※本記事は Amazon ECS(EC2タイプ)のちょっと長めのチュートリアル( 第1回 , 第2回 , 第3回 )の続きです。
( 第4回とは独立した内容なので、第3回までで構築した環境で確認可能です。)
今回は異常系の処理で、コンテナ・ecs-agent・インスタンスが停止した場合の動作を確認してみます。

インスタンスとサービスのスケール
いつものように、インスタンスとサービス(タスク数)をスケールアウトしてそれぞれ2に設定しておきます。
インスタンスのスケールアウト
ecs-cliコマンドでインスタンス数を2に変更します。ecs-cliコマンドのセットアップは 第4回の後半 に手順があるので参照して下さい。
## ※構成情報の設定
## ecs-cli configure --cluster <クラスタ名> --cfn-stack-name "EC2ContainerService-"<クラスタ名> --region <リージョン> --config-name <Config名(何でもよい)>
$ ecs-cli configure --cluster va-ecs-demo-cluster01 --cfn-stack-name EC2ContainerService-va-ecs-demo-cluster01 --region ap-northeast-1 --config-name vapractice-ecs
INFO[0000] Saved ECS CLI cluster configuration vapractice-ecs.
## ※インスタンス数の変更
## ecs-cli scale --capability-iam --size <変更後のインスタンス数> --cluster <クラスタ名> --region <リージョン> --aws-profile <awsプロファイル>
$ ecs-cli scale --capability-iam --size 2 --cluster va-ecs-demo-cluster01 --region ap-northeast-1 --aws-profile vatest
INFO[0000] Waiting for your cluster resources to be updated...
INFO[0000] Cloudformation stack status stackStatus=UPDATE_IN_PROGRESS
サービスのスケールアウト(タスク数を2にする)
awsコマンドでタスク数を2に設定します。
aws ecs update-service --cluster <クラスタ名> --service <サービス名> --desired-count <変更後のタスク数> --profile <awsプロファイル>
$ aws ecs update-service --cluster va-ecs-demo-cluster01 --service va-ecs-service01 --desired-count 2 --profile vatest
※サービス定義が出力されるが長いので省略※
1) コンテナ(ECSサービス)の異常終了
最初はコンテナが異常終了した場合です。ECSとしては"サービスの異常終了"となりますが、サービスの異常終了は意図的に起こせないのでインスタンスにログインしてコンテナを止めてみます。
実行前の状態:タスクが2つ実行中となっています。

インスタンス2台のどちらかにログインし、dockerコマンドでコンテナを停止します。
# ※Dockerプロセスの確認
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
57a15e208bbd <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:nginxtest "nginx -g 'daemon of…" 12 seconds ago Up 11 seconds 0.0.0.0:8080->80/tcp ecs-va-ecs-task-definition01-3-nginx-demo01-b2beddd695a2aae1bf01
f9c743cc0a4f amazon/amazon-ecs-agent:latest "/agent" 4 hours ago Up 4 hours ecs-agent
# ※コンテナ停止
# docker stop 57a15e208bbd
57a15e208bbd
# ※停止後のプロセス確認
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f9c743cc0a4f amazon/amazon-ecs-agent:latest "/agent" 4 hours ago Up 4 hours ecs-agent
AWSコンソールに戻ってタスクの表示を更新すると・・・

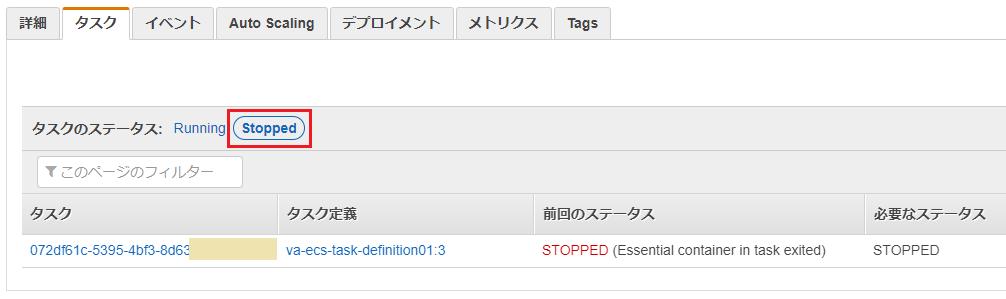
ぱっと見変化が無いように見えますが、よく見ると1つ目のタスクIDが変わっています。
タスクのステータス:"Stop"を選択すると、以前のタスクが異常終了した(Essential container in task exited)ことが確認できます。
インスタンス上で再度Dockerコマンドを実行すると、別のコンテナが起動されていることを確認できます。
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b4b83be1a7a2 <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:nginxtest "nginx -g 'daemon of…" 56 seconds ago Up 55 seconds 0.0.0.0:8080->80/tcp ecs-va-ecs-task-definition01-3-nginx-demo01-ec96c0dff697a4a9df01
f9c743cc0a4f amazon/amazon-ecs-agent:latest "/agent" 4 hours ago Up 4 hours ecs-agent
AWSコンソールで、サービス → イベントタブを見ると、20秒ほどで起動されたことが確認できます。

2) ECSエージェントの異常終了
続いてECSエージェント停止の場合を試してみます。ECSエージェントについてはこれまで説明していませんでしたが、dockerコマンドの結果に時々出ていた "amazon/amazon-ecs-agent:latest" コンテナが該当します。
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b4b83be1a7a2 <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:nginxtest "nginx -g 'daemon of…" 21 minutes ago Up 21 minutes 0.0.0.0:8080->80/tcp ecs-va-ecs-task-definition01-3-nginx-demo01-ec96c0dff697a4a9df01
f9c743cc0a4f amazon/amazon-ecs-agent:latest "/agent" 4 hours ago Up 4 hours ecs-agent
# ※amazon-ecs-agentの方を止める
# docker stop f9c743cc0a4f
f9c743cc0a4f
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b4b83be1a7a2 <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:nginxtest "nginx -g 'daemon of…" 21 minutes ago Up 21 minutes 0.0.0.0:8080->80/tcp ecs-va-ecs-task-definition01-3-nginx-demo01-ec96c0dff697a4a9df01
停止後、AWSコンソールに戻ってインスタンスの表示を確認すると、接続されたエージェント:falseになっていることが確認できます。

しばらく待っているとECSエージェントが再起動され、tureに戻ります。

インスタンス上で再度Dockerコマンドを実行すると、別のコンテナが起動されていることを確認できます。
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
51e3ff72cebb amazon/amazon-ecs-agent:latest "/agent" 23 seconds ago Up 23 seconds ecs-agent
b4b83be1a7a2 <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:nginxtest "nginx -g 'daemon of…" 21 minutes ago Up 21 minutes 0.0.0.0:8080->80/tcp ecs-va-ecs-task-definition01-3-nginx-demo01-ec96c0dff697a4a9df01
# ※ecs-agentのログを確認
# cat /var/log/ecs/ecs-init.log
※途中省略※
2019-09-20T06:23:12Z [INFO] Agent exited with code 0
※途中省略※
2019-09-20T06:23:22Z [INFO] Starting Amazon Elastic Container Service Agent
※途中省略※
エージェントの再起動自体は10秒ほどで行われますが、ECSの状態反映は多少時間が(1分ほど)かかる場合もあるようです。
3) EC2の異常終了
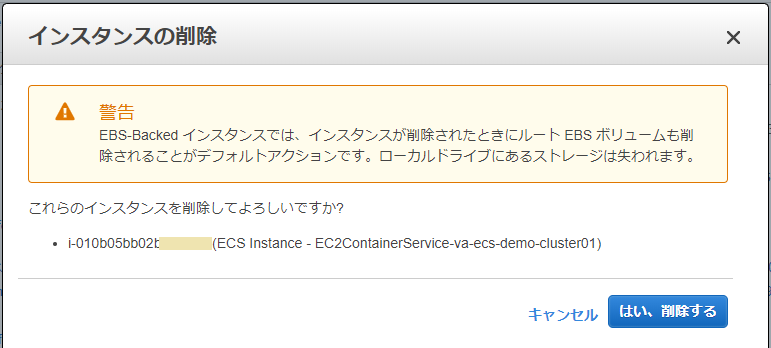
最後にEC2の異常終了を試します。起動中のインスタンスのどちらかを選び、

思い切って(?)インスタンスを削除します。

新しいインスタンスが起動するので、少し時間がかかりますが、待っていると2台構成に戻ります。
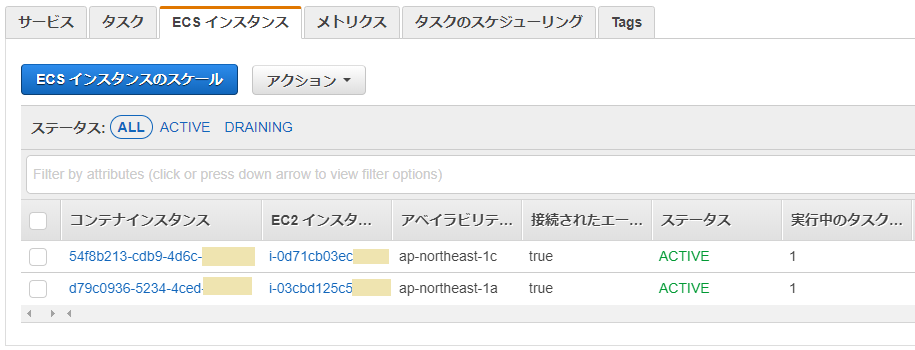
第2回で確認したように、この場合はAutoSchalingグループでのインスタンス起動となります。ログを見ると1分ほどでインスタンス起動しているのが確認できます。

サービスの方にもログが残ります。サービスへの反映は2~3分ほどかかっているのが確認できます。

新規インスタンスにログインすればコンテナ起動していることも確認できます(特に見た目変わりませんが)。
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8c10747e6f2f <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:nginxtest "nginx -g 'daemon of…" 29 minutes ago Up 29 minutes 0.0.0.0:8080->80/tcp ecs-va-ecs-task-definition01-3-nginx-demo01-d2fbd8bedfaecba6e001
fc7638c8ee12 amazon/amazon-ecs-agent:latest "/agent" 30 minutes ago Up 30 minutes ecs-agent
以上で、コンテナ・ecs-agent・インスタンスが停止した場合に再起動される動作が確認できました。
手順には入れませんでしたが、再起動中にブラウザでのアクセス http://<ELBのDNS名>:8080/index.html も確認するとより分かりやすいかと思います。
スケールイン
以降は毎回の手順ですが、サービスとインスタンスを0に戻しておきます。
サービスのスケールイン(タスク数を0にする)
awsコマンドで設定します。
aws ecs update-service --cluster <クラスタ名> --service <サービス名> --desired-count <変更後のタスク数> --profile <awsプロファイル>
$ aws ecs update-service --cluster va-ecs-demo-cluster01 --service va-ecs-service01 --desired-count 0 --profile vatest
※サービス定義が出力されるが長いので省略※
インスタンスのスケールイン
ecs-cliコマンドでインスタンス数を0に変更します。
## ecs-cli configure --cluster <クラスタ名> --cfn-stack-name "EC2ContainerService-"<クラスタ名> --region <リージョン> --config-name <Config名(何でもよい)>
$ ecs-cli configure --cluster va-ecs-demo-cluster01 --cfn-stack-name EC2ContainerService-va-ecs-demo-cluster01 --region ap-northeast-1 --config-name vapractice-ecs
INFO[0000] Saved ECS CLI cluster configuration vapractice-ecs.
## ecs-cli scale --capability-iam --size <変更後のインスタンス数> --cluster <クラスタ名> --region <リージョン> --aws-profile <awsプロファイル>
$ ecs-cli scale --capability-iam --size 0 --cluster va-ecs-demo-cluster01 --region ap-northeast-1 --aws-profile vatest
INFO[0000] Waiting for your cluster resources to be updated...
INFO[0000] Cloudformation stack status stackStatus=UPDATE_IN_PROGRESS