サイトの掲載情報を取得する際、Get Textアクティビティでは苦戦したケースがあったので、
具体的な問題点と、代替策の紹介をします。
問題点
例えばコレ→ 
写真投稿サイトFlickrの投稿写真の絞り値(この例だとf/4.5)を取得してみたのですが、
単純にGet Textを使うとSelectorは

と設定されます。
idの 'yui_3_~' は固定でなくページアクセスの度に変わるので、二度目からは確実に失敗します。
(Flickrは全てのコントロールのidを動的に生成してるっぽい)
逆に後半部分を*(アスタリスク)に変えると、他のコントロールとダブってうまくいかない。
代替策=アンカー画像の相対位置でテキスト取得
HTML要素を使ったSelectorには限界があるので、画像検出機能に頼ります。
絞り値の左にはシャッターマークがあるので、これを頼り(アンカー/Anchor)に絞り値を取得します。

Citrix Recording > Scrape Relative を使います。


 まずシャッターマークを囲んで目印(アンカー)にします。
まずシャッターマークを囲んで目印(アンカー)にします。
 次にフキダシ内の[indicate]を押して、
次にフキダシ内の[indicate]を押して、
 取得したいテキスト部分を囲むと・・・
取得したいテキスト部分を囲むと・・・
狙ったテキストを取得でき…るはずが、↓の[Nokon D500]のように他の余計なテキストも拾ってしまってます。
どうもScraping Methodが"FullText"なのが原因のようで、

"Native"にするとうまく狙った範囲のテキストだけ取得できました。

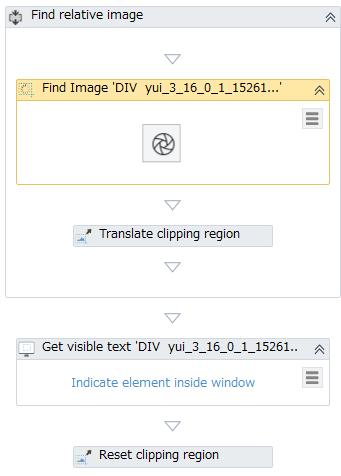
Save&Exitで自動生成されたワークフローは
- Find imageでシャッターマークの位置を取得
- Set clipping regionで1.からの相対位置指定でテキスト読み取りRegionを設定
- Get visible textで2.のRegion内のテキストを読み取り、変数に保存
- 再度Set clipping regionでテキスト読み取りRegionをクリア
となりました。
で、実行。うまく取れてます→ 
ただし画像検出である以上、ディスプレイ上に検出したい画像が表示されている必要があります。
今回のFlickrの絞り値はサイトの下の方にあるので、最初にSend keyでPage downさせて
絞り値が表示される位置までスライドさせる必要があります。面倒。
※補足
今回のFlickrですが、Get TextアクティビティでもサイトのHTML構造を(IEならF12で)調べながら
Selectorを工夫する事で、安定したデータ取得を実現可能です。
HTMLの構造↓を見ると、親のclass要素(c-charm-item-~)とSPANタグで掴めそう。

parentclass要素を使う事で安定的に掴めるようにしたSelector。コレでいけます。

Selectorを工夫して安定性を高められるのがUiPathの最大の強みなのですが、
なぜ最初からこういうSelectorを生成してくれないのか。
安定したSelectorを自動で組んでくれるAIが必要だな・・・