はじめに
画像生成にGAN(敵対的生成ネットワーク)という手法があります。それを用いると目視では本物か生成された画像か見分けがつかなくなるほど高精度の画像を生成できます。そのため、顔を見せたくない人の代わりにその画像を使うなどをできたりします。一方、「ディープフェイク」の問題があったりします。
それでは、見分けが難しい生成画像をどのようにして見分ければ良いのでしょうか。その手がかりになるのが今回紹介する論文だと思います。
※本記事の「はじめに」と「さいごに」は私が書いたもので、それ以外は紹介する論文を引用しました。
論文紹介
本記事で参考にした論文は以下になります。
この論文の1.導入(INTRODUCTION)、3.方法(METHOD)、4.実験(EXPERIMENTS)を簡単ではありますがそれぞれ紹介していきます。
導入(INTRODUCTION)
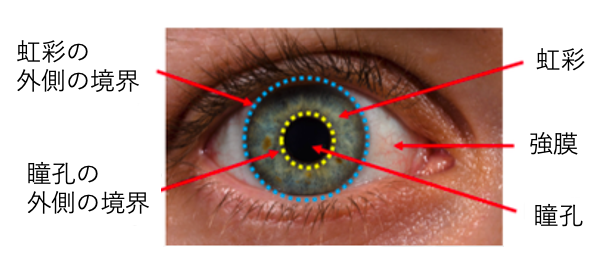
GANによって人の顔の画像を生成でき、生成された画像と実際の顔画像を視覚的に区別することは困難です。GANで生成された画像をSNSなどのプロフィール画像として、悪意のある目的で簡単に使用できたりします。これは重大な社会的混乱を引き起こす可能性があります。GANで生成された顔画像検出に関する研究も進んでいます。こちらの研究では、角膜の鏡面反射の輝きの不一致性を用いて実際の顔画像とGANで生成された顔画像を区別することを提案しています。しかし、その検証は限られた設定の下で行われているため、それに従わない場合には多くのご検知が発生してしまいます。これらの制限を排除して、よりロバストなモデルを探索するために、本論文では瞳孔の形状に基づく新しい生理学ベースの方法を提案します。具体的には、人間の目の瞳孔の形に注目しました。目の各名称については下の図をご覧ください。特に健康な成人の動向はほぼ円形の形をしていることがわかります。
ここで、本物の顔画像とGANで生成された画像に映る目を比較してみましょう。
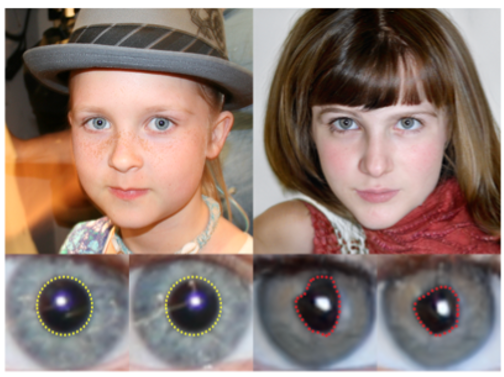
左側は実際の人間、右側はGAN(StyleGAN21)で生成のされた顔と目の画像です。実際の目の瞳孔はほぼ円形(黄色)であるのに対して、GANで生成された瞳孔は不規則な形状(赤色)であることがわかります。また、GANで生成された顔画像では、両方の瞳孔の形状は大きく異なっています。このように人工的だと感じさせる理由の1つは、現在のGANモデルは人間の目の解剖学的構造、特に瞳孔の幾何学的形状を理解していないということです。この観察を動機とし、2つの目から瞳孔を自動的にセグメント化しそれらの境界を抽出できる、GANによって生成された顔の新しい検出方法を提案します。それは、予測された瞳孔マスクと楕円に適合した瞳孔マスク間の境界交差オーバーユニオン(the Boundary intersection-over-union:BIoU)スコアを計算し、それらが楕円形であるかどうかを評価し検出するという方法です。実験では、実際の顔とGANで生成されたBIoUスコアの分布が明確に分離されていることが示され、これはそれらを区別する定量的指標として使用できます。
まとめると以下の3点です。
-
StyleGANで生成された高品質の顔には、実際の人間の瞳孔とは異なる不規則な瞳孔形状が広く存在することがわかりました。
-
GANで生成された顔を検出するための手がかりとして不規則な瞳孔形状を使用できる、シンプルでありながら効果的な新しい生理学ベースの方法を提案します。
-
私たちの調査結果は、自動検出方法の設計に使用できるだけでなく、人間がGANで生成された顔を視覚的に区別するための良い手がかりにもなります。
方法(METHOD)
瞳孔の形状を見てそれがGANで生成された画像であるかを検知するために、まず、二つの目の瞳孔の形状を自動的に抽出し、次にそれらが楕円形であるかどうかを評価します。
瞳孔のセグメンテーションと境界の抽出
次の図は入力画像(GANで生成された画像)からの瞳孔のセグメンテーションと境界検出のステップを示しています。最初に、顔検出を行い、その後ランドマーク検出2により顔のランドマークを取得します(a)。ランドマーク検出を行うと二つの目に対応する領域が切り取られます(b)。次にEyeCool3を使用して瞳孔の形状と境界を抽出します(c)。最後に抽出した瞳孔の形状から楕円をフィットさせます(d)。この楕円を楕円適合瞳孔マスク(EllipseFittedPupilMask)と呼びましょう。
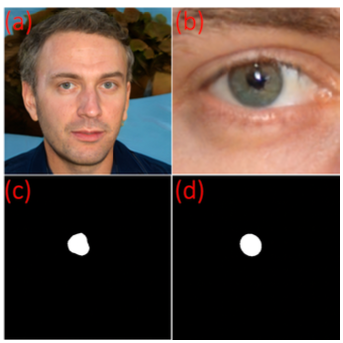
(a) 入力画像で高解像度の顔画像
(b) ランドマーク検出を使用してトリミングされた目の画像
(c) 画像(b)の予測された瞳孔の形状
(d) (c)の楕円適合瞳孔マスク
不規則な瞳孔の形状の測定
生成された画像の境界の質に敏感な画像セグメンテーションの尺度を特定することを目的としたBIoUを用いて、瞳孔の形状が楕円に近いかどうかを測定します。次の図はBIoUを説明するために瞳孔を簡略化した図です。
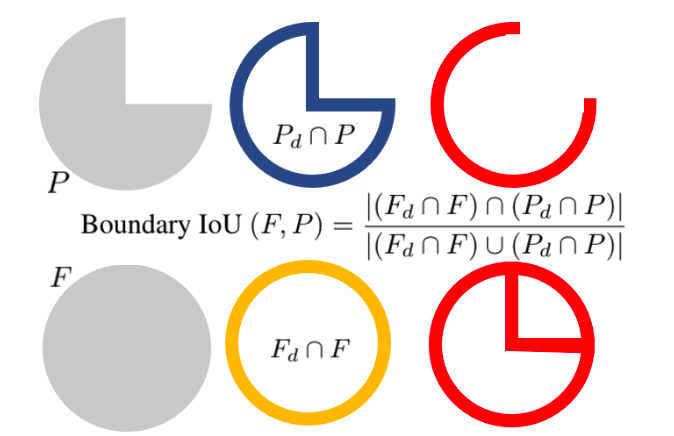
図の左側は、予測された瞳孔の形状(上の$P$)と楕円適合瞳孔マスク(下の$F$)を表しています。真ん中は、境界からの距離$d$以内のマスクを表しています。境界から$d$の分だけ内側に縮小したものがそれぞれ$P_d$と$F_d$を表しており、$P$及び$F$とのそれぞれとの共通部分が青色や赤色で描かれています。右側の図はBIoUの分子と分母に対応する領域の濃度(集合の大きさ)がそれぞれ上と下に対応しています。この定義を見てわかるように予測された瞳孔の形状が楕円に近ければBIoUは1に近づきます。そのため、瞳孔が楕円に類似しているかどうかはこのBIoUをみることで達成できます。つまり、BIoUが1に近ければ本物の顔画像、そうでなければGANで生成された顔画像だと判断できるということです。
実験(EXPERIMENTS)
GANで生成された画像の検出を実験を行なって確認します。
準備
データセットは、本物の顔画像データFlickr-Faces-HQ(FFHQ)4とStyleGAN2で生成された画像(1024×1024ピクセル)です。実装では、DLib5で提供されている顔検出とランドマーク検出を使用し、目の領域をトリミングします。その後、EyeCoolによって、瞳孔の形状をセグメント化します。さらに、瞳孔の楕円適合を行いBIoUを計算します。BIoUに現れるハイパーパラメータ$d$は$d=4$としました。
結果
まず、分析結果の例を次の図で示します。上側の図が実際の顔の両目、下側がGANで生成された顔の両目です。予測された瞳孔の境界から距離$d=4$内にある楕円適合瞳孔マスクを黄色や赤色で強調表示しています。また、BIoUスコアを画像中の数字で表しています。
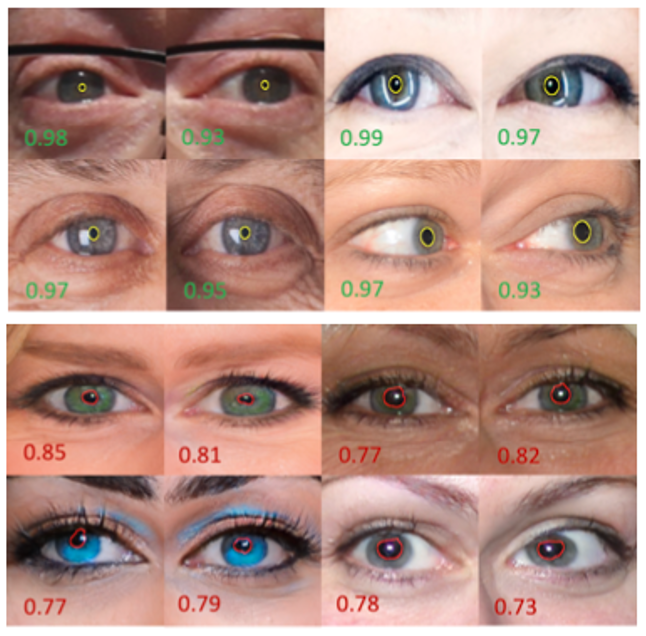
実際の人間の瞳孔はほぼ楕円形であるのに対して、GANで生成された画像の瞳孔は歪な形状をしていることがわかります。そのため、本物の顔画像ではBIoUが全て0.9を超えているのに対して、GANで生成された画像は0.9を超えていません。
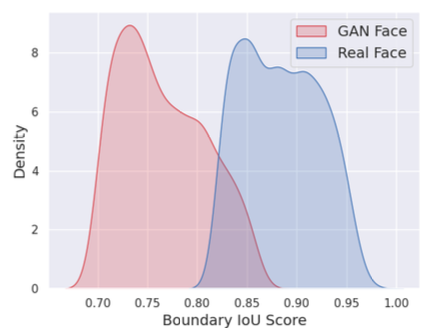
また、次の図で実際の顔画像とGANで生成された顔画像の瞳孔のBIoUスコアの分布を示しました。分布の重なりはあるもののBIoUスコアが本物の生成画像であることの区別に効果的な指標であることがわかります。
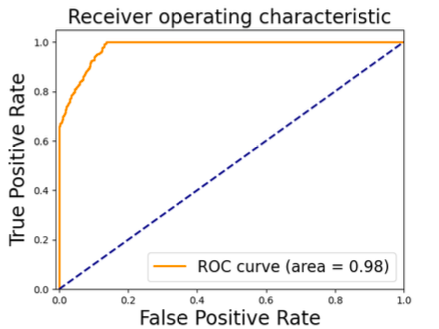
さらに、次の図はROC曲線を描いており、AUCは0.98となりました。この観点からも瞳孔の不規則な形状がGANで生成された画像の識別に効果的であることがわかります。
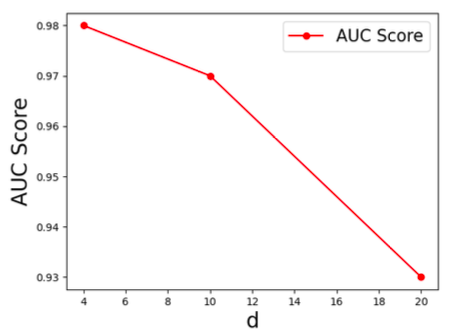
ハイパーパラメータの分析
BIoUには境界までの距離を示すパラメータ$d$があります。下の図はこの$d$に対するパフォーマンスをみています。$d=4$の時にAUCが0.98となっています。$d$が大きくなればなるほど下がっていることもわかります。これは$d$が大きいと境界に対する感度が小さくなるためです。
制限
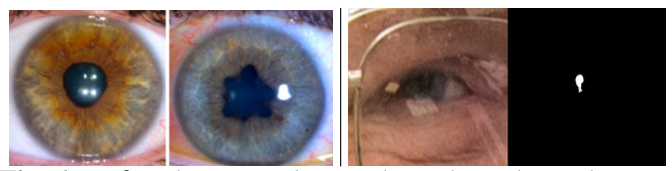
紹介した方法にはいくつかの制限があります。瞳孔の形状に着目してGANで生成された画像の検出を行っています。そのため、実際の顔画像の瞳孔の形状が楕円形ではない場合には誤検知となる可能性が発生します。例えば、病気や感染などで瞳孔や虹彩が歪になるケースが起こります。次の図の左側に病気や感染による非楕円形の虹彩や瞳孔の例を示しました。この場合には、今回紹介した方法は適用できません。しかし、データセットの実際の画像ではこのような異常な瞳孔はありませんでした。さらに、瞳孔の閉塞または瞳孔のセグメント化の失敗も誤った予測につながる可能性があります。この例が右側の図です。メガネの反射光などの妨害によりセグメントがうまくできていないことがわかります。
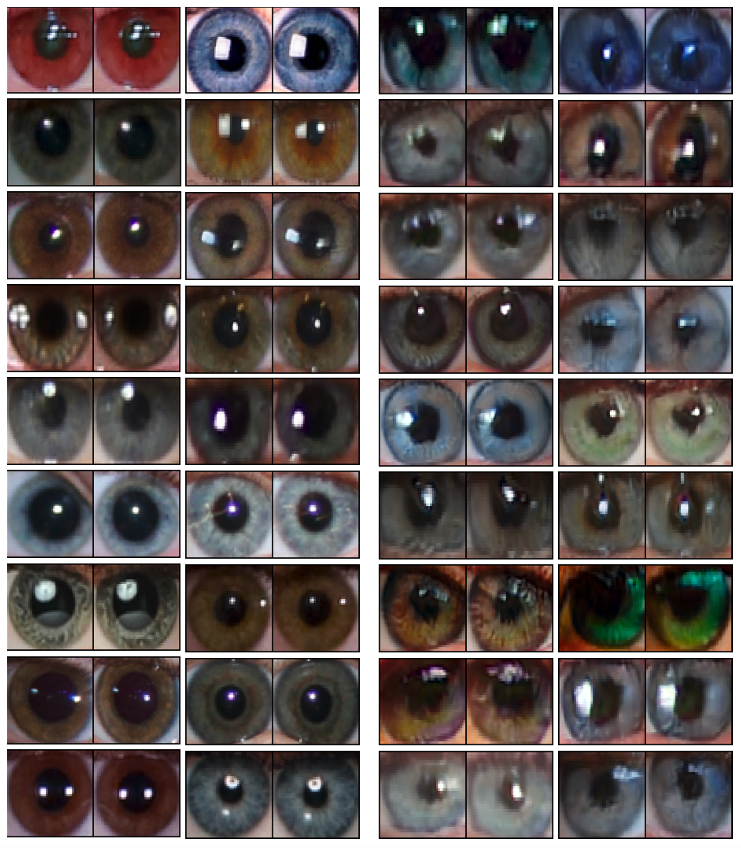
しかし、この瞳孔に着目するという手法を用いれば、人間は顔が本物かどうかを視覚的に簡単に見分けられます。次の図は実際の人間の顔(中央より左側)とGANで生成された顔(中央より右側)からの瞳孔のペアデータです。GANで生成された画像の瞳孔の形は歪で不規則であることがわかります。また、両目での違いもGANで生成された画像の方が顕著に現れています。実際には、顔画像を十分に大きくして瞳孔の形状を確認し、顔が本物かどうかを簡単に確認できます。
さいごに
ここまでみてくださりありがとうございます。ここまで読んでみると、どのようにしてGANで生成された画像かどうかを見分ければ良いのかわかったかと思います。私は、瞳孔に着目したという点が研究者たちの緻密さが窺えて大変面白かったです。しかも、BIoUという比較的簡単な指標を用いている点も素晴らしいなと感じました。
一方、より人間の画像に近づけたければ瞳孔もきちんと学習できるGANを作れば良いと思いました。生成画像からランドマーク検知で瞳孔を検知し、瞳孔を滑らかな楕円形にするという操作などできればより高品質な人画像になります。まだまだ私自身GANについては学習途中ですがこれからも続けていきたいと思います。
-
StyleGANはNVIDIAの研究者たちによって2018年12月に発表された手法です。生成される画像は高解像度(最大1024×1024ピクセル)で本物の画像と見分けがつかないぐらいです。StyleGAN2はそのStyleGANの問題点である「水滴のような塊が画像に出現する」や「顔パーツが姿勢の向きに追従しない」を修正し、更なる画像品質の向上に寄与しました。 ↩
-
ランドマークは、画像のある特徴点のことを言います。例えば顔画像ですと目、鼻、口、顎などの情報です。さらに知りたい人は「ランドマーク検出」などで調べてみてください。 ↩
-
FFHQデータとは、1024×1024ピクセルの70000枚の高品質画像データのことです。さまざまな年齢、民族性、画像の背景など多くのバリエーションがあり、メガネ、サングラス、帽子などのアクセサリを身につけた画像も多くあります。詳細はこちらの論文をご参考ください。 ↩