型が同じであれば、price列のインデックスが利用される。
5.3.3 【必須】IS [NOT] NULLはインデックスが利用されないことを意識し代替条件がない場合のみ利用する
(1) 概要
IS [NOT] NULLは原則、インデックスが使用されない。
探索条件でIS [NOT] NULLは安易に使用せず、別の探索条件で代替できないかを検討すること。
代替条件がなく、IS [NOT] NULLを利用する場合、他の条件で件数の絞り込みを行ってから、IS [NOT] NULLの検索が行われるよう検討すること。
また、NULLを扱う場合はNULLを考慮するための関数(NULLIF等)が必要になるため複雑さが増す。
さらに、NULLの有無でCOUNTや相関副問い合わせ等、一部の処理で結果が変わってくる。
NULLを扱う場合は注意して利用すること。
(2) 記述例
悪い例:
SELECT
u.user_name
FROM
user u
WHERE
u.addr IS NULL
IS [NOT] NULLによる判定では、対象の列にインデックスが定義されていても、インデックスが利用されない。
良い例:
SELECT
u.user_name
FROM
user u
WHERE
u.rec_status = 'x'
AND u.addr IS NULL
検索の効率を上げるため、別の条件で絞り込みを行った後に、is null判定を行うなど、
性能を考慮したSQLを検討する必要がある。
(3) その他のNULLに関わる注意点
その他のNULLに関わる注意点
NULLに対して等号を含む比較演算子を使用しても真(TRUE)を返すことはない。
例:
aaa = NULL
aaaがNULLの場合でもTRUEにならない。
5.3.4 【推奨】検索、結合条件式において、列に対して演算、関数を使用しない
(1) 概要
条件式内の列に対して演算、関数を使用すると、インデックスが使用されず性能が劣化する可能性がある。
演算や関数が本当に必要かどうか、あらかじめアプリ側で演算ができないか等、別の方法で回避ができないかを検討することを推奨する。
また、テーブルの定義を変更することも検討する。
(2) 記述例
悪い例:
列を演算している例
SELECT
g.goods_name
FROM
goods g
WHERE
g.price * 1.05 BETWEEN 10000 AND 99999
列に関数を適用している例
SELECT
p.purchase_id
FROM
purchase p
WHERE
TO_CHAR(p.purchase_ymd, 'YYYYMMDD') = '20150808'
良い例:
列演算の修正例
SELECT
g.goods_name
FROM
goods g
WHERE
g.price BETWEEN 10500 and 104998
列への関数適用の修正例
SELECT
p.purchase_id
FROM
purchase p
WHERE
p.purchase_ymd = TO_DATE('20150808', 'YYYYMMDD')
演算、関数について、列への適用ではなく、比較する値の方に適用することで、列のインデックスを利用できるようにする。
5.3.5 【推奨】likeの条件一致検索では、中間一致、後方一致検索は避ける
(1) 概要
likeを使用した中間一致・後方一致検索はインデックスが使用されず、性能が劣化する可能性がある。
likeを使用したあいまい検索は、前方一致検索を行うことが望ましい。
中間一致等を用いる場合は、他の検索条件で絞込みを行うと性能が向上する可能性が高まる
(2) 記述例
悪い例:
likeを利用した中間一致検索の例
SELECT
u.user_id,
u.user_name
FROM
user u
WHERE
u.user_name like '%日本%'
likeでの中間一致検索、後方一致検索はインデックスが利用されない。
良い例:
likeを利用した前方一致検索の例
SELECT
u.user_id,
u.user_name
FROM
user u
WHERE
u.user_name like '日本%'
前方一致検索であれば、インデックスが利用される。
業務要件により、中間一致、後方一致の検索をやむを得ず用いる場合、可能であれば検索条件を増やし、中間一致検索、後方一致検索の対象を絞込む。
中間一致検索に他の条件を加えた例
SELECT
u.user_id,
u.user_name
FROM
user u
WHERE
u.age > 20
AND u.sex = '1'
AND u.user_name like '%日本%'
5.4 GROUP BY句、ORDER BY句に関する基準
5.4.1 【必須】ORDER BY、GROUP BY句は、インデックスを利用できるようにする
(1) 概要
order by句を指定しての照会では、インデックスを使用することで内部的なソート処理を行うことなく指定されたソート順を保証することができ、性能向上を期待できる。
また、group by句に対しても、インデックスを使用し内部的なソート処理/ハッシュ処理を行わずにグループ化できるため、性能向上を期待できる。
order by、group by句は、インデックスを利用できるように指定すること。
以下の条件を全て満たした場合、order byの実行で内部的なソート処理を回避することができる。
<A> order by句/group by句に指定する列のすべてが、同じ順序で一つのインデックスの第1構成列から連続している。
または連続しない場合には、インデックス構成列の連続しない列に、=述語(列=値指定)を探索条件に指定している。
<B> order by句のasc/desc指定と、インデックス定義時の構成列のasc/desc指定が同じか、まったく逆(本項目はgroup byには該当しない)
(2) 記述例
前提として複合インデックス(sname ASC, zcnt DESC, dno ASC)は定義済みとする。
内部的なソート処理を回避できていない例:
① asc/desc指定がインデックス定義と異なる例
SELECT
s.zcnt,
s.dno
FROM
stock s
ORDER BY
s.sname DESC,
s.zcnt DESC,
s.dno ASC
asc/desc指定がインデックス定義と異なるため、内部的なソート処理を回避できない。
② 指定順序がインデックス定義の指定順と異なる例
SELECT
s.zcnt,
s.dno
FROM
stock s
ORDER BY
s.dno ASC,
s.zcnt DESC,
s.sname DESC
指定順序がインデックス定義の指定順と異なるため、内部的なソート処理を回避できない。
③ 指定列がインデックスの先頭列から連続しない例
SELECT
s.zcnt,
s.dno
FROM
stock s
WHERE
s.sname = 'A'
ORDER BY
s.dno asc
指定列がインデックスの先頭列から連続せず、欠落列の=述語指定もないため、内部的なソート処理を回避できない。
内部的なソート処理を回避できる例:
① asc/desc指定がインデックス定義と同じ例
SELECT
s.zcnt,
s.dno
FROM
stock s
ORDER BY
sname ASC,
zcnt DESC,
dno ASC
指定順およびasc/desc指定がインデックス定義と同じであるため、内部的なソート処理を回避できる。
② asc/desc指定がインデックス定義と逆の例
SELECT
s.zcnt,
s.dno
FROM
stock s
ORDER BY
sname DESC,
zcnt ASC,
dno DESC
asc/desc指定がインデックス定義とまったく逆であるため、内部的なソート処理を回避できる。
③ order by句に未指定の列がwhere句に「=述語」で存在する例
SELECT
s.zcnt,
s.dno
FROM
stock s
WHERE
s.sname = 'A'
ORDER BY
zcnt DESC,
dno ASC
order byにインデックスの先頭列はないが、whereに「=述語」で存在するため、内部的なソート処理を回避できる。
6 XMLコーディング内容に関する基準
6.1 パラメータ
6.1.1 パラメータの種類
| No | 種類 | 使用目的 | 接頭文字(デフォルト) | 使用例 |
|---|---|---|---|---|
| 1 | パラメータ | 検索条件項目、更新項目等の値を代入する | : (半角コロン) | WHERE field = :field |
| 2 | 動的パラメータ | SQLの一部分を代入する | @ (アットマーク) | SELECT @field |
6.1.2 接頭文字の再定義
デフォルトの接頭文字(半角コロン、アットマーク)は、既に別の用途で使用されている場合、SQLタグの paramPrefix, dynamicPrefix 属性より接頭文字の再定義が可能です。
| No | 種類 | 接頭文字再定義属性 | 使用例 |
|---|---|---|---|
| 1 | パラメータ | paramPrefix | WHERE field1 = !field1 |
| 2 | 動的パラメータ | dynamicPrefix | SELECT $fieldName |
6.2 動的SQLの注意点
SQL文中の文字列連結時に空白文字のエラーが起こらないように注意する。
SQLタグの dynamicPrefix 属性で指定した接頭文字を使用する場合は '" (ダブルクォート) で囲む必要がある。
例:
<sql id="sql1" paramPrefix="!" dynamicPrefix="$">
SELECT
fieldName
FROM
tableName
WHERE
fieldId = !fieldId
</sql>
6.3 【必須】分岐
渡されたパラメータより操作を分岐させることが可能です。
分岐する時は 文を使用する。
param は NULL でない、かつ空文字でない場合、分岐結果は TRUE になる。
param は NULL、又は空文字の場合、分岐結果は TRUE になる。
例:
SELECT
u.user_id,
u.user_name
FROM
user u
WHERE
u.age < 20
<if exists="user_name">
AND u.user_name = :user_name
</if>
6.4 【必須】エンコードに関する注意事項
SQL文の中に小なり記号 (<) 、大なり記号 (>) の直接記述を禁止する。
必要な場合、以下代替文字を使用して記述する。
小なり記号 (<) → <
大なり記号 (>) → >