01/21 (追記)
ソースコード内にコメントを入れました。
03/03 (追記)
GUIを実装しました。
はじめに
syamu_game氏と会話したくなったのでチャットボットを製作しました。
これからチャットボットを作ろうと考えている方や作ってみたい方へのヒントとなれば幸いです。
公開します。
各素材とソースコード(github)これと照らし合わせながら読んでいただければわかりやすいと思います。
上記のgithubフォルダをクローンした後
$ cd engine
$ python bot.py
で動きます。
アルゴリズム
入力を受け付け
↓
形態素解析
↓
名詞や動詞などを受け取りword2vecでランダムに単語抽出
↓
マルコフ連鎖で文章作成
↓
出力
なんだかよくわからないという方でも大丈夫です!
下準備
形態素解析エンジンのインストール
$ pip install janome
word2vec用ライブラリのインストール
$ pip install gensim
開発
素材の入手
https://www63.atwiki.jp/syamugame/pages/67.html
hatsugen.txtという名前で保存します。
分かち書きtxtファイルの作成
名詞、動詞、形容詞、記号のみを半角スペース区切りで保存します。
from janome.tokenizer import Tokenizer
import os
text_file = 'hatsugen.txt'
def tokenize(text):
t = Tokenizer()
result = []
#各行に分ける
lines = text.split('\n')
#末尾の空白行を削除
del lines[-1]
for line in lines:
print('解析行:',line)
tokens = t.tokenize(line)
for token in tokens:
base_form = token.base_form
#カギカッコはマルコフ連鎖でうまく扱えない為除外
if not base_form in ['「', '」']:
pos = token.part_of_speech
pos = pos.split(',')[0]
if pos in ['名詞','動詞','形容詞','記号']:
result.append(base_form)
return result
def main():
file_dir = os.path.abspath('../src/' + text_file)
try:
bindata = open(file_dir, 'rb').read()
text = bindata.decode('utf-8')
words = tokenize(text)
except Exception as e:
print('error!',e)
exit(0)
wakati_file = '../src/wakati.txt'
with open(wakati_file, 'w', encoding='utf-8') as f:
f.write(' '.join(words))
if __name__ == '__main__':
main()
以下のようなファイルが作成されると思います。
wakati.txt

word2vecモデルの作成
word2vecとは
ワードをベクトル化して単語の距離を測れるようにしたものです。詳しくはぜひ調べてみてください!
やってみよう
今回は100次元に設定しています。
from gensim.models import word2vec
wakati_file = 'wakati.txt'
if __name__ == '__main__':
file_dir = '../src/' + wakati_file
w2v_data = word2vec.LineSentence(file_dir)
model = word2vec.Word2Vec(w2v_data, size=100, window=3, hs=1, min_count=1, sg=1)
model.save('../src/syamu_w2v_model.model')
テストしてみる
from gensim.models import word2vec
model_file = 'syamu_w2v_model.model'
model = word2vec.Word2Vec.load('../src/' + model_file)
# 調べたいワード
words = ['メニュー','オフ','OL']
for word in words:
similar_words = model.most_similar(positive=[word])
print(word,':',[w[0] for w in similar_words])
結果は以下のようになります。

syamuさんの世界観がうまく現れていると思います。配列wordsの単語を好きなものに変えてぜひ色々調べてみてください。
マルコフ辞書の作成とテスト
今度はテストも一気にやっちゃいます!
from janome.tokenizer import Tokenizer
import json,os
from markov_test import test
text_file = 'hatsugen.txt'
json_file = 'syamu_markov.json'
def tokenize(text):
t = Tokenizer()
lines = text.split('\n')
words = ' '.join(lines)
tokens = t.tokenize(words)
markov_dic = make_markov_dic(tokens)
return markov_dic
def make_markov_dic(tokens):
tmp = ['@']
dic = {}
for token in tokens:
word = token.base_form
if word == ' ' or word == ' ' or word == '「' or word == '」' or word == '\n':
continue
tmp.append(word)
if len(tmp) < 3:
continue
#もし4になったら
if len(tmp) > 3:
#先頭の@を取り除く
tmp = tmp[1:]
word1, word2, word3 = tmp
if not word1 in dic:
dic[word1] = {}
if not word2 in dic[word1]:
dic[word1][word2] = {}
if not word3 in dic[word1][word2]:
dic[word1][word2][word3] = 0
dic[word1][word2][word3] += 1
if word == '。':
tmp = ['@']
continue
return dic
def main():
if not os.path.exists('../src/' + json_file):
try:
bindata = open('../src/' + text_file, 'rb').read()
text = bindata.decode('utf-8')
except Exception as e:
print('error!',e)
exit(0)
markov_dic = tokenize(text)
json.dump(markov_dic, open('../src/' + json_file, 'w', encoding='utf-8'))
else:
markov_dic = json.load(open('../src/' + json_file, 'r'))
print(test(markov_dic))
if __name__ == '__main__':
main()
import random
def test(markov_dic):
ret = []
if not '@' in markov_dic:
return 'no dict'
top = markov_dic['@']
word1 = word_choice(top)
word2 = word_choice(top[word1])
ret.append(word1)
ret.append(word2)
while True:
word3 = word_choice(markov_dic[word1][word2])
ret.append(word3)
if word3 == '。':
break
if len(ret) >= 10:
ret.append('。')
break
word1, word2 = word2, word3
return ''.join(ret)
def word_choice(sel):
keys = sel.keys()
ran = random.choice(list(keys))
return ran
テスト結果は以下のようになります

ボロボロですが文章が生成されました!
これで必要な素材が揃ったのでボットの開発に移ります。
ボットの開発
from gensim.models import word2vec
from janome.tokenizer import Tokenizer
import json, random
model_file = 'syamu_w2v_model.model'
markov_file = 'syamu_markov.json'
def tokenize(s):
t = Tokenizer()
tokens = t.tokenize(s)
for token in tokens:
base_form = token.base_form
pos = token.part_of_speech
pos = pos.split(',')[0]
if pos in ['名詞','動詞','形容詞']:
return base_form
return '@'
def load_w2v(word):
model = word2vec.Word2Vec.load('../src/' + model_file)
try:
similar_words = model.most_similar(positive=[word])
return random.choice([w[0] for w in similar_words])
except:
return word
def make_sentence(reply):
markov_dic = json.load(open('../src/' + markov_file))
if not reply == '':
ret = []
if not '@' in markov_dic:
return 'no dict'
top = markov_dic['@']
word1 = word_choice(top)
word2 = word_choice(top[word1])
ret.append(word1)
ret.append(word2)
while True:
word3 = word_choice(markov_dic[word1][word2])
ret.append(word3)
if word3 == '。':
break
if len(ret) >= 10:
ret.append('。')
break
word1, word2 = word2, word3
return ''.join(ret)
else:
return ''
def word_choice(sel):
keys = sel.keys()
ran = random.choice(list(keys))
return ran
def main():
while True:
s = input('you :')
if s == 'quit':
break
exit(0)
word = tokenize(s)
if not word == '@':
reply = load_w2v(word)
else:
reply = ''
sentence = make_sentence(reply)
print('syamu:' + sentence)
if __name__ == '__main__':
main()
こちらの発言を解析しword2vecにかけランダムに単語を抽出した後マルコフ連鎖で文章を生成しています。
遊ぼう
早速遊んでみましょう!

う〜ん、なんとなく会話になっていますね…
ぜひ色々話しかけてみてください!
GUI
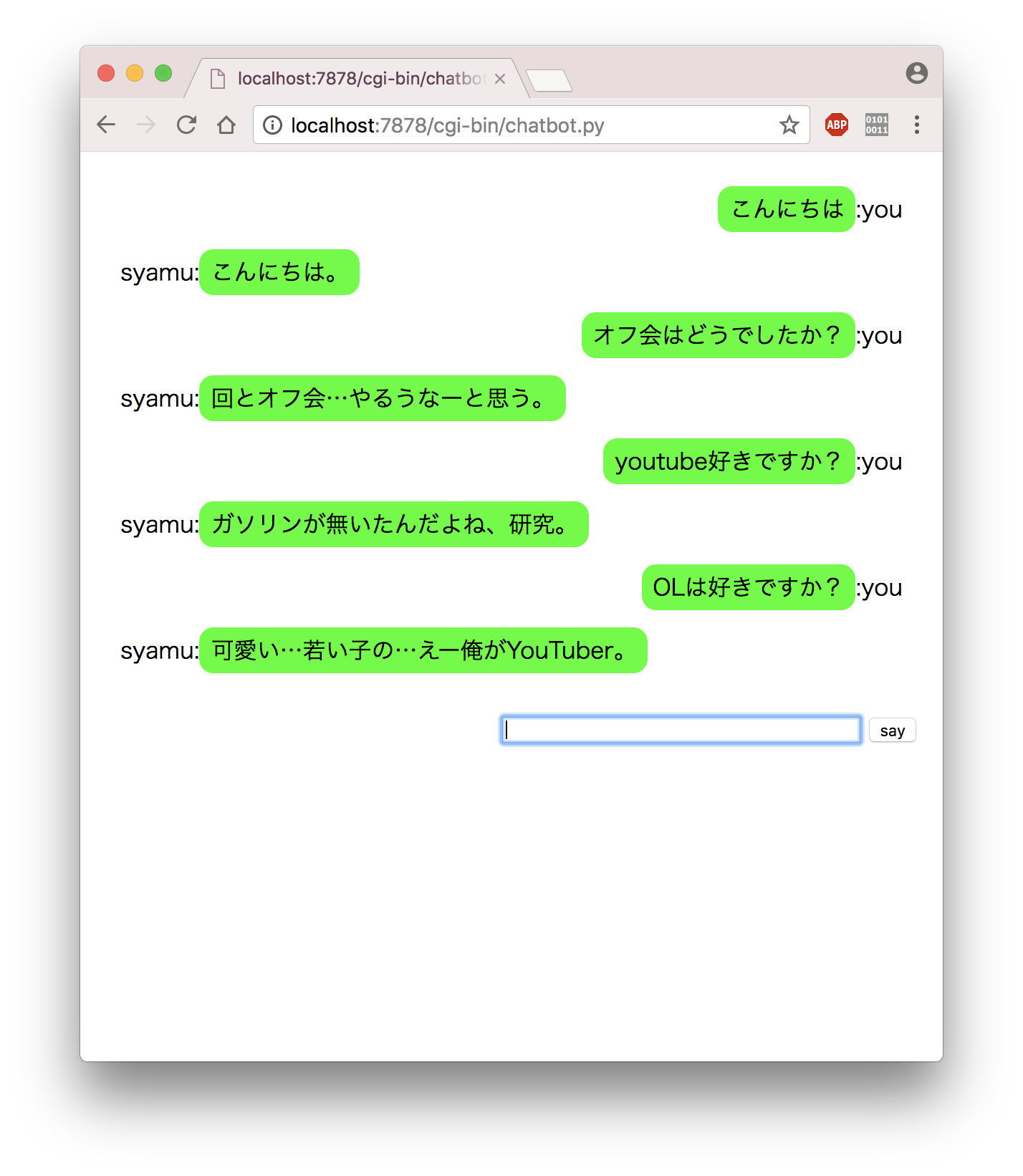 サーバーを立てた後cgi-binフォルダ下のchatbot.pyをブラウザから実行してください
# 最後に
ここまで読んで頂きありがとうございました!
皆さんもぜひチャットボットを作ってみてください!
サーバーを立てた後cgi-binフォルダ下のchatbot.pyをブラウザから実行してください
# 最後に
ここまで読んで頂きありがとうございました!
皆さんもぜひチャットボットを作ってみてください!