おはこんばんにちは
zerobillbank株式会社のインフラエンジニアtomatoことtomatoです。
今回はkubernetesシリーズの最終回ということで、
構築時のトラブルシューティングから運用・監視についてお話していきたいと思いまうす![]()
ちなみに前回の記事はこちらです![]()
「おじいちゃん kubernetesってなに?」「...それはコスモスじゃよ」(1) -概要編-
「おじいちゃん kubernetesってなに?」「...それはコスモスじゃよ」(2) -構築編-
構築のトラブルシューティング
構築時のエラーに対応として、まずPodで起こっているエラーか、
それ以外で起こっているエラーかを分類するといいと思います。
Podのエラー
Podでエラーが起こっているかを確認するのは簡単です。
kubectl get poでPodを確認した時に、正常時の場合はSTATUSがRunnning、STATUSが1/1のように分母と分子が等しくなっているはずです。
$ kubectl get po
NAME READY STATUS RESTARTS AGE
sample-775487cf8-d5czn 0/1 ImagePullBackOff 2 15m
それ以外の場合はエラーが出ていますので、
describeコマンドを使ってエラーの原因を確認します。
$ kubectl describe po sample-775487cf8-d5czn
---省略
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal BackOff 28s (x4 over 1m) kubelet, ip-xxx.internal Back-off pulling image "nginx:1.123"
Warning Failed 28s (x4 over 1m) kubelet, ip-xxx.internal Error: ImagePullBackOff
describeコマンドで対象のPodを調べると、Eventsの欄にエラーイベントが出力されます。
上記の例では存在しないnginxのバージョンを指定したため、イメージがpullできないエラーが出ていました。
調査系コマンド
上記のdescribeコマンドでも調査は可能ですが、
多くのケースでは下記の2つのコマンドのどちらかを打てば
エラー原因を見つけることができます。
logsコマンド
kubectl logs [deployment名]
get events
kubetctl get events | grep [deployment名]
アクセスできないエラー
上記以外でPodは正常に稼働しているにも関わらず
Webページなどが上手くアクセスできない場合についての対処方法についてです。
この場合、どこでアクセスが途切れているかを下記のステップで特定します。
- Podでのアクセス確認
- Service経由でのアクセス確認
- Ingress経由でのアクセス確認
Podでのアクセス確認
$ kubectl exec -it [Pod名] -- /bin/sh
alpineなどは操作系のツールが入っていないことが多いため、
その場合は下記のコマンドでインストールします。
# update
apt update
# curlのインストール
apt install -y curl
# netstatのインストール
apt install -y net-tools
# aptがない場合
apk -U add curl
apk add net-tools
動いているプロセスの確認
$ netstat -pant
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:3000 0.0.0.0:* LISTEN 1/nginx: master pro
上記コマンドで、対象のアプリケーションが動作している事と
動いているPort番号を確認します。
$ curl http://localhost:3000
welcome nginx!!
これで表示されれば 1. Podでのアクセス確認 は問題なしです。
Service経由でのアクセス確認
$ curl http://nginx:3000
welcome nginx!!
これで表示されれば 2. Service経由でのアクセス確認 は問題なしです。
よくあるミスとしては、service.yamlの中のportsの項目の
portとtargetPortの記載ミスです。
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: sample
labels:
app: nginx
spec:
type: NodePort
selector:
app: nginx
ports:
- port: 80 # Default port for image
targetPort: 80
port... image内でのPort番号。上記のPod内でnetstatした場合のPort番号になる。
targetPort... kubernetes上のPort番号。Serviceに紐付く。
この場合、image内でのPort番号は3000なので、portは80ではなく3000と記載します。
またdeployment.yaml内にもcontainerPortという項目があり
こちらはservice.yamlのtargetPortと合わせる必要があります。
Ingress経由でのアクセス確認
上記までで問題がなくてアクセスできない場合は、ドメイン周りの問題が考えられます。
実際にページにアクセスした際のエラーメッセージを基に
ドメインやSSL証明書周りを確認してみてください。
運用
kubernetesではyamlで管理することで冪等性を担保していますが
運用に置いてyamlの取り扱いで気をつけたほうがいいなーと思う点をあげてみます。
applyの前にはdiffを取る
applyコマンドで適用をする前に、必ずdiffコマンドで差分確認をしましょう。
想定外のyamlを当ててしまう事故を防げます。
# 想定の差分が出ることを確認
$ kubectl diff -f nginx/deployment.yaml
# 適用
$ kubectl apply -f nginx/deployment.yaml
# 差分が出ないことを確認
$ kubectl diff -f nginx/deployment.yaml
更新の際にはrolloutコマンドを用いる
Podの更新の際はdeleteコマンドではなく、rollout restartコマンドを使用します。
deleteコマンドでPodを削除しても、deploymentが存在していればPodは再起動されますが
削除してから再起動する間にサービスダウンが発生します。
rollout restartコマンドであれば、古いPodを残しつつ、新しいPodに順次移行してくれるため、サービスダウンなく再起動をすることができます。
configやsecretなどのリソースのみを更新する場合、Podが再起動されないと
新しい定義が読み込まれませんので、その際もrollout restartコマンドを忘れずに実行しましょう。
$ kubectl rollout restart deploy/nginx
deployment.apps/nginx restarted
おまけ
kubectl api-resourcesと打つと、利用できるリソースの一覧を表示できます。
さらにリソースごとのショートカットの名前と、yamlに記載するapiVersionも確認できるので
何かあった時に覚えておくと便利なコマンドです。
$ kubectl api-resources
NAME SHORTNAMES APIGROUP NAMESPACED KIND
bindings true Binding
componentstatuses cs false ComponentStatus
configmaps cm true ConfigMap
endpoints ep true Endpoints
events ev true Event
limitranges limits true LimitRange
namespaces ns false Namespace
nodes no false Node
persistentvolumeclaims pvc true PersistentVolumeClaim
persistentvolumes pv false PersistentVolume
pods po true Pod
...
監視
監視については色々なツールがあると思いますが、
まず手軽にやるのなら下記のツールと相性が良いと思います。
無料でUIによるログ表示から、アラート発報まで一通り必要なことができちゃいます![]()
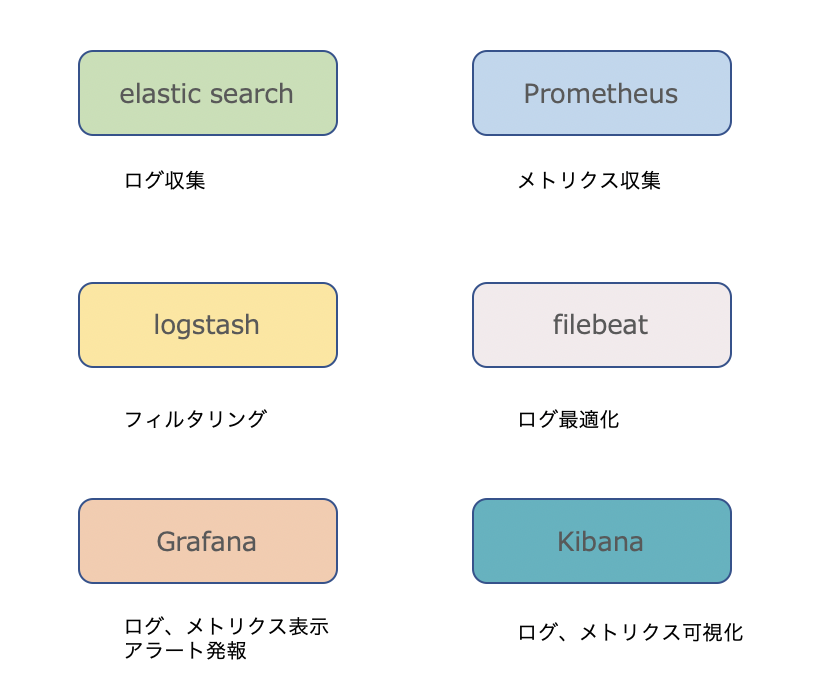
またhelm(パッケージ管理ツール)が3系になり、とても導入が楽になりました。
ただし、デフォルト設定のまま適用すると、どんな値なのかの認識や管理ができないため
一旦ローカルにfetchしてからinstallするのが良いのではと思います。
各設定値についてはvalues.yamlに記載されてますので
変更したい項目を見つけて値をいじるとinstallもしくはupgradeの際に適用されます。
インストール
helmのインストールについては下記を参照してください。
https://helm.sh/ja/docs/intro/install/
fetchする
$ helm repo update
$ helm fetch stable/filebeat
$ helm fetch stable/logstash
$ helm fetch stable/elasticsearch
$ helm fetch stable/kibana
$ helm fetch grafana/grafana
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
$ helm fetch prometheus-community/kube-prometheus-stack
installする
$ helm install -name filebeat -n monitoring -f filebeat/values.yaml stable/filebeat
$ helm install -name logstash -n monitoring -f logstash/values.yaml stable/logstash
$ helm install -name elasticsearch -n monitoring -f elasticsearch/values.yaml stable/elasticsearch
$ helm install -name kibana -n monitoring -f kibana/values.yaml stable/kibana
$ helm install -name grafana -n monitoring -f grafana/values.yaml grafana/grafana
$ helm install -name prometheus -n monitoring -f kube-prometheus-stack/values.yaml prometheus-community/kube-prometheus-stack
インストールはこれだけですのでとても簡単!
ちなみに更新したいときはinstallの部分をupgradeに変えるだけです。
Grafanaは設定周りがちょっとややこしいので、以前に書いた下記の記事を参考にしていただければと。
helm3を使用して超簡単にkubernetesにGrafanaをデプロイする方法がまるでtomato
おわり
というわけで全3回に渡ってkubernetesについて解説していきました。
気づいた点があれば随時加筆していきたいと思います。
一人でも多くkubernetes沼にハマってくれるエンジニアが増えてくれればいいなと思っております。
みなさま良いkubernetesライフを!!
ではまた🙋♂️
さいごに
ZEROBILLBANKでは一緒に働く仲間を募集中です。
なんとかjsとか、ブロックチェーンとか、kubernetesとかでいろんなAPIを作るお仕事。
今のところエンジニアは5人くらい。スタートアップだけど、結構ホワイトで働きやすいです。