この記事で利用している新しい顔検出がOpenCV 4.8.0からアップデートされYuNet v2(202303)になります。
APIに変更は無いのでソースコードは修正の必要は無く、モデルを差し替えるだけでそのまま利用できると思います。ただし、各種閾値などのパラメーターは調整が必要になる可能性があります。
詳しくは該当のPull Requestを参照してください。
https://github.com/opencv/opencv/pull/23020
https://github.com/opencv/opencv_extra/pull/1038
この記事はOpenCV Advent Calendar 2021の4日目の記事です。
新しい顔検出/顔認識のAPI
OpenCV 4.5.4から新しく顔検出/顔認識のAPIが実装されました。
- cv::FaceDetectorYN ... YuNetによる顔とランドマークの検出
- cv::FaceRecognizerSF ... SFaceによる顔の認識
これらのAPIをサンプルプログラムとともに紹介していきます。
前回の記事ではYuNetによる顔検出を紹介しました。今回の記事ではSFaceによる顔認識を紹介します。
SFaceによる顔の認識
SFaceでは顔画像から128次元の特徴を抽出、別の顔画像から抽出しておいた特徴と比較することでスコアを出します。
このスコアが閾値以上であれば2つの顔画像に映っている人物は同じ人物だと言えます。
サンプルプログラム全体は以下で公開しています。
サンプルプログラムの構成
サンプルプログラムは3段階の構成になっています。
- generate_aligned_faces.py ... 画像から顔を検出して切り出し、顔画像として保存する
- generate_feature_dictionary.py ... 顔画像から特徴を抽出、特徴辞書として保存する
- face_recognizer.py ... 入力画像から顔を検出し特徴を抽出、特徴辞書と比較して顔認識する
1. 画像から顔を検出して切り出し、顔画像として保存する
モデルを準備する
ここでは以下の学習済みモデルを利用します。リンクからダウンロードしてください。
モデルを読み込む
学習済みのモデルファイルを読み込み、顔検出器と顔認識器を生成します。
cv2.FaceDetectorYN.create()にはYuNetの学習済みのモデル、入力画像サイズを指定します。
cv2.FaceRecognizerSF.create()にはSFaceの学習済みのモデルを指定します。
# モデルを読み込む
face_detector = cv2.FaceDetectorYN.create("yunet.onnx", "", (0, 0))
face_recognizer = cv2.FaceRecognizerSF.create("face_recognizer_fast.onnx", "")
入力サイズを指定する
cv2.FaceDetectorYN.setInputSize()で入力画像の大きさに合わせてサイズを設定します。
# 入力サイズを指定する
height, width, _ = image.shape
face_detector.setInputSize((width, height))
顔を検出する
cv2.FaceDetectorYN.detect()に画像を入力して顔を検出します。
# 顔を検出する
_, faces = face_detector.detect(image)
faces = faces if faces is not None else []
顔を切り抜く
顔の検出結果から顔領域を切り抜きます。このとき目・鼻・口の位置が一定になるように正規化され、どの顔も同じ大きさになります。
cv2.FaceRecognizerSF.alignCrop()に顔を検出した元画像と顔の検出結果を入力します。
ここではcv2.FaceDetectorYN.detect()の結果をそのまま入力します。他の顔検出手法の結果を入力したい場合は、顔の検出結果をcv2.FaceDetectorYN.detect()の出力フォーマットに合わせるか、自分で正規化した顔画像を生成する必要があることに注意してください。
戻り値は正規化された顔画像です。ランドマークの位置が一定になるようにアフィン変換された顔が112x112のサイズで出されます。
# 検出された顔を切り抜く
aligned_faces = []
if faces is not None:
for face in faces:
aligned_face = face_recognizer.alignCrop(image, face)
aligned_faces.append(aligned_face)
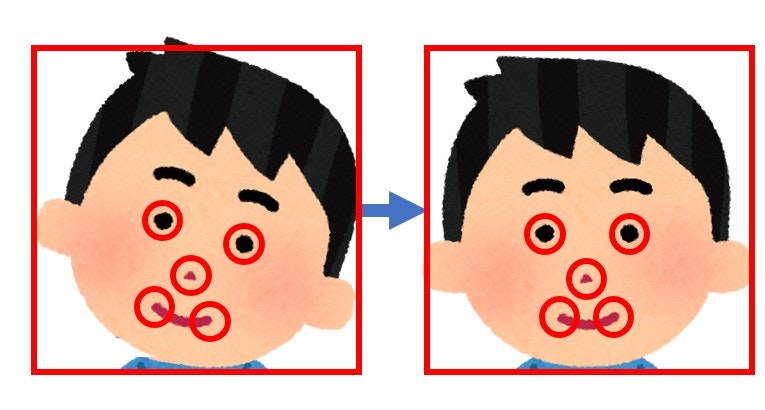
顔画像を保存する
正規化された顔画像をファイルに保存します。
ここでは一例としてface001.jpg、face002.jpg、…のように名前を付けて保存しています。
for i, aligned_face in enumerate(aligned_faces):
cv2.imwrite("face{:03}.jpg".format(i + 1), aligned_face)
2. 顔画像から特徴を抽出、特徴辞書として保存する
モデルを準備する
ここでは以下の学習済みモデルを利用します。リンクからダウンロードしてください。
モデルを読み込む
学習済みのモデルファイルを読み込み、顔認識器を生成します。
cv2.FaceRecognizerSF.create()にはSFaceの学習済みのモデルを指定します。
# モデルを読み込む
face_recognizer = cv2.FaceRecognizerSF.create("face_recognizer_fast.onnx", "")
特徴を抽出する
あらかじめ読み込んでおいた正規化された顔画像から特徴を抽出します。
cv2.FaceRecognizerSF.feature()に正規化された顔画像を入力します。
戻り値は抽出された128次元の特徴になります。
# 特徴を抽出する
face_feature = face_recognizer.feature(aligned_face)
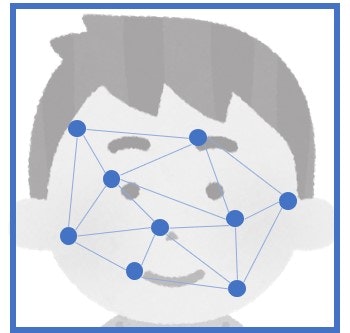
特徴を保存する
抽出した特徴をファイルやデータベースなどに辞書として保存しておきます。
ここではNumPyのnumpy.save()で.npyファイルに保存しています。
入力画像のファイル名face001.jpgを利用してface001.npyのようなファイル名で保存しています。
これが特徴ファイルになります。認識したい人物の数だけ特徴ファイルを作成しておきます。
# 特徴を保存する
filename = os.path.splitext(os.path.basename(file))[0] # face001.jpg -> face001
np.save(filename, face_feature)
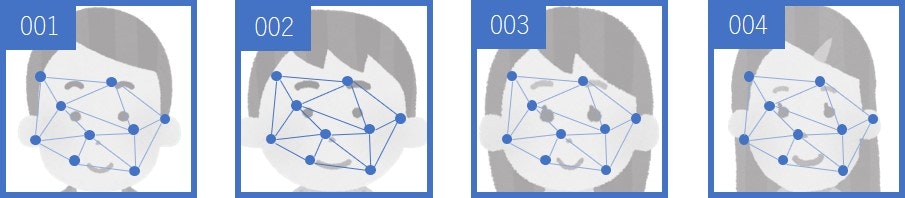
また、次節では認識結果を表示するときに特徴ファイルのファイル名をユーザIDとして利用しています。
わかりやすいようにirasutoya.npyなどのようにリネームしておくとよいでしょう。
3. 入力画像から顔を検出し特徴を抽出、特徴辞書と比較して顔認識する
特徴を辞書に読み込む
認識したい人物の数だけ作成しておいた特徴ファイルから特徴を読み込みます。
ここではファイル名をユーザーIDとして特徴とセットにして辞書を作成しています。
# 特徴を読み込む
dictionary = []
files = glob.glob(os.path.join(directory, "*.npy"))
for file in files:
feature = np.load(file)
user_id = os.path.splitext(os.path.basename(file))[0] # face001.npy -> face001
dictionary.append((user_id, feature))
モデルを準備する
ここでは以下の学習済みモデルを利用します。リンクからダウンロードしてください。
モデルを読み込む
学習済みのモデルファイルを読み込み、顔検出器と顔認識器を生成します。
cv2.FaceDetectorYN.create()にはYuNetの学習済みのモデル、入力画像サイズを指定します。
cv2.FaceRecognizerSF.create()にはSFaceの学習済みのモデルを指定します。
# モデルを読み込む
face_detector = cv2.FaceDetectorYN.create("yunet.onnx", "", (0, 0))
face_recognizer = cv2.FaceRecognizerSF.create("face_recognizer_fast.onnx", "")
入力サイズを指定する
cv2.FaceDetectorYN.setInputSize()で入力画像の大きさに合わせてサイズを設定します。
# 入力サイズを指定する
height, width, _ = image.shape
face_detector.setInputSize((width, height))
顔を検出する
cv2.FaceDetectorYN.detect()に画像を入力して顔を検出します。
# 顔を検出する
_, faces = face_detector.detect(image)
faces = faces if faces is not None else []
正規化して特徴を抽出する
ここからは検出された顔ごとに処理していきます。
まずは正規化された顔画像から特徴を抽出します。
cv2.FaceRecognizerSF.alignCrop()で顔の検出結果から正規化された顔画像を取得します。
cv2.FaceRecognizerSF.feature()で正規化された顔画像から特徴を抽出します。
# 顔を切り抜き特徴を抽出する
aligned_face = face_recognizer.alignCrop(image, face)
feature = face_recognizer.feature(aligned_face)
辞書に含まれる特徴と比較する
辞書に含まれる特徴と抽出した特徴を比較します。
cv2.FaceRecognizerSF.match()に比較したい特徴を2つと距離の計算方法を指定します。
ここでは比較にはcv2.FaceRecognizerSF_FR_COSINEを指定してコサイン距離を利用しています。1
戻り値はスコアになります。この値は同じ人物では大きく、別の人物では小さくなります。
簡易的にチュートリアルで示されているコサイン距離の閾値0.363より大きければマッチしたと判定しています。
より正確に処理するならば、閾値以上かつスコアが最も高いものを選ぶ必要がありますが、辞書に含まれる人物の数が少なければ上記の処理でも十分でしょう。
ここでは結果(True/False)とマッチしたユーザーIDとスコア(距離)を返しています。
# 閾値
COSINE_THRESHOLD = 0.363
NORML2_THRESHOLD = 1.128
# 特徴を辞書と比較してマッチしたユーザーとスコアを返す関数
def match(recognizer, feature1, dictionary):
for element in dictionary:
user_id, feature2 = element
score = recognizer.match(feature1, feature2, cv2.FaceRecognizerSF_FR_COSINE)
if score > COSINE_THRESHOLD:
return True, (user_id, cos_score)
return False, ("", 0.0)
# 辞書とマッチングする
result, user = match(face_recognizer, feature, dictionary)
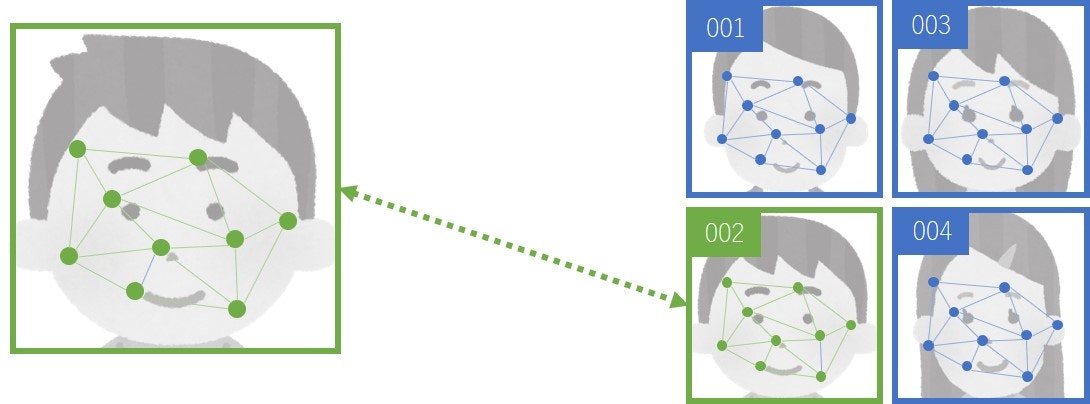
認識結果を描画する
顔のバウンディングボックスを描画、その上に認識結果をテキストで描画します。
認識結果がTrueの場合は辞書にマッチする顔が見つかったので緑色のバウンディングボックスでユーザーIDとスコアを表示しています。
認識結果がFalseの場合は辞書にマッチする顔が見つからなかったので赤色のバウンディングボックスで上にunknownと表示しています。
# 顔のバウンディングボックスを描画する
box = list(map(int, face[:4]))
color = (0, 255, 0) if result else (0, 0, 255)
thickness = 2
cv2.rectangle(image, box, color, thickness, cv2.LINE_AA)
# 認識の結果を描画する
id, score = user if result else ("unknown", 0.0)
text = "{0} ({1:.2f})".format(id, score)
position = (box[0], box[1] - 10)
font = cv2.FONT_HERSHEY_SIMPLEX
scale = 0.6
cv2.putText(image, text, position, font, scale, color, thickness, cv2.LINE_AA)
実行結果
サンプルプログラムを実行すると以下のように顔が認識され表示されます。
ここで示した実行結果は同じ画像から抽出した特徴を利用しているので正しく認識して当然ですね。

図1. 実行結果 (FDDBより引用)
異なる画像から抽出した特徴を利用した場合にも正しく認識できるのか確認してみましょう。

図2. 実行結果(株式会社ホロラボより引用)
実際のシーンでは照明環境や経年変化などの様々な要因で認識の成功率が大きく変わってきます。
照明を固定するなどの撮影環境の工夫や認識ごとに特徴ファイルを更新したり複数の特徴ファイルを使うようにするなどの冗長性を持たせる工夫が必要になるでしょう。
【おまけ】OpenCVの実装の気に入らないところ
新しい顔認識APIが追加されましたが、手放しで喜べるばかりではありません。
顔検出APIと同様に私が個人的に気に入らないところは以下の通りです。
-
objdetectモジュールに実装されている
cv::FaceRecognizerSFはdnnモジュールの機能をSFaceによる顔認識用にラップして実装されています。
dnnモジュールではそのようなタスク別のAPIをHigh Level APIと呼んでおり、すでにオブジェクト検出やクラス分類などがdnnモジュールに実装されています。
しかしながら、cv::FaceRecognizerSFはobjdetectモジュールに実装されています。個人的にはこれをdnnモジュールに移行してHigh Level APIとして実装し直すべきだと思います。 -
顔画像の切り出しAPIがユーザーフレンドリーではない
cv::FaceRecognizerSF::alignCrop()の入力フォーマットはcv::FaceDetectorYN::detect()のフォーマットが前提になっています。
はい、そんなことドキュメントには一言も書いてないですね。OpenCVあるあるのソースコードを読め方式です。
他の顔検出や顔ランドマーク検出の手法の結果を使いたい場合はこのフォーマットを合わせる必要があります。
わかりやすいようにバウンディングボックス、ランドマークを別々に入力するようにするなど改善できるような気がします。
このあたり時間があったら実装してPull Requestを投げる予定なのでOpenCV 5.xではこの記事の内容は変わってるかもしれないです。