DataFrameの作り方
データ入力
import pandas as pd
dt = {
'a':[30, 40],
'b':[20, 50]
}
dtf = pd.DataFrame(dt)
dtf

カラム(列名)のつけ方
dtf.columns = ['A社', 'B社']
dtf

インデックス(行名)のつけ方
dtf.index = ['4月売上', '5月売上']
dtf

カラム名の変更方法
dtf = dtf.rename(columns = {"A社": "AAA社", "B社": "BBB社"})
dtf

インデックスとカラム一度で設定することも可能
dt = [
[30, 40],
[20, 50]
]
dtf = pd.DataFrame(dt, index=['4月売上', '5月売上'], columns=['A社', 'B社'])
dtf

Indexが同じDataFrame同士を結合する
DataFrame_A作成
df_A = [
[30, 40],
[20, 50]
]
df_A = pd.DataFrame(df_A, index=['4月売上', '5月売上'], columns=['A社', 'B社'])
df_A

DataFrame_B作成
df_B = [
[10, 90],
[50, 40]
]
df_B = pd.DataFrame(df_B, index=['4月売上', '5月売上'], columns=['C社', 'D社'])
df_B

DataFrame_A と DataFrame_B を結合
df_AB = pd.concat([df_A, df_B], axis=1)
df_AB

DataFrameからデータを抽出する
列名を抽出する
dtf.columns
-------------------------------------
Index(['A社', 'B社'], dtype='object')
行名を抽出する
dtf.index
--------------------------------------------
Index(['4月売上', '5月売上'], dtype='object')
カラムのデータを抽出する ※1列のみの場合
dtf['A社']
-----------------------
4月売上 30
5月売上 20
Name: A社, dtype: int64
カラムのデータを抽出する ※複数列の場合
dtf[['A社', 'B社']]

行データを行名を指定して抽出する ※1行のみの場合
dtf.loc['4月売上']
---------------------------
A社 30
B社 40
Name: 4月売上, dtype: int64
行データを行名を指定して抽出する ※複数行の場合
dtf.loc[['4月売上', '5月売上']]

行数でデータを抽出する ※1行のみの場合
dtf.iloc[0]
---------------------------
A社 30
B社 40
Name: 4月売上, dtype: int64
行数でデータを抽出する ※複数行の場合
dtf.iloc[0:2]

日付の連番を自動で生成する
date_range関数で日付をperiodの分だけ連番で振れる
test_df = pd.DataFrame(list('ABCDEFGHIJ'), index=pd.date_range('20240101', periods=10))
test_df

行を取り出す時は「-」あり・なし両方可能
# 両方とも同じ出力結果
test_df['2024-01-03':'2024-01-07']
test_df['20240103':'20240107']

DataFrameの値をコピーする
参照コピーにならないので、元のDataFrameに影響を与えずに済む
copyライブラリのdeepcopy関数を使用する
import copy
df_copy = copy.deepcopy(df)
DataFrameの列にある不要な文字を取り除く
数値によくある3桁ごとの「,」を取り除いて更にobject型からint64型に変換
df['money'] = df['money'].str.replace(',', '').astype('int64')
文字列の入ったDataFrameでmean()を実行すると起きるエラーを回避する
DataFrame作成
dt = [
['4月売上', 'X社', 40],
['4月売上', 'Y社', 50],
['5月売上', 'X社', 30],
['5月売上', 'Y社', 70],
]
dtf = pd.DataFrame(dt, columns=['売上月', '得意先', '売上高'])
dtf

objectで平均値とれないというエラー発生
dtf_group = dtf.groupby('売上月').mean()
dtf_group
==========
TypeError: agg function failed [how->mean,dtype->object]
numeric_only=Trueオプションを追加することで回避できる
dtf_group = dtf.groupby('売上月').mean(numeric_only=True)
dtf_group

並べて順位をつける
DataFrame作成
import pandas as pd
df = [
['ProductXX', 100],
['ProductYY', 120],
['ProductZZ', 30],
['ProductAA', 50],
]
df = pd.DataFrame(df, columns=['製品名', '売上高_万円'])
df

売上高を降順に並べる
df_sort = df.sort_values("売上高_万円", ascending=False)
df_sort

「順位」というカラムを追加して、そこに順位を入力
df_sort["順位"] = range(1, df_sort.shape[0]+1)
df_sort

カラムを並べ替える
df_sort = df_sort.reindex(columns=["順位", "製品名", "売上高_万円"])
df_sort

Indexをリセットする
df_sort = df_sort.reset_index(drop=True)
df_sort

複数の列名を一気に変える
例として、e-StatでダウンロードしてきたCSVファイルによくある、「列と1行目の部分をドッキングして、不要部分を削除する」という操作を行う。
ここでは、列の「Unnamed 0~4」を「団体コード、都道府県名、市区町村名、性別」に変更して、index=0の行をdropする。
DataFrame再現
original_data = {
'Unnamed: 0': ['団体コード', '-', '-', '-', '010006', '010006'],
'Unnamed: 1': ['都道府県名', '合計', '合計', '合計', '北海道', '北海道'],
'Unnamed: 2': ['市区町村名', '-', '-', '-', '-', '-'],
'Unnamed: 3': ['性別', '計', '男', '女', '計', '男'],
'総数': ['人', 123223561, 60093419, 63130142, 5148060, 2433466]
}
df = pd.DataFrame(original_data)
df

削除するカラムをold_columns、新しい絡むをnew_columnsにリストにする
old_columns = list(df.columns[0:4])
new_columns = list(df.iloc[0, 0:4])
print(old_columns)
print(new_columns)
========================================================
# 出力結果
['Unnamed: 0', 'Unnamed: 1', 'Unnamed: 2', 'Unnamed: 3']
['団体コード', '都道府県名', '市区町村名', '性別']
古いカラムと新しいカラムを辞書形式にzipでドッキングする
columns_dict = {old:new for old, new in zip(old_columns, new_columns)}
print(columns_dict)
======================================================================
# 出力結果
{'Unnamed: 0': '団体コード', 'Unnamed: 1': '都道府県名', 'Unnamed: 2': '市区町村名', 'Unnamed: 3': '性別'}
DataFrameの列名を更新する
df.rename(columns=columns_dict, inplace=True)
df

不要な0行目を削除して、Indexを振りなおす
df = df.drop(index=0).reset_index()
df

列の範囲を指定して平均値等を出力する
データ指定の箇所で、df[columns[:]]を指定してあげると、最初に出した平均や2番目に出した分散などの影響を受けずに済む。
データ部分だけのカラムを指定
import numpy as np
import pandas as pd
data = [[172, 165, 186, 179, 168], [1.72, 1.65, 1.86, 1.79, 1.68]]
index = ["身長[cm]", "身長[m]"]
columns = ["A", "B", "C", "D", "E"]
df = pd.DataFrame(data=data, index=index, columns=columns)
df["平均"] = df[columns[0:5]].mean(axis=1, numeric_only=True)
df["分散"] = df[columns[0:5]].var(axis=1, numeric_only=True)
df["標準偏差"] = np.std(df[columns[0:5]], axis=1)
df

カラムを指定しないとこうなる
import numpy as np
import pandas as pd
data = [[172, 165, 186, 179, 168], [1.72, 1.65, 1.86, 1.79, 1.68]]
index = ["身長[cm]", "身長[m]"]
columns = ["A", "B", "C", "D", "E"]
df = pd.DataFrame(data=data, index=index, columns=columns)
df["平均"] = df.mean(axis=1, numeric_only=True)
df["分散"] = df.var(axis=1, numeric_only=True)
df["標準偏差"] = np.std(df, axis=1)
df
平均については、A~Eまでの値を計算しているが、分散はA~平均までの値が入ってしまい、標準偏差はA~分散までの値が入ってしまう。

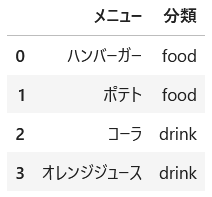
map関数でキーに対応する値を引っ張ってくる
import pandas as pd
burger_shop = pd.DataFrame({
'メニュー': ['ハンバーガー', 'ポテト', 'コーラ', 'オレンジジュース']
})
food_map = {
'ハンバーガー': 'food',
'ポテト': 'food',
'コーラ': 'drink',
'オレンジジュース': 'drink'
}
burger_shop

burger_shop['分類'] = burger_shop['メニュー'].map(food_map)
burger_shop
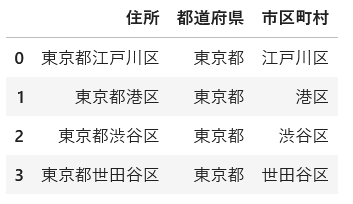
map関数で同じDataFrameのデータからデータを部分的に取り出す
address_data = pd.DataFrame({
'住所': ['東京都江戸川区', '東京都港区', '東京都渋谷区', '東京都世田谷区']
})
address_data

address_data['都道府県'] = address_data['住所'].map(lambda x: str(x)[0:3])
address_data['市区町村'] = address_data['住所'].map(lambda x: str(x)[3:])
address_data