書籍冊数認識アプリケーション開発
はじめに
兵庫県立大学社会情報科学部ではラーニングコモンズに本棚が設置してあります。それを筆者が所属するデータ分析研究会が管理のお手伝いをしており、毎週月曜日に本の冊数を数えて、紛失した本がないか確認していました(2022年時点)。しかし、人手で数えるのはとても手間です。そこで、本を数えてくれるAIを作ればもっと楽に管理できると考え、大学生なら誰でも持っているであろう媒体であるスマートフォンを利用し、LINEbotで本を数えてくれるアプリケーションを作ることにしました。
■イメージ図
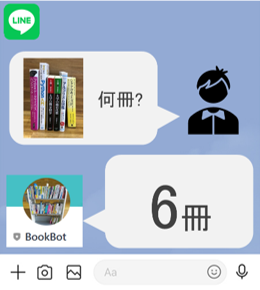
関連研究とアプローチ
本を数える方法としては本同士の境界をエッジ検出で把握して数えるという方法があります[1]。しかし、ラーニングコモンズにある本は大小さまざまで、スマホのカメラで撮影する関係で背景も映り込むため、エッジによる検出が難しいです。
そのため、今回は物体検出による方法を用います。物体検出とは画像を取り込み、画像の中から定められた物体の位置と種類、個数を特定するという技術です。これを使うことで、背景が映り込んでいたり、本が多少重なっていても、識別して書籍を数えることができます。物体検出の例は多くありますが、棚にある物体を認識する例として、商品棚から商品の識別をするという事例があります[2]。この事例から、本棚からの書籍の認識ができそうなことが分かります。しかし、これにはPythonでの実装例が載っていなかったため、実装の際は血液成分の識別をする記事を参考にします[3]。用いる手法は、SSD(Single Shot multibox Detection)300という学習済みモデルを本の識別ができるように再学習させる方法です(この方法をファインチューニングといいます)。この手法で、画像を送るとそこに映っている本の冊数を教えてくれるAIの作成を目標として取り組んでいきます。
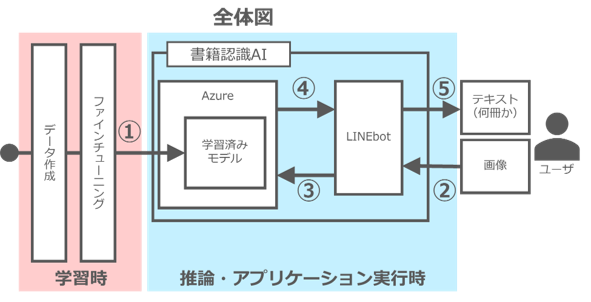
①データの作成・拡張とファインチューニング
➁ユーザがLINEbotに画像を送信
➂LINEがAzure(クラウドサービス)に画像を送り、Pythonで学習済みモデルを動かして何冊あるか推定
④何冊か結果をflask(PythonのWebアプリケーションフレームワーク)でLINEbotに送信
⑤LINEbotがユーザに冊数を送信
データセット準備
データセットを作っていきます。ファイルとコード配置の構造は以下の通りで、主にAnnotationsのところを作成していきます。

用意するデータは3種類で、本の画像と、その画像の本の位置を記録したxmlファイル、訓練用・テスト用・検証用データに分けるためのテキストファイルの3つです。画像とそれに対応するxmlファイルの作成にはアノテーションツールのlabelImgを使います。labelImgは、画像内の物体の位置情報を示す四角い枠(バウンディングボックス)を付けられるツールです。インストールと使い方は「【簡単】LabelImg(アノテーションツール)のインストール」の記事を参考にしました[4]。
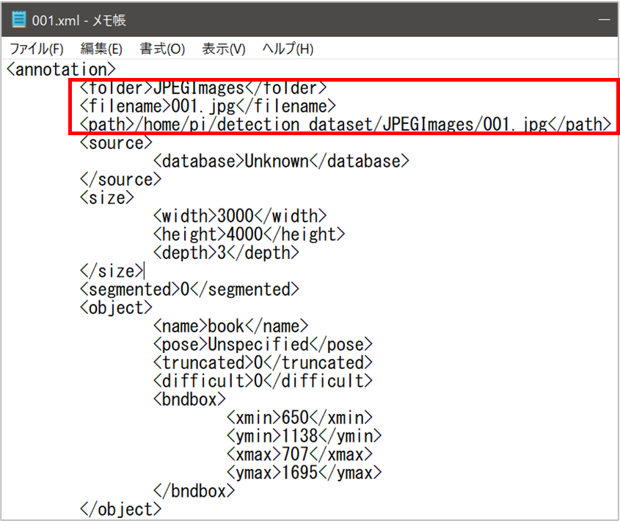
アノテーションすると以下画像のようにバウンディングボックスを付けることができます。

labelImgでバウンディングボックスを付加するとxmlファイルが生成されるので、パス名とファイル名が正しいか確認しておきます。
テキストファイルは新規作成で自分で作成します。以下のように画像ファイルの名前を記入します。

手動で作成したデータは全部で35個と少ないので、データ拡張(データオーギュメンテーション)でデータ全体の水増しをします。具体的には、色の変換と画像の角度変換を行います。色変換で10パターン、角度の変更で4パターン増やし、合計で1400個のデータにします。
ファインチューニングと推論
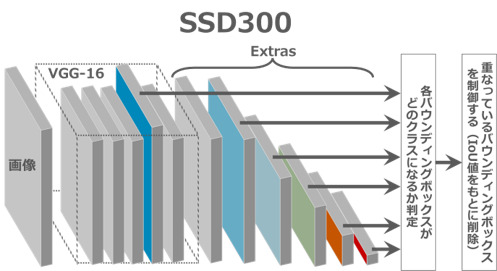
今回の記事では、学習時はGPUのTesla K80を用い、推論時はCPUでも動くように調整します。特に学習時は同じスペックでの学習を推奨します。実装では参考記事[3]のGithubからコードを拝借し、SSD学習済みモデルのパラメータをダウンロードします。各「VOCDetection, VOC_ROOT, VOCAnnotationTransform」をそれぞれ書籍物体検出用にいくつか適宜変更し、先ほど作成したデータセットを読み込みます。上手く読み込めていたら、ここからファインチューニングに入っていきます。SSDのモデル図は以下画像の通りです。
重みの初期値を学習済みモデルの重みに設定し、先ほど準備したデータセットで学習させます。 学習回数は1000回、バッチサイズ32、学習率0.001で実行しています。学習時、ある程度の本の重なりを許容するためにバウンディングボックスの閾値を0.25に設定していますが、推論時は誤った推定を防ぐために閾値を0.3に設定し直します。以下は物体検出時の関数です。
# 物体検出関数
def detect(image, labels):
# 画像を(1,3,300,300)のテンソルに変換
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
x = cv2.resize(image, (300, 300)).astype(np.float32)
x -= (104.0, 117.0, 123.0)
x = x.astype(np.float32)
x = x[:, :, ::-1].copy()
x = torch.from_numpy(x).permute(2, 0, 1)
xx = Variable(x.unsqueeze(0))
# 順伝播を実行し、推論結果を出力
if torch.cuda.is_available():
xx = xx.cuda()
y = net(xx)
# 表示設定
plt.figure(figsize=(8,8))
colors = plt.cm.hsv(np.linspace(0, 1, 21)).tolist()
plt.imshow(rgb_image)
currentAxis = plt.gca()
# 推論結果をdetectionsに格納
detections = y.data
# 各検出のスケールのバックアップ
scale = torch.Tensor(rgb_image.shape[1::-1]).repeat(2)
COUNT=0
# バウンディングボックスとクラス名を表示
for i in range(detections.size(1)):
j = 0
# 確信度confが0.3以上のボックスを表示
# jは確信度上位200件のボックスのインデックス
# detections[0,i,j]は[conf,xmin,ymin,xmax,ymax]の形状
while detections[0,i,j,0] >= 0.3:
score = detections[0,i,j,0]
label_name = labels[i-1]
display_txt = '%s: %.2f'%(label_name, score)
pt = (detections[0,i,j,1:]*scale).cpu().numpy()
coords = (pt[0], pt[1]), pt[2]-pt[0]+1, pt[3]-pt[1]+1
color = colors[i]
currentAxis.add_patch(plt.Rectangle(*coords, fill=False, edgecolor=color, linewidth=2))
currentAxis.text(pt[0], pt[1], display_txt, bbox={'facecolor':color, 'alpha':0.5})
j+=1
#バウンディングボックスの数を数える
COUNT+=1
plt.tight_layout()
plt.savefig("./results/result_books.png")
plt.show()
plt.close()
print(f"{COUNT}冊")
return detections
推論する際は、以下のコードを実行するだけで推定ができるようになります。
# SSDネットワークの定義とパラメータのロード
net = build_ssd('test', 300, 21)
net.load_weights('./weights/BOOK_1000_32_025_cpu.pth')
# 識別したい画像の読み込み
image = cv2.imread('./data/IMAGE.jpg')
# 物体検出
detections = detect(image, BOOK_CLASSES)

これで、本の冊数を認識して教えてくれるAIが完成しました。これをLINEbotとして実装します。
アプリケーションの実行
LINEbotの実装にはflaskを用います。実装は以下の通りです。
app = Flask(__name__)
# LINEbotAPIを使うための情報
YOUR_CHANNEL_ACCESS_TOKEN = {LINEのCHANNEL_ACCESS_TOKEN}
YOUR_CHANNEL_SECRET = {LINEのCHANNEL_ACCESS_SECRET}
line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN)
handler = WebhookHandler(YOUR_CHANNEL_SECRET)
# flaskでの処理
@app.route("/callback", methods=['POST'])
def callback():
# get X-Line-Signature header value
signature = request.headers['X-Line-Signature']
@handler.add(FollowEvent)
def handle_follow(event):
""" 登録時のメッセージ """
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text='認識したい画像を送ってください'))
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
""" テキストメッセージへの応答 """
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=event.message.text + '...ですよね'))
@handler.add(MessageEvent, message=ImageMessage)
def handle_image(event):
""" 画像への応答 """
message_id = event.message.id
message_content = line_bot_api.get_message_content(message_id)
pil_img = np.array(Image.open(io.BytesIO(message_content.content)))
# 物体検出
TEXT = detect(pil_img, bccd_labels)
# テキスト(何冊か)を返す
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=TEXT))
if __name__ == "__main__":
port = int(os.getenv("PORT", {ポート番号}))
app.run(host="0.0.0.0", port=port)
実装が完成したので、上記のコードを実行させながら、LINEで本の画像を送ってみます。

学習データにない書籍冊数を把握できているので、精度は高そうです。また、自宅で撮影した本でも認識できていたため、ある程度の汎化性能も確認しました。
成果・考察
今回の記事では、スマートフォンを利用し、LINEbotで本を数えてくれるアプリケーションを作成しました。SSDをファインチューニングさせた結果、少数の本の冊数を認識させることに成功しました(1~8冊まで正しく認識することを確認しました)。このことから、物体検出で本の冊数を算出するアプローチは有効であることが分かります。一方で、本棚全体の画像を送信した際は、78冊中69冊ほどしか認識できておらず、多くの本が密集している状況ではうまく機能しないことが分かりました。
重なっている本の認識のため、Jingru Yiらの研究[5]のようなバウンディングボックスを変形させた状態で学習させることが課題ですが、今後はバウンディングボックスごとに画像を切り出し、本の種類を識別できる可能性があり、今後も継続して取り組むに値する内容です。
時間をかけて取り組んだ点
今回の取り組みで時間をかけて取り組んだ点は以下の3つです。
■SSDのファインチューニングした後、ハイパーパラメータ調整
〇試行回数は20回以上
〇1回の学習につき半日~丸1日かかることもあり、難航した末に最適なモデルを選択
■教師データの自力作成とデータ拡張
〇1枚の画像につき最大78個のバウンディングボックスを作成
〇最終的には35個の自作画像をデータ拡張で増やして学習
■課題解決のためのアプリ開発 + LINEbot実装
〇書籍が増え続けるラーニングコモンズ本棚の管理を補助
この記事を見て取り組んでみたくなった方は上記の3つの難関に留意して計画的に取り組んでいただけるとスムーズにいくと思います。読んでくださりありがとうございました。
参考
[1]・・・茨田 将史「自動本棚整理機のための漫画書籍タイトル認識手法に関する研究」
https://gamescience.jp/2015/Paper/Barada_2015.pdf
[2]・・・赤塚隼ら「画像認識を用いた商品棚解析ソリューション-画像から商品の陳列情報を一括把握-」
https://www.nttdocomo.co.jp/binary/pdf/corporate/technology/rd/technical_journal/bn/vol26_2/vol26_2_005jp.pdf
[3]・・・cedro3「PyTorch 新たなクラスの物体検出をSSDでやってみる」(最終閲覧日:2022/02/11)
http://cedro3.com/ai/pytorch-ssd-bccd/
[4]・・・「【簡単】LabelImg(アノテーションツール)のインストール」(最終閲覧日:2022/02/11)
https://self-development.info/%E3%80%90%E7%B0%A1%E5%8D%98%E3%80%91labelimg%EF%BC%88%E3%82%A2%E3%83%8E%E3%83%86%E3%83%BC%E3%82%B7%E3%83%A7%E3%83%B3%E3%83%84%E3%83%BC%E3%83%AB%EF%BC%89%E3%81%AE%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88/
[5]・・・Jingru Yiら「Oriented Object Detection in Aerial Images with Box Boundary-Aware Vectors」
https://arxiv.org/pdf/2008.07043.pdf